利用机器学习方法对灾难生命支持课程NDLS培训效果进行分析预测
2020-12-31章鸣嬛潘曙明汤璐佳
郭 欣,陈 瑛,章鸣嬛,张 璇,潘曙明,汤璐佳
(1.上海杉达学院信息科学与技术学院大数据分析与处理研究中心,上海 201209;2.上海交通大学医学院附属新华医院,上海 200092)
0 引 言
根据世界灾难流行病学研究中心数据,自1995年来,全世界灾难发生频率增加了一倍,危害程度也在不断升高[1-2]。2019年底新型冠状病毒(2019-nCoV)肺炎疫情再次侵袭华夏大地,中国在公共卫生领域投入了大量人力、财力与物力,取得了一定的成效,疫情使人们认识到必须建立健全应急体系,形成应急储备能力,才能够确保及时、高效地应对各类突发事件,将事件影响降到最低。2015年美国灾难生命支持(National Disaster Life Support, NDLS)课程引进中国。经过2015—2017年的在地化改革后,NDLS课程在中国落地,截止2019年底共进行了68期培训,参训人数累计1740余人,但该课程是否符合中国应急培训的实际情况,是否得到中国学员的认可,如何提高培训质量仍有待探讨。
机器学习是一种重要的数据挖掘方法,在许多领域得到广泛应用,可分为监督学习和非监督学习。2种学习的主要差别在于用于建立模型的数据除带有特征(feature)外是否还带有标签(label)或者说是否有确定的结果[3],监督学习有确定的结果,非监督学习则无。近年来,国内外越来越多的研究者尝试将机器学习方法应用于预测分析研究。Zhang等[4]采用梯度提升分类器对大学生主观幸福感进行预测。徐铖斌等[5]采用随机森林法,针对杜克大学外部感染控制监测网登记的结直肠手术病例历史数据集,进行结直肠手术部位感染预测分析。章鸣嬛等[6]使用Logistic回归和决策树2种机器学习分类算法进行建模分析影响乳腺癌5年预后的因素。高英博[7]基于SVR、LSTM和XGBOOST算法建立建筑能耗预测模型,对建筑能耗预测方法进行研究。可见,利用机器学习方法构建模型是进行预测分析的常用方法。
