Spark平台下日志清洗系统设计
2020-12-28李光明李垚周
李光明,李垚周,李 颀
(陕西科技大学 电子信息与人工智能学院,陕西 西安 710021)
0 引 言
现如今政府之间业务联系紧密,各级部门之间大量数据交流频率越来越高,由于数据清洗[1]包含抽取[2]、转换、加载[3]3个阶段,而各部门之间所用系统独立,在产生大量日志数据的同时,没有合理的将日志数据进行抽取和转换,日志数据[4]无法合理利用,导致政府领导不能得到更加精准的信息,对领导决策无法完全发挥相应的作用,在对数据进行分析时,出现数据分析[5]不精准等问题。为更好应对上述问题,分布式并行大数据清洗成为ETL(extraction-transformation-loading)中的重要手段。
在海量数据清洗领域中,MapReduce[6]日志清洗框架作为当前流行的并行框架而被大型互联网公司奉为至宝,实验结果表明,基于MapReduce的并行日志清洗框架在处理大数据时,具有高可扩展性和高容错性[7],同时还能降低资源消耗。针对大数据清洗,已有不少学者正从事研究。刘心光等[8]从4个优化规则设计基于改进的链式MapReduce并行ETL,通过在Map和Reduce进行分工完成作业,来减少ETL清洗流程和I/O消耗,但是该框架没有考虑到Shuffle、Sort过程,在面对大数据量时,如果不采用分区并行计算,容易造成数据倾斜[9]问题,导致数据清洗分布不均,时间消耗过长。李宁宁等[10]也对大数据清洗进行深入研究,采用基于任务合并的方法对清洗过程进行优化,利用多个相同文件进行合并,使其在Map阶段进行一次Shuffle操作,从而提高转换效率,但只是针对MapReduce并行清洗框架进行研究和设计,由于MapReduce只针对于离线数据[11]清洗,并且数据处理模式单一,只存在Map-Reduce操作,处理过程中还会造成大量磁盘I/O占用[12],导致清洗效率降低。针对上述问题,解书亮等[13]进行基于Spark的并行ETL研究与实践,提出并行ETL方法,但并行处理是Spark集群自带的配置设置,且聚合过程中,没有考虑Join优化过程,只是单纯运用Spark原理进行聚合操作,也没考虑到数据倾斜等问题。基于上述问题,本文结合Spark分布式技术对日志清洗系统进行设计,主要贡献如下:
(1)使用Hadoop集群[14]、Flume[15]、Kafka[16]、Spark Streaming[17]等大数据相关技术进行日志清洗系统架构设计,并将实时转换过后的日志数据加载到HBase[18]数据库中。
(2)针对数据抽取,采用决策对象识别算法将抽取分为3阶段,实现对海量数据的快速过滤、去重。
(3)对Join操作进行优化,通过添加N以内的随机数前缀,对数据较多的Key进行子扩展,先进行局部操作,再去除随机数之后进行聚合操作,避免Join操作时出现数据倾斜问题。
1 Spark日志清洗系统设计
1.1 Spark原理设计
Spark实时流计算框架具有快速、易用、通用、兼容性[19]等特点,该领域包含Spark Core[20]、Spark SQL[21]、GraphX[22]以及Spark Streaming等相关组件,本文主要运用Spark Streaming核心组件,首先Spark Streaming支持多种数据输入源,如Kafka、Flume、Twitter[23]、以及简单的TCP套接字[24]等,其次当日志数据在经过抽取后,可以通过Spark Streaming中内含的RDD(resilient-distributed-dataset)算子进行压平、过滤、去重等操作,经过一系列算子进行转换操作后可以加载到Hive[25]、HBase等多种存储工具中。
Spark Streaming提供一个高级抽象,称为DStream[26],内部使用RDD算子进行实现,当从外部持续数据时,Spark Streaming会将数据通过RDD算子进行操作转换,每个RDD算子在执行时,都会将间隔内的数据存储到内存中,其原理如图1所示。

