基于机器学习的列车设备故障预测模型研究
2020-12-31潘兆马杨学锋邹文露
袁 焦,王 珣,潘兆马,杨学锋,邹文露
(中国中铁二院工程集团有限责任公司,四川 成都 610031)
0 引 言
车载设备是高速铁路列控系统的大脑中枢,是保证其运行安全和运营效率的核心要素。随着我国高速铁路和运输体量的迅速增长,迫切需要提高高速铁路运输效率和运营安全,而车载设备故障的快速排除、定位、诊断和维护手段的优化是其决定性因素。然而,列车实际运行过程中,高速铁路车载设备快速、实时和连续地产生海量的流数据,数据量庞大、高维性、多源异构且故障模式分布不均衡等特点为数据的记录、整合和高效提取带来巨大挑战,难以快速实时地根据数据对故障进行准确预测和智能分类。鉴于以上原因,实现准确高效的车载设备故障识别具有极其重要的意义。
初期的车载设备故障预测模型主要是基于传统的静态存储数据如车载日志等对故障进行分析和挖掘,但是流式数据难以实现全部有效存储,静态存储数据后再进行遍历的传统方法明显不再有效。随后提出的基于流数据的机器学习预测模型在智能交通系统[1]、高速公路实时安全风险预测[2]、地理信息系统[3]、地热学[4]、金融交易平台[5]、基础设施智能仪表[6]、垃圾邮件与垃圾邮件发送者识别[7]和黑洞模拟模型[8]等领域,具有较高的准确性。因而,利用机器学习对流数据进行直接分析和挖掘十分必要,可以更快速、实时和准确地对车载设备故障进行排除、定位及诊断。但是,数据分类是极其重要的数据挖掘技术,流数据的分类是流式数据分析和挖掘的核心和难点。季一木等人指出,对高速铁路车载设备流数据分类的关键在于根据流式数据增量学习构造一个分类函数或分类变量,能够将新的输入变量映射到具体的类别变量上[9-11]。
