基于CNN的车牌识别精定位算法研究
2020-12-25陈冬英曾淦雄
陈冬英,曾淦雄
(1.福建江夏学院电子信息科学学院,福建福州,350108;2.福州大学数学与计算机科学学院,福建福州,350108)
一、引言
国内人均汽车保有量不断提高,带来的交通压力越来越重。因此实现对车辆的管理自动化将是现在亟需解决的一大问题,而车牌识别系统是实现这一过程不可缺少的环节。
车牌识别系统(License Plate Recognition System, LPRS)属于计算机视觉中的一种现实应用,对实现收费停车场的无人化管理、不停车通过高速收费站、各类小区、校园机动车出入登记有着重要的意义。[1-2]国内外相关学者也进行广泛的研究。上海理工大学王艳、谢广苏等学者提出了一种基于最大极值稳定区域(maximally stable extremal regions, MSER)和笔画宽度变换(stroke width transform, SWT)的车牌识别方法。[3]该方法使用MSER和Canny边缘相与运算后得到MSER筛选得到区域,并在区域上做心态学操作,完成车牌定位。使用归一化后的模板匹配,采用HU不变矩以及网格特征完成汉字识别,利用跳跃点实现识别数字与字母。贵州大学的李良荣、荣耀祖等学者,提出基于SVM的车牌识别技术,基于Sobel与HSV色域空间的车牌定位,查找字符轮廓与垂直投影法的字符切割,基于SVM的字符识别,并利用遗传算法对SVM参数进行优化。[4]
传统的车牌识别包含车牌定位、字符切割及字符识别三个部分,存在着鲁棒性和精确性不兼容性。为克服已有传统技术存在的不足,本文提出一种基于卷积神经网络(CNN)的车牌识别与精定位算法研究方法。主要通过对车牌识别三个阶段的研究,分别提高各个阶段的识别准确性,进而提高整个系统的识别率。首先,车牌的粗定位使用基于Haar特征级联分类器,而后结合精确定位算法包含上下边界检测与左右边界检测并进行车牌矫正。其次,字符分割算法部分则通过基于字符分布特征的切割算法,在不降低切割率的情况下相较于传统的切割方法简单易用。最后,分别设计了用于中文字符识别的卷积网络和用于英文与数字识别的卷积网络。通过对高速公路拍照系统拍摄的高清车牌图像及由CCPD开源提供具有低分辨率、弱光或强光、高度倾斜车牌等特征数据集进行验证明,精定位算法能够对车牌进行有效定位,识别准确达98%以上。
二、传统车牌识别算法原理及其存在的不足
卷积神经网络属于近些年来在计算机视觉邻域引起广泛重视的技术方向之一。[5]最早的真正意义上CNN由LeCun在1989年提出[6],随后被改进用于手写字符识别任务中。在2012年的ImageNet图片分类中,深度卷积神经网络AlexNet夺得桂冠。由于卷积神经网络能够避免对图像进行复杂的前期预处理,因而得到了广泛的应用[7]。当下CNN作为许多科学领域中的一个研究热点。
