生成对抗网络下小样本语音情感识别方法
2020-12-28高英宁崔艳荣孙存威
高英宁,崔艳荣+,孙存威
(1.长江大学 计算机科学学院,湖北 荆州 434023;2.电子科技大学 计算机科学与工程学院,四川 成都 611731)
0 引 言
语音情感识别(SER)是指从语音数据里辨别出人类的情绪状态[1]。SER方法里,提取情绪特征的质量大幅度上决定着情感识别精度。传统的特征提取方法一般是针对整句语音数据,提取语速、基音频率等情绪特征[2]。这种方式提取的特征往往会丢失掉语音数据中的部分情感特征和时频两域的相关性信息,导致情感识别精度低。
随着深度神经网络的出现,卷积神经网络(CNN)在图片处理领域[3]和长短时记忆网络(LSTM)在语音处理方面[4]取得了显著成功。近年来语音情感识别领域引入了CNN[5]和LSTM[6],解决了传统SER方法所出现的问题。基于深度神经网络的语音情感识别模型通常需要大量的训练数据才能获得一个良好的识别率[7]。若仅用小样本的语音数据作为训练集训练模型,容易出现过拟合现象,使得泛化能力差,从而导致识别率低。
经典的数据增强是对原数据集应用微小变换进行数据增强[8]。一些常见的图像数据增强技术,如移位和旋转,不适用于文本或语音处理。相比之下,生成对抗网络(GAN)侧重于实际数据的模拟[9]。因此,本文使用Wasse-rstein生成对抗网络[10](WGAN)对抗训练来自主学习原始样本的分布规律,生成新的数据样本进行数据增强。目前,很少有研究人员将生成对抗网络应用于小样本语音情感识别去解决小样本情感识别率低的问题。因此,本文提出一种生成对抗网络模型下的小样本语音情感识别方法。
1 小样本语音情感识别算法
针对本文提出的生成对抗网络模型下小样本语音情感识别方法,其算法流程如图1所示。

图1 生成对抗网络模型下小样本语音情感识别流程
1.1 语音信号预处理
对语音情感数据进行预处理就是为了把语音的时域信号变成包括时域和频域特征的语谱图信号[11]。首先,对一段长的语音数据执行分帧操作,把语音信号切割成大小相等的片段,其中的每一段为一帧,分别对每一个语音帧进行加窗处理,以减小信号中不连续部分的幅值,通过傅里叶变换计算出每帧语音数据的频率谱,对其平方转化得到对应频谱的能量谱,最后把所得到的结果按照时间维度拼接形成语谱图,如图2所示。

图2 语谱图
人们的情感变化可以清晰表现在语谱图上。例如,人们伤心时,语速较慢,平均音调较低,语气强度比较低,在语谱图中深颜色部分的面积较小,相邻条纹间隔较大。
1.2 生成对抗网络数据增强算法
原始的GAN包含:生成器网络(G)和判别器网络(D)。G的任务就是通过输入随机分布噪声z,产生尽可能拟合真实数据分布Pr的数据G(z),D的任务是尽可能辨别出输入的样本是来自数据集的样本x还是模拟样本数据G(z)。G的最终目的为最大化D判别错误的概率,D的最终目标是使得自己判断正确的概率达到最大,即D(G(z))尽可能接近0,D(x)尽可能接近1,模型优化函数如下式

(1)
式中:Pr(x)为真实样本的分布,Pg(z)表示随机噪声的分布。
GAN的训练为G和D交替进行。理想的状态下,该模型最终会找到一个全局最优解,即D判断不出输入的数据是来自数据集的样本x还是G产生的模拟样本G(z)。
GAN的模型流程如图3所示。

