一种基于红外图像序列的深度学习三维重建仿真方法初探
2020-12-26陈寂驰魏国华郭聪隆张立和
陈寂驰,魏国华,郭聪隆,张立和
(1. 北京理工大学 信息与电子学院,北京 100081;2. 大连理工大学 电子与信息工程学院,辽宁 大连 116086)
0 引 言
对比二维空间,在三维空间中描述物体更加直观、全面,且易于被人们所接受。三维重建技术把真实场景刻画成符合计算机逻辑表达的数学模型,在文物保护、医疗技术、虚拟现实、军事仿真等领域具有广泛而深刻的应用前景。
红外热成像不同于可见光成像,在表征物体温度分布的同时,不受光照、烟雾、高压等环境因素的影响,因此得到了广泛的关注。红外热成像不仅为军事领域提供了大量的技术支撑,随着热成像技术的快速发展,其应用已经拓展至民用智能驾驶、电气设备检查、建筑检验、医学辅助诊断、环境资源开发、能源保护以及自然灾害预测、防治等领域。
然而,对比于可见光图像,红外图像的分辨率低、对比度差、视觉效果模糊,还有各种形式的噪声,重建难度更大,往往由于提取不到足够的特征点导致重建失败。因此,基于红外图像的三维重建技术研究具有一定的必要性。
基于光学三原色(red-green-blue,RGB)图像序列的点云生成算法为我们提供了重建思路。其中,SCHONBERGER等提出的方法[1]在传统的从运动恢复结构(structure from motion, SFM)方法的基础上,通过优化和改进实现了待重建物体稀疏点云的输出;基于片面的多视点立体视觉(patch-based multi-view stereo, PMVS)算法[2]通过获取图像序列以及拍摄相机参数,可以重建图像序列中可见物体或场景的稠密点云;多视点立体聚类视图(clustering views for multi-view stereo, CMVS)算法[3]解决了传统多视点立体视觉(multi-view stereo,MVS)方法无法应对大规模图像序列重建的问题,将SFM算法的结果作为输入,通过对原始图像序列聚类,每个分类单独应用MVS提升重建效果。
点云补全技术中,PointNet[4]以及PointNet++[5]提供了直接对点云数据进行局部以及全局特征提取的方法;HAN等提出的一种高分辨率形状补全网络[6],解决了传统的基于图形表面重建方法不能修复大面积缺失区域的问题,提出一种由数据推动的深度神经网络用于对缺失三维形状的恢复;FoldingNet[7]设计了一个具有折叠意义的解码器,将一个固定的二维平面折叠成一个三维的曲面,以代表原来的三维点云,但是这种全局解码结构对局部缺失点云的恢复能力有限;点云修复网络(point completion network, PCN)[8]提出了一种直接对部分3D点云操作,通过网络进行映射,完整复原稠密点云的方法,无需中间体素化过程,采用从粗糙到精细的复原方式进行重建;强化学习代理控制的生成对抗网络(reinforcement learning agent controlled GAN network, RL-GAN-Net)[9]首次提出将强化学习和生成对抗网络相结合,用于含有噪声的局部点云的形状补全;TopNet[10]采用结构点云解码器,降低了计算过程对计算机内存的消耗;级联优化网络[11]提出一种新的点云补全生成对抗网络,相比于PCN和TopNet,在训练参数较少的情况下提升了重建效果;WEN等提出的基于Skip-attention机制的网络[12],可以在得到全局特征的同时保留更多的细节信息,在对缺失形状补全性能方面的表现优于PCN和TopNet;点云分形网络(point fractal network,PF-Net)[13]通过改进的特征提取方法,以一种组合式的多层感知机(combined multi-layer perception,CMLP)实现缺失点云的分级恢复,不足是对缺失点云具有一定视角限制;AtlasNet[14]、变形和采样网络(morphing and sampling network, MSN)[15]通过网络结构学习一种二维平面上的点到待重建物体表面元素之间的映射关系,虽然后者在AtlasNet基础上通过构建扩展代价函数以及引入残差网络进行残差学习,提高了重建精度,但采样后的空间点云会缺失一部分原始信息,此外,基于PointNet方法设计的编码器不具备提取点云细节特征的能力。
综合以上方法,本文所提出的三维图像重建方法的思路是,首先获取待重建物体的原始点云,然后在尽可能保留原始点云的基础上高精度补全缺失部分。
1 仿真模型
1.1 基于红外图像序列的原始点云生成
1) 红外图像预处理
通过图片序列生成待重建物体稀疏三维点云,需要对图像序列特征点进行提取、配准,方向梯度直方图特征(histogram of oriented gradient, HOG)、尺度不变特征变换(scale-invariant feature transform, SIFT)、加速稳健特征(speeded up robust features, SURF)等经典特征描述方法,为在图片旋转、尺度缩放、亮度变化、仿射变换、噪声等因素下提取图像特征做出了重要贡献。本文采用AgisoftMetashape软件辅助生成稀疏点云,原始数据为红外图片序列(本文采用的红外图像尺寸为512×512)。操作中,一方面由于软件自身对输入数据的限制(最低有效输入分辨率为5MPix),另一方面,原始输入数据存在有限的色彩差异以及纹理缺失情况,在恢复空间信息过程中不可避免地会损失部分有效信息,在没有升采样的前提下,无法实现特征点配准以及原始点云生成。为了能够在第一阶段生成足够多的原始点云,采用基于双三次插值(bicubic interpolation, BI)的算法对原始图像序列进行升采样预处理,插值内核可描述为
W(x)=
(1)
式中,参数a选取经验值-0.5。
在尽可能保持原始输入信息灰度稳定性的基础上,提高特征点提取数量,图像插值处理前后效果对比如图1所示。
2) 相机位姿校准及点云生成
错误的相机位姿估计会带来待重建物体空间三维信息丢失、重叠或者扭曲,实验中采用局部相机位姿校准,完整还原拍摄相机姿态(仿真环境中图像序列为均匀俯仰角和方位角下360张待重建物体红外照片),可视化校准前后对比结果如图2所示,校准后不同视角的点云生成结果如图3所示。

