基于优化残差网络的多模态音乐情感分类
2020-12-31李晓双韩立新李景仙周经纬
李晓双,韩立新,李景仙,周经纬
(河海大学计算机与信息学院,江苏 南京 211100)
0 引 言
听音乐是人们日常管理压力和调节情绪的最常见方式之一,认知科学家Changizi[1]认为音乐带有情感是因为人们将内容和节奏联系起来从而引起的自身的情绪。换言之,音乐是一种情感介质,传递了人类真实的感受。因此,音乐存在特定的情感标签,显式的情感标签有利于听众在适当的时间、地点快速地选择想听的歌曲。通过对国内外各大音乐平台的检索,发现多数音乐曲目缺少情感类别标签,即使已存在的情感标签也往往依赖于人为手动的添加标注,这种情感分类方法极不标准且缺乏可信度。而随着数字存储技术和移动互联网的发展,数字音乐也出现了严重的信息过载问题。因此音乐情感的自动分类也成为了当今研究的热点之一,在音乐检索和推荐等方面有着广阔的应用前景。
目前在音乐信息检索领域,公认的音乐情感模型[2-3]有Hevner情感模型和Thayer情感模型。Hevner情感模型主要包括8类情感,在空间中离散分布,存在特定的环形关系;Thayer情感模型则从Stree和Energy这2个维度将音乐的情感分为4类:生机勃勃、焦虑、令人满足和沮丧。基于本文的研究内容和使用情景更符合二维的情感模型,因此采用Thayer情感模型并在其基础上做出适当的改进,将音乐情感分为4类:快乐(Happy, H)、平静(Quiet, Q)、悲伤(Sad, S)和愤怒(Anger, A),进行音乐情感分类的研究。
基于传统机器学习的音乐情感分类研究中音乐情感的特征提取往往与分类器构建分开设计,想要获得较高的分类准确率,不仅要提取出更为全面的特征表示,同时还要构建准确高效的分类器。国内外众多学者在这2个方面做出了不同的尝试工作并取得了不错的成果。对于特征提取,目前研究人员对音频数据提取的表示特征主要包括:中心距(Central Moments)、过零点(Zero Crossing Rate, ZCR)、节奏(Tempo)、梅尔倒谱系数(Mel-Frequency Cepstral Coefficients, MFCC)、色度特征(Chroma Features)、频谱中心(Spectral Centroid)等;分类器的设计也是多种多样,常用的有基于支持向量机(Support Vector Machine, SVM),基于逻辑回归(Logistic Regression, LR)、基于K近邻(K-Nearest Neighbour, KNN)等[5-6]。由于音乐音频具有高维、多维、易变性等特点,基于传统机器学习的音乐情感分类方法的准确率十分依赖于特征提取的优劣,该类方法的自动情感分类效果不准确,可信度较低,有很大的提升空间。
