基于DA-Elman的铁路货运量预测
2020-12-26宋伟张杨
宋伟, 张杨
(1.陕西广播电视大学 开放教育学院, 陕西 西安 710068; 2.国际商业机器公司, 陕西 西安 710100)
0 引言
铁路货运量预测对国家和区域经济发展规划具有至关重要的参考作用,高精度的铁路货运量预测为铁路发展规划的制定和运输企业的运营决策提供科学决策的依据和参考[1]。目前,铁路货运量预测方法主要有灰色理论[2]、广义回归神经网络[3]、BP神经网络[4]、径向基神经网络[5]、Rough Set理论[6]、分形理论[7]、支持向量机[8]以及Elman神经网络[9-11]等,但这些方法普遍具有预测精度低和滞后性明显的缺点,需要进行定性分析和修正。
蜻蜓算法[12](dragonfly algorithm,DA)是受蜻蜓两个聚集群体(迁徙群体和觅食群体)启发所提出的群搜索智能算法。该算法具有控制参数少、复杂度低和计算速度快等优点,被广泛地应用于模式识别、参数优化、工程优化设计等问题。针对极限学习机(extreme learning machine,ELM)模型性能受其初始权值和偏置的影响,文献[13]将DA算法应用于ELM模型参数优化,实现小麦发芽粒和小麦虫蛀粒检测。为提高概率神经网络(probabilistic neural networks,PNN)湖库营养状态识别精度,文献[14]应用DA优化PNN模型的平滑因子,结果表明,DA可以有效提高PNN模型识别精度。为实现PID控制器最优化控制,文献[15]选择误差性能指标ITAE为DA算法的适应度函数,运用DA算法优化PID控制器,实现PID控制器最优控制。与粒子群算法、布谷鸟算法和人工蜂群算法相比,DA优化PID控制器参数具有更优的控制性能。
