一种改进的数据场和决策图联合聚类算法
2020-12-27陈涛高鹏成
陈涛,高鹏成
哈尔滨工程大学 信息与通信工程学院,黑龙江 哈尔滨 150001
在不断改变的战争形式中,信息化战争已取代传统战争形式成为当今战争的主流形式[1]。雷达信号分选是电子侦察的一个重要的环节,信号分选的成功与否成为电子战发挥作用的标志,甚至会影响战争的最终格局[2]。但是伴随科学技术水平的发展和提高,雷达信号分选面临的电磁环境越来越复杂多变,雷达数量和类型层出不穷,雷达信号错综复杂交叠,杂波干扰等问题。因此,如何对复杂多变的电磁环境中的错综交叠的脉冲信号进行精确和快速的分选,是当今雷达信号分选的重点和难点。
为了处理复杂电磁环境的雷达信号分选,赵贵喜等[3]将数据场引入雷达信号分选的领域,将数据场和K-means 进行联合实现聚类,为雷达信号分选提供新的思路;徐赛等[4]将样本熵作为特征参数进行分选,也取得了不错的成果;Brendan J. Frey 等[5]基于仿射思想提出了一种新的聚类算法,沙作金[6]将数据场结合平面变换技术实现了复杂电磁环境下的雷达信号分选。
现代电子侦察设备每秒能够接收到百万个脉冲信号,这些脉冲信号互相错杂、密集分布,直接应用于雷达信号分选会导致信号处理工作量大,浪费大量的时间,降低时效性。故而,需要对脉冲信号进行预分选处理,降低脉冲信号的密度。聚类是利用数据对象之间的相关性,可以作为预处理步骤,达到降低信号密度的目的。但是传统的如K-means 聚类算法,需要人为预先设置具体的参数信息[7],且对噪声点敏感,聚类的质量受到初始人为设置参数信息的影响。为此,本文提出一种基于数据场和决策图的聚类算法。数据场主要通过计算数据对象的场强函数值累加形成势值,利用势值可以清楚快捷地识别孤立的噪声点。数据场聚类是利用势值的极值确定聚类中心和聚类数目,决策图是依据数据对象的局部密度参数值和到最近大密度点的距离值来确定聚类中心和聚类数目。由于数据场寻极值的步骤繁琐以及决策图对噪声点敏感,故将数据场和决策图做了不同程度的改进,并将两者进行联合聚类,按照数据对象的势值和到最近大密度点的距离实现聚类。