随着深度学习的发展,越来越多的研究学者利用深度神经网络来有效地提取音频特征从而实现音乐的情感分类[6-7]。Han等人[7]初步利用深度神经网络从原始的音频数据中提取了高级特征表示,并验证了深度神经网络在语音情感识别中的有效性。Hu等人[9]利用卷积神经网络提取音频特征来训练音频数据,音频情感分类的准确率得到了较大幅度的提升。
目前国内外对音乐情感数据集的构建还处于起步阶段,多数学者的研究是在自己构建的小型数据集上学习,在这领域缺少可信度较高的公共音乐情感数据集。针对这一问题,本文利用Free Music Archive (FMA)数据集的构建思想[10],收集整理了各大音乐平台上免费、合法的音频数据,并结合FMA的部分数据最终构建EMA(Emotion Music Archive)数据集(EMA数据已共享到https://pan.baidu.com/s/INAaqJahoKUvaYEAQQwoDuw),并邀请数位专业音乐人士对EMA数据进行人工的情感标注。
本文采用卷积神经网络,从音频的可视化角度去研究音乐的情感分类。首先利用多模态翻译将难以提取特征的音乐音频模态转换为易于操作的图像模态,在较大程度上保留了音频原始信息,大幅度减少了人工成本;同时为了解决音乐情感公众数据集缺失的问题,在FMA数据集的基础上构建了特定的音乐情感数据集EMA;此外,为了尽可能多地保留图像特征点参与计算,减少信息流失,本文基于深度残差网络对残差块进行了优化改进,使其更适应本文研究的细颗粒度情感图像的分类;最后针对常用的Softmax分类器函数存在类内分离、而类间紧凑这一弊端,引入改进的Center loss函数的变体来缓解这个问题。实验结果表明了本文优化改进后的模型的有效性和适应性。
1 多模态翻译
多模态翻译是多模态机器学习中的一个核心技术,将数据从一种模态转换(映射)到另一种模态,用不同的模态生成相同的实体[11],可以优化更好的目标。在语音识别与合成、视觉场景描述、跨模态检索等领域都有着十分重要的应用。
本文利用多模态翻译学习,将音乐的音频模态转换为语谱图的图像模态,使得音乐音频以图像的形式进行处理。语谱图[12]是一种时域频域分析图,如图1所示,横轴代表时间,纵轴代表频率,灰色的浓淡表示声音能量(频率分量),利用二维图像来表达三维频谱信息,综合了音频时域分析和频域分析的特点,能够表示音频随时间变化带来的频率和声音能量的动态变化。目前语谱图已经成为音频特征分析的重要表达方式,让音频数据有了更简单紧凑的表示形式。

