基于区块链分布优化的大数据融合QM模型研究
2020-12-26王国军胡静汪瑾
王国军, 胡静, 汪瑾
(国网宁夏电力有限公司, 宁夏 银川 750001)
0 引言
大数据领域的关键问题是如何将大数据表示为一个统一的模型,以及如何有效地降低大数据的维数[1]。结构化大数据、非结构化大数据和半结构化大数据全都有代表其独特特征的表示模型,却没有统一的模型能够统一表示这三类数据[2]。大量的区块链分布大数据分布在网络空间中,形成规模庞大的网络资源库,使得现有算法难以有效地处理大数据,从而降低了计算结果的精度,相关的大数据融合模型方面的研究受到了人们对的广泛关注。
李红等[3]提出大数据时代数据融合质量评价模型,该模型可扩展至多个数据库融合的状况,实现数据融合质量的提升。Birrenkott等[4]提出一种基于光容积描记的稳健大数据融合模型,评估每个调制的呼吸质量,同时对各个RQI进行融合,以获得每个时间窗调制的单个RQI,并对剩余调制进行加权,以提供每个时间窗的单个RR估计,以此建立大数据融合模型。Shen Wang等[5]提出了一种基于区块链的优化模型和体系结构,并在此基础上,提出了一种两阶段的调度算法,提高了分布式数据先进控制方法。
基于此,本文提出基于压缩感知和模糊分区调度的区块链分布大数据融合模型,通过仿真实验验证,得出有效性结论。
1 数据的分块存储结构模型及信息聚类
1.1 区块链分布大数据的分块存储结构模型
为了实现基于区块链分布优化的大数据融合QM模型设计,首先构建区块链分布大数据的分块存储结构模型,根据区块链分布大数据的属性分布进行共享调度,得到区块链分布大数据信息评价结构模型,采用分块调度的方法进行区块链分布大数据的分块存储结构设计,建立区块链分布大数据分布式融合模型,提高区块链分布大数据的检测和特征分辨能力,根据上述分析,进行区块链分布大数据的分块存储模型设计,如图1所示。

图1 区块链分布大数据的分块存储结构模型
图1中,区块链的用户接口采集到用户数据集后,将其输入到资源调度器中,根据资源的固定属性特征匹配到各自的客户端,如:服务器-客户机(CS)和用户网络边缘设备(CE)中,在这个过程中,讲用户数据设为副本集合,进行副本管理,然后根据设置好的计算机原件参数进行副本优化,形成存储元件,完成分块储存。
在云计算环境下,进行区块链分布大数据QM融合集构造,区块链分布大数据的存储模型表示为一个p维矢量,区块链分布大数据的信息分布式迁移特征量,如式(1)。
PQ=(ek+vk)×Ut
(1)
式中,ek表示区块链大数据的特征数量值,vk表示特征基数值,Ut表示区块链大数据的信息基量;用云计算方法实现区块链分布大数据的大数据库重建,提取区块链分布大数据的关联规则特征集,采用有向图模型构建区块链分布大数据的量化评价节点分布结构,在区块链分布大数据信息库中进行模糊关联特征提取和信息匹配[6],构造区块链分布大数据的线性组合模型表达式,如式(2)、式(3)。