在众多机器学习方法中,Apriori关联规则分析和决策树颇受国内外研究者们的重视[8-13]。其中,Jhang等[8]利用Apriori算法对不同类型痴呆患者的护理需求进行分类研究。Salas等[11]应用决策树构建了一种新的资本流动突发事件预测模型,该模型能够准确估计全球未来的资本流动异常。Surucu-Balci等[13]运用决策树方法找出了社会化媒体的贴文特性,从而提高了利益相关者在集装箱航运市场上的参与度。本文通过将Apriori关联规则分析和决策树相结合的方法实现NDLS培训效果预测。运用Apriori关联规则算法先根据样本数据建立频繁项集,再依据频繁项集产生关联规则,从而找到影响学员培训效果的关键因素。由于关联规则不能直接用于预测,后续使用决策树模型对培训效果进行预测分析,并根据决策树提取的规则验证Apriori关联规则的结论是否正确。最后将这2种建模方法的结果与利用分类回归树(Classification and Regression Tree, CRT)算法建模的结果进行对比,找出对NDLS培训效果影响最大的若干因素,为改善NDLS课程培训方法、提高培训质量提供参考。
1 数据采集及预处理
1.1 数据采集
选取2018年6月—2019年12月期间参加NDLS培训的650名学员的基本信息、学习情况以及满意度调查信息作为数据来源。这些信息均源于课题组自主开发的“NDLS培训信息采集系统”,在该系统中设计了问卷调查和测试功能,学员在参加培训前和培训后均需参加问卷调查和测试。通过采集最终得到的学员培训数据如图1所示。
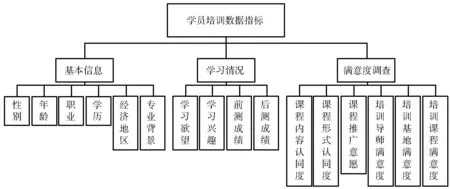
图1 学员培训数据
1.2 数据预处理
本文数据预处理的流程如图2所示,为后续分析预测做准备。

图2 数据预处理流程
1)数据整合。将采集到的学员基本信息、学习情况以及调查信息等多个数据文件,利用数据库技术,根据学员编号的唯一性,将多个表格的数据合并到一个表中。