1 数据场
“场”的概念最初是用来描述物质对象之间的作用力,受到场论思想的启发,李德毅院士将物理作用力引入到数据处理领域,创造性地提出数据场的概念。数据场理论认为每一个数据对象的状态值都是场中其他所有数据对象作用力的累积。类同库伦定律,数据对象的作用力与距离成反比,距离越远,作用力越小;距离越近,作用力越大。所有数据对象之间的作用力和作用范围构建了数据场[8]。
1.1 场强函数
如万有引力和库仑定律,将数据场中描述数据对象之间的作用力用场强函数来表征,根据数据对象与距离的关系可以清楚地知晓,数据对象密集的地方场强函数值大,数据对象稀疏的地方场强函数值小。一般用高斯函数来描述数据对象的作用力,场强函数描述数据对象x与y点的作用力为

式中: ρ为数据点的影响能力,鉴于数据对象具备独立性和完整性,设参数值为1;d(x,y)是数据对象x与y点之间的欧式距离[9]; σ是衡量数据对象的作用能力的辐射因子变量。
1.2 势函数
势函数是描述数据对象受到的场强函数的标量累加和,假设存在n个数据对象(x1,x2,···,xn),则数据对象y受到的场强函数累加和表示为

1.3 辐射因子
辐射因子 σ是表征数据点的作用能力,由式(1)可知,场强函数值与辐射因子 σ成正比。假设只存在一个孤立的数据点,在不同辐射因子 σ的基础上,势值随距离的关系图如图1 所示。
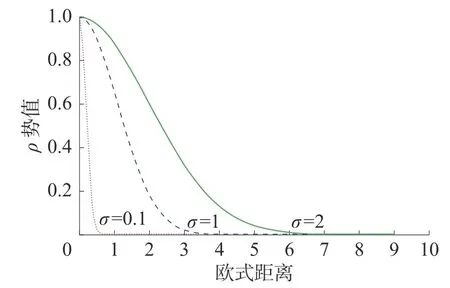
图1 势值随距离关系曲线
从图1 中可以看出,势值随距离呈衰减趋势,且辐射因子 σ越小,衰减的程度越快。辐射因子σ的取值对于势值非常关键,因而,如何选取最合适的辐射因子 σ成为数据场聚类的一个非常重要环节。
