基于Spark的电影推荐系统的设计与实现
2020-12-28孙成
孙成
摘要:在人们的生产生活中经常可见大数据[1]的身影,数据量呈现几何式的增长,传统的信息传递机制越显弊端。现在正是推荐系统大力发展的上升期,但是也要克服随之而来的诸多问题,经常出现的冷启动[2]、数据稀疏性[3]等问题被众多学者广泛研究。该文打算采用聚类技术和协同过滤等技术来缓解这些问题,提升推荐质量,从而满足人们能够快速地获取所需信息。然后设计出一个关于电影的推荐网站,采用现今比较流行的处理大数据的Spark[4]技术以及依托建立在其上层的MLlib机器学习生态库。达到处理海量数据的能力,根据现有的条件技术从离线推荐和热门推荐两种方式分区组合推荐来实现本系统。
关键词:大数据;协同过滤;Spark;机器学习
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2020)33-0080-02
开放科学(资源服务)标识码(OSID):
现在网络上提供的信息量过于庞大,用户经常都会遇到信息过载的情形,使其难以做出符合自身需求的选择。因此,许多科研人员一直在努力试图探究新的技术,来帮助人们快速而又精准地寻找到他们所感兴趣的物品,这就是推荐系统的作用。通常我们在需要寻找信息的时候,我们会借助搜索引擎来完成,但是它也存在一些不足,用户需要使用准确的关键词来涵盖所要检索的内容,其次检索后返回的结果也很难让其非常满意。对于不同人使用同样关键字进行搜索,但系统展示的结果将是一样的,无法做到个性化的推送。而然推荐系统对用户来说就不需要严格的条件,它并非一定要让用户提供准确的检索关键词就能主动地发掘用户爱好,从而可以为不同的用户做出特定的推荐服务。
1 Spark概述
Apache Spark于2009年由加州大学伯克利分校的AMP实验室所开发的分布式计算框架,与MapReduce相比它是基于内存运行的,使得运算速率大幅提升。也正是这一优点让Spark很快变为Apache社区知名度很高的项目,而且还得到国内外众多知名度很高的互联网公司所青睐,例如IBM、Twitter、百度、阿里巴巴等。
Spark中有一种弹性分布式数据集RDD( Resilient Distribut-ed Dataset),它是数据和运算的抽象,可以通过它实现Spark将数据在内存中的缓存操作。Spark还提供了广播变量和累加器,广播变量能够将数据发送给每个节点,方便数据的共享传输,累加器能够将节点中的元算结果数据聚合返回。用户可以使用外部数据来创建RDD,也可以通过采用已有的RDD来创造。RDD有两类基本操作分别是:转化操作(transformations)和行动操作(action),转化操作的RDD只有在遇到行动算子才会去计算执行。
2 基于Spark的电影推荐系统设计与实现
2.1 系统总体架构设计
单一的推荐算法都会存在薄弱点,很难兼顾所有需求,此时需要同时考虑将多种算法组合以达到互补的效果,弥补自身的不足。最后将从离线推荐和热门推荐两方面设计出关于电影的推荐系统。