2)数据清洗。前期采集的原始数据有些缺少数值,对于空缺严重的记录采用忽略的方法,如2018年参加培训的学员中有相当一部分没有填写培训后的调查问卷,考虑到数据完整性和准确率,将这些学员记录直接删除。对于其他个别空缺,采用人工填充空缺值的方法,填充所在属性的均值、中位数或众数。另外,将一些有明显错误和重复的数据进行纠错及去重。最终数据清洗后得到406条有效记录。
3)数据消减。为了缩小挖掘数据的规模,在基本不影响最终挖掘结果的前提下消减部分字段。本文原始数据共有16个字段,对这些字段进行单因素分析,发现“职业”与“专业背景”重复度较高,“课程推广意愿”与输出变量关系不大,将这2个字段删除,保留其余14个字段如表1和表2所示。

表1 选取的字段(数值型)
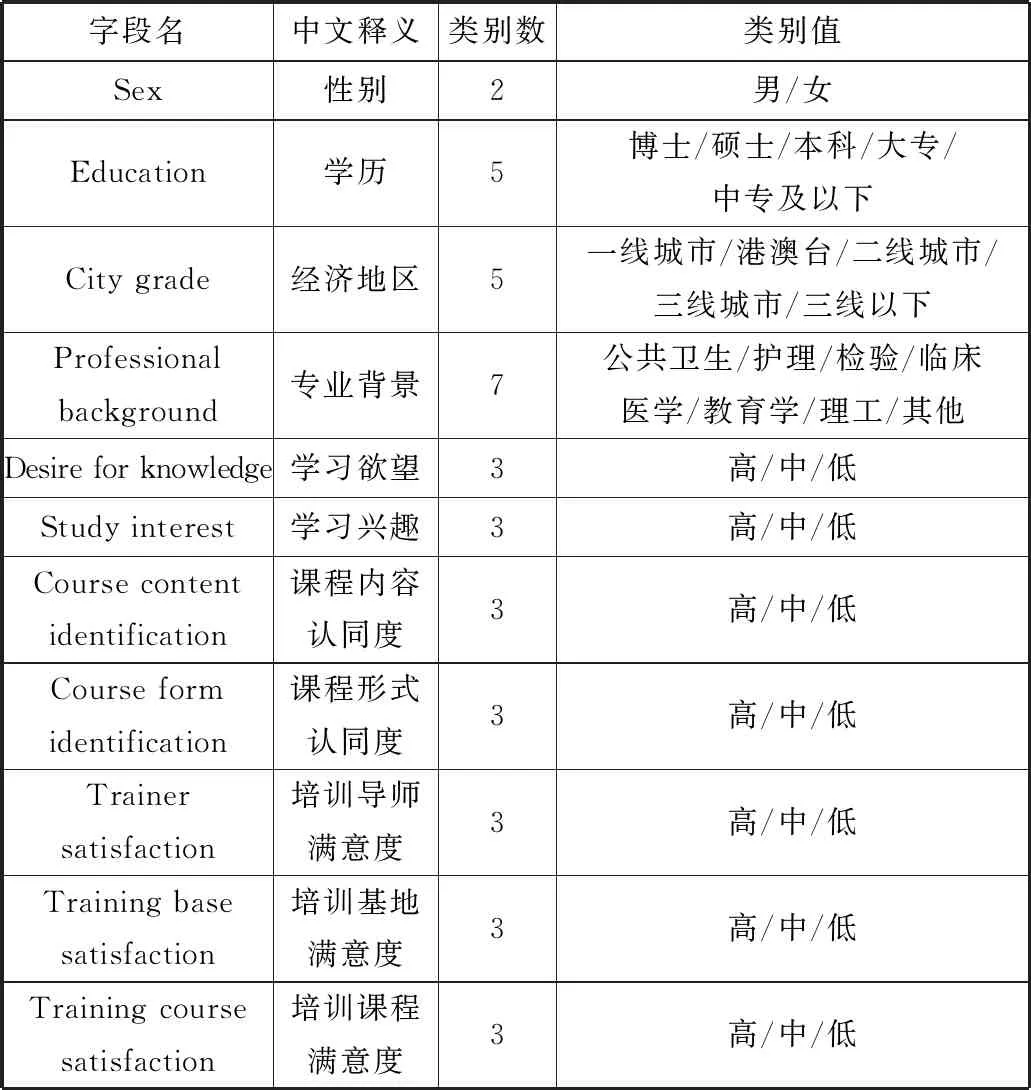
表2 选取的字段(分类型)
4)数据转换。本文使用的Apriori关联分析和决策树方法均要求变量为分类型字段,故此处的数据转换主要是对数据进行离散化操作。在划分前/后测成绩的等级时采用K-means聚类算法,将前/后测成绩分为优、中、差3个等级。年龄字段通过计算平均值进行划分,高于均值为年长,相反为年轻。学历、经济地区、专业背景3个字段的原始分类过于精细,故适当地进行合并。
2 建模方法及过程
2.1 建模方法
本文主要使用Apriori关联规则分析和决策树2种机器学习方法,建模流程如图3所示。
关联规则分析属于非监督式的机器学习方法,能够有效揭示数据中隐含的关联特征。Apriori[14]是影响较大的关联规则算法,利用迭代形式,循环处理:1)产生候选集;2)基于候选集计算支持度并确定频繁项集,直到生成最终的频繁K项集;3)从频繁K项集中产生所有简单关联规则,选择置信度大于用户指定最小置信度阈值的关联规则,组成有效规则集合,供用户决策分析[15]。
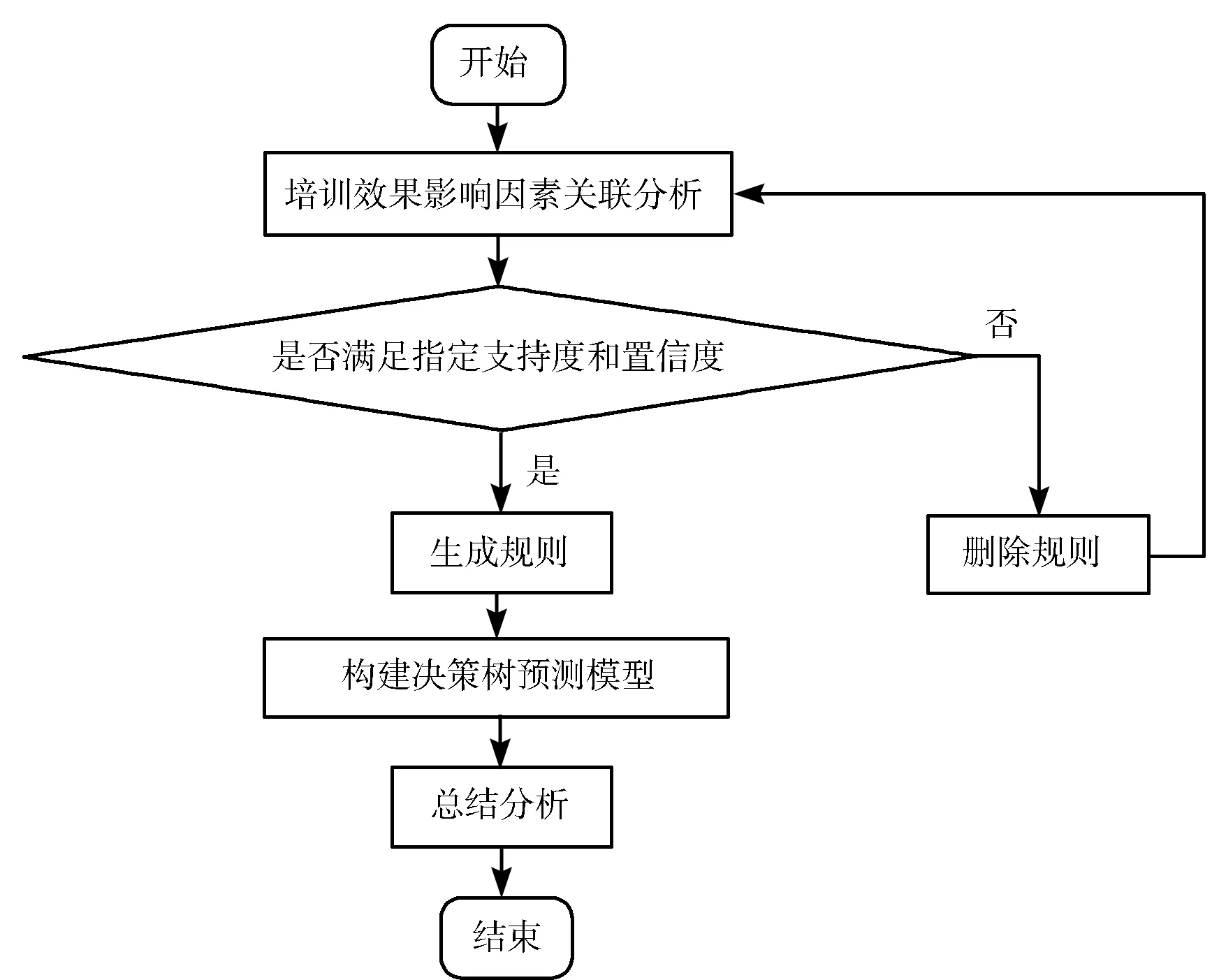