为了获取最优的辐射因子 σ,利用描述数据间分布不确定性的熵的概念。一般将在数据场表述数据对象之间的不确定性的熵用势熵来表述。可以利用势熵对辐射因子 σ进行优化选择。假设存在n个数据对象D={x1,x2,···,xn},其相对应每个数据对象的势值为Ψ1,Ψ2,···,Ψn,则相应的势熵的计算公式为
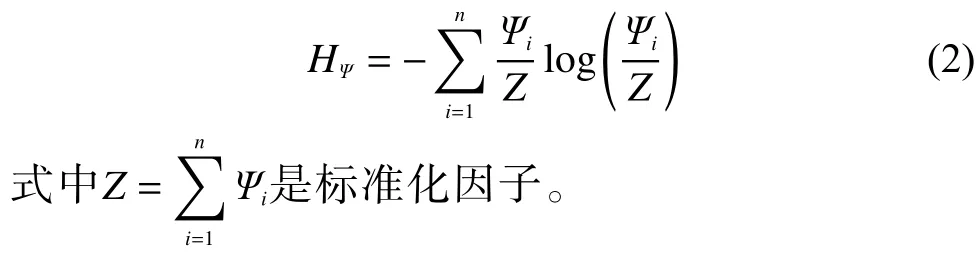
由式(2)可得,0 ≤HΨ≤log(n)。当辐射因子σ参数值变得非常大时,数据场中的每个数据对象的势值都不断趋近相等,每个数据对象之间的分布规律混杂无序,数据对象之间不确定性达到最大,势熵的函数值最大;当辐射因子 σ参数值变得非常小时,数据对象的分布基本有序排布,数据对象之间的不确定性达到最小,势熵的函数值最小。当且仅当辐射因子参数值小到一定时,数据场中的每个数据对象之间可以到达动态平衡,即每个数据对象的势值参数值都趋近相等,即Ψ1=Ψ2=···Ψn,HΨ=log(n)。
数据对象的势熵与辐射因子的关系如图2 所示。由图可知势熵与辐射因子的变化规律为,辐射因子 σ不断增大,势熵值先减小后增大。所以,选取最优的辐射因子就是选择势熵的最小值,即


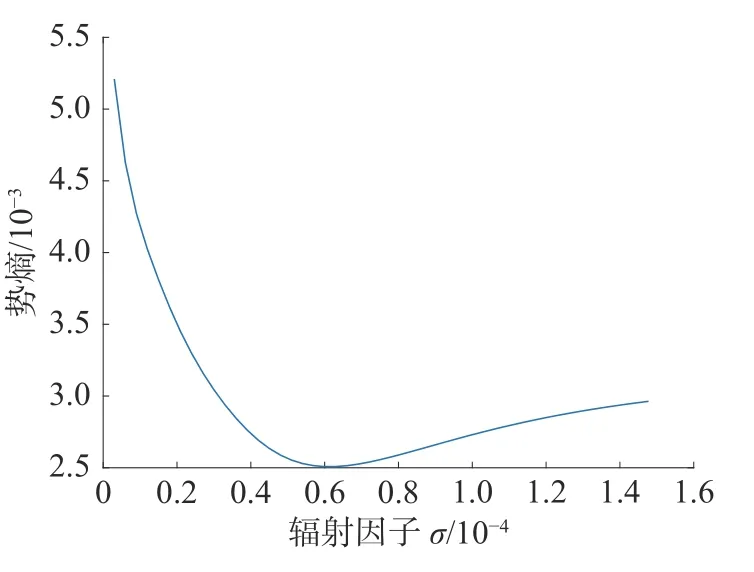
图2 势值与辐射因子关系
1.4 数据场的改进
对数据场进行改进就是需要对场强函数进行改进,但是基于式(1)可知,只要改进辐射因子σ和距离d(x,y)即可。在1.3 节中采用了势熵的概念将寻找辐射因子 σ转变为寻找最小势熵,并利用斐波那契法可以得到最小势熵,即得到辐射因子 σ。故剩下的只需要对距离进行修改。由图1可知数据场不同的辐射因子的作用范围。场强函数的公式满足高斯函数,根据高斯函数具有的“ 3σ”原则,即在±3σ区间内包含99.73%的数据对象,标记的地方就是 3σ位置。因此,每个数据对象的辐射范围是以自身为中心,最大辐射范围是3σ,即数据对象只对处于半径值 3σ内的其他数据对象产生影响,对于距离处于 3σ外的数据对象之间产生的影响力基本忽略不计。因此,可以将场强函数的公式改进为