图1 音乐片段的语谱图
本文构建使用的EMA数据集选取了每首曲目中间的30 s(FMA数据集的转储方式)作为该曲目的代表。同时为了简化其音频表示,将信息缩减至更容易管理的水平,将这30 s的音频数据分割为一个个相同时间的片段,作为代表该曲目的独立样本。
对分割后的音频片段采用短时傅里叶变换进行音频分析和模态翻译。短时傅里叶变换的原理是通过移动代表一个时序局部化的窗函数来计算不同时间节点的功率谱,将每帧数据图堆叠从而得到语谱图。同时利用奈奎斯特-香农采样定理将44100 Hz的采样率重建至22050 Hz,一方面消除了可能包含在此频率上的噪声;另一方面采用更低的压缩率保证使用所需的全部信息。
2 优化的残差网络模型
2.1 深度残差网络
深度神经网络在训练过程中会因为网络层级的加深出现准确率饱和甚至是退化的现象,这是由于深层次的网络训练会出现梯度消失或梯度弥散。针对这一问题,He等人[13]提出了基于残差的深学习框架——深度残差网络(Deep Residual Network,Deep ResNet),它能够通过增加网络深度提高准确率,同时采用残差块进行跳跃连接构建网络结构来解决性能退化问题,其基本思想是在构建卷积神经网络时通过加入捷径连接(shortcut connections)支路构成基本残差学习单元,利用堆叠的非线性卷积层来拟合一个残差映射(residual mapping)。深度残差网络作为一种极深的卷积神经网络框架,在精度和收敛等方面都展现了很好的特性。ResNet由很多个残差单元组成,每个残差块如图2所示[14],可以表示为:
yl=h(xl)+F(xl,Wl)
(1)
xl+1=f(yl)
(2)
h(xl)=xl代表一个恒等映射,在训练的前向和反向传播阶段,信号可以直接跳跃传递,既没有引入新的参数,也没有增加计算复杂度,却使训练变得更加简单,从而解决深层网络难以训练和性能退化的问题。

图2 残差网络的残差块结构
图3所示的2种不同的残差块结构[14]分别适用于浅层的ResNet网络(左图),如ResNet18/34,和深层的ResNet网络(右图),如ResNet50/101。一般称整个结构为一个“积木块(building block)”,特别又将右图的结构称为“瓶颈设计(bottleneck design)”,这2种设计结构具有相同的时间复杂度。
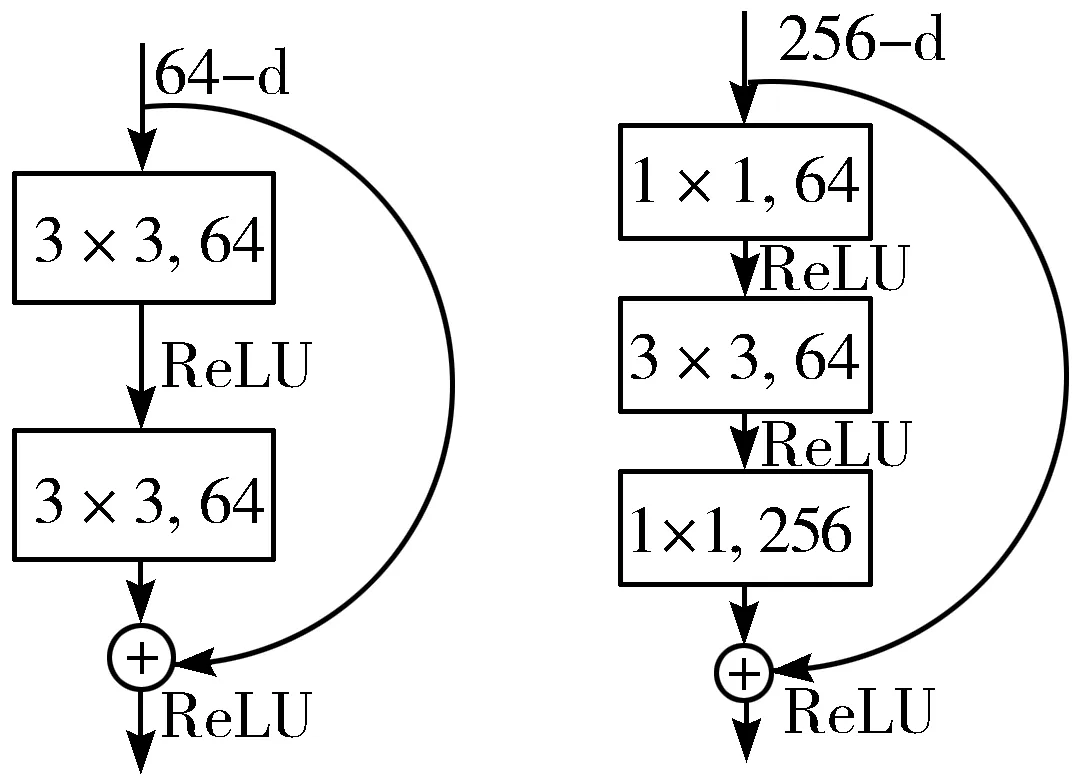
图3 2种不同形式的残差块跳跃结构图