图3 建模流程
支持度用来测度简单关联规则的普遍性,表示项目X和项目Y同时出现的概率[16],数学表示为:
(1)
置信度是对简单关联规则准确度的测量,描述了包含项目X的事务中同时包含Y的概率,反映X出现的条件下Y出现的可能性[17],数学表示为:
(2)
决策树属于监督式的机器学习方法,其目标是建立分类模型或回归模型[15],树的生长和修剪是方法的核心[18]。决策树生长算法用来确定决策树的分支准则[19],本文采用C5.0算法,以信息增益率为标准确定最佳分组变量和分隔点。即选取信息增益率最大的变量作为根节点,并按其值划分样本数据集合,直到该变量只有一个值时停止划分,训练集中的其他子集则继续递归分割构造树的分支,当所有子集中的元组属于同一个类别时结束算法。信息增益率的数学定义为:
GainsR(U,V)=Gains(U,V)/Ent(V)
(3)
决策树修剪是为了解决“过拟合”问题,C5.0算法采用后修剪方法从叶节点向上逐层修剪[20]。
2.2 基于Apriori算法的NDLS培训效果影响因素关联分析
本文运用Apriori算法找出使学员培训效果为“优”的影响因素。建模工具采用SPSS Modeler,设最小支持度为10%,最小置信度为80%,后项变量为后测成绩,其他变量为前项变量,为了避免关联规则过于复杂,设置规则的最大前项数为5,挖掘分析后得到10条规则,提升度均大于1,均为有效规则。进一步提高准确率,将置信度的最小值调大为82%,对规则进行精简,最后得到有代表性的4条规则,见表3。
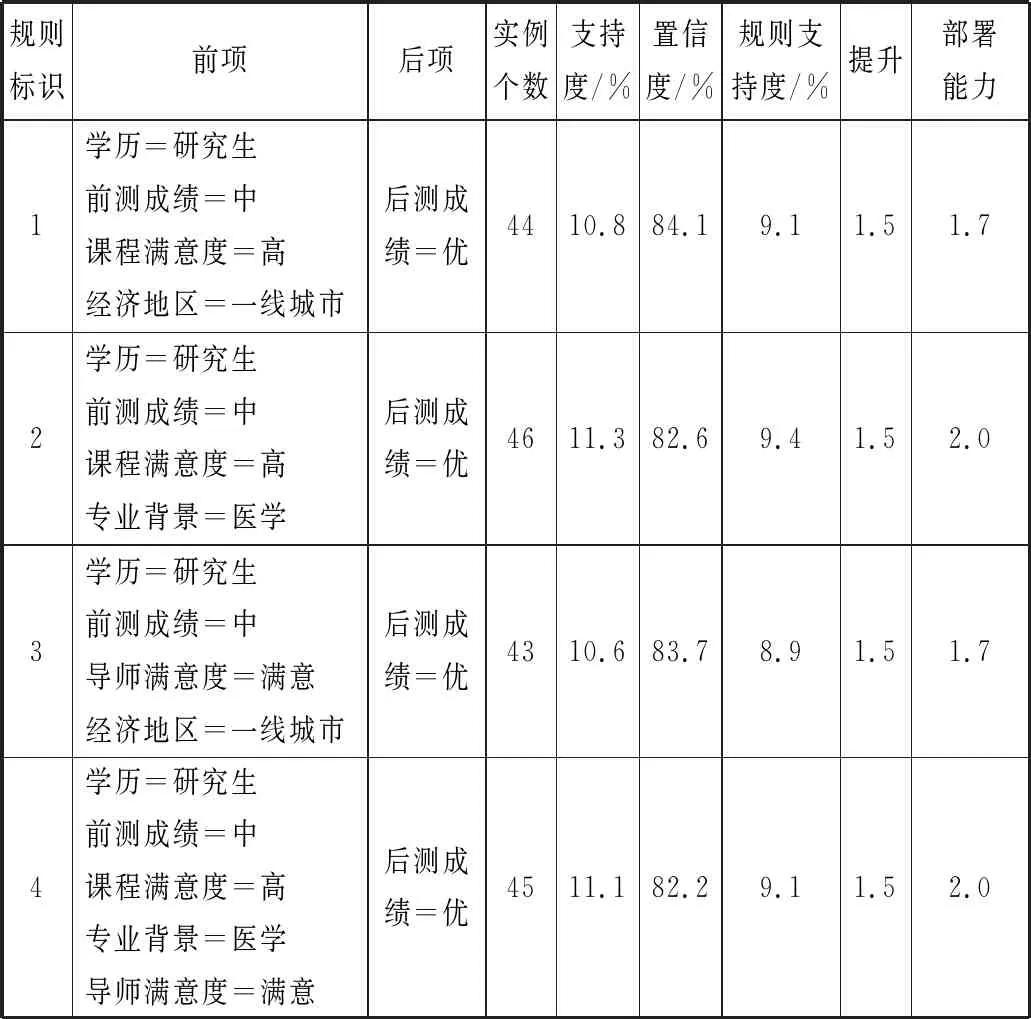
表3 精简后的关联规则表
分析表3中的规则可知,当学历为研究生,前测成绩为中时,学员培训后的成绩为“优”,这说明有高学历和学习基础较好的学员的培训效果更好。除了学历和前测成绩对培训效果有影响以外,学员对课程的满意度也很重要,只有课程的内容和设计满足学员的需求才能达到较好的培训效果。另外,来自经济较发达、综合实力较强的一线城市的学员更容易取得好的培训效果。最后还可以看出有医学相关背景的学员,以及对导师授课满意的学员学习效果较好。因此,在众多影响培训效果的因素中,学历、经济地区、专业背景、前测成绩、课程满意度、导师满意度这6个因素决定性最强。