针对上述关键问题,本文关注利用机器学习中的决策树进行流数据分类的方法。决策树是机器学习中的一个树状预测模型,调整后的决策树相较于其他分类算法计算量更小,更适用于处理多源异构、连续性和实时性的流数据[12-13]。基于规范化的列控设备流数据的特征,本文首先采用CVFDT决策树算法,然后结合自适应的学习过程和时间滑动窗口提高模型的准确率和实时性[14-15],构建车载设备管理维护平台,以期提高故障识别和诊断准确率,提升高速铁路运营安全和效率。
1 高速铁路车载设备
高速铁路列控车载系统是保证列车运行安全和效率的关键设备。我国列控系统在参照欧洲列控标准的基础上,结合自身列车特点,建立了CTCS(Chinese Train Control System)标准[16]。CTCS可划分为5个等级,由CTCS-0至CTCS-4组成。目前,CTCS-3级是我国重点采用的列控系统,它可通过无线通信设备实现车地通信,在高速运行中对列车进行有效管理[17]。高速铁路车载设备结构如图1所示,车载系统包含主用和备用2系,可提高系统可靠性。车载设备主要由无线通信单元(GSM-R)、人机界面(DMI)、网关(TSG)、司法记录单元(JRU)、C3主控单元(ATPCU)、C2主控单元(C2CU)、测速智能处理单元(SDP)、应答器信息传输单元(BTM)、应答器读取天线(CAU)、测速测距单元(SDU)、安全传输单元、无线传输单元、TCR轨道电路信息读取器和MVB总线等构成。
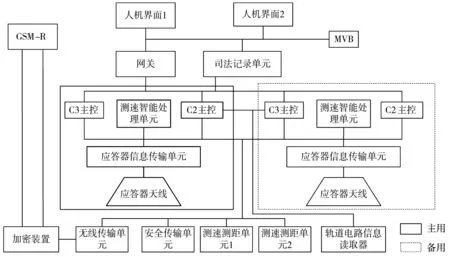
图1 高速铁路车载设备结构图
车载智能设备记录数据主要来源于车载模块数据、MVB总线数据和JRU司法记录单元数据。车载模块数据主要来源于C3主控单元、C2主控单元、测速智能处理单元和网关。其中,C3和C2主机模块是列车的核心控制单元,是最重要的数据来源。在列车高速运行中,可根据流数据对列车设备频发的故障进行高效分析,智能诊断车载设备故障类别,如BTM相关、ATPCU相关、SDU相关和JRU相关故障等。
2 流数据与决策树分类算法
2.1 铁路车载智能设备中的流数据