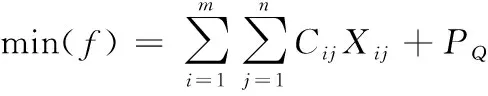
(2)
(3)
式中,Cij表示更新支撑集,Xij表示所选索引特征参数集,由此得到区块链分布大数据QM融合模型,根据存储节点分布,进行区块链分布大数据QM融合。
1.2 区块链分布大数据的大数据挖掘
在构建区块链分布大数据的异构存储结构模型的基础上,提取区块链分布大数据的关联规则特征量,采用云计算技术实现区块链分布大数据分块QM融合,构建区块链分布大数据的自适应调度参数▽2F(x),描述区块链分布大数据QM融合的约束参量,如式(4)。
2JT(x)J(x)+2S(x)
(4)
式中,JT表示线性组合模型信息匹配值,J(x)表示融合约束数据特征量,S(x)表示区块链分布大数据QM融合节点。结合最优时延均衡控制方法进行分块区域调度,设区块链分布大数据的特征映射为f(k),在大数据分布区域,进行区块链分布大数据的分布式检测和信息聚类[7],到区块链分布大数据QM融合的计算公式,如式(5)。
Ui,j(t)=exp[B[zi(t)-zj(t)]2]
(5)
式中,zi(t)和zj(t)分别表示区块链分布大数据共享的模糊决策增量值和决策减量值。采用相关性的统计分析方法,得到区块链分布大数据共享度,如式(6)。

(6)
式中,pi,j(t)表示区块链分布大数据共享的模糊相关性特征分布集,用4元组(Ei,Ej,d,t)来表示区块链分布大数据共享调度的主特征量,根据上述分析,建立区块链分布大数据信息融合及QM融合的关联函数,如式(7)。
(7)
式中,P(d|t,ci)为ci类区块链分布大数据共享调度的分布概率,在语义本体模型中执行区块链分布大数据的样本统计,得到区块链分布大数据信息采样的n个统计变量,实现数据挖掘[8]。
2 大数据融合QM模型优化
2.1 分布大数据的统计特征量提取
在上述进行区块链分布大数据的异构存储结构模型设计的基础上,进行大数据融合QM模型优化设计,基于压缩感知和模糊分区调度的区块链分布大数据融合模型,分析各数据模块的参数特征,反复进特征融合,以此对混合型的区块链分布大数据进行关联特征分布式检测[9]。
定义1: 在模糊聚类中心提取区块链分布大数据的粗糙集特征量,结合模糊关联特征检测方法进行区块链分布大数据的信息重组,区块链分布大数据的融合系数满足标准正态分布X~Sα(σ,β,μ),0<α<2,则区块链分布大数据的融合问题为一个共线性问题,如式(8)。
cx+b~Sα(|c|σ,sgn(c),cμ+b)
(8)
定义2:在时频域内,区块链分布大数据线性测量特征值满足X~Sα(σ,β,μ),1<α<2,则区块链分布大数据的QM信息融合度,如式(9)。