关联规则是对样本隐含规律的一种归纳和总结,并没有关于预测误差的评价指标,因此通常不直接用于预测。本文在关联分析之后,使用决策树模型对培训效果进行预测分析,同时利用决策树分析的结果验证关联分析的结论。
2.3 基于决策树模型的NDLS培训效果预测
2.3.1 决策树构建
构建决策树的目标是利用学员的基本信息、学习情况以及满意度调查信息对学员的培训学习行为进行建模,对学员的学习效果做出预测。学员接受培训后的测试成绩是评价培训效果的重要指标,本文将后测成绩作为标识属性,其他属性为决策属性。基于样本数据集,本文使用C5.0算法建立学员培训效果预测树,通过在该数据集上训练模型找到一个从特征属性到标识属性的映射关系,建立一个树形模型,并且应用该模型对新的类别未知的实体进行分类。决策树的最大深度设置为6,当叶节点样本数小于5时,停止树生长[21]。并应用Boosting策略对多个预测模型进行投票,从而提高预测准确度,以获得最佳的树形结构,结果如图4所示。
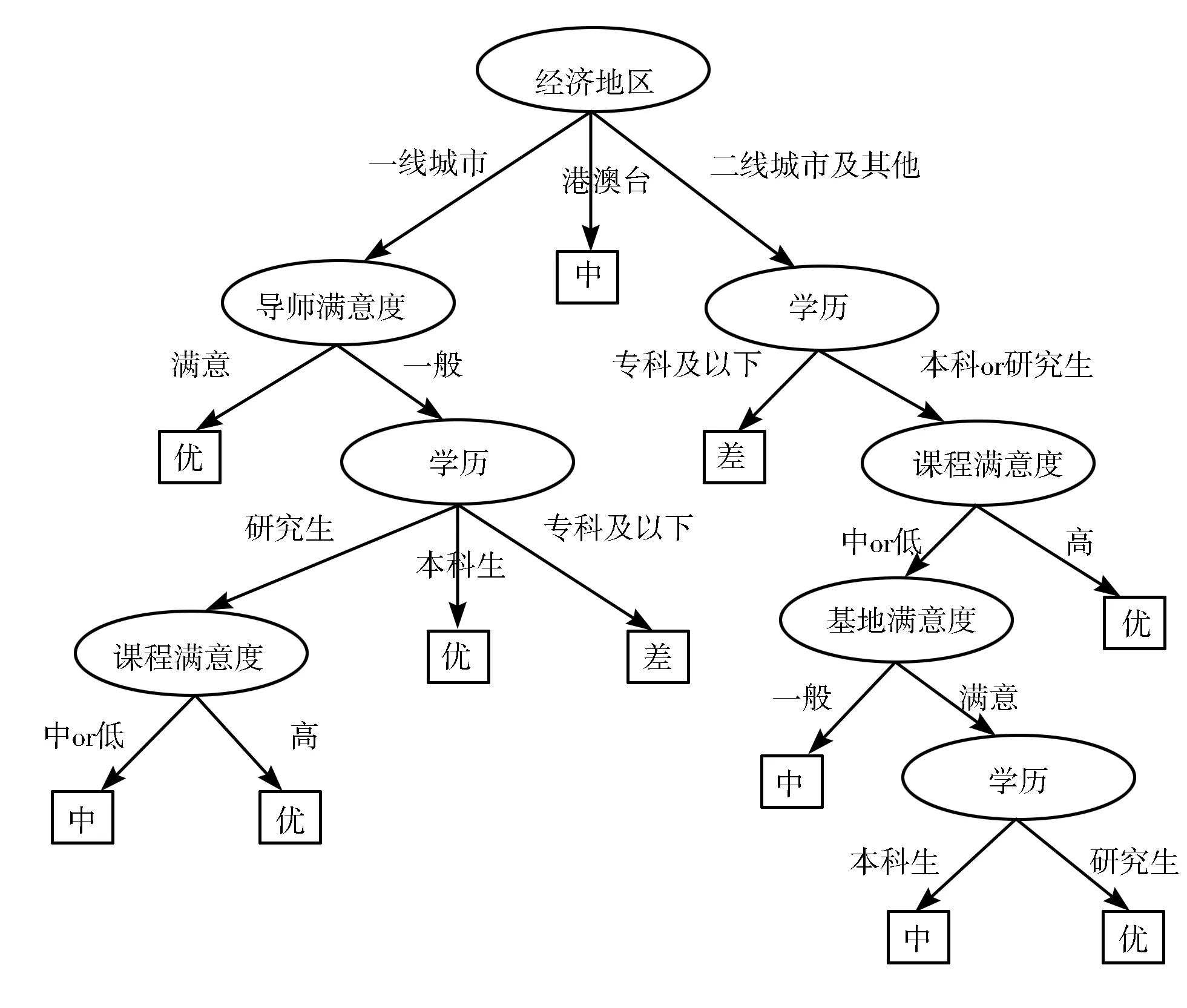
图4 NDLS培训效果预测树
2.3.2 规则提取
根据图4所示的预测树,可使用IF-THEN的分类规则从根节点、分支到叶子节点进行路径描述,提取出11条预测规则,使之更易被理解[22]。限于篇幅,此处仅列出5条后测成绩为“优”的预测规则:
1)IF经济地区=“一线城市”AND导师满意度=“一般”AND学历=“本科生”THEN后测成绩=“优”
2)IF经济地区=“一线城市”AND导师满意度=“一般”AND学历=“研究生”AND课程满意度=“高”THEN后测成绩=“优”
3)IF经济地区=“一线城市”AND导师满意度=“满意”THEN后测成绩=“优”
