基于深度学习的青藏高原畜牧业多目标动物图像检索研究
2020-12-24更藏卓玛安见才让
更藏卓玛 安见才让

摘 要: 深度学习作为机器学习的一大重要分支,近年来在图像处理与自然语言处理领域应用极为广泛,随着深度学习被应用于各行各业,越来越多复杂的问题也随之简化。本文利用深度学习中的卷积神经网络模型进行研究,采用当下较为流行的YOLO框架,设计并实现了一套实用于青藏高原畜牧业动物图像检索的系统,该系统可根据相应需求检索单目标和多目标图像,在多次实验结果反馈中正确率较高,可在一定范围内满足实际应用。
关键词: 深度学习;卷积神经网络;图像检索系统
中图分类号: TP391.4 文献标识码: A DOI:10.3969/j.issn.1003-6970.2020.07.025
本文著录格式:更藏卓玛,安见才让. 基于深度学习的青藏高原畜牧业多目标动物图像检索研究[J]. 软件,2020,41(07):126-131
Research on Multi-objective Animal Image Retrieval of Animal Husbandryin Qinghai Tibet Plateau Based on Deep Learning
GENG ZANG Zhuo-ma, AN JIAN Cai-rang
(Qinghai Nationalities University, qinghai 810000)
【Abstract】: As an important branch of machine learning, deep learning has been widely used in the field of image processing and natural language processing in recent years. With the application of deep learning in all walks of life, more and more complex problems are also simplified. In this paper, the convolution neural network model in deep learning is used for research, and a set of practical animal image retrieval system is designed and implemented based on the current popular yo framework. The system can retrieve single target and multi-target images according to the corresponding needs. The accuracy of the system is high in multiple experimental results feedback, and it can meet the practical application in a certain range.
【Key words】: Deep learning; Convolutional neural network; Image retrieval system
0 引言
目前,在國内有很多动物图像检索方面的研究,并取得了突破性的成绩。但都是在研究基于养殖场环境下的动物图像检索,而且是单目标的图像检索。在养殖场环境下光线较稳定,这有利于图像特征提取。在国内目前很少有基于青藏高原自然环境下并且是多目标的图像检索的研究,青藏高原畜牧业动物图像中动物对象的形式又是各种各样的,所以需要研究出各种状态下的动物图像检索方法具有一定的意义。
在深度学习中,卷积神经网络由于其相对简单高效地提取特征方法使得其成为了目前最常用的一项技术。深度学习模型,特别是深度卷积神经网络模型,在不同的视觉任务比如图像分类、注释、检索和目标检测方面由于其强大的表达学习能力取得了巨大的成功。国内一些研究人员开始对基于CNNs的算法在图像检索方面进行了探索并取得了一定的成果。