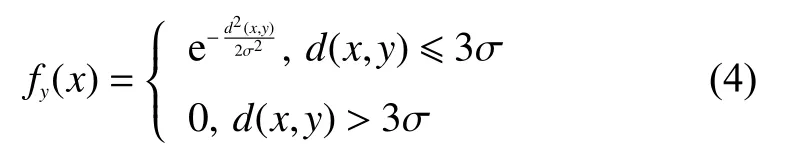
鉴于现实电磁环境中不只存在脉冲信号,还存在大量的噪声干扰等因素,聚类的效果还会受到信号噪声等干扰因素影响。但是噪声点不是真实的脉冲信号,距离会超过聚类中心点的辐射范围,即距离值大于 3σ,孤立噪声点的势值参数值非常接近0,改进的数据场可以使得孤立的噪声点更加容易被识别出,从而剔除。
2 决策图
按照目前存在的聚类算法,大多数都是基于数据对象之间的距离信息进行数据的簇类划分处理,但是这些算法处理数据会需要大量的工作量,消耗大量的时间。2014 年,Rodriguez 等[10]在基于密度聚类算法的基础上进行改进优化,提出了一种快速简捷的搜索聚类中心的聚类算法,并将该算法命名为密度峰值聚类算法。该算法主要是利用数据对象的局部密度值和到最近大密度点的距离形成决策图,再在决策图中处理参数信息得到聚类中心和聚类数目,所以该算法也被称为决策图聚类算法。决策图聚类算法可以实现自动选择聚类中心和聚类数目,且相较于其他聚类算法,决策图聚类算法需要处理的步骤少,能够快捷地得到聚类簇组,节省大量数据处理时间。
2.1 决策图基础
决策图聚类算法可以实现数据对象的快速聚类,核心思想是对聚类中心或密度峰值点进行相关的理论假设:1)每个数据聚类簇组中的聚类中心拥有最大的局部密度参数值,聚类簇组中其他相邻数据点的局部密度值低于聚类中心的局部密度值[11];2)不同数据聚类簇组的聚类中心之间有着比较远的距离,即高局部密度的数据点分布比较远。基于决策图聚类算法的2 个理论假设,决策图聚类算法引入了2 个重要的参数变量,局部密度 ρi以及数据对象到最近大密度点的距离 δi。