4)IF经济地区=“二线城市及以下”AND学历=“本科or研究生”AND课程满意度=“高”THEN后测成绩=“优”
5)IF经济地区=“二线城市及以下”AND学历=“本科or研究生”AND课程满意度=“中or低”AND基地满意度=“满意”AND学历=“研究生”THEN后测成绩=“优”
由上面5条规则可知,来自一线城市的学员更容易取得优秀的后测成绩,这可能因为一线城市竞争激烈、学员压力大,促使其更加努力学习,另外他们获取新知识的渠道更多。排除地区因素,可以看出,对培训导师满意度高的学员其培训效果为优,而对导师满意度一般的学员其培训效果还要再看其他因素,可见导师的培训是否到位对培训效果有着很大的影响。排除地区和导师满意度因素,由规则可知学历越高培训效果越好,由此可以判断出培训效果与个人的先验知识及学习能力也有关。另外,在其他因素相同的情况下,课程满意度和基地满意度越高,学员培训效果越好,可见课程内容的好坏以及各个培训基地是否做好了组织和服务工作同样会影响培训的效果。
3 结果及分析
3.1 2种建模方法的实验结果
利用Apriori算法绘制所有因素的关联性网状图,见图5。各色节点代表了不同的属性,任意2点之间的连线越粗表明属性间的关系越强。图中被圆形圈出的节点代表后测成绩属性,被矩形圈出的是关联规则分析出的6个影响因素:学历、经济地区、专业背景、前测成绩、课程满意度、导师满意度,从图中可以看出后测成绩与这6个因素之间基本上都有明显的连线,说明其对培训效果有影响作用。
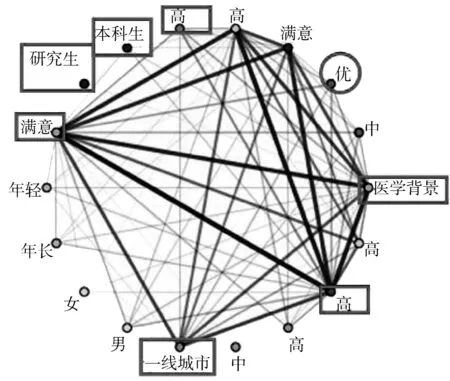
图5 所有因素之间的关联网
在决策树模型中,13个影响NDLS培训效果的因素的重要性对比见图6。所有影响因素中经济地区是信息熵增益最强的属性,其次是课程满意度、导师满意度、基地满意度、前测成绩和学历,决策树根据这6个属性的值形成分支。因此,这6个因素对于预测目标的贡献度较大,其他因素的影响不明显。与Apriori关联规则分析的结果对比,可以发现此处少了专业背景因素,多了基地满意度因素,两者的结论基本吻合。
