一种基于谱减法的语音增强算法研究
2020-12-26刘雅琴甘文丽
刘雅琴, 甘文丽
(洛阳师范学院 信息技术学院, 河南 洛阳 471934)
0 引言
语音增强是从带噪语音信号或者受干扰信号中提取出纯净的原始语音。随着语音识别和语音通信技术的发展,语音增强广泛应用于各种受到噪声污染影响语音质量环境中。由于噪声来源众多,随应用场合不同,其特性也各不相同,因而难以找出一种通用的语音增强算法适用于各种噪声环境。必须针对不同噪声,采取不同的语音增强算法。常用的语音增强方法有:滤波器法[1]、谱减法、子空间法、小波变换法和神经网络等[2-3],上个世纪70年代后期产生的谱减法,具有算法简单,处理宽带噪声效果明显的特点,成为单通道噪声处理中常用增强技术[4]。
本文从理论上分析基本谱减法,并给出功率谱减法的实现步骤,在此基础上为了减少谱估计的误差,引入噪声谱估计系数a。在Matlab平台上,对加入高斯白噪声的带噪语音信号使用该算法进行降噪处理,并对不同信噪比的情况做对比研究。
1 谱减法的基本原理
谱减法是常用的语音增强算法,其核心思想[5]:首先对带噪语音信号进行傅里叶变换,得到相应的幅值和相位谱,计算带噪语音信号的功率谱和噪声信号的功率谱;第二,将带噪语音信号的功率谱减去噪声信号的功率谱,则得到纯净语音信号的功率谱;最后,对得到的功率谱开方,得到相应的幅度谱,其相位谱用第一步得到的带噪语音信号的相位谱代替,进行傅里叶反变换则得到增强后的语音信号。
设纯净的平稳语音信号为s(t),噪声语音信号为n(t),要求噪声和语音不相关,则谱减法的基本步骤如下。
1) 得到加性的带噪语音信号,如式(1)。
y(t)=s(t)+n(t)
(1)
2) 对式(1)两边进行傅里叶变换,如式(2)。
Y(ω)=S(ω)+N(ω)
(2)
Y(ω)用极坐标表示,如式(3)。
Y(ω)=|Y(ω)|ejφy(ω)
(3)
式中,|Y(ω)|是带噪信号的幅度谱,φy(ω)是带噪信号的相位谱。
噪声信号N(ω)用极坐标表示,如式(4)。
N(ω)=|N(ω)|ejφn(ω)
(4)
式中,N(ω)是噪声信号的幅度谱,φn(ω)是带噪信号的相位谱。N(ω)是未知的,可以用语音前导无话段的幅度谱估计,φn(ω)根据语音信号对相位的不灵敏性,可用带噪信号的相位谱φy(ω)代替。经过这样代替虽然对语音质量有一定的影响,但不影响语音的可懂性。
3) 计算功率谱,如式(5)。
(5)
由于语音是非平稳信号,通过加窗处理得到一帧语音信号,从而得到相对平稳信号,计算这一帧信号的功率谱,如式(6)。

(6)
(7)

(8)
对于短时平稳信号,如式(9)。
(9)
4) 变换式(9)得到增强后的语音估值,如式(10)。
(10)
5) 由式(10)以及结合2)求得的带噪语音信号的相位,求出增强后语音信号极坐标形式,再经过傅里叶反变换得到增强后语音信号,如式(11)、式(12)。
(11)
(12)
2 基于谱减法的语音识别实现
2.1 实现步骤
本系统对于上述的基本功率谱谱减算法进行了改进,在求增强后的纯净语音能量谱估值时,增加了噪声谱系数a,具体实现步骤如下。
1) 读入纯净语音信号s(t),消除该语音信号直流分量并进行归一化处理。
2) 设置信噪比,叠加高斯白噪声,得到带噪语音信号y(t)。
3) 分帧,加海明窗,设置帧长200,帧移80,保留所得的帧数。
4) 进行FFT变换,计算幅值和相位,再求其功率谱能量|Yw(ω)|2。
5) 设定带噪语音前导静音段时间,计算出静音段的帧数,求其平均幅值|Dw(ω)|2,作为噪声的估值。