针对Elman神经网络(elman neural network,ENN)模型性能受权值和阈值选择的影响,为提高铁路货运量预测的精度,运用蜻蜓算法优化选择ENN模型的权值和阈值,提出一种DA优化Elman神经网络的铁路货运量预测方法。实证结果表明,与PSO-Elman和Elman相比,DA-Elman的铁路货运量预测精度最高,为铁路货运量预测提供了新的方法和科学决策的依据。
1 蜻蜓算法
在DA算法中,蜻蜓个体在避撞、结对、聚集、觅食和避敌等行为综合作用下进行觅食和寻优,不同行为描述如下[16-17]。对于第i个蜻蜓,其避撞、结对、聚集、觅食和避敌等行为的位置更新,如式(1)—式(5)。
(1)

(2)

(3)
Fi=X+-X
(4)
Ei=X-+X
(5)
式中,X为当前蜻蜓个体的位置;N为相邻蜻蜓个体的数量;Xj和Vj分别为第j个邻近蜻蜓个体位置和速度;X+和X-分别为食物源位置和天敌位置。
在5种蜻蜓群体行为综合作用下,蜻蜓个体的步长向量更新策略,如式(6)。
ΔXt+1=(sSi+aAi+cCi+fFi+eEi)+wΔXt
(6)
式中,w为惯性权重;s、a、c、f、e分别为不同行为的权重;t为当前迭代次数。
蜻蜓个体的位置更新数学模型,如式(7)。
Xt+1=Xt+ΔXt+1
(7)
2 Elman神经网络
ENN由输入层(Input Layer)、隐含层(Hidden Layer)、关联层(Association Layer)和输出层(Output Layer)组成,其为局部反馈连接的前向神经网络。其结构示意图,如图1所示。
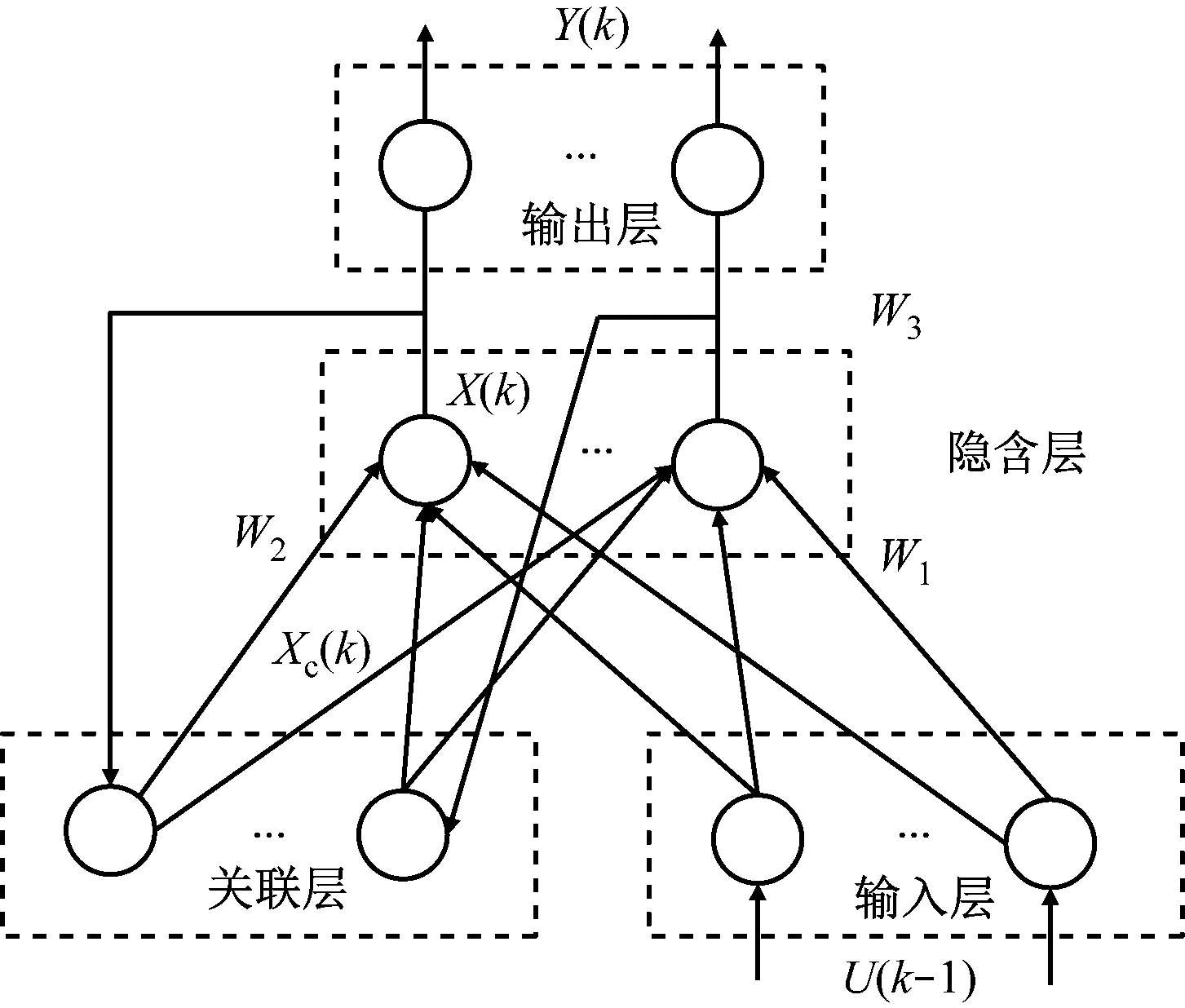
图1 Elman神经结构示意图
与传统的静态前向神经网络相比,ENN网络增加了一个关联层,也叫连接层,该层从隐含层接受反馈信号,隐含层节点数与关联层节点数相等,两者一一对应进行连接。图1中,W1为输入层到隐含层的权值矩阵;W2为关联层到隐含层的权值矩阵;W3为隐含层到输出层的权值矩阵;U(k-1)、X(k)、Y(k)和Xc(k)分别为ENN的输入向量、隐含层输出向量、ENN的输出向量和关联层的输出向量,其数学模型[18],如式(8)。