国内学者高姗[1]等在文献中提出了一种基于多目标区域的图像检索模型,并实现了一款高效的检索算法。该方法先使用某些目标检测算法找出并定位出图像中的目标,接着使用卷积神经网络(CNN)提取到各个目标的像素特征,同时提出了一种新的多目标区域相似度测量方法使得多目标检测。文献所提出的新算法在PASCAL VOC2007[2]图像库中使用后平均查准率达到43.47%。在PASCAL VOC2012图像库中使用后平均查准率达到44.85%。相比于传统算法在检索的准确性上得到了一个大的提升。随着发展,越来越多优秀并且成熟的模型不断的横空出世,进入到大众视野,比如模型准确率较高的R-CNN[3]系算法,适合处理实时问题的YOLO[4]算法等等,都可以处理多目标图像的检索问题,采用合适的框架进行训练模型,经过合适的调节参数,模型可以达到很高的正确率,能够应用到实际生产生活中。
基于以上所述,本文根据YOLO算法的计算速度快,误检测率低,准确率高等的优势特点,采用YOLO模型作为本文的网络模型,并结合新提出的方法—G-Method,实现了一款较实用的青藏高原畜牧业多目标动物图像检索系统,并检索结果用藏文进行表示。
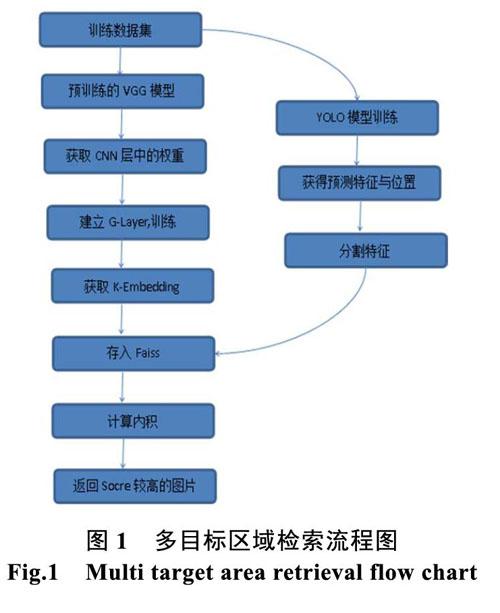
1 多目标区域检索架构
为了完成多目标区域检索系统,需要将目标从目标源中提取并分割。提取目标源将使用YOLO模型,YOLO模型能够给出目标的特征与相对位置,但是YOLO模型给出的特征与相对位置在一般情况下都是含有噪声,也就是说目标特征与目标位置信息是存在偏差,为了降低这种偏差使得特征与目标位置更加精准,本文建立G-Method方法:
(1)在一般情况下,YOLO模型的精准度容易受到训练样本数量与质量的影响,为了降低最终输出的噪声,G-Method将从训练样本入手。首先将训练样本送入预训练好的VGG模型,获得样本集比较好的Embedding 权重参数向量,即各个CNN层的参数向量。
(2)在CNN层训练完毕之后,将在CNN层后加上一个K维的全连接层,记为G-Layer。G-Layer使用多分类损失函数,并且以Softmax作为激活函数。当模型训练完毕之后,将每一个样本送入G-Layer模型,最终每一个训练样本将产生一个K维的Embedding向量,这个Embedding向量包含了训练样本的所有有效特征信息。
(3)将所有K维的Embedding向量存入Faiss数据库中,等待与预测结果向量做内积,这里所有的向量均为单位向量。
(4)使用YOLO模型的输出的分类与位置信息将原始输入特征向量分割,分别送往Faiss中与其做内积,并设定内积结果阈值,如果结果内积值高于阈值,那么认为此结果可信,并且是与现有数据样本非常接近的结果。
流程图如下。
2 多目标区域定位
YOLO算法中的核心思想是会将输入的图像切割成S*S的网格(cell)。每一个网格都需要预测B个边框值(bounding box),边框值包括目标的中心坐标(x,y),它是相对于每个单元格来计算的,并且经过了归一化的处理,设该单元格的坐标为(xcol,yrow),该图片的长、宽的坐标设为(xc,yc),则具体的计算公式为:
其中x为网格的横坐标,y为网格的纵坐标。w为网格的宽度,h为网格的高度。边框的长和宽(w,h),同理也是相对于整张图片计算得到的,设预测的边界框的宽和高分别表示为,即计算公式为:
同时每个边界框需要预测出一个置信度(confidence score),置信度主要分为两个部分,一是判断网格中是否有目标值,二是边框值的准确度,表示为:
公式中的IOU为非极大抑制输出结果,若网格中含有目标值,则,此时置信度的值就为IOU的值,文章后续将会对IOU展开进行解释说明。若网格中不包含目标值,则,此时置信度的值为0。综上所述,每个网格都需要预测B*(4+1)个值,假设每个网格需要预测C个类别,则每个网格都对应一个S*S*(B*5+C)维的向量。
3 多目标特征提取
在计算置信区间时提出了IOU的概念,它反应的是边界框与真实的框之间的重合程度,值越大,说明预测的位置更加接近于真实的位置,预测结果更加准确。IOU可以表示为:预测边界框面积交集比上预测边框面积的并集,即:
IOU=预测边框的交集/预测边框的并集 (4)
IOU用于测量真实和预测之间的相关度,相关度的程度越高,该值越高,也就越能代表预测的目标区域越准确。
另外在多目标的预测过程中,YOLO算法中主要通过NMS(non maximum supperssion),非极大限制抑制来进行对结果的预测。它的核心思想是选择高分输出,与输出重叠的目标去掉,并且不斷重复该过程。每个网格中,设ci为第i个边界框分数(score)。即score=p(ci|obfect)?confidence。设置阈值为0.5,过滤掉置信度较低得分的边界框,从而保证留下来的边界框是置信度较高的预测区域。