考虑到实验配置和计算能力,最终选择了ResNet50网络结构,瓶颈架构使用一个3层的堆栈,如图3中右图所示,第一和第三层的1×1的卷积层用来恢复维度,中间3×3的卷积层成为维度小的瓶颈,目的是为了降低参数的数目,相较于左图所示结构,参数数目相差了近16倍。
2.2 优化残差块结构
随着ResNet网络模型的深度使用,许多研究者对其网络构架进行了不同的优化调整,使之适用于不同的实用场景。比较成功的有ResNetXt和DenseNet架构。
ResNetXt是Xie等人[15]提出的关于ResNet网络模型的一种变体,主要思想是在原始的ResNet模型的基础上引入了Cardinality(基数),这一超参数的引入有效地减少了其他超参数的调整工作,在文中作者通过实验验证了ResNetXt架构有更强的适应性,训练时间得到了大幅度的缩减。
DenseNet是Huang等人[16]提出的一种深度优化的新框架,借鉴了ResNet架构快捷连接的思想,但DenseNet架构将所有层直接相连,后续的输入由前序所有的特征映射组成,最终通过深度级联融合。使用DenseNet架构的准确率得到了明显的提升,但实际应用成本较高。
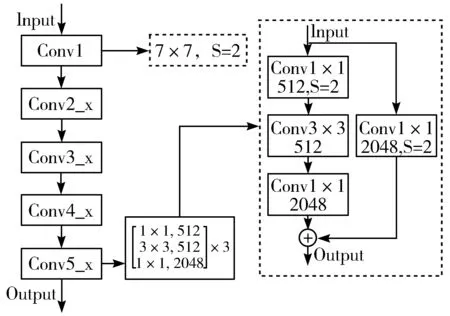
图4 原始ResNet50网络结构示意图
本文参考了文献[17]中ResNet结构的分解图,在ResNet50网络模型的基础上进行优化改进,使之更适合本文研究的内容。首先给出原始的ResNet50网络架构示意图,如图4所示。
ResNet50模型常用的是一个7×7的卷积核进行网络输入,计算量较大;同时,当ResNet50中残差块的输入维度与输出维度不相同时,常用的方法是用一个步长为2的1×1的卷积核增加维度,使输入和输出维度相同,如图4中虚线框中内容所示。但对于细颗粒度图像的分类问题,选用步长为2的卷积层时会丢失大部分的冗余信息,3/4的特征点没有参与计算,这样会对最后的计算结果产生不良的影响,在一定程度上降低了特征信息的可信度。
本文从上述2个问题出发,对该模型进行了优化改进,改进后的ResNet50网络架构如图5所示。
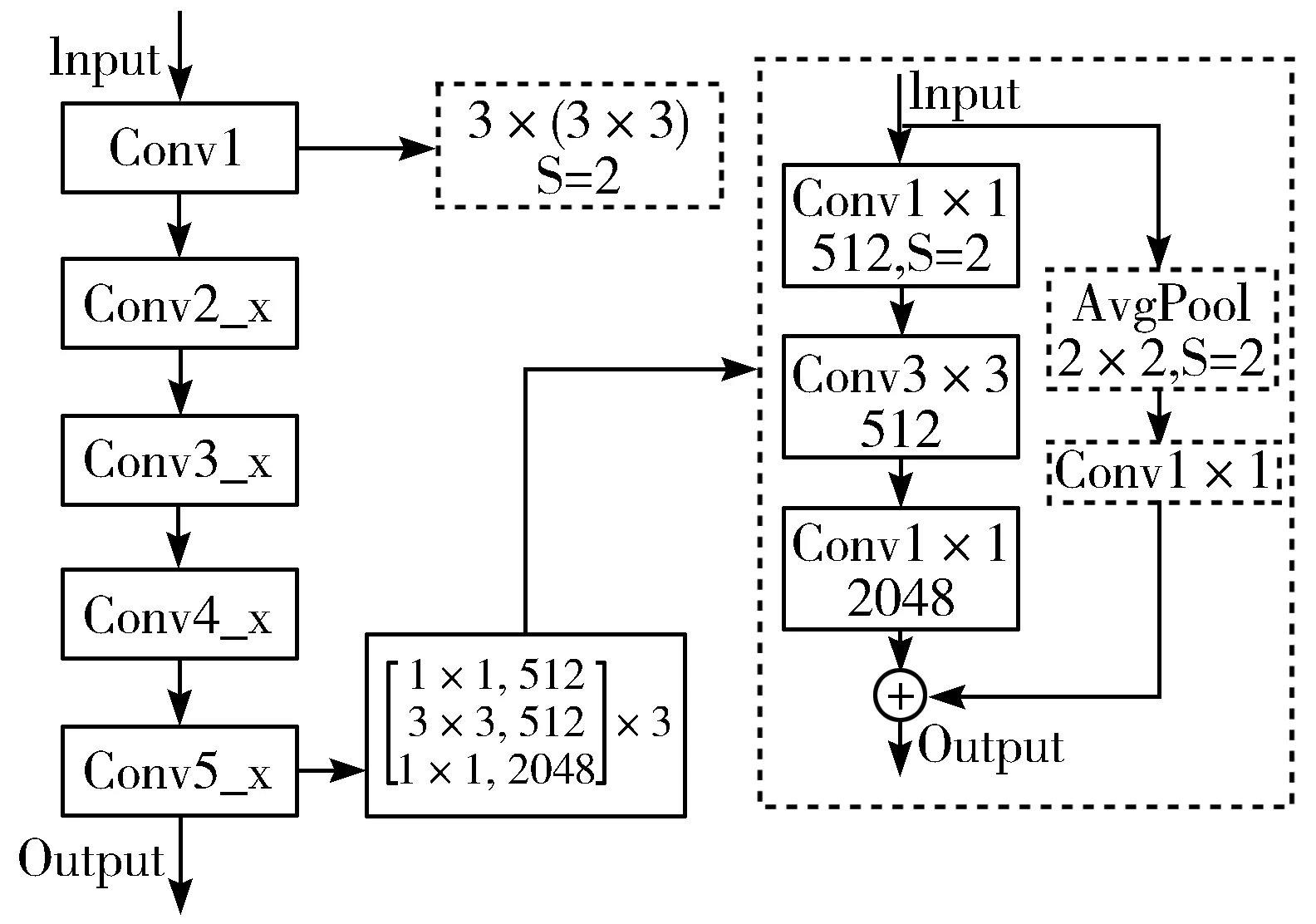
图5 优化后的ResNet50网络结构示意图
首先,借鉴Inception v2思想将部分的7×7的输入卷积核替换为3个3×3的小尺寸卷积核,在保持卷积核感受野相同的同时,减少参与计算的参数,从而减轻计算量。对于一个7×7的卷积,所用的参数总数为49 channels,而使用3个3×3的卷积所用的参数总数为27 channels,可以显著地减少参数的数量,缩短计算时间。为了尽可能多地保留参数点参与计算,在残差块的快捷路径上将步长为2的1×1的卷积替换为步长为1的1×1的卷积,同时为了保留梯度,使输入输出维度一致,在这个卷积层前添加一个步长为2的2×2的均值池化层。这样的改进虽然也会丢失部分信息,但相较于步长为2的1×1的卷积层,该方法先经过选择再丢失冗余信息,每个特征点都参与了计算,这样能保留大部分的特征点信息,在一定程度上弥补原始结构信息流失的问题。