流数据通常是指一组大量的无边界的数据项序列,其具有连续性、大量性、实时性、变化性、多样性等特点。通常用时间序列模型(Time Series Model)表示。例如,令t表示时间戳,at表示t时间戳到达的数据,则流数据可以表示为{…,at-1,at,at+1,…}[18]。流数据通常使用元组、键值对记录等格式。
在CTCS-3级列控系统运行过程中,C2CU、ATPCU、TSG、SDP等模块会产生大量车载模块数据。车载控制单元通过MVB总线进行数据交互,这部分数据被称作MVB总线数据。同时C2CU、ATPCU这2个模块与司法记录器(JRU)之间通过Profibus总线进行数据交互,向JRU发送数据,因此JRU设备中也存储了大量的JRU数据[19]。车载设备模块数据、MVB总线数据和JRU数据共同组成了车载智能设备数据,这些数据都是在列车运行过程中实时产生的,属于流数据的一种,可以通过串口、MVB总线以及网口分别进行采集并整理,并通过网络实时发送到智能管理维护系统进行流数据分析处理,以了解各个设备工作运行状态,为及时发现和解决问题提供数据支持,从而实时、高效地进行车载智能设备的维护和管理。
2.2 数据预处理
通过以上方式采集到的车载智能设备原始数据中往往包含有部分噪声数据、部分记录不完整的数据以及记录不一致或者冗余的数据。因此不能直接使用原始数据进行数据流决策树分类,需要进行数据预处理操作。通过数据预处理能够大幅提高车载设备中的流数据决策树分类的精度和性能。其过程主要包括数据清理、数据集成、数据变换以及数据规约等。数据清理主要通过缺失值填充、光滑噪声、识别离群点、纠正不一致数据等方式来完善和规范数据;数据集成和数据变换是指根据需要将数据转换为易处理的形式进行分类学习,以发现其中潜在的规律;数据规约技术在尽量保持数据完整性的同时对原始数据进行压缩,大大缩小了数据集规模,使得对规约后的数据分析更加有效,并保持与原数据分析结果基本一致。其常用方法主要有:数值规约、维规约、数据立方聚集、数据属性子集选择、离散化以及概念分层产生等。