图1 谱减法实现流程图
2.2 实现结果及分析
本系统的语音为较为纯净的实验室环境下,采用Windows7自带录音机录音,语音内容为“洛阳师范学院”,单声道,PCM编码,位数8位,频率16 kHz,噪声为随机产生的高斯白噪声,系统的算法在Matlab平台上实现。实验室环境下纯净语音“洛阳师范学院”波形图,如图2所示。
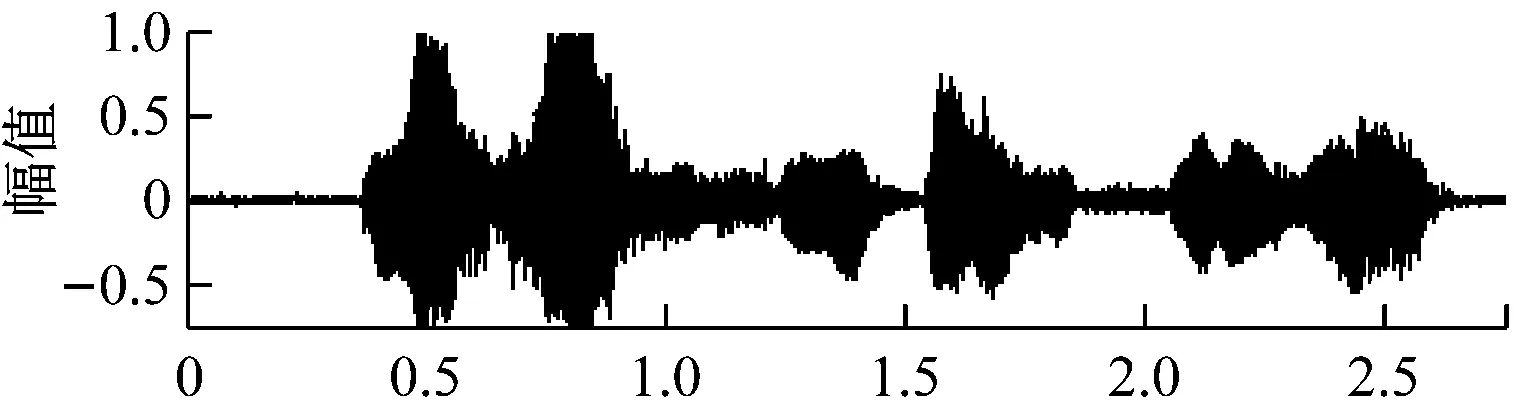
图2 纯净语音“洛阳师范学院”波形图
本实验对输入信噪比分别为5 dB、0 dB、-5 dB、-10 dB的四种情况分别进行了增强测试。测试结果波形图,如图3、图4所示。