假设待聚类的数据对象为D={x1,x2,···,xN},将不同数据对象xi和xj之间的欧式距离参数值设置为dij=distance(xi,xj),则局部密度 ρi以及数据对象到最近大密度点的距离 δi对应的公式如下:
1)局部密度 ρi被定义为
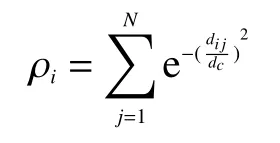
式中参数dc>0被称为截断距离,是衡量决策图聚类算法的一个非常重要的参数变量,利用其参数阈值处理数据对象来得到聚类中心和聚类数目值。但是参数dc是人为选取,一般选择原则是让所有数据对象的局部密度值总和满足待聚类数据对象总数N的2%:

2)最近大密度点的距离 δi被定义为
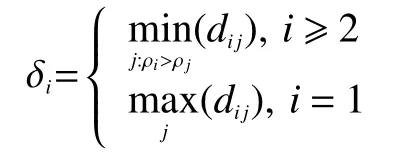
与K-modes 聚类算法类似,峰值密度聚类算法首先需要得到待聚类数据对象的聚类中心,该算法是利用 ρ和δ作为横纵坐标形成决策图,选择图中 ρ和δ都比较大的数据点对应的数据对象作为聚类中心,就是人为选择决策图右上方对应的数据对象为聚类中心,利用局部密度值的靠近原则将其他数据对象点划分到不同的聚类簇组中,从而完成整个数据对象的聚类。
2.2 决策图改进
对决策图的改进主要就是要解决人为选择ρmin和δmin的问题,使其能够实现自动确定所需要的聚类数目。鉴于决策图的聚类思想是聚类中心点拥有较大的局部密度 ρ和最近大密度点的距离 δ参数值,故而可以设置变量 γ,具体的表示为
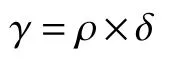
这样可以将变量 γ作为判断聚类中心的变量参数,且变量 γ参数值大的数据点就可以作为聚类中心点,可以通过设置阈值来获取聚类所需要的聚类数目。具体操作是先按照每个数据对象的变量 γ值进行降序排列,再利用相邻数据对象变量γ的比值差来判断,当比值差小于设定的阈值时结束算法。其具体的数学表达式为