详细算法如下:
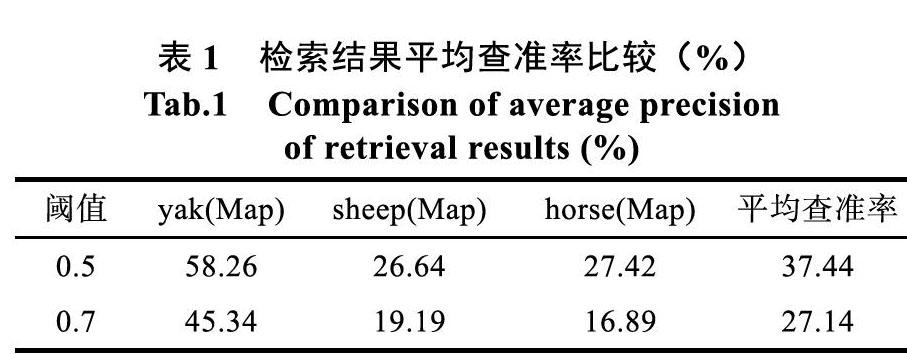
根据候选框的类别分类概率做一个排序:a1< a2 (1)首先标记最大概率矩形框a6是要保留下来的; (2)从最大概率矩形框a6作为开始,分别判断a1-a5与a6的IOU是否大于某个预先设定的阈值,假设a2、a4与a6的IOU超过预先设定的阈值,那么就剔除a2、a4; (3)从剩下的矩形框a1、a3、a5中,选择概率最大矩形框,将其标记为需要保留下来的矩形边框,然后判读a5与a1、a3的IOU,剔除超过阈值的矩形边框。 4 损失函数的计算 YOLO的损失函数包含三部分:位置误差、置信度误差和分类误差。 损失函数的计算就是为了计算坐标的、置信度和分类结果这三个方面达到平衡,其中有宝盖帽子符号为预测值,无帽子的为训练标记值。表示物体落入格子i的第j个边界框内。如果某个网格内没有目标,就不对分类误差进行反向传播。 5 检索性能评价指标 实验采用查准率-查全率曲线(Precision—Recall curve)和平均查准率(mean Average Precision, mAP)作为性能评价标准,公式如下: 其中TP是真正例,FP是假正例,FN是假负例。通过precision和recall的结果,就可以来计算AP,AP就是表示由precision和recall组成曲线的下方面积。 由于在一般情况下曲线下方的面积是无法计算的,所以VOC大赛采取11点[5]的原则: AP的计算是以11个点作为基础进行代替计算,然后将11个点的AP进行一个平均即可得到mAP: 6 实验与分析 基于YOLO本文采用了Darknet框架,它是由C语言和CUDA实现的,对GPU的利用率相比与CPU要高一些,并且易移植到其他平台。其中yolo层和upsample层在YOLO-V1中使用。yolo层主要 指定边界框等信息,计算当中的损失函数等。它自身具有很多优点,相比于其他框架,易于安装,没有其他的依赖项,可以不用依赖任何库。即使Darknet框架是有C语言程序编写的,但也提供了友好的python接口,YOLO采用多尺度预测,每一种尺度预测2个边界框,并且使用的是多个Logistic分类器代替softmax分类器,这样准确率不会下降,从而提高模型的拟合程度。最后经过YOLO模型训练所获得的分类与位置信息将原始输入特征向量分割分别送往Faiss数据库中。并结合本章新提出的G-Method流程,所产生的k维向量存入到Faiss数据库中,与预测结果向量做内积,并设定内积结果阈值,如果结果内积值高于阈值,那么认为现有的数据样本非常接近预测结果。 ①在有限的训练成本和训练时间的条件下,上图是对于yak的多目标检测,可以看到,不同位置的yak已经能够被检测出来,yak后面的部分表示模型给出该类别下的置信度,由上到下分别为0.6,0.88,0.49。此时模型已经不再像单。 目标搜索只能检测出单一的物体,而是能够识别途中所有的目标类别以及其对应的位置。图中也有一个小yak并没有被检测出来,这是因为在给定的置信度与NMS下,这个位置的预测结果在候选区中被剔除了,因为对于应用方面需要的结果是可 信的、可靠的,而不是为了求全而获排列出所有的结果。 ②对于最下方的yak而言,可以发现虽然这个对象最大,但是它的姿势或者说像素点的排列并没有在训练样本中大量的出现,从而导致置信度偏低,可以揣测,模型只“看到了”耗牛角(因为在单目标中,耗牛角也是模型学习到的一部分内容),导致模型可以相信这个地方的类别是耗牛,但是不愿意给出较高的置信度,因为耗牛身体并不是训练集中常常出现的像素排列。图3为牦牛多目标检索结果。 图4检测目标为sheep,在sheep的检测过程中,大部分的sheep已经被检测出来,但是可以发现检测结果中出现了一个错误的目标,即右侧将sheep识别为yak,但错误目标对象极度模糊,也就是使用肉眼观察都需要相对仔细才能观察到。而模型却能将位置精确的找到,将类别识别错误,并且置信度也比较低。这说明模型在一定程度上是比肉眼初步观察更加优秀。对于检测目标的前面两个sheep而言,置信度都相对比较低,这是因为: 第一,受到了图片分辨率的影响,由于低分辨率导致像素排列不紧密,模型无法较好的预测像素排列结果。 第二,依然和yak的检测结果类似,模型实际上只能够识别sheep的脸部区域,无法通过其他卷积层学得的身体相关部分给出更加高的置信度值。 