最终,将2种方法的结论进行整合,在决策树筛选出的6个因素上增加专业背景,共同作为影响NDLS培训效果的主要因素。
3.2 2种建模方法的实验结果评估
利用Apriori算法对样本数据建模后得到10条关联规则,满足这10条规则的样本实例为401个,占总样本量的98.8%。为了提高建模准确率,将规则精简为4条,精简后4条规则的前、后项与精简前10条规则的前、后项均吻合,因此可以认为这4条规则的结论具有代表性和说服力。4条规则的置信度均在82%以上,说明规则的准确性较高;支持度均在10%以上,说明规则具有普遍性;提升度均为1.5,大于1,说明规则具有指导意义。可见,利用Apriori算法得到的结论可以反映出影响学员培训效果的因素。
采用十折交叉验证[23]对决策树预测模型进行评估,该方法首先将数据集随机划分成不相交的10组,然后选择9组作为训练样本集用于建立预测模型,剩余1组为测试样本集用于计算模型误差。反复进行组的轮换,直至每一组样本都做过学习样本和测试样本为止。最终将10次试验所得的预测值的平均值作为算法精度的估计。本文交叉验证的结果显示决策树模型预测的准确率为76.8%,模型中各条规则的置信度也都在70%以上,模型的预测能力良好,可用来对学员的培训效果进行预测。
3.3 与其他方法的对比
此外,本文还利用人工神经网络(Artificial Neural Network, ANN)和支持向量机(Support Vector Machine, SVM)进行预测结果对比,但这2种方法要求输入为数值型变量,而本文所涉及的数据大部分为分类变量(见表1、表2),对于多分类变量,需转换成哑变量形式;对于二分类变量,则需转换成0或1的数值型变量。建模的结果显示,ANN和SVM的准确率均低于25%,不适合用于本研究。于是,本文改用分类回归树(CRT)算法进行建模对比,结果筛选出对培训效果影响最大的因素依次为学历、基地满意度、课程满意度、经济地区、前测成绩和导师满意度,除了排序的位次有差异外,内容与前文的结论一致。但CRT的准确率为64.9%,低于C5.0算法的76.8%,仍然优选前文的结果。