(8)
式中,b1为隐含层的阈值;f(x) 和g(x)分别为隐含层和输出层的传递函数;b2为输出层的阈值。
3 基于DA-Elman的铁路货运量预测
3.1 适应度函数
针对ENN预测精度受其权值和阈值的影响,本文运用DA对ENN网络的权值和阈值进行优化选择,DA-Elman模型的适应度函数,如式(9)。
s.t.W1∈[W1min,W1max]
W2∈[W2min,W2max]
W3∈[W3min,W3max]
b1∈[b1min,b1max]
b2∈[b2min,b2max]
(9)
式中,n为训练集个数;x(i)和y(i)分别为第i个样本的实际货运量和预测货运量。[W1min,W1max]、[W2min,W2max]、[W3min,W3max]、[b1min,b1max]、[b2min,b2max]分别为W1、W2、W3、b1、b2的取值范围。
3.2 算法步骤
基于DA-Elman的铁路货运量预测算法步骤如下。
Step1:读取铁路货运量数据,划分训练集和测试集,并归一化处理,如式(10)。

(10)
式中,x′为归一化之后的数据;x,xmax,xmin分别为原始数据、原始数据中的最大值和最小值;a、b为归一化之后的最小值和最大值,文中a=-1,b=1;
Step2:初始化DA参数:当前迭代次数t、最大迭代次数T、种群规模N和优化变量的上下限[W1min,W1max]、[W2min,W2max]、[W3min,W3max]、[b1min,b1max]、[b2min,b2max];
Step3:随机初始化初始位置X和步长ΔX;
Step4:令t=1,将训练集带入Elman模型,运用式(9)计算蜻蜓个体的适应度并排序,记录和保存当前最优解;
Step5:更新食物源位置X+、天敌位置X-以及s、a、c、f、e和惯性权重w;
Step6:按式(1)~(5)更新S、A、C、E和F;