3 改进的Softmax分类器
3.1 Softmax分类器
在使用深度学习实现多分类的使用场景中,Softmax函数常常被许多研究者使用。Softmax函数可以将提取的特征输入映射到[0,1],并且通过归一化操作保证了和为1。Softmax的形式为:
(3)
其中Wyi和byi分别是对应于类yi的最后一个完全连接层的权值和偏差,n是类别数目。对于多分类问题的目标函数常选取交叉熵函数,即:
(4)
直观上看,标准Softmax函数用一个自然底数e先拉大了输入值之间的差异,然后使用一个配分将其归一化为一个概率分布。在分类问题中,希望模型识别正确的类别的概率接近1,其他的概率接近0,如果使用线性的归一化方法,很难达到这种效果,而Softmax函数通过先拉开差异再归一化,在多分类问题中优势显著。在卷积神经网络的分类问题中,常常使用one-hot编码器对预测的类别进行处理,目前通用的Softmax函数是将每个输入x非线性放大到exp(x),形式为:
(5)
通过公式(3)~公式(5)可知,Softmax函数会将不同的类别特征分离开,不同类别之间会存在一定的距离,但接近一定程度后距离就保持不变,所以往往会出现同一类别之间的距离有可能大于不同类之间的距离。这一问题在人脸识别领域普遍存在,同时对于本文研究的音乐情感4分类来说,训练样本有限,最终的目的是对任意未知的音乐曲目进行情感分类,实际的测试集会是无穷大的概念,上述问题同样存在,所以需要对Softmax分类函数进行改进,在Softmax函数保证情感类别可以区分的同时,还要考虑更多的未知数据特征,尽量保证训练时提取的特征向量同类之间更加紧凑,不同类之间更加分散。
3.2 引入Center loss函数变体
为了保证分类模型具有类内聚敛,类间分离这一特性,近年来也有一些学者对Softmax做出了相应的改进[18-21],比较常用的有Angular-Softmax、Center-Softmax。
Angular-Softmax的思想是将样本特征之间的分离特性转换为角度边界学习,具体公式为:
(6)
其中:
Lθ=‖Wyi‖‖xi‖cos (θyi)+byi
(7)
文献[19]中提到将其权值归一化,令‖W‖=1,并使偏置为0,最后通过人脸识别实验分析验证了该函数的有效性。但这些特征仍然不具有很好的辨识性,随着数据量的增大,提升效果有限。