(一)神经网络
将神经元按层次组织在一起就构成了神经网络,一个简单的二分类神经网络见图1。

图1 简单二分类神经网络
其中input layer 接受网络输入,hide layer是网络核心,output layer是网络输出,在二分类问题中,通常输出是或否。数据通过输入层进入网络,每一层将计算结果输入下一层,最后又通过输出层完成输出。
(二)卷积神经网络
一个典型的用于手写数字识别的卷积神经LeNet-5结构见图2。
其中c1/c3/c5是卷积层。卷积层是通过卷积核,对上一层的输出进行离散卷积运算而得的,卷积核中的每一个参数都相当于普通神经网络的权值。
S2/s4是池化层(下采样),将输入图像分割为多个子区域,在区域内取最大或平均形成新的图像。经过步长为2的池化层后,原图像尺寸减小一半。
F6是全连接层,图像经过卷积层和池化层之后,特征已经提取充分。接下来就是把特征图像偏平化,即通过Flatten层,将二维图像变为一维输出。之后经过全连接层,使用softmax进行分类。输出结果中,概率值最高的即为分类结果。
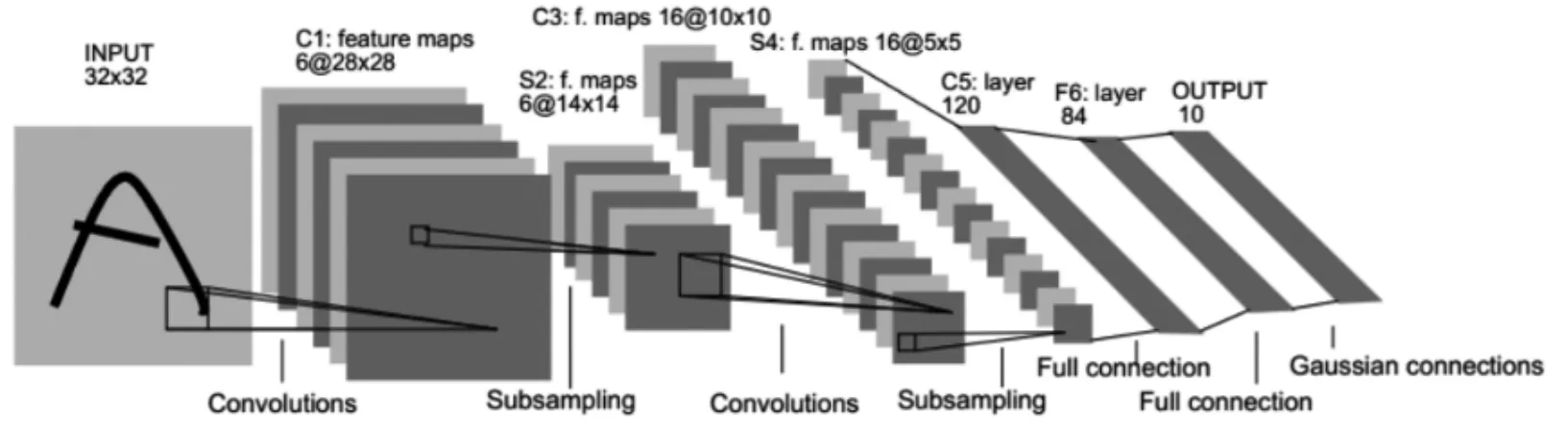
图2 LeNet5神经网络
在车牌识别系统里,实现了字符分割以后,对字符进行识别。传统的方法包含支持向量机SVM分类,BP神经网络、基于字符的模板匹配等方法,随着近年来人工神经网络的流程,在传统的车牌识别算法中主要有采用基于BP的神经网络算法实现,存在着鲁棒性和精确性不兼容性。
三、基于CNN的车牌识别精定位算法及其实现步骤
车牌识别系统有3部分:一是车牌定位模块;二是字符分割模块;三是字符识别模块。车牌定位模块通过对图像进行灰度化处理、模糊处理、HAAR特征级联类器探测、车牌边缘精定位等操作实现对车牌区域的提取。字符分割模块则是通过对车牌进行灰度图像均值化处理,自适应二值化处理,文字边缘检测等手段,结合车牌的字符分布特征从车牌上分割字符。字符识别模块则是通过字符数据训练一个卷积神经网络实现字符识别。并将输入图片和输出结果使用GUI界面显示。具体的系统流程图见图3。
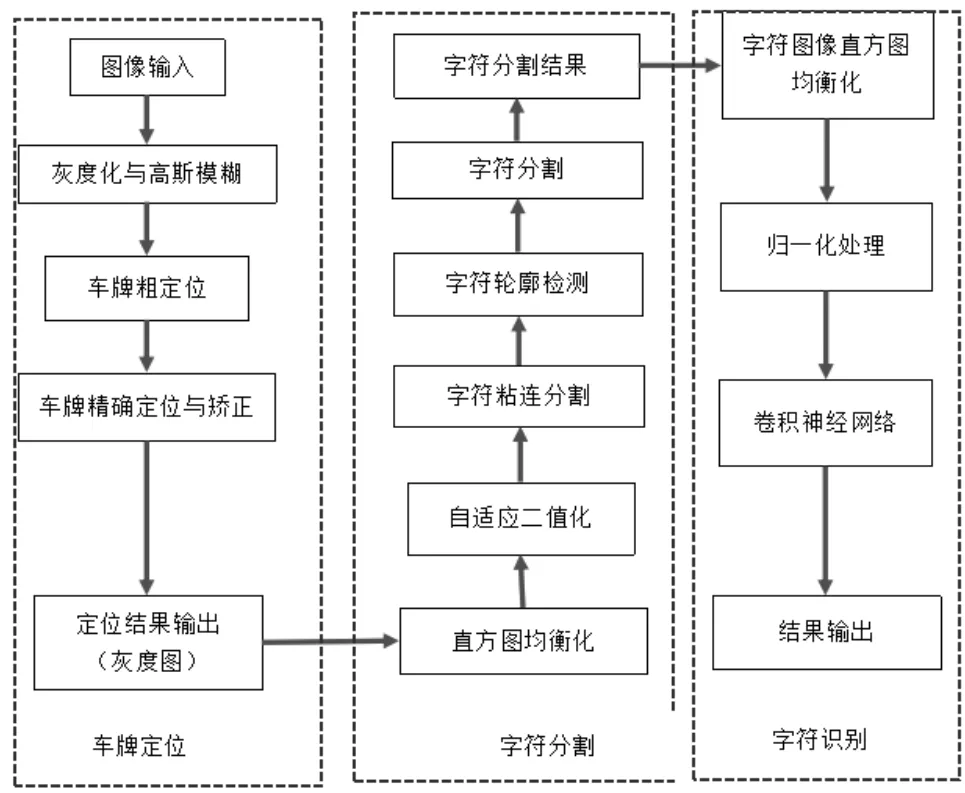
图3 车牌识别系统流程图
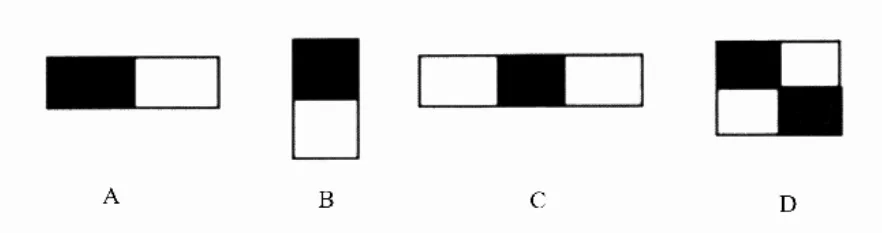
图4 Haar特征种类
(一)车牌检测
车牌检测与精确定位,分为两个部:一是基于Haar特征的级联分类器,二是用于上下边界拟合的精定位算法以及车牌矫正。[8]