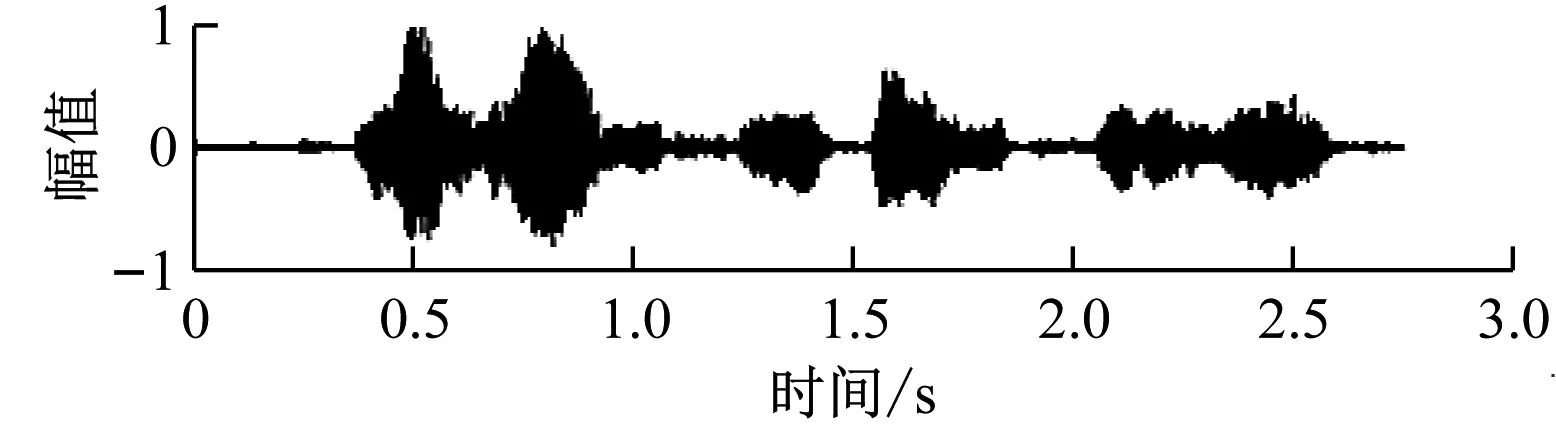


图3 信噪比5 dB、0 dB的测试结果
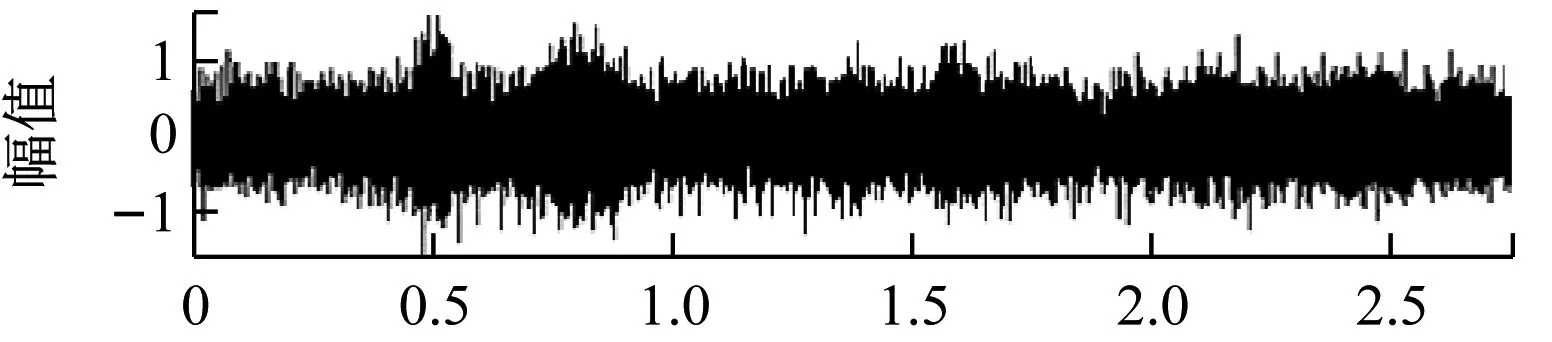


图4 信噪比-5 dB、-10 dB的测试结果
为了更加清晰看出不同信噪比下的效果,计算出不同情况的谱减法增强后信噪比,如表1所示。

表1 不同信噪比输出结果对比
通过对不同信噪比下增强结果的对比分析得到,输入信噪越低,增强后的信噪比提高越多,对于低信噪比的语音信号增强有一定的效果。
在实验中也发现,当信噪比高于20 dB,增强后的信噪比反而下降,说明该算法对于高信噪比的语音信号增强效果不明显,主要因为一是增加的噪声不明显,二是原本录制的语音不纯净;当信噪比低于-16 dB,虽然增强后信噪比提高了,但是人耳已经很难分辨语音信号的内容,语音全部被噪声淹没。因受谱减法本身的限制,采取的是功率谱预估,产生误差,为了对以上两种情况进行语音增强,为此要寻求新的增强算法[6]。
3 总结
本文从理论上分析语音增强的谱减法,给出了基于功率谱的谱减法的完整步骤,在此基础上为了消除谱减法功率谱估计的误差,在求增强后纯净语音信号的功率谱中引入系数a。在Matlab平台上对加入高斯白噪声,信噪比分别为5 dB、0 dB、-5 dB、-10 dB四种情况带噪语音信号进行了仿真验证,结果表明输入信噪越低,增强后的信噪比提高越多,该算法对于低信噪比的语音信号增强有一定的效果。但是当信噪比低于-16 dB,不能分辨出语音信号;当信噪比高于20 dB,难于消除纯净语音在录音时本身所带的噪音。针对这两种情况,将更加深入研究,提出更加高效的增强算法。