Center-Softmax的思想是最小化类内间距,通过引入Center loss来控制特征中心,具体公式为:
(8)
其中,cyi代表类别yi的特征中心,它会随着特征的变化而变化,m代表mini-batch的大小,来更新特征中心。针对本文研究的情感图像属于细颗粒度的图像分类,所以希望最终分类模型类内聚集、类间分离。而Center-Softmax只考虑了类内中心化,还有改进的空间。
本文考虑:1)训练样本到类别中心点的距离最短(借鉴Center loss思想) ;2)训练样本与其非对应类别中心的距离之和最大。对Center loss函数做出改进,引入非对应类的距离,在控制同类中心点的基础上,尽可能保证不同类中心点之间的距离最大。改进后的Center loss函数公式为:
(9)
分母加1是为了防止分母出现为0的情况。本文改进后的分类函数L_Center_Softmax的最终表示为:
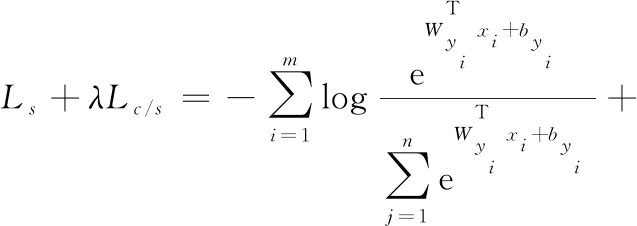
(10)
改进的损失函数将中心损失和类间距离相结合,可以提高特征的可分辨性,保证了特征类内间距缩小的同时增加不同类间的区分性,增强细颗粒度图像分类的适应性。
4 实验结果与分析
4.1 实验环境
本文实验是在服务器上运行完成的,其配置为:CPU为Intel(R) Xeon(R) CPU E5-2660 v4;主频为2.00 GHz;内存32 GB,同时借助Tesla V100 PCIe 32 GB显卡进行加速处理(V100支持16位浮点型的模型训练),使用开源深度学习框架Pytorch和开源视觉库OpenCV3完成本次实验。
4.2 数据集和参数设计
本文构建的原始EMA数据集包含1200首自己收集整理的合法的英文曲目和筛选的FMA数据集的部分曲目共计2000首音乐,选取每首音乐中间的30 s,并分割为一个个相同时间的片段,通过模态翻译转换为语谱图(PNG图),每张图谱图片段的大小设置为224×224×3(3通道),充分利用音频数据的短模式特性。EMA数据集包含宣泄A、快乐H、安静Q和悲伤S这4类情感,部分数据集如图6所示。

图6 部分EMA数据示意图
本次实验采用十折交叉验证方法,随机将4类情感数据等比例分成10份,每次选取一份作为测试集进行试验,最后通过求取10次实验的平均学习准确率作为最终的交叉实验结果。
实验中学习率初始化设置为0.01,同时采用指数衰减方式依次迭代递减;使用SGD作为该实验的优化算法,batch size=128;对于深度网络卷积操作之后,使用BatchNormalization操作,并以0.5概率进行Dropout。