E(x)=μ
(9)
定义3:如果区块链分布大数据分布满足凸组合模型X~Sα(1,β,0),1<α<2,即区块链分布大数据索引对应的列矩阵X正偏,区块链分布检测的误差,如式(10)。
(10)
根据上述定义,得到区块链分布大数据索引的关联特征分布式检测结果表示如下。
m1(d1)=0.177 0,m1(d2)=0.166 5,m1(d3)=0.259 7,m1(Θ)=0.396 8
m2(d1)=0.239 3,m2(d2)=0.221 4,m2(d3)=0.328 6,m2(Θ)=0.210 7
在校验块Dn中,进行区块链分布大数据的特征分块匹配,从而实现区块链分布大数据的信息融合聚类处理,提高区块链分布大数据的查全率。采用回归检验和演化博弈方法进行区块链分布大数据融合过程中的定量递归分析,结合递归分析结果,进行数据融合的QM模型设计。
2.2 大数据融合QM模型优化
提取区块链分布大数据的统计特征量,采用回归检验和演化博弈方法进行区块链分布大数据融合过程中的定量递归分析[10],构建区块链分布大数据检索模型,得到数据的融合尺度,如式(11)。
(11)
计算数据的新近似值和新残差,得到统计特征量J(Wi)可以用如下形式简化,如式(12)。
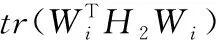
(12)
式中,H2表示统计特征量数据融合高度,Wi表示统计特征量数据融合元素。将压缩感知重构算法用于在数据融合中,采用最速下降法和梯度投影方法进行区块链分布大数据融合处理,得到区块链分布大数据的特征检测模型描述,如式(13)、式(14)。
R1(k)=R2(k)exp(-jω0Tp/2),k=0,1,…,(N-3)/2
(13)
R2(k)=Akexp(jφk),k=0,1,…,(N-3)/2
(14)
沿着目标函数值下降方向,建立区块链分布大数据检测模型,如式(15)。
JI(nTB)=Acos(n×2πΔfTB)-Bsin(n×2πΔfTB)=
Ccos(n×2πΔfTB-θ)
(15)
采用回归检验和演化博弈方法进行区块链分布大数据融合过程中的定量递归分析,提取区块链分布大数据的关联规则特征量,得到区块链分布大数据检测输出,如式(16)。

(16)
根据关联规则挖掘结果,实现区块链分布大数据的分块QM融合,根据上述分析,得到区块链分布大数据融合模型,如图2所示。

图2 区块链分布大数据融合模型
3 仿真测试分析
为了验证本文方法在实现区块链分布大数据融合中应用性能,进行仿真实验分析。假设区块链分布大数据的稀疏度为0.74,分块融合的维数为12,对区块链分布大数据采样的长度为1 200,特征训练集为100,根据上述仿真参数设定,进行区块链分布大数据融合,得到原始的区块链分布大数据和区块链分布数据融合结果,如图3、图4所示。