Step7:按式(6)~(7)更新步长和位置;
Step8:若t>T,输出和保存ENN模型的最优权值和阈值;否则,t=t+1,返回Step4;
Step9:将ENN模型的最优权值和阈值代入Elman进行铁路货运量预测。
4 实证分析
4.1 数据来源
为了说明DA-Elman铁路货运量预测模型的有效性和可靠性,选择我国2000-2018年铁路货运量数据为研究对象,数据来源于国家数据网http://data.stats.gov.cn/,2000-2018年我国铁路货运量序列,如图2所示。

图2 2000-2018年我国铁路货运量图
由于影响铁路货运量的因素很多,将铁路货运量作为DA-Elman的输出,国内生产总值、铁路货运量、公路货运量、公路运营路程、铁路运营路程、铁路复线比例、铁路货物周转量和铁路运输从业人员等影响货运量的因素作为DA-Elman的输入。2000~2012年铁路货运量数据作为训练集,2013~2018年铁路货运量数据作为测试集,前者建立DA-Elman铁路货运量预测模型,后者验证DA-Elman铁路货运量预测模型的精度。
4.2 评价指标
选择相关系数R和均方根误差(root mean square error,RMSE)作为铁路货运量预测效果的评价指标[19-21],如式(11)、式(12)。
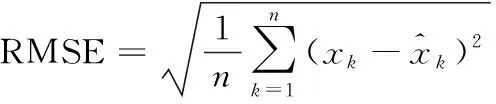
(11)
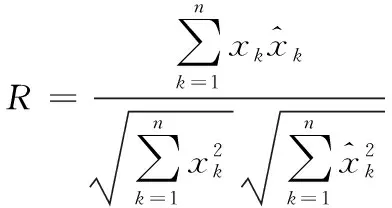
(12)
4.3 结果分析
Elman网络参数为:N1=8,N2=16,N3=1;DA参数:最大迭代次数T=100,种群规模N=10,DA-Elman模型预测结果,如图3所示。
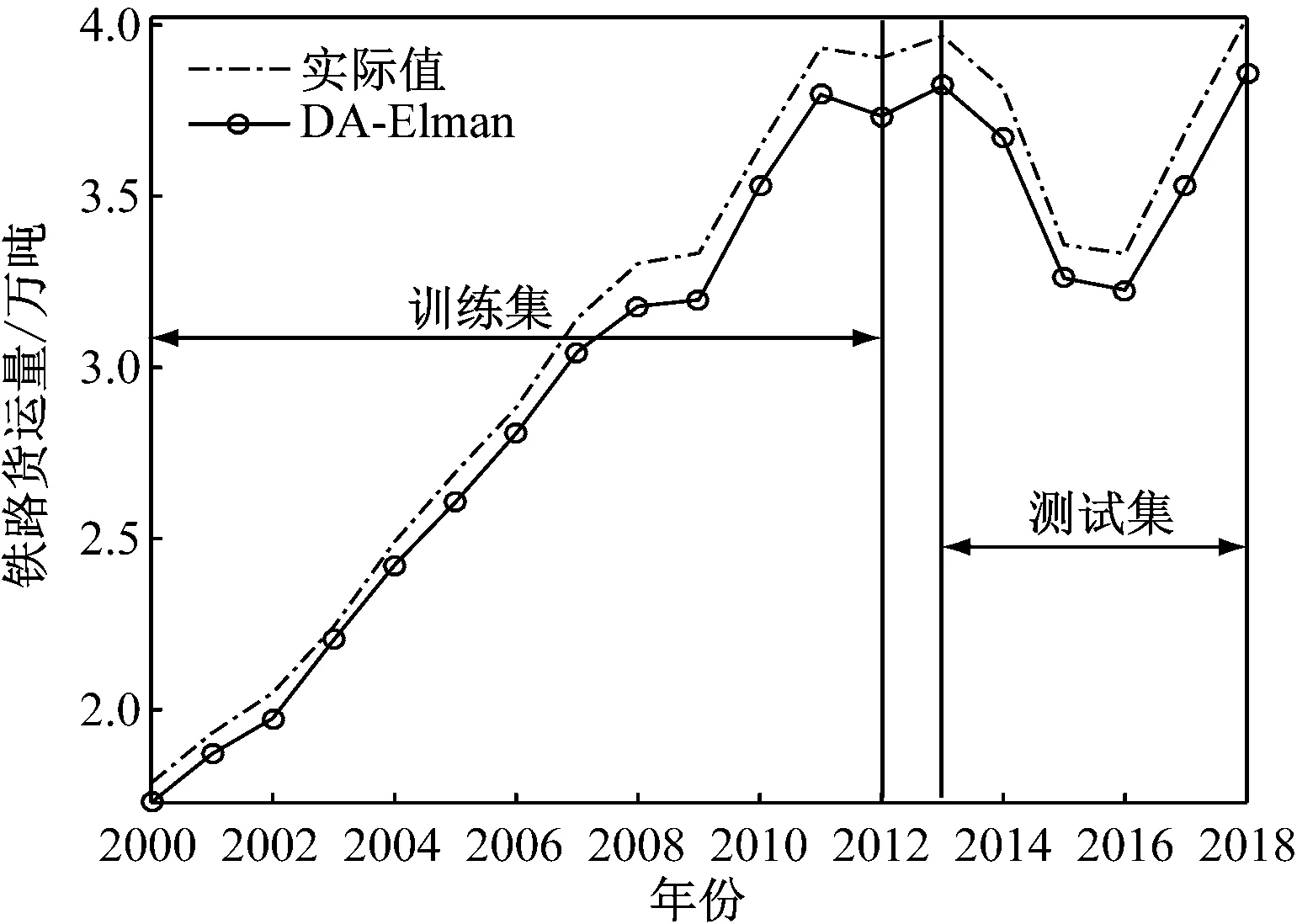
图3 DA-Elman铁路货运量预测结果