离线推荐方面是使用用户历史行为数据作为依据,分析用户与电影直接的潜在联系,它考虑了所有有价值的信息,全面分析比较。也正因如此,它在实际的运算过程中会非常占用系统资源,耗时较长。由于离线推荐对实时性要求不高的特点,也使得这种全面考虑的方式能够得以实现。可以设置一个任务,按照预设的周期内运行一次离线推荐步骤,以保障数据的时效性和可靠性。
热门推荐方面,主要是为了考虑新注册用户进入系统时,由于没有历史行为信息无法做出较优质的推荐,退而求其次地使用热门推荐来尽可能满足新用户的需求,不至于给用户非常糟糕的体验感.因为往往给用户的第一印象至关重要的。当用户在电影业务系统的操作增多时,那就可以再对其做个性化的推荐。因此可以避免出現刚注册的用户进入系统后的冷启动问题。
2.2 电影推荐系统的需求分析
2.2.1 功能需求
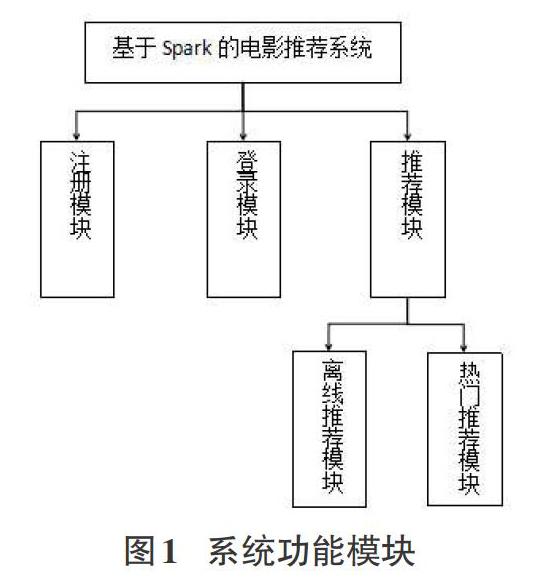
1)注册模块
新用户在浏览器输入网址打开账户注册页面,填写相关用户基本信息,再向系统进行提交操作。
2)登录模块
将用户的账号密码填写到登录网站,提交后系统会自动验证其真实性,如果正确则进入系统主界面,如果失败则会提示重新检查信息后再次提交。
3)电影推荐模块
本模块是推荐系统的核心关键所在,它会根据各用户的历史信息做出非常接近其真实喜好的电影推送。如果是新用户,则会采取把近期内的比较热门的推荐给他。尽可能兼顾所有的用户,使得推荐效率更高。同时业务系统也可以搜集用户的行为信息,比如用户给电影的评分。通过多方面的渠道了解用户的兴趣爱好,能够为用户做出更加精准的推荐,使得用户的推荐列表中的电影一直是他所喜爱的。系统功能模块如图1所示。
2.2.2 用户需求
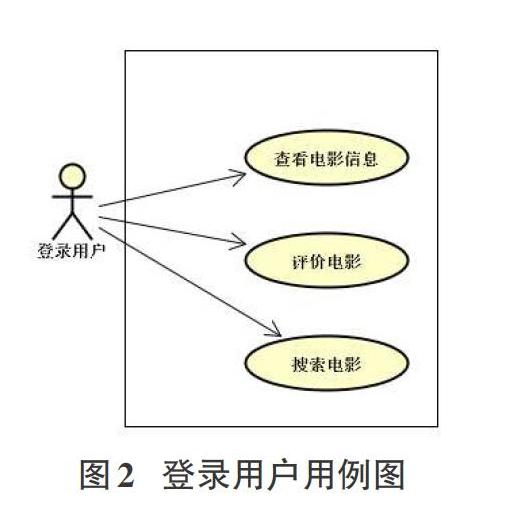
在网站的登录界面填写账号与密码,通过验证其真实性后转跳到推荐首页,其中一部分展示的电影列表是为当前登录用户所做的个性化推荐,另一部分展示的是近期比较热门的电影,这部分向所有用户都推荐相同的内容。登录用户用例图如图2所示。
2.2.3 电影推荐流程设计
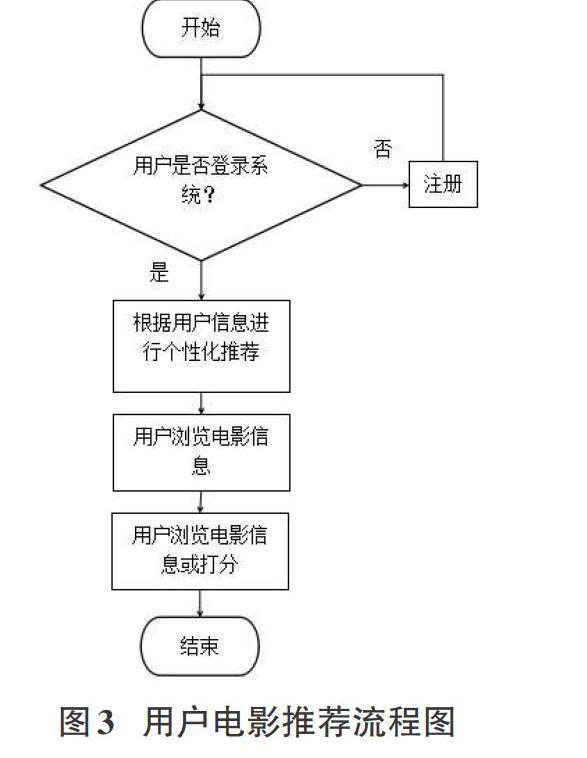
用户进入电影网站后,如果是用老用户直接输入账号密码登录,如果是新用户则转跳到注册页面后再重新登录。推荐系统为用户展示电影信息,用户可以选择某部电影查看详情,同时还可以对此电影采取打分操作。用户电影推荐流程如图3所示。
2.3 离线推荐
离线部分打算采用聚类技术与协同过滤等技术来实现,具体为:
1)从数据库中读取模型所需要的评分数据M,存储形式为:用户ID,电影ID,评分。
2)使用Spark MLlib库中已经实现的交替最小二乘法(ALS,Alternating Least Squares)来训练模型。其原理是,对评分矩阵M采取交替的方式进行分解。先令电影特征矩阵V为零,将其固定后求用户特征矩阵U,再固定U求V,一直循环交替运算下去,直到损失函数f收敛或已到预先设定次数,那么此时的U,V就是所需的最优值。