4.3 音频时间段选择
通过查阅相关文献,不同的研究者对音频片段的长度选择有所不同。本文将对不同长短的时间段进行实验对比,从而选择最适合本研究的音频时间段,并以此为基础进行后续对比实验。
本节在原始的ResNet50模型和本文改进后的ResNet50模型上分别进行实验,基于EMA数据集分别选择1.5、3、5、7.5 s的音频段的数据进行对比。同时考虑时间段长度与数据样本量成反比,而样本数量越多、覆盖越全面,学习效果越好。所以综合考虑时间段与样本数量的关系,在2000首30 s的音频数据上进行测试。时间段和样本数量之间的关系如表1所示。

表1 时间段长度和样本数量之间的关系
2种分类模型对不同时间段图像的分类准确率如表2所示。

表2 不同时间段的分类准确率
根据表2的实验结果分析可知,随着时间片段长度的增加,模型分类的准确率呈上升趋势,采用长时间段的音频数据可以得到更好的情感分类效果。但由于EMA数据集的数据量限制,采用较长时间段的音频数据会大幅度减少训练样本数量,如表1所示。通过分析表1和表2的实验结果可知,采用5 s的时间段的学习效果最好。
综合考虑时间段长度和数据样本量,选择5 s的时间段作为本实验音频信号的划分标准,并以此为基础进行后续对比实验。
4.4 对比实验
在对比实验中,本文选择了几种具有代表性的算法在EMA数据集上进行实验比较[22]。
其中SIFI+BOG+SVM[23]是指利用了SIFT特征检测和BOW+线性核函数的SVM进行音乐语谱图的情感分类,直接借用开源接口完成;ResNet50_V是指本文优化残差块后的ResNet50网络模型;L-center-Softmax是指用改进后的分类器函数。取10次测试结果的平均值作为最终的结果,最终的对比实验结果如表3所示。
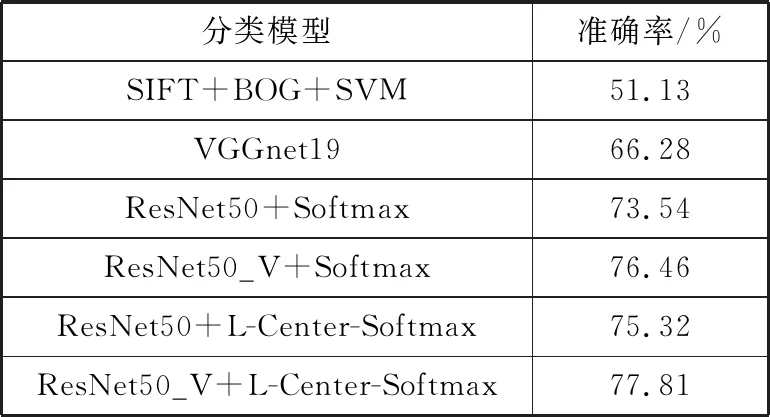
表3 分类模型实验对比结果
根据表3的实验结果可以看出,ResNet50相较于传统的机器学习方法和浅层的网络模型,在图像分类上有显著的成果,网络层次的加深带来分类精度的大幅度提升;优化后的ResNet网络在本文研究的问题上也有小幅度的提升,实验结果也比较稳定,相较于原始的ResNet50网络模型分类准确率提升了2.92个百分点,表明了优化后的残差结构的有效性;替换为L-center-Softmax分类函数后,模型的分类准确率也有小幅度的提升,说明改进传统的Softmax函数也有着积极的效果;实验中准确率最高的是优化了网络结构并替换了分类函数的ResNet50_V+L-Center-Softmax模型,正确率为77.81%,相较于传统的机器学习算法,分类准确率提升了26.68个百分点,相较于原始的ResNet50模型,分类准确率提升了4.27个百分点。