1.Haar特征
Haar矩形特征是用于物体识别的一种灰度图像的数字特征。Haar特征可以有效反映图像的灰度变化,拥有较高的空间分辨率,可以有效提取图像特征,形成特征值。最初的Haar特征有4类,见图4。
其中A与B分别表示的是水平方向和竖直方向上的特征,特征值为对白色区域求和减去黑色区域求和。C包含了3个矩形区域,特征值为白色区域求和减去2倍黑色区域求和。D则是计算对角方向上的梯度。对于一副图像而言,通过改变模板的大小和位置,通过矩形窗口的滑动,生成矩形特征。根据检测目标的特征的不同,Haar特征可以分为3类:直线模板、环形模板、对角模板。在识别过程中,Haar矩形特征通过在图像上的滑动,完成对整张图像的Haar特征值计算。
2.车牌检测
该部分使用OpenCV中基于Haar特征的级联分类器实现,在将图像送入分类器之前,对图像进行灰度化与高斯模糊处理[9]。级联分类器的输出为原图像中的车牌的左上角坐标和车牌区域的宽度与高度。
(二) 车牌精确定位算法与矫正
1.上下边界拟合
上下边界拟合的基本思路:(1)通过对车牌图像的多次自适应二值化,形成不同的二值图像;(2)每张二值化图像都可以通过OpenCV的Findcontours查找到可能包含字符的矩形框,在一张图上画出所有的对角点;(3)由上述两个步骤能够产生足够的样本点。通过上下边样本点采用随机抽样一致化算法拟合上下边界。
其中,随机抽样一致化算法是基于最小二乘法的一种具有高度抗干扰能力的拟合算法。算法流程:(1)随机选取若干样本点,设为k;(2)基于若干样本点,由最小二乘法拟合出直线方程f;(3)计算所有样本点与该拟合方程f的估计误差;(4)设置误差阈值sigma,选出小于误差阈值的样本点;(5)重复1—4的过程,选取足够的样本点;(6)重复5的过程。最终找到的拟合方程f,即为最优方案。
算法流程中的k参数选取,sigma参数与迭代次数的选取,针对不同的样本数据有不同的选择。
2.左右边界的检测
左右边界确定的基本思路如下:(1)将灰度图进行均衡化后,通过Sobel算子找到垂直边缘;(2)对垂直方向进行统计求和,画出直方图;(3)对直方图两边进行处理可以确定左右边界。
其中,Sobel算子[10]被用于提取图像中的边缘信息。Sobel算子的原理对传入的图像做像素卷积运算,实质是求解图像的梯度值。
1)水平方向求导算子

2)垂直方向求导算子

3)通过水平方向和垂直方向求解近视梯度

本文中,sobel算子只应用于垂直边缘的检测。因此在使用时,只使用垂直方向的求导算子。
3.垂直边缘的确定
通过对车牌图像做sobel梯度求导后,做垂直投影,得到垂直分布直方图。通过分析垂直直方图两端的波峰与波谷情况,进而确定车牌字符的开始与结束位置。