图3 GAN的模型流程
由于原始的生成对抗网络通过交叉熵(Jensen-Shannon divergence,JS)散度来衡量真实样本数据和生成样本之间的距离,会使得优化目标函数式(1)出现梯度消失[12]。而WGAN是对GAN的一种改进,提出了使用Wasserstein距离来进行数据分布的比较,即使两个数据分布之间没有重合的部分,Wasserstein值也能很好地表示出两个数据样本距离的远近,使得模型的训练更加稳定,基本解决了模型崩溃问题,优化目标函数变为式(2)
L=Ex~Pdata(x)[D(x)]-Ez~Pz(z)[D(G(z))]
(2)
根据式(2)可以得出生成器和判别器的损失函数如下式
Dloss=Ez~Pz(z)[D(G(z))]-Ex~Pdata(x)[D(x)]
(3)
Gloss=-Ez~Pz(z)[D(G(z))]
(4)
其中,x表示输入的真实样本,采样于真实样本Pdata(x),z表示输入的正态分布噪声,采样于分布Pz(z)。
1.2.1 生成器
输入的数据为100维的采样于正态分布的噪声,将输入噪声通过一个全连接层后维度转换(Reshape)成(4,4,1024)的三维张量,经过6层小步幅反卷积层进行上采样,使得输出特征图大小逐渐扩大为前一层的两倍,最终输出一个维度为(256,256,3)的模拟样本图像,生成器模型如图4所示。反卷积层的卷积核均为5×5像素,步幅大小为2,前5层反卷积层均使用ReLU非线性激活函数,最后一层使用Tanh激活函数。同时在生成模型中添加批量归一化方法,该方法避免了生成器模型把所有的样本数据都收敛到同一个点,解决了初始化差的问题。
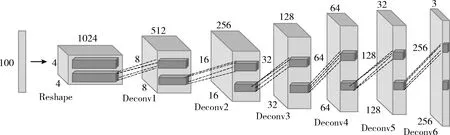
图4 生成器模型
1.2.2 判别器
输入数据为真实的样本和生成的样本,是一张维度为(256,256,3)的图片,通过带步长的卷积层进行下采样,逐步学习输入样本的深层次特性,最后全连接层输出判别器的判断结果,判别器模型如图5所示。卷积层的卷积核均为5×5像素,步幅大小为2,模型中所有层都需要使用Leaky ReLU激活函数。在判别器中添加批量归一化方法降低初始化参数对训练结果的影响,加快训练速度。

图5 判别器模型
1.2.3 模型训练
生成器模型的训练需要先固定判别器的参数。输入采样于正态分布的噪声z,对z进行一系列的小步幅反卷积操作和归一化操作,输出一批假的语谱图,将它输入到判别器模型。根据式(4)计算生成器模型的损失,依据判别器模型的判别结果以及数据集样本和模拟样本的Wasserstein距离,采用RMSProp算法调整模型的权重参数,最小化Wasserstein距离。
判别器模型的优化需要输入真实样本和生成器生成的样本。根据式(3)来计算判别器模型的损失,判别器模型尽力去拟合出两个输入之间的Wassertein距离,采用RMSProp优化算法调整权重参数。
训练过程采用生成模型和判别模型交替训练方法,为了防止过拟合的问题,加快收敛,在更新一次生成器参数之前,均需要更新判别器参数k次。
1.3 语音情感识别模型
1.3.1 迁移判别器参数
WGAN训练完成时,G可以产生高质量的模拟样本,D学习到大量样本特征。使用迁移学习,充分利用WGAN在训练集上对抗训练学习到的大量知识,将其用于解决语音情感识别率低的问题。本文迁移判别器模型包括除全连接层外的所有网络层参数,新的语音情感识别模型仅需要重新训练最后的LSTM层和分类层,将G生成的模拟样本作为训练集训练情感识别网络。
1.3.2 LSTM网络
由于循环神经网络(RNN)具有强大的记忆功能,适合使用上下文信息对序列数据进行建模,并得到相应的输出。然而RNN在学习长时序信息时,容易出现梯度消失。LSTM是对RNN的一种优化,主要解决了训练长序列信息时出现的梯度消失和梯度爆炸问题[13],图6为LSTM的结构单元。