图1 Spark Streaming原理
1.2 Spark系统设计
本系统采取Spark框架中的实时流技术进行架构设计,在数据源层面,采取Web前端旅游子系统产生的日志数据作为数据源,后经Tomcat服务器进行存储,实时架构使用Flume进行数据采集,存储到Kafka消息队列中,然后经流式处理框架Spark Streaming进行数据转换,实时存储到Hbase数据仓库中,整个架构按照分层模式分为视图层、存储层以及控制层和业务处理层,同时还包含两个子系统模块,系统架构设计如图2所示。

图2 系统架构
如图2所示:系统总体架构设计将从以下几部分进行分解:
(1) 数据存储层:实时架构在数据存储层上采取HBase和Mysql进行数据存储,同时将Web端采集的日志数据存储在Kafka中,这样做的优点在于,Kafka包含生产者消费者模型,可以实时接收数据,同时HBase具备列式存储优势,可存储任意格式。
(2) 业务处理层:采用Spark Streaming流式处理框架,可以针对Kafka消费者组中的数据进行实时拉取,将数据按照DStream形式进行处理,而DStream内部设计采用RDD进行表示,最终会转换成Operation操作,对重复的数据会按照Key值进行统计计算,然后经过聚合输出到数据仓库中。
(3) 控制层:通过引入决策对象识别算法和分区聚合算法对转换的数据进行算法优化,提高处理效率。
(4) 视图层:前端页面数据会通过图形化进行展示,在架构上采取前后端分离思想,采用MVVM模式,运用HTML、CSS(cascading-style-sheets)、JavaScript、JQuery、Ajax技术设计。
1.3 Spark功能设计
大数据日志清洗系统结合改进后的分区聚合算法对实时产生的数据进行清洗,通过提高Join操作的效率以保证日志数据的精准度。在用户功能模块设计上包含超级管理员和普通管理员模块,在操作类模块布局中包含日志清洗功能,配置管理功能,图形统计和资源统计功能,同时各功能模块中包含子功能。基于Spark的大数据清洗系统功能模块如图3所示。

图3 大数据日志清洗系统功能模块
日志清洗管理功能包含数据导入、清洗规则制定以及清洗流程解析子功能,通过对将导入的数据解析、验证、转换处理以到达清洗效果。
配置管理功能包含流式架构的集群配置,如Kakfa集群、Hadoop集群、Spark集群、Flume集群等。
资源统计功能主要包含各资源的调度、清洗后数据的展示以及在计算时文件的统计等子功能。
2 清洗技术
2.1 数据清洗概述
数据清洗简称ETL,其目的在于对不合理、不规则、有噪音有缺陷的数据进行去重、过滤,只保留合理有用的数据。在ETL操作中,分3个步骤,分别为抽取、转换、加载,在本文中,数据抽取来自旅游子系统,产生的数据多为日志数据,所以主要工作是去除重复数据和补全因为并发过程中造成的字段缺失的数据。现阶段针对海量数据处理问题,在大数据领域中有两种处理方式,一种是通过MapReduce进行清洗,一种是使用Spark进行数据清洗。
2.2 MapReduce清洗技术
MapReduce并行清洗技术采取分而治之的设计思想,将原始数据抽象成Map-Reduce操作对,输入输出采取
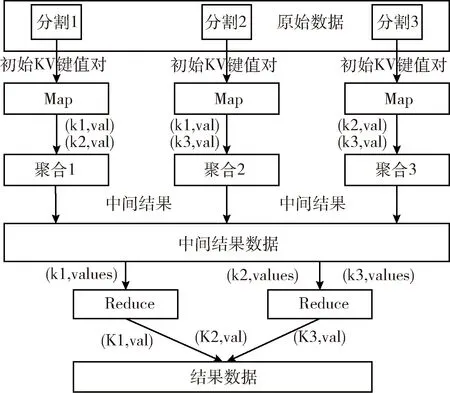
图4 基于MapReduce的ETL流程
具体操作步骤如下:
(1)将原始数据划分为多个Key/Value键值对。通过Map统计每个Key键,存入Value值中。
(2)Combiner整合Map结果,将Map的输出作为Combiner的输入,再将Combiner的输出作为Reduce的输入。
(3)Partition分割每个Map节点的结果,按照Key分别映射给不同的Reduce。
(4)Reduce完成最终的数据聚合,存入数据仓库中。
虽然MapReduce在数据清洗方面有很大优势,但每次进行MapReduce处理后,数据都存入磁盘中,对I/O消耗过大,且ETL的数据均为离线数据,无法实时处理,所以清洗效率不是很高。
2.3 Spark清洗技术
Spark在进行数据清洗时,以弹性分布式数据集RDD为计算依据,RDD以一组分片为数据集的基本组成单元,每个分片为一个计算任务处理,分片的数量决定并行计算的粒度,而Spark Streaming内部DStream也是基于RDD算子来表示,清洗流程如图5所示。