2.3 决策树分类算法
在完成对数据预处理之后,则进行车载设备数据流分类。由于车载智能设备在列车运行过程中所产生的数据具有规模大、类型多、高速动态变化、实时连续等特点,为了从大量的信息中快速挖掘设备异常相关的参数信息,传统数据挖掘方法已不再适用于列车车载设备数据流应用场景,因此本文对车载设备数据利用数据流挖掘算法实现对设备故障关键信息的识别。首先通过Hoeffding树构建单分类决策树模型对车载设备数据流进行初步分类。在此基础上,为解决车载数据流随时间变化产生的概念漂移,本文应用CVFDT算法,在Hoeffding树的基础上添加滑动窗口,从而使得建立决策树模型的数据流能够不断实现更新,保持车载设备数据分类模型的准确率。
2.3.1 Hoeffding树
Hoeffding树[20]是决策树的一个变种,由华盛顿大学教授Pedro Domingos和Geoff Hulten在2000年提出。它是基于Hoeffding不等式构建的,Hoeffding不等式给出了随机变量的和与其期望值偏差的概率上限:
(1)
Hoeffding树的基本思想如下:
设G是增益函数(如信息增益、基尼指数等),xa,xb是待分类数据的2个属性,在所有分类属性中,xa对应的增益值最高,xb对应的增益值次之。令:
(2)
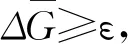
(3)
其中,R表示随机变量的取值范围,n表示样本数量。要使xa更加接近于最佳分类属性,则要求误差ε足够小,由上式可知,ε是随着随机变量个数n的增加而递减的。