图6 LSTM结构单元
LSTM的计算公式可表示为
it=σ(Wixxt+Wihht-1+Wicct-1+bi)
(5)
ft=σ(Wfxxt+Wfhht-1+Wfcct-1+bf)
(6)
ot=σ(Woxxt+Wohht-1+Wocct+bo)
(7)
ct=ft·ct-1+it·tanh(Wcxxt+Wchht-1+bc)
(8)
ht=ot·tanh(ct)
(9)
其中,Wfx、Wfh、Wfc、bf为忘记门ft的权重参数和偏置项,Wcx、Wch、bc为记忆单元ct的权重参数和偏置项,Wox、Woh、Woc、bo为输出门ot的权重参数和偏置项,Wix、Wih、Wic、bi为输入门it的权重参数和偏置项,ht为LSTM网络最后的输出值。
利用LSTM网络在时域上的建模能力,将语谱图输入卷积神经网络训练后得到多张特征图。特征图的横坐标表示时域维度,纵坐标表示频域维度,将其进行维度转换,时域维度作为时间步长,特征图数和频域维度作为一个时间步的序列特征输入,将其送到LSTM进一步提取特征。经过对特征图的维度重构后,可以提取到语音样本的深层次长时域上下文特征。
1.3.3 情感识别模型训练
本文将训练完成的生成对抗网络的判别器模型和长短时记忆神经网络应用到小样本语音情感识别中。图7为语音情感识别模型,对训练完成的对抗网络模型中的判别器网络进行参数迁移,去掉最后的全连接分类层,在进行特征图维度转换,连接上两层LSTM网络,隐藏节点数分别为1024、512,添加一层全连接层,通过softmax激活函数进行语音情感识别。在新的情感识别模型中进行参数微调,损失函数采用交叉熵函数,利用随机梯度下降法调整权重参数,使用生成样本训练语音情感识别网络。

图7 语音情感识别模型
1.4 语音情感识别
对于一个输入的语音信号,经过情感识别模型的特征提取得到Fi,将特征Fi输入到全连接层,经过softmax激活函数进行情感映射,即式(10)所示,所输出的最大概率Si为情感识别结果
(10)
2 实验结果与分析
2.1 实验环境与数据集
本文实验环境:操作系统为Windows10,深度学习框架为keras和Tensorflow,GPU为NVIDIA GEFORCE GTX 1060。选择德语情感语料库(EMODB)作为数据样本。EMODB由10名专业录音人对10句文本进行录制,共535条数据,包括7类情绪状态,分别为生气、畏惧、开心、中性、伤心、惊讶、无聊。训练集和测试集的比例设置为7∶1。
2.2 实验设计
2.2.1 WGAN迭代次数对识别率的影响
本实验使用训练集对WGAN进行训练,G和D的更新次数为1∶5。在WGAN不同迭代次数时,每条数据对应生成50张语谱图作为训练集训练本文语音情感识别模型,测试WGAN的迭代次数对语音情感识别准确度的影响。
图8为语谱图在经过多次迭代后生成的模拟样本图片,图9为WGAN的Wasserstein距离图。由图8和图9可以看出,在模型训练的开始阶段,生成的语谱图变化较为剧烈,Wasserstein距离较大。随着实验的不断进行,产生的模拟样本逐渐接近原始的数据样本。当训练迭代次数达到300时,发现图9的Wasserstein距离趋于稳定,说明模型训练近似达到最优,得到了和原始样本在视觉上具有高度相似性并且具有多样性的图像。

图8 产生语谱图效果

图9 生成对抗网络Wasserstein距离
图10表示在本文语音情感识别网络结构下,使用生成器生成模拟样本作为训练集,测试生成对抗网络在不同迭代次数下,对语音情感识别率的影响。

图10 WGAN迭代次数对语音情感识别准确度的影响
由图10可以看出,在WGAN训练初期,由于对抗网络变化剧烈,G生成的样本质量太差,对训练集的扩充作用太小,导致识别率比较低。随着实验的不断进行,生成的语谱图逐渐接近原始数据样本,生成的样本对数据集有了较好的增强效果,使得语音情感识别率逐渐提高。然而实验迭代次数到达300后,语音情感识别准确度趋于稳定,这是因为随着WGAN迭代次数增加,网络逐渐处于收敛状态,G和D都达到了最优状态。
2.2.2 数据增强方法对比实验
在相同条件下,使用本文语音情感识别模型,比较不同的数据增强方法,对情感识别准确度的影响。通过6组对比实验来进行测试,实验一使用原始训练集训练本文情感识别网络。实验二到实验五分别采用对训练集样本等比例随机转动、随机偏移、随机缩放、随机剪切方法将数据扩充50倍。实验六采用WGAN来进行数据增强,在生成器和判别器对抗训练300次时,使用生成器为训练集中每条数据对应生成50条模拟样本作为训练集。
由表1可知,实验一采用不增强数据方式训练语音情感识别网络,识别率为90.47%。实验二和实验三所使用的数据增强方法使得情感识别准确度有所下降,这是因为随机转动,随机偏移改变了语谱图的时序结构,导致丢失了很多情感时频相关性信息,使得准确度下降。实验四和实验五所使用的数据增强方法使得情感识别准确度有略微提高,这是由于随机缩放和随机剪切保持了语谱图中的时频两域信息的相关性,但是产生的增强数据缺少样本多样性,导致模型辨别能力没有大幅度提高。而实验六的准确度相比传统方法有了很大的提高,这是因为WGAN使用语谱图进行训练时,不是简单的对语谱图进行拟合,而是通过G和D的对抗训练对语谱图进行特征学习,训练完成后,G可以生成和原始图像具有高相似度并且多样性丰富的样本图像,使得模型识别能力有了显著提高。