图5 Spark并行大数据清洗流程
由图5可知,Spark Streaming从Kafka消息队列中读取日志数据后,在其内部是由一个个DStream组成,DStream是用一系列连续的RDD来表示。每个RDD含有一段时间间隔内的数据,根据分片数量设置分区,并对数据进行实时抽取,采取并行分区方式处理数据,先通过RDD读取到文本信息,对数据进行压平分割,统计相同Key所对应Value值的个数,再通过Join操作将相同Key对应的Value进行聚合,输出到数据仓库中,最终达到清洗目的。相比于MapReduce框架,Spark框架更适合于企业对大数据的ETL处理,随着业务需求的不断变更和数据量的不断增大,可以根据实际情况来实现功能、集群的扩展。
本文对基于Spark的数据清洗算法进行了研究和实践,重点解决数据过滤、去重、数据倾斜等问题,因为在数据清洗过程中,对脏数据的处理是最耗时的阶段,需要多步操作,通过决策对象识别算法进行快速过滤去重,提升数据的抽取效率,通过改进的Join操作对去重后数据进行聚合,避免数据倾斜。
2.4 决策对象识别算法
假设决策表T具有n个不同的决策对象值,将兼容对象决策对象值用1,2,3,…n代表,不兼容对象决策对象值用n+1表示,我们可以设置决策表T由n+1个子决策表组成,即D1,D2,D3,…,Dn,每个子决策表包含相同的类对象,对象编号为n1,n2,n3,…,nn,因此,决策表T是一个兼容的决策表。假设对象a有不同的对象值,它被映射为1,2,3,…,r,可以得出
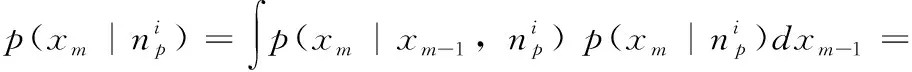
(1)

假设可辨别对象由两个对象组成,即决策对象和条件对象。如果两个对象的决策值不同,则条件对象a的属性值也不同,那么a便可以识别这两个对象,即具有相对的可识别能力。一个对象所能识别的对象数目越多,相对识别能力就越强,就可以用相对识别数来衡量相对识别能力。在兼容性决策表T中A∈C,a可辨别一对属性的对象,表示如下
ObjPq={
(2)
式中:ObjPq为可辨别的对象,M为决策对象,N为条件对象。f(M,q),f(N,q)为决策值。