图1 插值前后效果对比图Fig.1 Comparison before and after interpolation

图2 相机位姿校准前后对比图Fig.2 Comparison of camera poses before and after calibration

图3 由红外图像序列生成的点云Fig.3 Point cloud generated from infrared image sequence
1.2 点云补全
类似于MSN[15]中输入不完整点云,通过深度学习网络实现缺失点云补全。采用一种联合式编码器-解码器网络直接作用于输入的不完整点云,可避免采用基于多视角体素表示方法带来的重建分辨率受限问题。PointNet[4]和PointNet++[5]提供了直接提取无序点云特征的方法,同时对不同尺度下点云特征进行了有效整合;PF-Net[13]改进了这种特征提取方法,能够提取不同尺度下的缺失点云特征用于缺失部分的补全。借鉴这种提取思路,但不同于PF-Net网络,本文方法直接输出待重建物体完整点云,当独立采用补全点云网络时,我们的模型可以实现端到端的输出。
1) 原始点云预处理
由于原始点云获取方式的多样性,为使模型可以适用于更多类型的点云数据,需要进行预处理工作。根据点云补全网络设计规模对获取的数据集采用均匀采样方式进行降采样,含有缺失部分的点云可以采用随机采样或者随机视角下缺失指定数量点的方式进行处理。为便于网络模型的学习,对点云数据进行了零均值化、坐标归一化处理,对于从ShapeNet数据集[16]获取的数据也可以进行二次归一化,如式(2)所示。
(2)