表1 数据增强对语音情感识别率的影响
2.2.3 参数迁移实验
为了验证本文中迁移训练完成的WGAN的判别器参数的有效性,设计了两组对比实验。采用WGAN来进行数据增强,在生成器和判别器对抗训练300次时,使用生成器为每条数据生成50条模拟样本作为训练集。
实验一:使用训练集训练本文情感识别网络。
实验二:迁移训练完成的WGAN的判别器参数到语音情感识别的模型,对其进行修改,去掉最后的全连接层,使用训练集训练本文语音情感识别模型。
由表2可以看出和不迁移模型相比,迁移WGAN判别器可以充分利用WGAN在训练集上对抗训练学习到的大量样本特征知识,且只需要训练情感识别网络的最后LSTM层和分类层,提高了语音情感识别准确度,加快了网络的训练速度,减少了约3/5的模型训练时间。

表2 迁移实验下语音情感识别率和耗时的比较
2.2.4 语音情感识别方法对比实验
为验证本文方法的可行性,通过如下实验来验证。
实验一:采用文献[14]所使用的方法,通过手动提取语音中的基频、共振峰等情感特征,使用SVM进行语音情感识别。
实验二:采用文献[15]提出的CNN模型,将小样本语音数据预处理为梅尔频谱图,使用CNN对频谱图进行特征参数提取并识别。
实验三:采用文献[15]提出的CNN-LSTM模型,使用CNN提取频谱图特征参数,把提取的特征图进行维度转换,将其输入到LSTM层中进行语音情感识别。
实验四:使用小样本语音情感数据对WGAN网络进行训练,训练完成后使用生成器生成模拟语谱图样本,并迁移判别器参数,对其结构进行调整,去掉全连接层,连接上LSTM层,对其参数精调,使用生成模拟数据作为训练集训练情感识别网络。
4种实验下的语音情感识别率见表3。

表3 4种实验下的语音情感识别率
由实验一和实验二可知,采用频谱图和CNN相结合的方法相比传统的语音情感识别方法准确率更高。这是因为传统的语音情感识别方法通过手工提取情感特征,会丢失部分时频特征信息,而CNN通过强大的特征学习能力对频谱图进行自动提取特征,提取到了更深层次的情绪特征,从而准确度更高。实验三使用CNN与LSTM相结合的网络模型进行情感识别,利用CNN对频谱图进行自动提取特征,LSTM对特征图进一步提取时序信息特征,相比单独使用CNN模型提升了情感识别的准确度。然而由于前面的3组实验的训练样本量偏小,模型收敛效果不好,导致准确度不高。而实验四采用本文提出的模型,通过WGAN对抗训练来增强数据,迁移判别器的权重参数到情感识别模型,使得语音情感识别模型收敛速度更快,并且连接上LSTM网络结构后使得模型的识别能力更强,进一步提高识别准确度。
3 结束语
本文提出的一种生成对抗网络模型下小样本语音情感识别方法,使用小样本语音数据对抗训练WGAN,生成器和判别器对抗训练学习样本特征,生成器产生高质量的模拟语谱图样本,解决了实际训练过程中训练数据不足的问题。迁移判别器网络参数到语音情感识别模型,加快了网络的收敛。对其进行参数微调,去掉最后一层全连接层,连接上多层LSTM网络,充分提取语音信号的时频两域相关性信息,添加全连接网络进行语音情感识别,进一步提高了语音情感识别准确度。