(三)字符分割
通过分析由前级产生的车牌图片,以及根据中国车牌样式的字符分布特点,本设计采用基于先验字符分布特点的字符分割算法。字符分割步骤如下:
1.对图片进行放缩,放缩为标准车牌大小(440,140),进行灰度化、高斯模糊处理,得到去噪后的图片。在这个基础上,进行直方图均衡化,降低环境光对后续处理的进一步影响。接着,对均衡化的图片做自适应二值化得到二值化图像,再进行简单的粘连字符分割,得益于前级处理模块的处理效果,该部分只做简单的判断,根据某列上,白色像素点的数量进行断开即可。
2.对处理完成的二值化图像,使用OpenCV内置的findcontours函数查找字符轮廓,并进行简单的字符框过滤。
3.基于字符分布特征的后续处理。具体包括如下步骤:
(1)字符宽度和字符面积过滤。输入的车牌尺寸被调整为(440 * 140)。因此正常字符宽度应该大于45个像素宽,因涉及数字‘1’的存在,当轮廓宽度大于13像素,小于90像素时接受。轮廓高度应大于115,轮廓面积大于1500并且小于 11000时接受该轮廓为单字符轮廓。考虑到粘连字符分离不成功的情况下,若某个轮廓宽度大于90像素,面积大于11000时,根据车牌字符特征,认为此处存在粘连字符,进行切分,切分根据字符特征进行。
(2)根据字符的宽度特征进行矩形区域重新定型。规则为:当宽度小于35时,认为该字符为数字‘1’,裁剪其宽度值为40。由于中文汉字可能存在的一个字分离的情况,如“川”,采取当其切割位置小于60时,裁剪宽度为60。其他情况认为字符切割正常,裁剪宽度为58。
(3)经过上述处理,已经排除绝大部分情况,然而对于某些情况下,还是存在切割字符过少,或过多的情况。处理办法为,根据字符间距差小于35像素点剔除多余切割点。
(四)卷积网络(CNN)设计
该部分由两个卷积网络构成。参考LeNet-5[11]网络,分别设计用于中文字符和英文与数字字符识别。基本的网络结构与训练细节如下:
1.设计输入的字符图像为单通道灰度图,经过直方图均衡以及归一化处理的字符图像。
2.输入图像大小为(23 * 23)。输出为65类(实际上,对于英文和数字识别模型,输出只有34类),具体的参数见表1。

表1 卷积神经网络参数
三层设计如下:
(1)第一层设计细节:卷积层使用数量为32个大小5x5,滑动步长为1的卷积核,激活函数使用Rule,池化层使用大小2x2的最大值池化方案,为提高模型的泛化能力,加入0.25的Dropout比例数。
(2)第二层设计细节:由第一层经过卷积后输出的图像大小为(23-5)/1+1=19,经过2x2的池化层后,图像大小为 9x9大小。设计第二层卷积层使用数量32个,大小3x3,滑动步长为1的卷积核。激活函数为Rule。同样经过2x2大小MaxPooling。