基于以上基本思想,Hoeffding树在某个节点选择属性时,在足够多的训练数据中求出最佳分类属性作为该节点的测试属性,然后根据该属性的不同值所对应的类,采用分治的方式递归地获取下一层节点的测试属性,如果样本数据都在同一个类,则该节点为树叶,并用该类标记,最终形成一棵决策树。该算法对数据虽然是一次扫描,但是在保证误差ε足够小的情况下,需要增加样本数量n,从而增加了对内存的需求,这是该算法的瓶颈。
2.3.2 CVFDT算法
CVFDT算法[21](Concept-adapting Very Fast Decision Tree classification algorithm)是基于Hoeffding树的一种增量式的分类算法。CVFDT决策树可以动态改变窗口大小,根据当前已有数据构建临时决策树,在新的数据到来后动态地优化该决策树。当决策树的某个节点发生概念漂移时,会在该节点构建新的替代子树,当替代子树的分类效果优于原决策子树时,则替代子树改为新的决策子树。CVFDT决策树的构建主要可以分为3个过程,分别是CVFDTGrow,ForgetExample和CheckSplitValidity。其流程如图2所示。
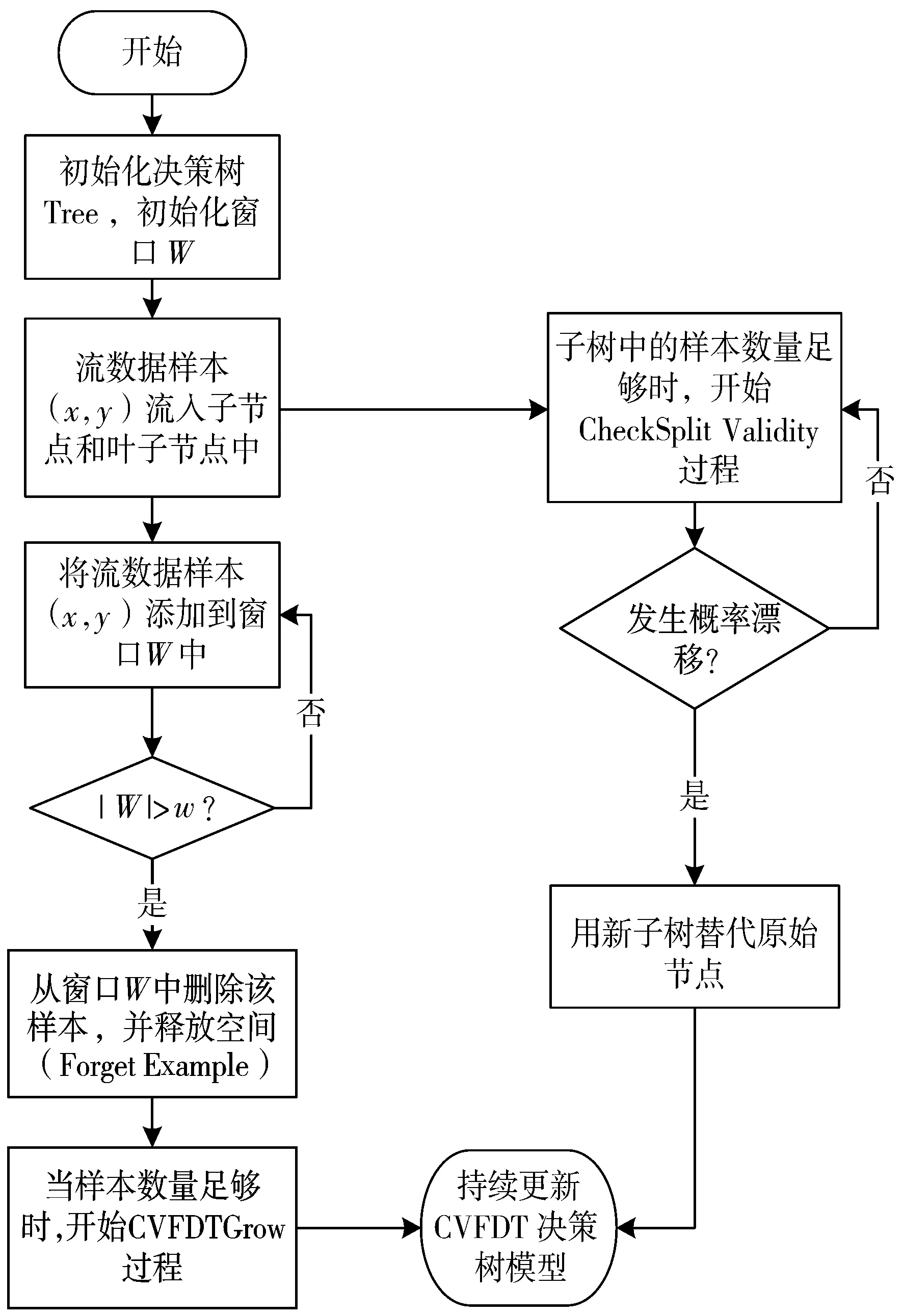
图2 CVFDT决策树流程图
3 铁路车载设备管理CVFDT模型
3.1 车载流数据特征提取
车载设备故障数据通常是由自然语言描述的文本信息,因此需要对原始数据进行预处理和特征提取。首先根据相关故障词汇在文本中出现的频率和相关历史经验,人为提取出具有代表性的故障词汇和故障类型。如表1和表2所示。
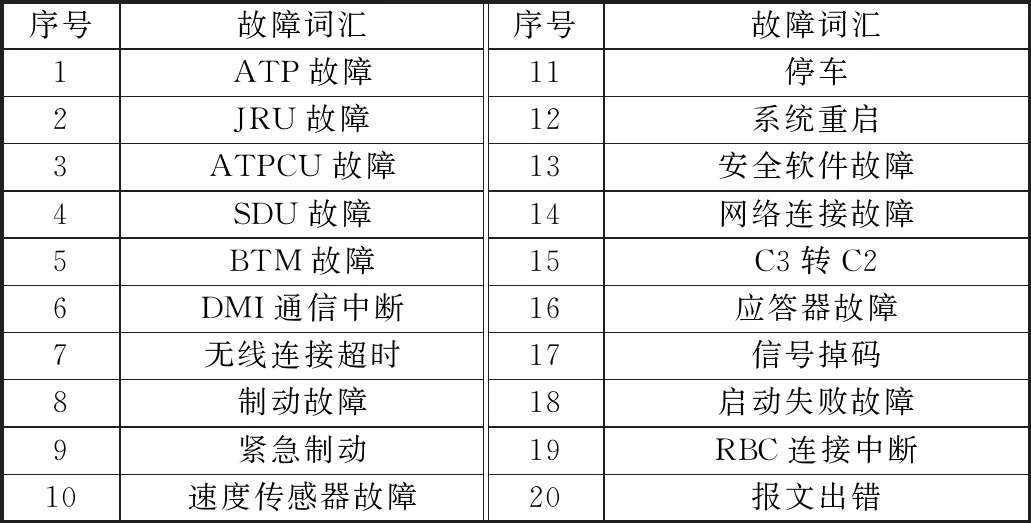
表1 故障词汇表
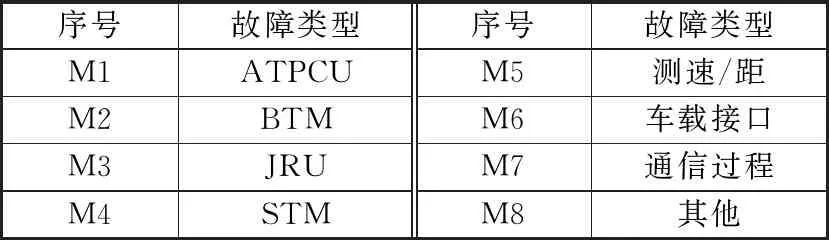
表2 故障类型表
然后针对这些故障词汇,采用TF-IDF(词频-逆文本频率)方法对其在文本中出现的频率和权重进行计算。
对特定词语t在文档d中的权重值w的计算公式如下:
(4)