由图3和图4可知,本文方法得到的原始区块链分布处理结果数据以60%为固定值,数据在上下波动,大数据处理结果数值稳定。采样点可在监测区块链内采集数据的准确位置,该区块链分布数据融合结果幅值最高为0.5,满足区块链分布大数据的自适应调度。
测试不同方法进行区块链分布大数据融合的性能,测试数据的召回率Q,如式(17)。
(17)
式中,α(a)表示在数据融合中为a的召回量;β(a)表示a在测试结果最终选择的大数据融合的总召回量,A表示区块链分布大数据融合量。利用上述公式计算,得到召回性能对比结果,如表1所示。
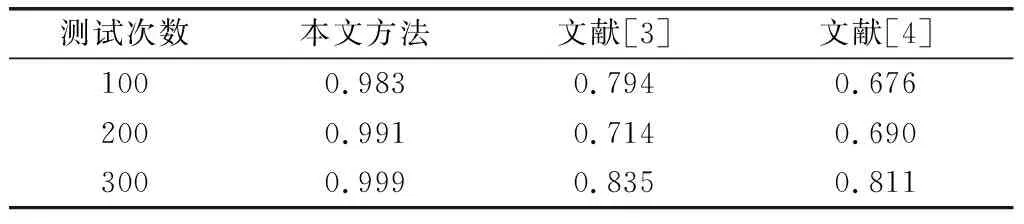
表1 区块链分布大数据融合的召回性能对比
由表1可知,利用本文方法对比文献[3]方法、文献[4]方法进行区块链分布大数据融合的召回性能测试时,本文的召回率较高,在最终进行300次测试后,本文方法的召回率高达0.999。
以表1区域链分布大数据融合召回数值作为研究对象,进行区块链分布大数据融合。当在同样的数据规模下进行执行时间的测试,可得出不同的执行速度即得到区域链分布优化效率;而在不同的数据规模下,对比执行时间分布点高低情况即可得出区块链分布效率,因此将横坐标设为0-600个的数据规模,如图5所示。
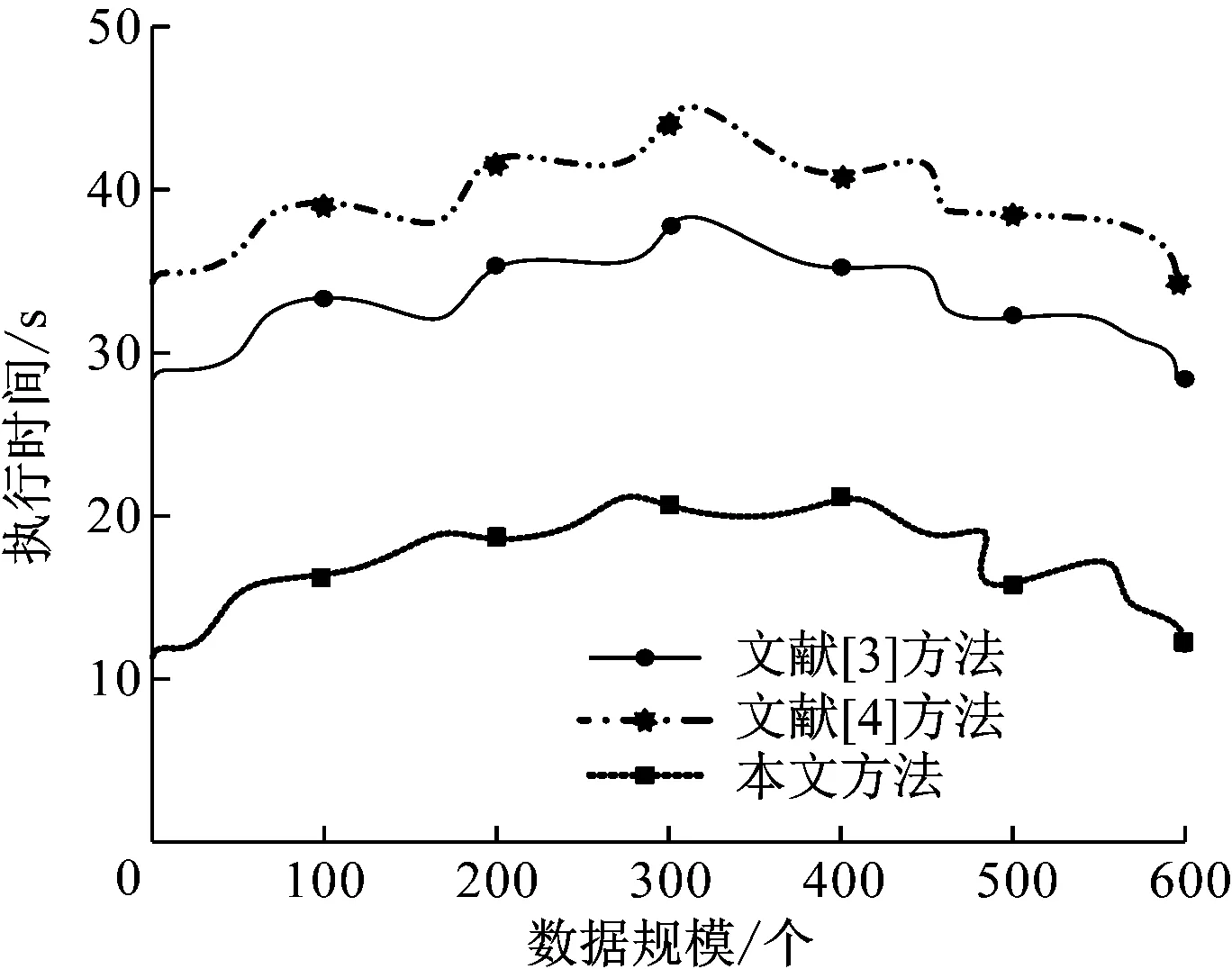
图5 不同方法下区块链分布优化效率分析
由图5可知,在相同的数据规模情况下,本文方法进行的区块链分布优化执行时间短,文献[3]和文献[4]方法耗时较长,这是由于在相同情况下,本文方法进行效率分析时,提取分布大数据的统计特征量,基于压缩感知和模糊分区调度的区块链分布大数据融合,对混合型的区块链分布大数据进行关联特征分布式检测。说明采用本文方法进行区块链分布大数据融合的特征分辨能力较好。而在不同数据规模时,本文方法的所有执行时间分布点都低于其他两种方法,例如当本文方法在200个数据规模的情况下,执行时间不超过20 s,而其他方法在起始处理时间就大于20 s。
4 总结
构建区块链分布大数据融合模型,结合特征挖掘和分布式调度的方法,进行区块链分布大数据采样和信息融合设计,提高区块链分布大数据的定量递归分析能力。本文提出基于压缩感知和模糊分区调度的区块链分布大数据融合模型,提取区块链分布大数据的统计特征量,进行区块链分布大数据融合过程中的定量递归分析。在语义本体模型中执行区块链分布大数据的样本统计,对混合型的区块链分布大数据进行关联特征分布式检测,采用差异化的特征分布式检索方法进行区块链分布大数据信息聚类,实现区块链分布大数据融合的QM模型优化设计,分析实验结果可知,本文方法进行区块链分布大数据融合数据处理结果数值稳定,效果佳,同时召回率较高,特征分辨性能较好。