4 结束语
我国目前尚无关于灾难医学、公共卫生应急响应方面的标准化培训课程,现有的非标准化课程大多仅注重理论,内容枯燥不易理解,NDLS课程源自美国,其教学方式方法本身与中国有本质上的区别,这一形式是否能够得到中国学员的认可与接受尚未可知。本研究通过剖析学员的培训前后理论知识接受程度、学员对课程的反馈,在美方课程的基础上进行优化,使其适合中国本土学员的基础认知水平,借鉴了国外应急培训内容,采用了桌面推演、案例分析、模拟实训等方法,增加了课堂的互动性,已经形成了标准化、进阶式的应急培训课程体系。
由于NDLS课程是从国外引进的新课程,缺乏本地化研究,且没有培训质量监控方面的研究,本文利用非监督和监督2种机器学习方法相结合的方式对NDLS的培训效果进行分析预测,找出影响培训效果的主要因素。基于Apriori算法得到的关联规则的置信度均在82%以上,支持度均在10%以上,提升度均为1.5,说明其结果准确、通用、有效。采用十折交叉验证对C5.0决策树预测模型进行评估,显示准确性为76.8%,模型性能良好。本研究可以引起业内人士对灾难应急响应培训体系优化的重视,进而转变人们对培训工作的固有观念,灾难应急响应培训以往多流于形式,得不到重视,培训体系得不到优化,这无疑阻碍了培训工作的高效开展,降低了培训效果,影响了培训效果的有效转化。
今后在培训过程中可以借鉴本研究的结论,提前干预影响培训效果的因素,提高培训质量。但是,由于NDLS课程在我国落地不久,前期数据没有及时收集或不够规范,目前采集到的数据有限,因此,结果可能会存在一定的局限性。另外,其他的机器学习方法也可以尝试应用于灾难应急培训质量监控研究,后续将进一步探索。本研究的结果将促进导师观念的转变,同时对优化策略进行跟踪检验,具有实践反思性,这种反思为日后优化培训体系后的总结与改进提供了思路与方法。