式中,tf表示特定词语t在文本d中出现的频率,N为文本中词语的总个数,n为特定词语t在文本中出现的次数,N/n为逆文本频率指数(即IDF)。
从而对文本数据进行向量化来提取其特征,将原文本信息转化为带权重的词集,形成规范的训练数据。如表3所示。
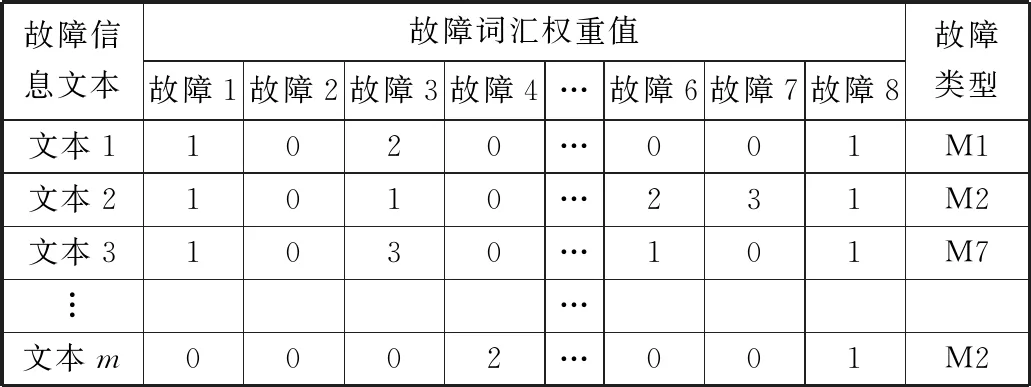
表3 规范化车载设备故障数据结构表
3.2 构建CVFDT模型
使用CVFDT算法对车载设备故障分类的算法如下:
T为空子树,初始节点统计数n=0,m为检查树增长的样例数,w为窗口所能容纳的数据块大小。对于输入的车载设备故障数据流(x,y),将其添加进窗口W中。
1) If |W|>w
①从窗口W中删除样本;
②释放空间。
2) CVFDTGrow增长过程。
①样本数据(x,y)流入叶子节点L;
②对(x,y)经过的每个节点Li,更新各个节点统计数n;
③对节点Li中的替代子树ALT(Li),递归调用CVFDTGrow增长函数;
④计算信息熵,找到最佳分类属性A进行分裂。
3) CheckSplitValidity过程。
①对于每个非叶子节点L的替代子树ALT(L)进行递归调用CheckSplitValidity过程;
②如果L的最佳分裂属性不是当前属性A,Aa是达到最大观测值G的属性,Ab是次最大观测值G的属性;
③IfG(Aa)-G(Ab)>ε
④Aa取代A成为当前最佳分裂属性。
以上的算法过程中,CVFDT通过不断输入的车载设备故障流数据,进行训练,生成了一个反映当前数据分布的实时模型,能够反映当前车载设备故障的实时状态,具有更好的分类预测效果,适用于复杂多变的列车运行环境。
3.3 车载设备故障预测结果分类
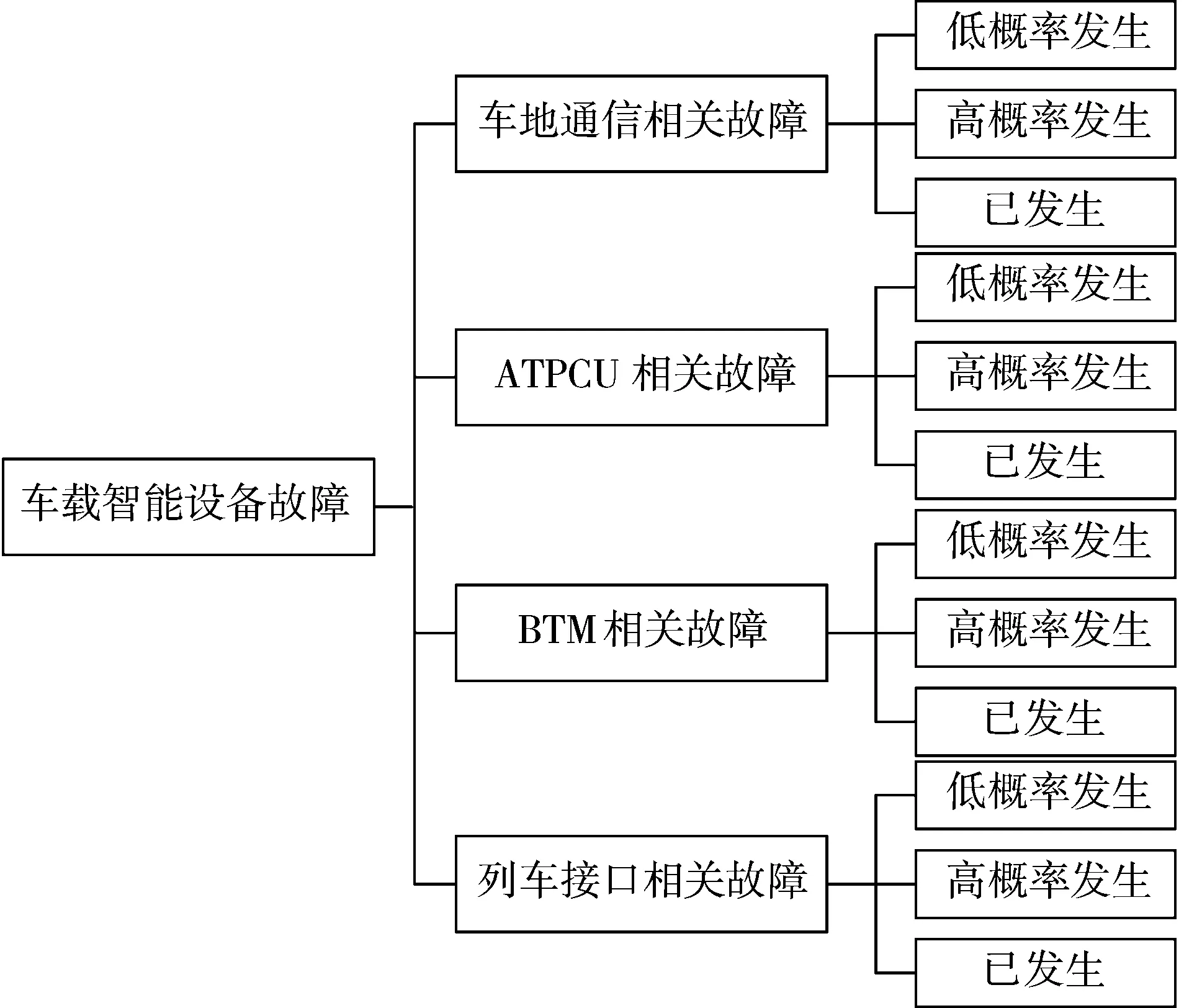
图3 车载设备故障预测图