图4 原始点云预处理结果Fig.4 Original point cloud preprocessing results
2) 点云补全网络模型
本文所设计的网络结构,不受点云缺失部分限制。所谓局部缺失,是指仅在某一个局部部分的消失或者稀疏化。局部缺失的概念是相对于整体稀疏化而言的,整体稀疏化类似于对整体稠密的点云进行均匀降采样,这样会导致视觉效果变差,但总的来说还是保留了一部分全局特征。PF-Net[13]实现了局部缺失点云的补全,但对于完整点云稀疏化的缺失补全是受到限制的。本文采用了类似于MSN[15]中“贴图”重建的方法,改进了PF-Net的不足,网络模型结构如图5所示。
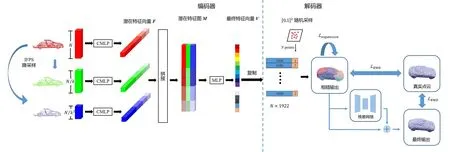
图5 网络模型结构Fig.5 Architecture of designed network model
编码器部分,借鉴了PF-Net[13]的结构,对输入的缺失点云采用迭代最远点采样(iterative farthest point sampling, IFPS)进行2次降采样处理,然后将降采样的结果与原始输入一起,分别通过3个CMLP[13]进行处理。这样做的目的是对不同尺度下的点云进行特征提取,以获得3组形状为1920×1的潜在特征向量,合并后获得形状为1920×3潜在特征图,再将其通过一个多层感知机(multi-layer perception,MLP)获得形状为1920×1的最终特征向量,作为后续解码器的输入。
解码器部分,借鉴了AtlasNet[14],将编码器中获得的特征向量与单位正方形上随机采样点坐标进行结合,形成形状为1922×N的输入数据,通过K个共享的MLP层共生成K×N个点,其组合为最终输出。这种方法的缺点在于表面元素之间的重叠,因此,又借鉴了MSN[15],通过构造扩张代价函数,使得不同的空间表面元素相对独立的同时减少表面元素的重叠程度,优化后的空间表面元素可以有效覆盖待重建物体表面,并且每一个MLP预测的缺失部分相对独立,从而实现了让每一个MLP负责某一个特定部分的预测。期望网络可以输出一个粗输出,将这个粗输出与原始点云结合,通过对整体数据进行最小密度采样(minimum density sampling,MDS)[15],再将获得的点云通过一个残差网络继续训练。这个网络的作用是获取最小密度采样后点云与真实点云点对点的三维坐标的偏移量,从而优化、校正现有点云的空间位置,通过残差的逐点累加实现最终缺失点云的输出。残差网络采用基于共享权重的一维卷积来实现。
代价函数部分,使用了扩张的代价函数,使得每个MLP计算得到的点相对集中,扩张代价函数如式(3)所示。
(3)
式中:K为生成表面的MLP个数;N为每个表面元素生成点云数量;Ti为每个MLP产生点云的最小生成树;dis(u,v)表示两节点的欧式距离;li表示Ti中所有边长的平均长度;f为指示函数,用于过滤距离小于λli的边(λ取1.5)。
如文献[17]分析,EMD比倒角距离(chamfer distance,CD)更能反映预测值向真实值的逼近程度;CD的缺点在于其计算复杂性高,为此,本文沿用了MSN[15]中的处理方法,采用了一种近似的EMD计算方法,在保证误差较小的同时减少了计算量,代价函数如式(4)所示。

(4)
式中:Scoarse是生成的粗糙点云;Sfinal最终输出结果;Sgt是真实的完整点云;实验中设置α为0.1,β为1.0。
2 仿真实验及结果分析
2.1 模型训练及结果展示
选取ShapeNet数据集[16]上16个类别(Airplane、Bag、Cap、Car、Chair、Earphone、Guitar、Knife、Lamp、Laptop、Motorbike、Mug、Pistol、Rocket、Skateboard、Table),共计16 831个训练数据,训练集、验证集、测试集样本数量分别为12 087、2 874、1 870。采用本文所述方法进行不同类别物体缺失点云重建,效果如图6所示。

图6 部分点云复原效果Fig.6 Partial results of point cloud completion using the proposed method
实验中采用两种训练方案。
第一种是针对指定类别数据进行训练,选取在文献[15]和[13]论文中EMD以及CD距离最大的3个类别进行训练。其中:完整点云数量2 048;缺失点云数量512;batchsize设置为8;epoch设置为70;生成表面数量(K)为8;降采样指标为1 024、512;学习率初始为0.01,第20个epoch下降为0.001,第30个epoch下降为0.000 1。PF-Net以及MSN采用相同的训练数据以及训练方法进行训练,测试集部分可视化结果如图7所示。