式中变量 ε作为阈值判断值,具体参数值根据实验需要设置。
3 数据场联合决策图聚类
数据场聚类所需要的步骤冗杂,需要利用势值参数进行极值判断来确定聚类中心和聚类数目,再来处理脉冲归属问题。孤立噪声点在数据场聚类中能够轻易地被识别剔除,决策图聚类只需要得到变量 γ,利用排序和阈值就能够快捷地确定聚类中心和聚类数目。但对于存在脉冲丢失和噪声干扰的情况下,决策图聚类的效果很差。所以,本文将数据场联合决策图进行数据聚类,具体的步骤如下:
1)对输入的待聚类的雷达数据的脉宽(pulse width, PW)、射频(radio frequency, RF)、波达方向(direction of arrival, DOA)进行归一化处理;
2)根据DOA 参数值对待分选的脉冲信号进行排序,并计算两两脉冲信号之间的欧式距离形成距离矩阵;
3)利用斐波那契法计算得出最佳的辐射因子 σ;
4)利用距离矩阵和最佳的辐射因子 σ计算出势值 φ和最近大密度点的距离δ;
5)对势值 φ和最近大密度点的距离 δ重新进行归一化处理,消除不同计算方式得到数据对象参数的权重问题,同时可以根据势值的大小消除孤立的噪声点;
6)设置变量τ=φ×δ作为判断聚类中心的变量参数,变量 τ参数值大的数据点就是聚类中心点,并利用相邻数据对象的变量 τ的比值差和设定的阈值来确定聚类数目;
7)对剩余的脉冲信号按照靠近原则划分到最近的聚类中。
4 聚类算法仿真
4.1 仿真条件
本文选择了12 部雷达辐射源信号,其中包括常规雷达信号、参差雷达信号、抖动雷达信号、脉组捷变和脉间捷变雷达信号,具体的参数信息如表1 所示,图3 是待聚类的雷达信号。其中,设置脉宽的精度为1 μs,载频的精度为1 MHz,方位角的精度为1°[12]。为了统一待聚类的数据对象之间各个参数的维度量纲,采用min-max 标准将数据对象进行归一化处理,结果为