同时为了进一步探究本文改进的ResNet网络模型对音乐情感状态的分类情况,衡量分类模型的性能,实验计算得出原始的ResNet50模型与本文改进后的ResNet50模型的情感4分类混淆矩阵,如表4所示。
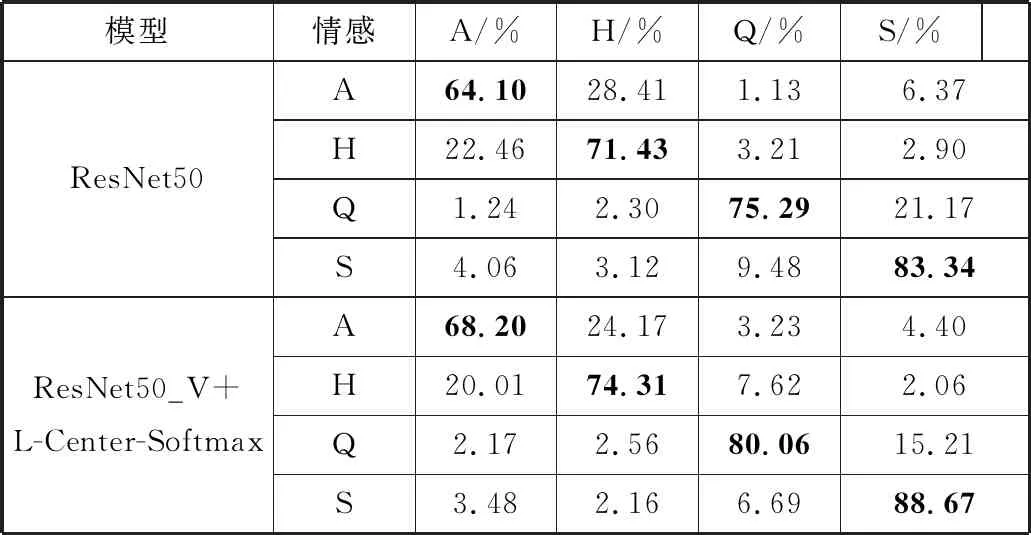
表4 情感分类混淆矩阵
从表4的分类混淆矩阵可以看出无论是原始的ResNet50模型还是本文优化后的模型,对安静和悲伤2种情感的识别率最高,改进后的ResNet50模型对2类情感的分类准确率分别达到了80.06%和88.67%,其余2种情感的识别准确率也达到可以接受的程度;同时实验发现愤怒和快乐2种情感最容易被混淆;优化后的ResNet50模型相较于原始的ResNet50模型在愤怒和悲伤2种情感的识别率有较大幅度的提升,对悲伤的情感识别准确率提高了5.33个百分点。通过分类混淆矩阵分析可知本文优化改进后的模型的稳定性,有效地提高了音乐情感分类的准确率。
5 结束语
本文提出了一种优化的深度残差网络模型,在音乐情感分类方面达到了较好的分类效果。首先,利用模态翻译的思想将音乐的音频模态转换为图像模态,保留了足够多的信息,使研究方向从音频识别转变为图像分类,更加方便简单;其次,本文的研究属于细颗粒度图像的分类,对原始的ResNet50模型进行了优化,使用更小的卷积核代替原始的输入卷积核从而减少了计算量;同时在残差块跳跃连接中先经过选择再丢弃冗余信息,保留了大部分的特征点来参与计算;最后针对Softmax分类器存在类间不聚集的弊端,在引入Center loss函数控制类别中心的基础上,同时增加类间的区分性,提出了一种新的分类函数L-Center-Softmax。通过实验,综合考虑音频划分的时间段长度与数据样本量的关系,最终选择将EMA数据集按照5 s的时长进行分割,最终构建数据样本。不同算法的对比实验结果表明,通过优化残差结构、改进分类函数的深度残差模型对音乐情感分类的准确率有积极的提升效果,最后的分类混淆矩阵也表明了本文优化后的模型的稳定性。
本文的工作仍存在一些不足之处:1)数据集。由于缺少公众的音乐情感数据集,自己构建的数据集的样本存在明显的不足,不能充分利用深层次网络模型的学习能力。2)仅采用单模态数据,容易产生数据缺失或存在较大噪声等问题,在实际使用过程中很容易受到其影响,所以通过多模态融合来提高音乐情感分类的准确率也是后续的研究重点。