RMSE与种群规模关系图可知,随着种群规模的增加,预测误差呈现增大趋势,因此文中种群规模统一设定为10,如图4所示。

图4 RMSE与种群规模关系图
将DA-Elman与PSO-Elman和Elman进行对比,粒子群算法(Particle Swarm Optimization Algorithm,PSO):最大迭代次数T=100,学习因子c1=c2=2,种群规模N=10。预测结果对比,如图5和表1所示。
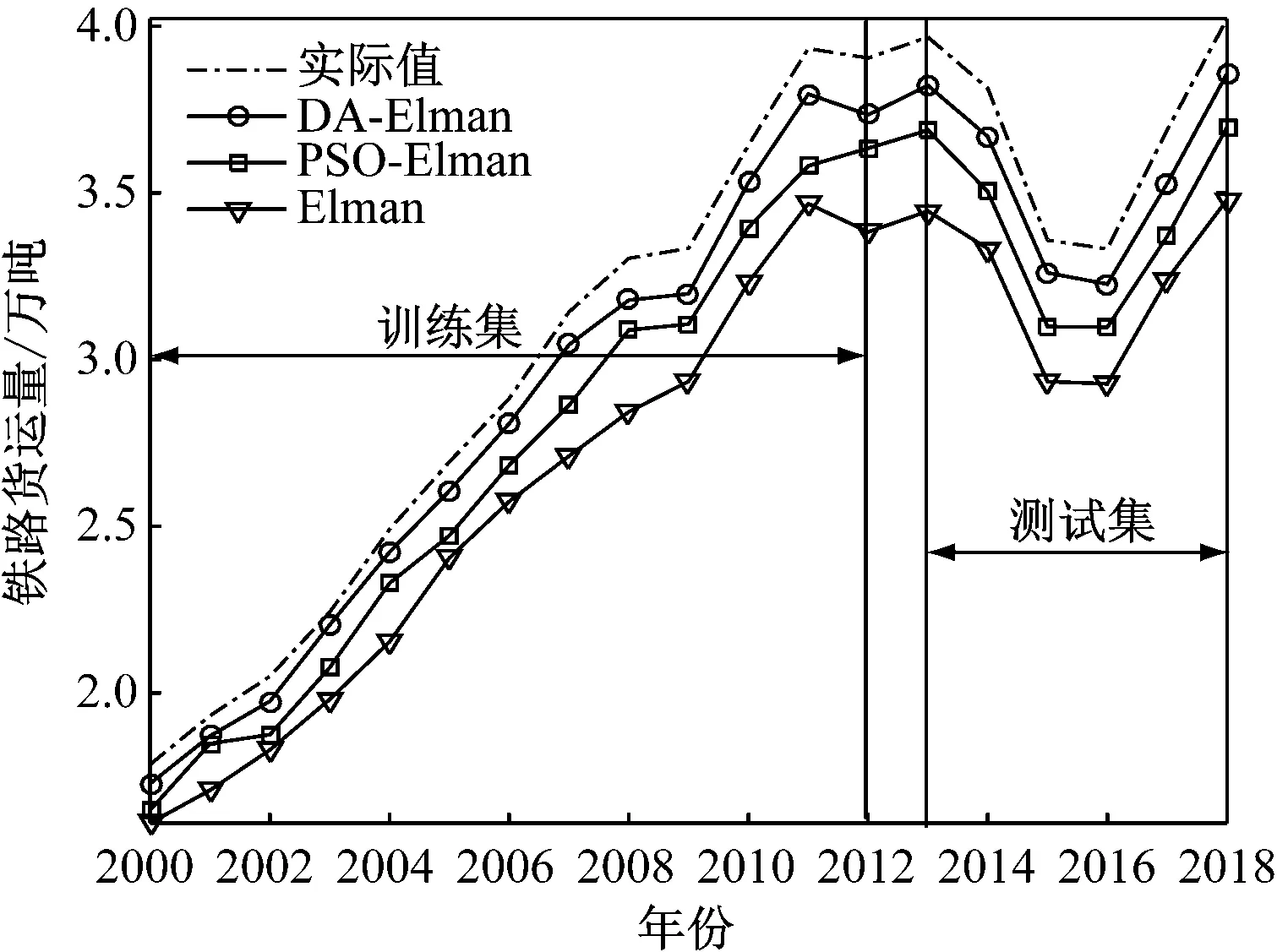
图5 预测对比图

表1 预测结果对比
由图5和表1可知:(1) 从铁路货运量整体预测结果角度来看,在训练集和测试集上,DA-Elman的RMSE最小且R达到最大,说明DA-Elman的铁路货运量预测值和铁路货运量实际值关联程度最高,预测效果最好,DA-Elman优于PSO-Elman和Elman;(2) DA-Elman和PSO-Elman预测精度优于Elman,主要原因在于DA和PSO优化选择了Elman模型参数,从而提高了Elman模型的预测精度。为了给铁路部门和运输企业提供科学决策的依据,运用DA-Elman铁路货运量预测模型对我国2019年~2021年的铁路货运量进行预测,如图6所示。

图6 铁路货运量2019~2021年预测结果
2019年~2021年我国铁路货运量预测结果分别为404 212万吨、406 103万吨和407 138万吨。综合分析可知,与PSO-Elman和Elman相比,DA-Elman的铁路货运量预测精度最高,为铁路货运量预测提供了新的方法和科学决策的依据。
5 总结
为提高铁路货运量预测精度,针对ENN预测精度受其权值和阈值的影响,提出一种基于DA-Elman的铁路货运量预测方法。选择我国2000-2018年铁路货运量数据为研究对象,研究结果表明,与PSO-Elman和Elman相比,DA-Elman的铁路货运量预测精度最高,为铁路货运量预测提供了新的方法和科学决策的依据。