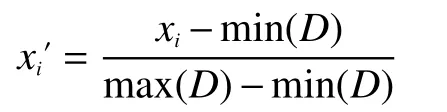
4.2 实验结果与分析
实验1为了验证数据场聚类算法的正确性,对算法进行仿真验证。用Matlab 模拟实际环境中的雷达信号,根据表1 的参数信息生成对应的雷达信号并进行数据场聚类,得到的聚类中心如表2 所示。
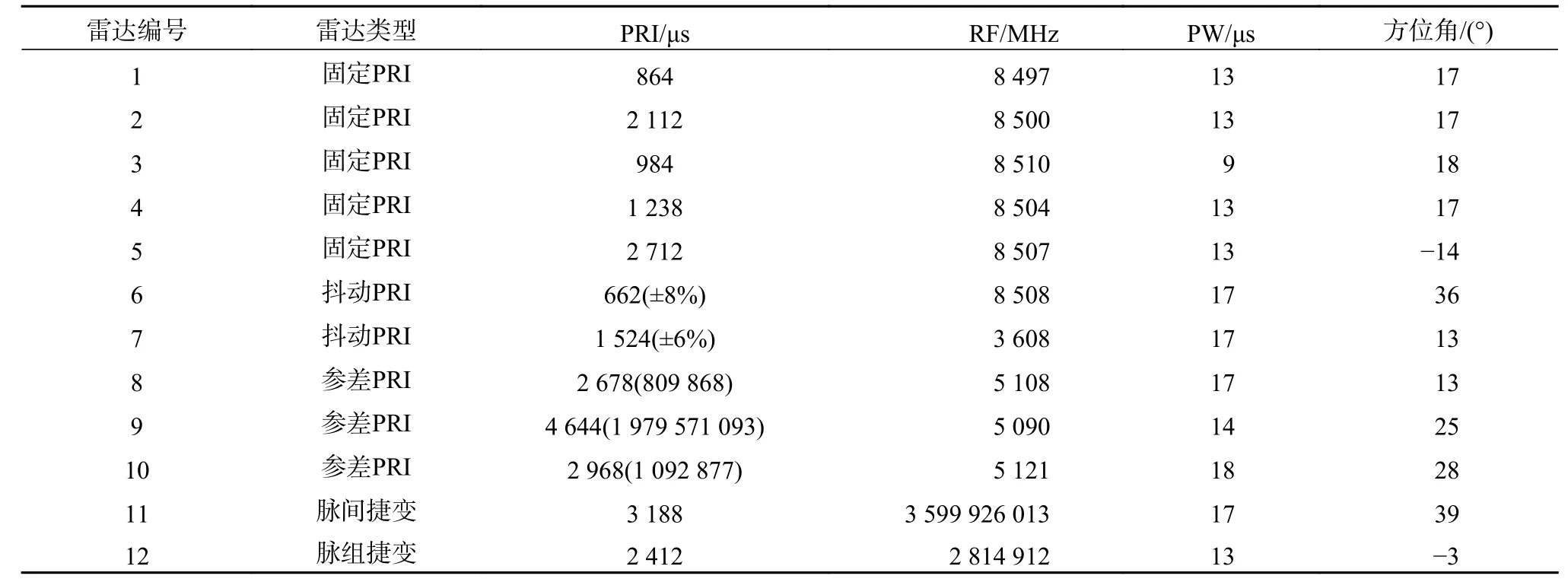
表1 雷达参数设置表
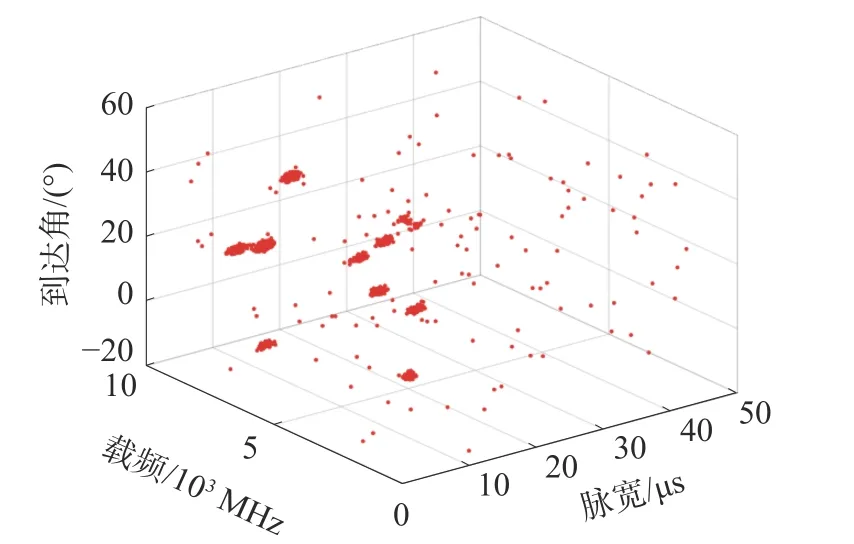
图3 待聚类的雷达信号
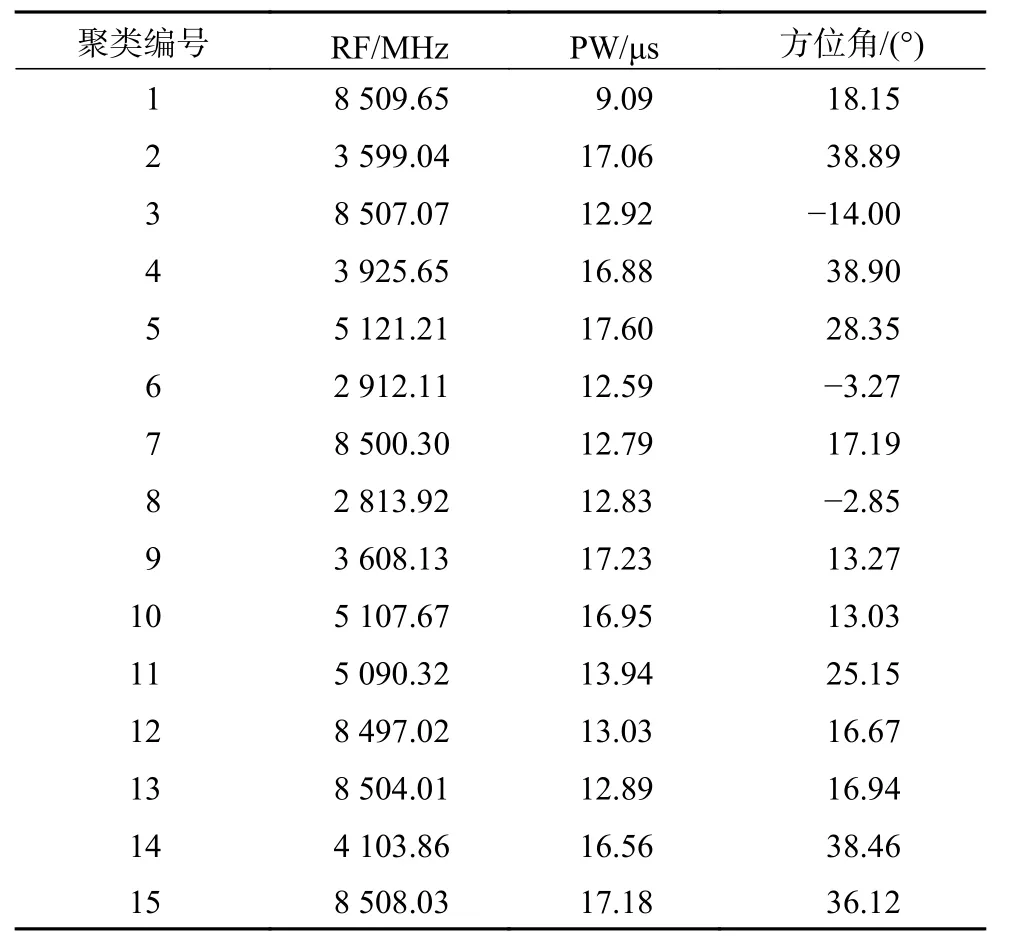
表2 聚类中心参数表
实验2利用式(1)、(4)不同的场强函数重新计算势函数,按照数据场聚类得出每个簇组的聚类中心,并与理论值进行比较,得出不同场强函数下的聚类算法的误差,并进行500 次蒙特卡洛实验,对误差处理得到方差值,图4 是不同场强函数对应的聚类误差图。
仿真结果显示改进的数据场聚类的平均误差要比数据场聚类的误差小,虽然误差值没有得到大幅度改进,但是改进的数据场聚类算法的方差值小,聚类效果稳定,分析图中出现几次误差远大于平均误差的原因是聚类数目比真实聚类数目多,造成同一组数据被分到不同的聚类簇组中,改进的数据场明显减少了这些现象,同时,改进的数据场减少了运算步骤,降低时间的复杂性,加快了聚类的效果,所以改进后的数据场对数据对象聚类的效果会更加好。
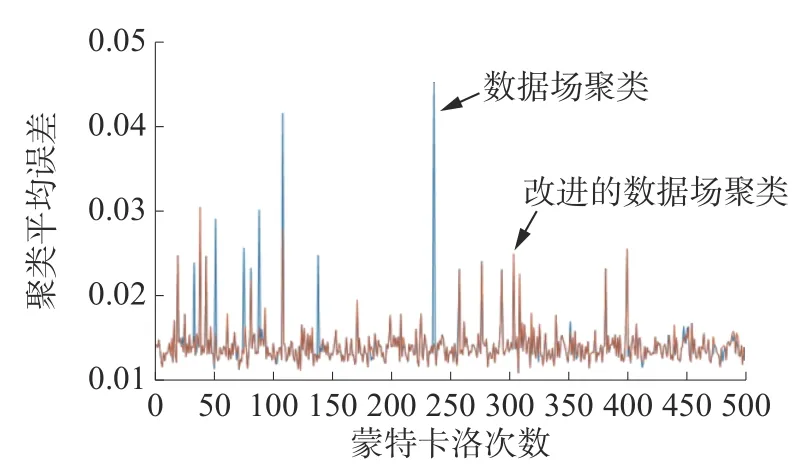
图4 数据场改进前后平均误差对比
实验3利用改进的决策图聚类仿真,忽略脉冲丢失和噪声干扰的情况下,形成图5 基于 γ-n的数据对象聚类决策图和图6 基于 γ-n数据对象聚类局部放大决策图,设置变量ε=1.15,获得前15个聚类中心。