(3)
式中:p,q,r为被映射的对象值,vi为等价类中的元素。
在兼容性决策表T中A⊆C, c∈C∪D,其中对象c为新增识别能力,定义为A1,A2,…,Ar之和,表示如下
ObjSU,A∪{c}|ObjSU,A=ObjSA1,{c}∪…∪ObjSAr,{c}
(4)
式中:A,C,U为对象,c为新增的识别能力。
算法1:
输入:对象A,识别能力c,保留对象D
输出:重复数据,重复次数
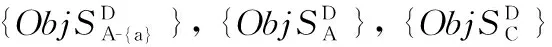
(1) Main1←Objectkey, Textvalue//传入参数, 创建Main1函数
(2) For each a int {ObjPq}
(3) A_Class←getObject(value, a)//将获得的对象传给导入类A
(4) B_Class←getObject(value, b)
(5) For each a int {ObjSU, A}
(6) context.write(B_Class,3)//输出重复数据
(7) context.write(C_Class,1)//输出重复次数
算法2:
输入:重复数据,重复次数的集合
输出:过滤后总条数
(1) Main2←Stringstr, Vectorv//传入参数, 创建Main2函数
(2) totalNum←foreach
(3) Context.write(str, new IntWritable(totalNum))//输出顾虑后总条数
输入: 决策表T
输出: 去重、过滤后的表Table
(1) Main←new JobConf//创建主函数Main, 然后new出SparkStreamingContext类
(2) Job←JobClient.runJob(conf)
(3) Table←For each c int{ObjSU,AU{c}|ObjSU,A}//循环遍历出两个对象集中日志条数
(4) Table←Table-{c} //得出去重、 过滤后的表
2.5 改善的Join操作
经过上步操作后,需要在数据仓库中对数据进行聚合处理,但如果使用传统的Map Reduce进行数据聚合操作,那在聚合时将产生大量的I/O请求,会降低聚合效率,现基于Spark环境,可以针对RDD算子使用分区聚合算法进行处理。通过Join操作对数据中Key值相同的记录进行聚合,以达到最终清洗的结果,在数据量少的情况下进行Join运算,不会发生数据倾斜等问题,但假设在RDD1和RDD2中,RDD1中的Key数据量过大,将会使Task1处理时间过长,这将导致数据倾斜等问题。现通过对Join操作进行优化改进,算法实现步骤如下:
步骤1 对大数据量相同的Key的RDD1,使用Sample采样出一份样本,统计每个Key的数量,并计算出最大的Key。
步骤2 从RDD1中分离出过大的Key通过以N为随机数对它标号,使之形成独立的RDD1_1,数据量正常的Key标号为RDD1_2。同理将RDD2也进行上述操作,得到RDD2_1和RDD2_2。
步骤3 将RDD1_1和RDD2_1进行Join操作,此时原先的Key将被分散成多份,分散到多个任务中进行Join操作,Join的结果记为Result,然后将随机数前缀去掉,得到Result1,同理RDD1_2和RDD2_2进行操作,结果记为Result2。
步骤4 最后将Join1和Join2通过union算子合并,就计算出最终结果Result3。
算法流程如图6所示。

图6 改进的Join操作
从图6中可以看出,当对Join操作进行算法优化后,RDD1上原有的一个任务被分成2个任务,每个任务进行1×2次运算,因为是并行处理,所以1×2次运算的总时间和2个任务并行运算次的时间是一样的,在避免数据倾斜的同时,提高了数据清洗效率。
2.6 清洗模块实现
基于Spark的大数据清洗系统主要进行实时数据清洗,流程如图7所示。

图7 大数据清洗系统流程
旅游子系统每天实时产生有1 G的日志数据,需要采用流式计算的方式对该日志数据进行清洗,通过Flume采集Web子系统产生的日志格式数据,存储到Kafka消息队列中,Spark Streaming实时拉取Kafka消费者组中的日志数据进行清洗,实现政府人员对实时产生数据的精准把控。
3 实验分析对比
3.1 实验环境
为对比数据清洗的效率,本实验搭建出Hadoop集群和Spark集群,以便进行实验对比。Hadoop集群和Spark集群均采用5台服务器进行部署,分别命名为Spark01至Spark05,其中Spark01为主节点,Spark02至Spark05为从节点,每台服务器都会部署Centos-7,Hadoop-2.6.4,Jdk-8u191-linux-x64,Spark-2.2.-1-bin-hadoop2.6,Zookee-per-3.4.5,Hbase-1.2.12,同时服务器内存配置为4 G、处理器内核总数为2核,每个处理器的内核数量为4个,磁盘大小为50 G,集群开发工具使用IDEA。
3.2 实验数据
本文实验数据来自于智慧咸阳大数据分析平台中的一个旅游子系统产生的日志数据,需要按照咸阳市政府的要求对产生的旅游日志数据进行清洗,该旅游子系统包含数据集大小10 G-50 G不等,实验使用精简数据集ml-1m、ml-3m、ml-5m与ml-7m进行对比实验,分别包括100万、300万、500万与700万条日志数据。
3.3 实验结果
本实验将从3个方面进行大数据清洗效率对比。
(1)Hadoop集群MapReduce清洗框架和Spark集群Spark清洗框架在不同数据样例下的运行速率,实验结果如图8所示。
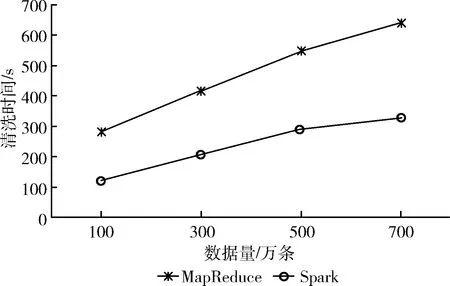
图8 Spark清洗与MapReduce清洗运行速率对比
由实验结果可以看出,当测试数据依次为100万、300万、500万、700万时,基于MapRduce的清洗系统明显比基于Spark的清洗系统所用时间更长,经实验对比,运用Spark清洗框架清洗数据时,时间相比MapReduce清洗框架缩短50%左右,表明使用Spark构建大数据日志清洗系统更加合理。
(2)为验证数据倾斜的改善效果,现将本文改进后的算法与传统的基于Spark的并行ETL数据清洗进行实验对比,根据均方根误差RMSE作为算法改善后的评价标准,其公式为
(5)
式中:N代表测试数据的条数,pi表示实际清洗时间,ri表示算法预测的清洗时间,当(pi-ri)的值越小,则整体RMSE的值越小,表明预测清洗的时间与实际的时间的偏差越小,即数据倾斜的改善效果更明显,大数据清洗系统的精准度和清洗效率越高。
1)在Spark平台下,将运用决策对象识别算法和对Join操作进行优化后的算法与传统基于Spark的并行ETL数据清洗算法进行实验对比,如图9所示。