在列车运行过程中,车载设备所产生的主要故障有:车地通信相关故障(47%)、ATPCU相关故障(24%)、BTM相关故障(13%)、列车接口相关故障(5%)及其他故障(11%)等。现将各类故障结果分为低概率发生、高概率发生、已发生这3类,可表示为图。通过对故障预测结果进行分类,可以使管理人员实时监控车载设备运行状况,更加准确地定位故障位置,以便高效地处理故障。故障预测结果分类如图3所示。
3.4 模型总体架构
基于车载流数据的实时故障诊断方法,需要构建数据采集、传输、处理及显示的软硬件系统。其系统主要由3个部分组成:车载设备数据采集器、服务器和客户端。工作的基本原理为车载设备采集数据后,上传到服务器,服务器根据已构建好的基于CVFDT算法的模型和车载信息流数据进行预测以判断列车各设备运行状态。最后将预测结果传送到客户端,供工作人员实时监控和维护车载设备。
1)车载设备数据采集器。
通过统一的数据接口,将各设备采集到数据进行汇总后(主要有车载模块数据、MVB总线数据和JRU司法记录单元数据),通过移动通信网实时传送到服务器。要求车载数据采集设备具备安全、稳定、可靠等特点。
2)服务器。
负责接收和保存车载设备传输的数据,同时将实时到达的流数据进行预处理后,输入CVFDT模型中,进行训练、分类,以实时预测各设备故障发生的可能性。同时实时保存其预测结果。用户可以从客户端上下载设备所采集到的历史数据和设备故障预测结果。
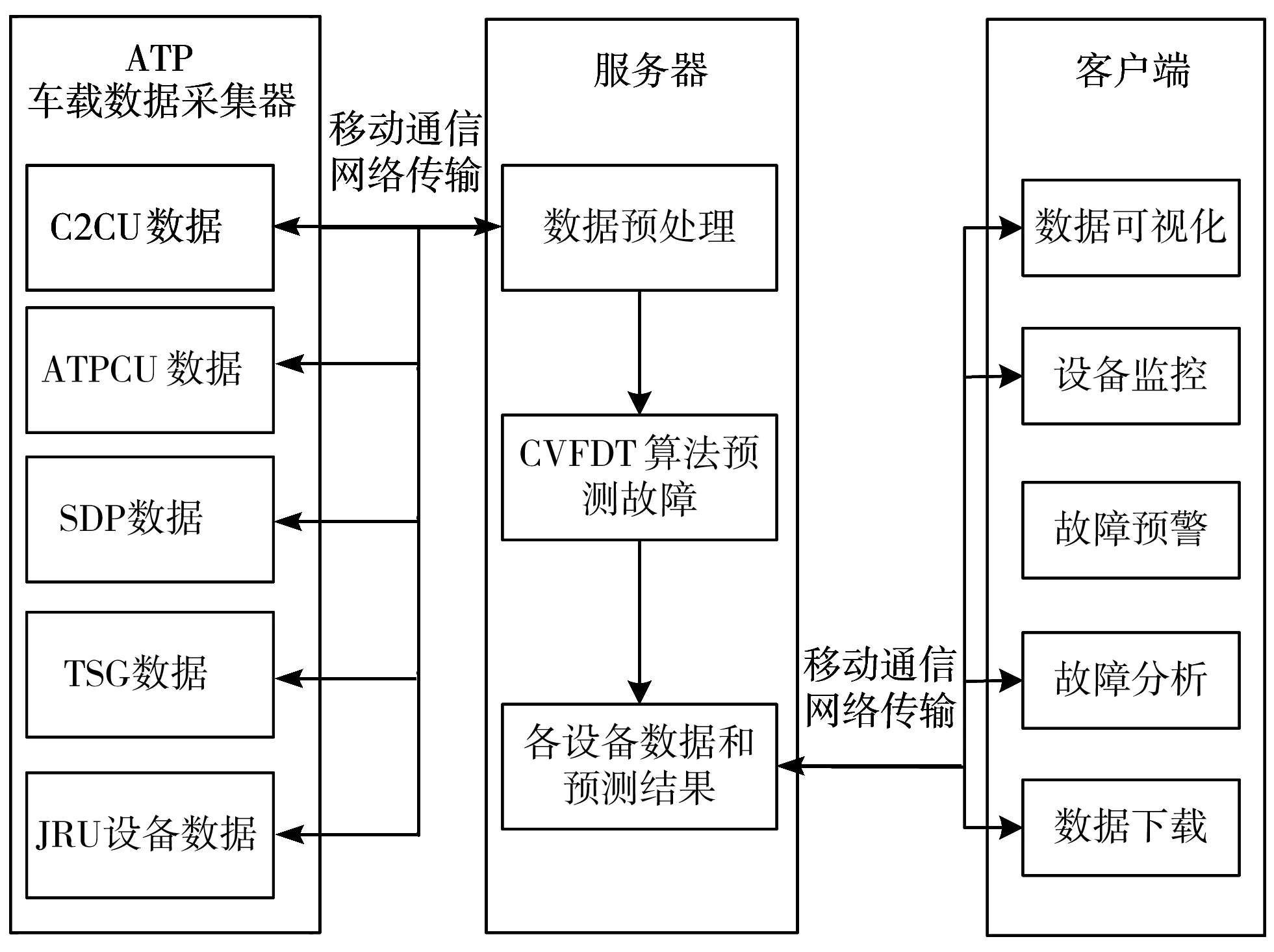
图4 系统流程原理图
3)客户端。
用户通过客户端软件来实时监控车载设备各部件的工作状况,实时查看各部件发生故障可能性的大小,对于当前可能高概率发生的故障,设立系统预警机制,及时通知用户进行排查和消除,以避免故障的发生。针对已发生的故障,可查看与故障相关的工作部件的历史车载数据流,并可供下载,进行后续系统的分析。
系统的基本流程设计原理如图4所示。
3.5 实验分析
本次实验采用了2016—2018年度CTCS3-300T型车载设备历史数据中抽取的共11583条实时流数据进行测试,将其分为训练集与测试集。