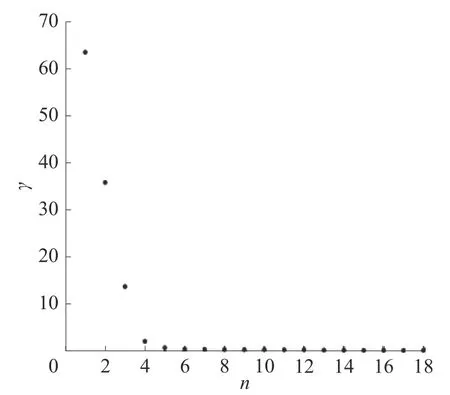
图5 基于γ-n 的数据对象聚类决策
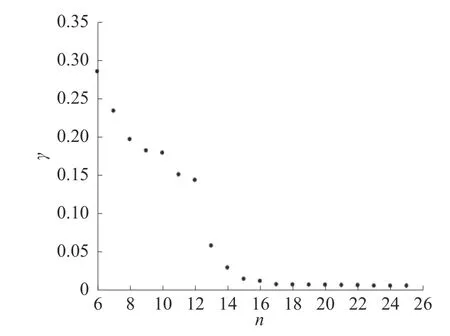
图6 基于γ-n 数据对象聚类局部放大决策
实验4利用改进的数据场联合改进的决策图进行聚类得到聚类中心,连同原数据场聚类得出的每个簇组的聚类中心,分别与理论值进行比较,得出2 种聚类算法的误差,并进行500 次蒙特卡洛实验,对误差处理得到方差值,图7 是不同聚类方式得到的聚类平均误差对比图。
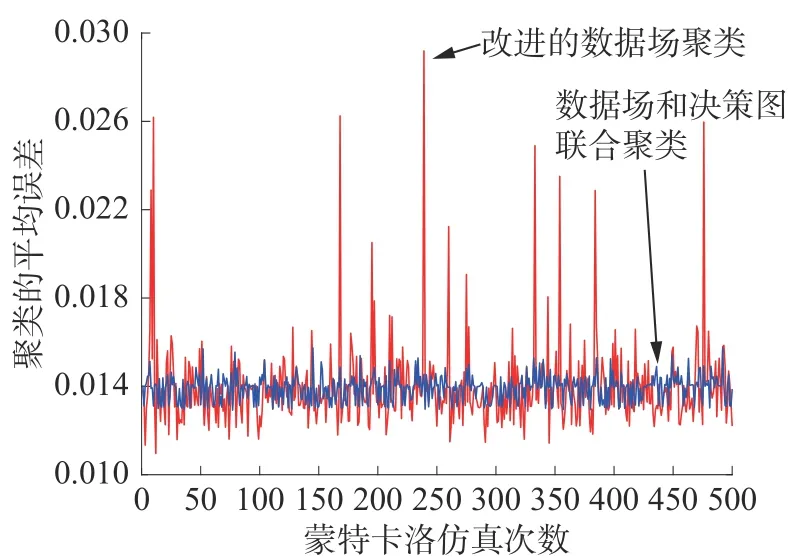
图7 不同聚类方式的聚类平均误差对比
从仿真结果中可以看出,数据场联合决策图的聚类平均误差比改进的数据场的聚类平均误差小,同时对应的方差函数值也比改进的数据场小,说明数据场联合决策图的聚类效果更加稳定,聚类效果更加好。而图中改进的数据场出现几次误差远大于平均误差的原因是聚类数目比真实聚类数目多,造成同一组数据被分到不同的聚类簇组中,数据场联合决策图明显对这种现象做了进一步的改进,基本上解决了这一问题。
5 结论
本文采取了一种改进的数据场和决策图联合聚类算法,主要是根据数据对象的势值和到最近大密度点的距离实现了聚类,且取得了理想的聚类效果。
1)改进的数据场能够更加快捷地处理孤立的噪声点,聚类的平均误差更加小,聚类效果更加稳定。
2)决策图实现了快速获得聚类中心和聚类数目的效果,在无噪声和脉冲丢失的情况下,聚类效果好。
3)数据场联合决策图聚类算法在能够处理孤立噪声点的基础上,克服了决策图对噪声和脉冲丢失的缺陷,联合聚类的效果更加显著。
经过仿真实验表明,本文提出的聚类算法在复杂的电磁环境下能够实现聚类功能,且有很好的聚类效果。但是联合聚类算法需要的时间复杂性更高些,聚类的时间会比数据场略多,后续需要对时间复杂性作进一步的研究,以缩短聚类的时间。