图9 传统算法与改进后算法清洗时间效率对比
2)在Spark平台下,将运用决策对象识别算法和对Join操作进行改进后的算法与传统基于Spark的并行ETL数据清洗算法进行实验对比,如图9所示。
由表1可得:本文改进后的算法较基于MapReduce日志清洗算法和传统的基于Spark并行ETL算法有较低的RMSE值,则时间复杂度较低,算法精准度提升,清洗效率提升,数据倾斜得到很好的改善。

表1 传统算法与改进后算法RMSE对比
(3)通过测试Reduce节点个数来验证算法改进后与传统算法对数据清洗速度的影响,实验指定测试数据分别为100万条、300万条、500万条、700万条时。对应实验结果如图10~图13所示。

图10 100万条数据对应不同的Reduce个数在算法改进前后的对比
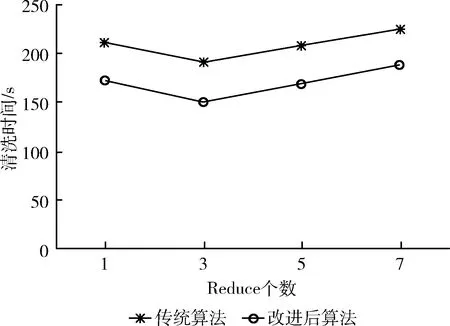
图11 300万条数据对应不同的Reduce个数在算法改进前后的对比