训练集包含:1)列车各车载设备正常运行所产生的部分流数据7489条;2)列车发生车地通信相关故障、ATPCU相关故障、BTM相关故障以及列车接口等相关故障前后1 min内,车载设备的部分流数据共计517条。
测试集包含:1)列车各车载设备正常运行所产生的部分流数据3496条;2)列车发生车地通信相关故障、ATPCU相关故障、BTM相关故障以及列车接口等相关故障前后1 min内,车载设备的部分流数据共计321条。
本实验分别采用了常用的3种流计算分类算法(BP神经网络、朴素贝叶斯法(NaiveBayes)、CVFDT)进行车载设备故障预测准确率验证,通过7次调整训练集与测试集的数量,得到实验对比结果如图5所示,其平均准确率分别为BP神经网络90.89%、NaiveBayes 87.78%、CVFDT 94.13%。
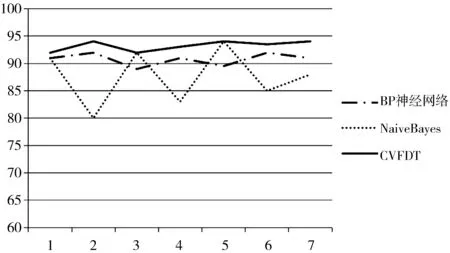
图5 车载设备故障预测模型分类实验
实验结果表明,基于流数据的CVFDT算法车载设备故障预测模型相较于其他算法准确率高,可以较好地监控和反馈车载设备工作状况,辅助工作人员诊断故障和维护设备,提高工作效率,保障铁路车载设备的正常运行。
4 结束语
随着高速铁路的迅速发展,对列控设备自动化、设备故障智能诊断和预测的要求不断提高。本文通过车载设备数据特征分析,采用CVFDT决策树算法,对车载模块流数据、MVB总线流数据和JRU司法记录单元流数据进行机器学习,一方面实现对不断到来的流数据准确分类,实现车载设备故障精准定位,提高诊断效率;另一方面对车载设备故障发生概率进行预测,实现故障“事前排除”和防护,降低车载设备对高速铁路运营安全和运输效率的影响。然而,由于决策树训练类别不足,流数据分类中并未考虑不同故障间的关联关系及故障间的交互影响程度。因此,在未来的研究中还需要提高对交互故障和关联故障的诊断有效性。