3)继续使用K-means方法对上一步中求出的电影属性特征矩阵V做聚类操作,直到聚类中心不再发生大幅的变化或者达到指定的运算次数,那么会停止计算,能够让相似的电影聚在同一簇中。
4)在同一簇中寻找离新目标电影距离最近的邻居,再按照一定的运算方式求出目标电影的特征值,将之合并到原始的V中。
5)最后将U与更新后的V进行相乘运算(M=UyT)得出的新矩阵,通过它能够对新电影进入网站后的推荐,进而起到了缓解冷启动的效果。
2.4 热门推荐
热门推荐模块将使用Spark SQL通过对历史数据采取统计的方式发掘有价值的信息。从数据库中获取用户的历史行为数据,在最近的一定范围内对每月的用户评价次数做出统计,在各个月份中适当选择一些评价次数特别高的电影,然后将其按月存到数据库中。在用户访问电影網页时,按照各月分别展示出排名靠前的电影。热门推荐就是面向所有的用户都推送相同热门电影,即使是新注册的用户也可以得到很好的推荐,从另一个角度讲也是在完善系统中所存在的冷启动缺陷,增强用户体验感。
3 实验解析
本实验主要对离线模块部分进行实验对比,通过调节数据量的大小来验证本系统的可行性。此处使用的由GroupLens提供的MovieLens免费的电影数据集,为了方便展开测试,对其大小预先做了划分,具体分为IOOK、400K、700K、IM和IOM。在Spark和单机环境下的实验结果如图4所示。
观察上图不难发现,当数据量在比较小的情况下,是否采用Spark或单机对系统执行效率影响较小。反之,如果数据量非常巨大,单机的运行效率下降尤为明显,而基于Spark的系统稳定性非常好,那是因为单机的系统资源急剧匮乏无法支持海量数据的高强度运算,使得系统性能大幅下降。
4 结束语
从大数据的角度设计了一个关于电影的推荐网站,从主要方面对其进行了分析,借助了现今比较流行的Spark技术来面对海量数据的接人。不仅能实现了老用户的个性化推荐,也能兼顾新用户的要求。最后也通过实验的方式验证了采用Spark实现大规模数据的优势。
参考文献:
[1]国杰,程学旗.大数据研究:未来科技及经济社会发展的重大战略领域——大数据的研究现状与科学思考[J].中国科学院院刊,2012,27(6):647-657.
[2]孙小华.协同过滤系统的稀疏性与冷启动问题研究[D].杭州:浙江大学,2005.
[3] Linden G,Smith B,York J.Amazon.com recommendations:item-to-item collaborative filtering[J]. lEEE Internet Comput-ing,2003,7(1): 76-80.
[4] Zaharia M, Chowdhury M, Franklin M J,et aI.Spark: clustercomputing with working sets[C]. USENIX Conference on HotTopics in Cloud Computing, 2010:1765-1773.
[通联编辑:王力]