图7 3种点云补全方法效果对比Fig.7 Comparison of three methods in point cloud completion
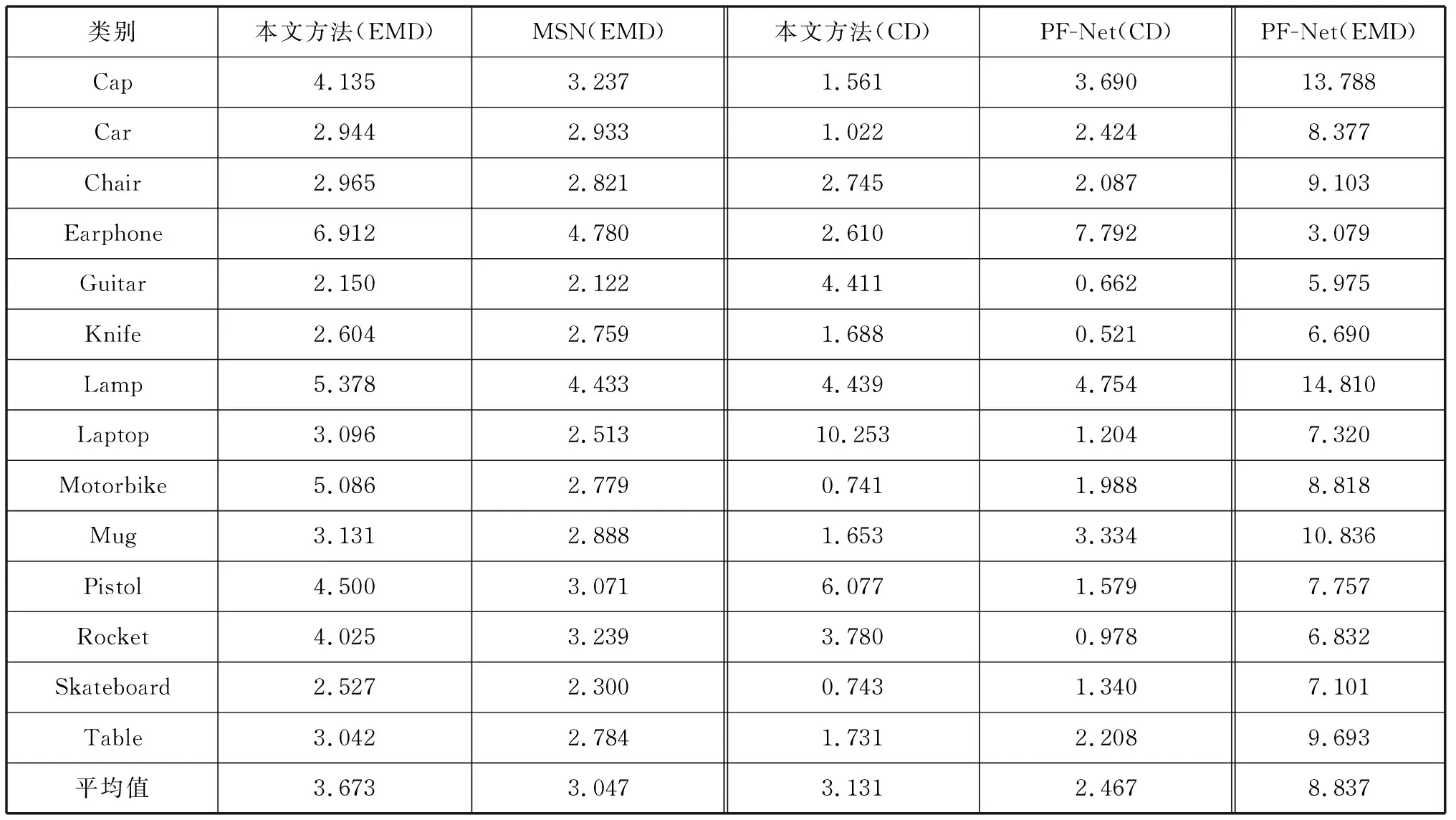
3种模型EMD、CD指标对比情况如表1所示。表1中EMD指标显示数值为EMD×100,CD指标显示数值为CD×1 000,对比MSN以及PF-Net分别采用EMD以及CD指标,考虑到不同指标之间的对比差异,在最后一列也加入了PF-Net的EMD指标。

表1 3种网络模型EMD、CD指标对比结果(方案一)Tab.1 Comparison results of EMD and CD indexes in three network models(program 1)
第二种训练方案采用全体训练数据,每训练5个epoch进行验证,最终通过测试集获取训练指标结果。其中:完整点云数量2 048;缺失点云数量512;batchsize设置为36;epoch设置为40;生成表面数量(K)为8;降采样指标为1 024、512;学习率初始为0.01,第20个epoch下降为0.001,第36个epoch下降为0.000 1。PF-Net以及MSN采用相同的训练数据以及训练方法进行训练,最终测试集上EMD、CD指标对比结果如表2所示(表2中各指标显示数值同表1)。

表2 三种网络模型EMD、CD指标对比结果(方案二)Tab.2 Comparison results of EMD and CD indexes in three network models(program 2)
(续表)
为测试点云补全网络对由红外图像序列生成的不完整点云的补全效果,在ShapeNet数据集[16]上选取Boat类别数据1 939个,手动筛选33个与待重建物体结构相似的CAD模型并点云化,之后进行数据增强操作。具体方法为:在归一化操作的基础上,在单位球体的表面选择64个视角点,对筛选出的33个点云进行指定视角下的缺失处理(去掉距离这个视角点最远的一些点),每个原始点云产生64个缺失点云,共形成2 112个训练数据,同时采用第一种训练方案进行训练。
值得注意的是,测试环节中,我们往往无法获得待重建物体的真实点云,直接将原始点云进行视角缺失处理是不合理的,此外,原始点云相对真实点云可能存在点的均匀缺失以及局部缺失。为平衡这两种缺失情况,将原始点云均匀降采样至1 792,以模拟256个点的均匀缺失(假设真实点云数量为2 048);然后对降采样后的点云进行基于64个指定视角的点云缺失处理,以模拟256个点的局部缺失,从而获得不同视角下各包含1 536个点的不完整点云;再将这些不完整点云通过补全网络进行补全,补全前后效果对比如图8所示。
图8(a)的点云与我们在图3(a)展示的点云不同,这是因为我们在图3的结果上又删去了一部分点(64个指定视角分别缺失256个点),以匹配点云补全网络输入数据规模,从而提升重建效果。