图12 500万条数据对应不同的Reduce个数在算法改进前后的对比
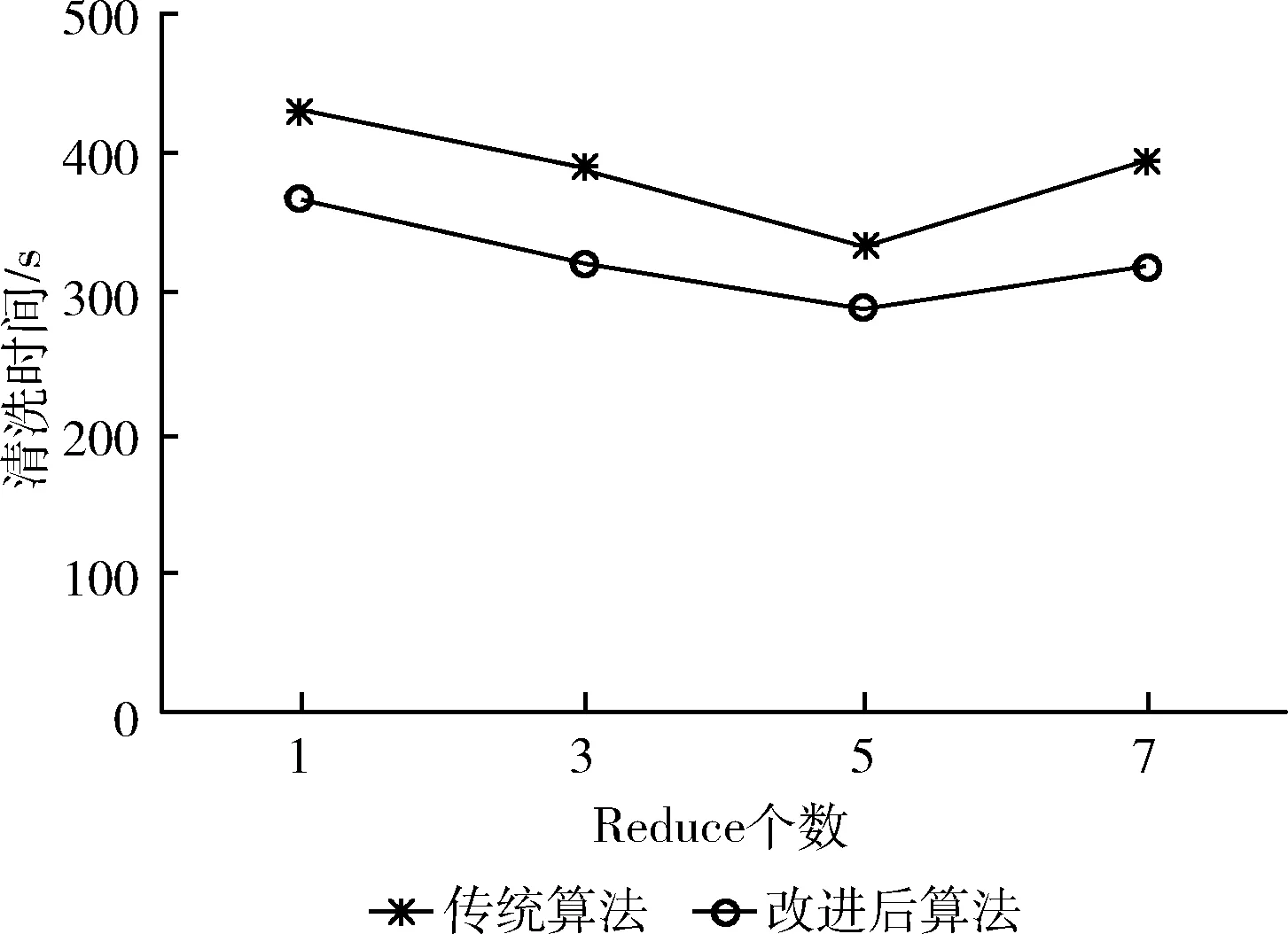
图13 700万条数据对应不同的Reduce个数在算法改进前后的对比
实验结果如图10~图13所示,改变集群中Reduce的个数,发现当数据为100万条,Reduce为1,数据为300万条,Reduce为3,数据为500万条,Reduce为5时,数据为700万条,Reduce为5时,日志数据清洗时间最短,且算法改进后比传统算法所用时间更少,清洗效率更高。
由此可以得出:当数据量给定时,改变Reduce节点个数,算法改进前后所用时间明显不同,且改进后的算法较传统算法所用时间更短。但当Reduce个数继续增多时,清洗时间反而增加,这是因为在给定数据量下,Reduce的数量已经确定,而一味提升并行化程度只会造成更多任务分配的开销。
4 结束语
本文实现了基于Spark平台的大数据日志清洗系统,实验结果表明相比于传统清洗系统或MapReduce清洗系统来说,清洗效率大大提升,能够高效、快速地完成大数据的清洗任务。
(1)通过Hadoop、Flume、Kafka、Spark Streaming等大数据组件进行系统搭建,提出决策对象识别算法,将抽取分为3阶段,分别为辨别等价类中重复数据,对等价类重复数据过滤处理,将过滤后数据存储在内存之中。
(2)对Join操作进行优化,通过加入随机数前缀,将数据先进行局部聚合,再全局聚合,降低发生数据倾斜概率。
下一步可以对Spark Streaming中的updateStateByKey算子进行优化,针对每个key的状态编写对接实际业务的清洗代码,使该日志清洗系统更加完善。