(3)第三层设计细节。首先经过第二层卷积和池化运算后,输出的图像大小为3x3。因此设计第三层卷积层的卷积核个数为512个,大小3x3,无池化。此时输入为1x1的特征点。之后为一个包含512个激活函数为Rule的神经元构成的全连接层,并使用0.5比例的Dropout。输入最后的输出层,输出层神经元个数为分类器分类个数65。
3.训练时使用损失函数为多分类的对数损失函数,优化器方面使用Adam,默认参数设置。Batch为32,epoch为1000次。
四、实验结果与分析
(一)数据准备
第一部分为常规数据集,特点为图像背景单一,车牌字符清晰,无粘连,亮度较为均匀,车牌图像倾斜角较小,识别难度总体偏小。多收集于高速公路上的拍摄照片。该部分用于验证系统在特定场景的应用运行情况。第二部分为挑战性较高的CCPD(Chinese City Parking Dataset)[12]的部分数据,该数据集具有分辨率低,背景复杂,部分粘连亮度差异大、图像倾斜角较大等特点,识别难度大。该部分用于验证系统在复杂环境的运行情况。本系统使用的测试数据集包含各省份的部分车牌图片。
(二)实验结果与分析
为了更准确地评估系统各个模块的工作情况,首先,测试车牌精确定位,输入包含车牌的图片,输出精确定位的车牌。其次,测试切割算法的有效性,输入车牌图片,得到单个字符的输出信息。最后,是系统的整体识别别率评估。其中,图5为系统运行界面与测试结果,表2为第一部分的测试结果。

图5 系统运行界面与测试结果

表2 常规数据集测试结果
完成系统测试后,由CCPD数据集中随机抽取30张图片进行测试,目的是测试本文提出的识别方法是否具有较强的鲁棒性和改进空间。结果表明,在随机抽取的车牌中,准确识别出了25张。说明本文的方法具有较强的鲁棒性,能够应对一定程度的复杂环境下的车牌识别。
表2显示的准确率98.15%,而基于SVM的车牌识别方法,准确率95%[1],基于MSER和SWT的新型车牌检测识别方法,准确率96.14%[3],可见本文算法更优。
五、结语
为提高车牌识别的准确性,本文通过对车牌识别的四个子模块进行改进,主要采用Haar特征的级联分类器检测出车牌信息后的精定位,并结合车牌字符的分布特征进行字符切割的算法设计,合理有效地使用先验的知识,完成对字符的精确切割;最后,使用keras搭建深度卷积神经网络(CNN)有效地对分割后的字符进行准确的识别。本文提出的算法,对特定场景的识别率很高,对某些复杂背景也具有一定精确的识别率,但对于国外车牌等的适用还没有详细研究。