图8 点云补全前后效果对比Fig.8 Comparison before and after point cloud completion
2.2 实验结果分析
1) 点云补全网络训练结果分析
由图6可以看出,对不同类别物体,本文所设计的联合式编码器-解码器网络可以有效应对随机视角缺失指定点数的情况,对于缺失部分的细节能够准确提取其特征,进行精细补全。
由图7可以看出,在采用相似的训练数据进行训练后,3种点云补全方法都可以实现缺失点云的补全:Lamp类中,本文方法与MSN都错误补全了灯柱部分,由于保留了原始输入,PF-Net补全效果最好,但是缺失部分与输入点云结合时出现了一定的位置偏差;Cap类中,3种方法表现都较好,PF-Net仍然存在结合偏差问题;Bag类中,本文方法保留了原始数据的整体形状,但是包带部分重建效果不是很精细,MSN出现了形状的误判,PF-Net将缺失部分很好地限制在包体中间。
由表1可以看出,本文方法的EMD指标均优于MSN、PF-Net的EMD指标,平均EMD指标较MSN下降7.1%,较PF-Net下降64.2%。表2显示了经过全体训练集训练,3种网络测试集的最终效果:与MSN相比,本文方法的平均EMD指标上升了17.0%,但是在Bag类以及Knife类别中表现较好;与PF-Net相比,本文方法在EMD指标方面优势明显,平均EMD指标下降58.4%,并且部分CD指标也优于PF-Net。
2) 红外图像序列重建结果及部分错误重建结果分析
由图8可以看出,点云补全网络可以有效实现缺失部分的恢复,但是补全结果出现了一定的形状泛化。这是因为待重建物体形状复杂度较高,训练数据集中样本较少,训练数据与待重建物体形状差异较大。此外,点云补全网络对所有点云坐标重新计算的过程,也会造成待重建物体部分精细结构位置的偏差。
由实验结果发现,部分类别的测试结果与真实值差距明显,例如Motorbike类以及Earphone类,重建效果如图9所示。本文设计的网络模型并没有很好地提取点云的精细特征,只对轮廓信息进行了提取与重建,同时错误补全了部分点云。原因主要是这两个类别训练数据相对较少,分别为125、49,在少量训练数据的前提下,如果没有应用数据增强技术,网络模型学习效果难以提升。

图9 部分错误重建点云Fig.9 Partial inaccurate reconstruction point cloud
3) 后续研究思路及改进方法
针对红外图像序列以及部分类别点云重建结果不精确的问题,在后续研究中可重点针对以下几方面进行改进、突破:
(1) 设计新的编码器-解码器网络,提升复杂点云特征提取、恢复能力,在保证EMD、CD指标稳定的同时将点云补全规模提升至10 000点以上;
(2) 探索红外图像序列所蕴含的缺失点云的空间三维信息,结合深度学习方法提升重建精度;
(3) 设计完全端到端的网络结构;
(4) 尽量减少网络对原始点云坐标的改动,重点优化点云缺失部分;
(5) 改进、优化训练方案,根据模型特点合理设置学习率、迭代次数以及优化器类型;
(6) 扩大数据规模,一方面,在更多数据集中选取训练数据,整合不同数据集中相同类别的数据;另一方面,当部分类别数据较少时,采用数据增强技术。
3 结束语
在现有点云补全网络的基础上,通过对不同网络优劣势分析,本文提出了一种分两阶段实现红外图像序列三维重建的方法;仿真模型部分给出从红外图像数据预处理以及原始点云生成到点云补全的完整方案;联合式编码器-解码器网络,针对缺失点云,应用分级的特征提取方法,并采用“贴图”方式形成指定个数空间曲面以覆盖点云缺失部分,通过构建扩张代价函数以及EMD代价函数实现参数优化,通过残差网络实现最终输出。
实验结果表明,本文方法能够有效实现不同类别点云的缺失补全,在相同数据集以及相似训练环境下,部分类别EMD指标相比现有补全网络有更加优秀的表现。