上图为horse的检测结果,在检测的结果中可以发现,虽然目标是horse但是模型也检测出了yak。 实际上在更一般的情况下,多目标检测更多的用于一张图片中含有多个不同的类,需要找出各个类别以及相应的位置,那么下面来看看混合型的情况。 (4)混合型(Mixture) 上图显示的就是在一般情况下的检索,检索的目标对象基本正确,其中可以发现检测过程中有2个误差。分别是将sheep识别为yak,以及将sheep识别为horse。但是仔细观察可以发现,虽然将类别识别错误,但是识别的位置却是正确的。 (5)检索性能分析 本章实验在图像数据集中随机选择了3000幅图像作为查询图像,检索的平均查准率如表1所示。 表1可得,阈值为0.5时,yak的Map是最高的,但是不管是哪一个类,随着阈值的增大查准率就降低了。虽然更高的阈值表示更加精准的输出,那么有些结果虽然是正确的,但是由于不满足精度需求也会过滤掉。 图9、图10和图11分别展示了模型在三个类的图像数据集上的PR曲线图,从图中可以看到,模型在yak类数据集上的查准率明显优于其他两种数据集上查准率。 7 总结 本文为畜牧业动物图像检索建立了一个基于深度学习的网页端系统。利用卷积神经网络,单目标图像检索,多目标图像检索等基础理论,构造了一个由网页端可以实现对畜牧业动物进行分类预测的图像检索系统,无论是对简单的图像目标还是对于繁琐目标的图像,模型都可以以较高的准确率来判断出图像中目标的类别,并给出准确度。对于较小目标的图像,模型依旧存在误判,但并不影响实际 应用。采用的YOLO模型框架在实现的过程中表现的效果符合预期想要达到的目标,经过相关参数的调试后,最终确定为本文图像检索系统中采用的模型。实验结果证明,采用YOLO框架的模型拟合程度较高。 参考文献
高珊, 李秀华, 张峰, 宋立明. 基于多目标区域的图像检索[J]. 电视技术, 2018, 42(4): 55-61.
M. Everingham, L. Van Gool, C. K. I. williams, J. Winn, and A. Zis-Serman. The PASCAL Visual Object Classes Challenge[J]. Int J comput vis, 2010, 88: 303-338.
Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[J]. Computer Vision and Pattern Recognition, 2013, 1(April): 580-587.
Joseph Redmon, Santosh Divvala, Ross Girshick. You Only Look Once: Unified, Real-Time Object Detection[J]. Computer Vision and Pattern Recognition, 2016.
叶虎, 赵一凡. 最完整的检测模型评估指标mAP计算指南[DB/OL]. https://blog.csdn. net/l7H9JA4/article/details/80745028. 2018, 06, 19.
王晓华. OpenCV+TensorFlow深度学习与计算机视觉实战[M]. 清华大学出版社, 2019, 2月, 第-版.
朱啸天. 基于深度学习的动物图像检索算法研究[D]. 学位论文, 沈阳理工大学, 2015.
猿辅导研究团队. 深度学习核心技术与实践[M]. 北京:电子工业出版社, 2018.
李钊, 芦苇, 邢薇薇. CNN视觉特征的图像检索[J]. 北京邮电大学学报, 2015, 38(b06): 103-106.
海林鹏, 文运平. 基于图像分块目标区域的检索技术研究[J]. 河南理工大学学报(自然科学版), 2013, 32(1): 73-75.
侯贵洋, 赵桂杰, 王璐瑶. 草莓采摘机器人图像识别系统研究[J]. 软件, 2018, 39(6): 184-188.
张传栋, 徐汉飞, 陈弘毅, 等. 基于超红图像与轮廓曲率的苹果目标识别与定位方法研究[J]. 软件, 2015, 36(8): 30-35.
王聪兴, 刘宝亮. 一种基于图像处理的表面故障裂纹检测系统[J]. 软件, 2018, 39(5): 144-150.
彭云聪, 任心晴, 石浩森. 基于核加权KNN和多目标优化的众包平台定价系统设计[J]. 软件, 2018, 39(6): 150-154.
王浩, 楊德宏, 满亚洲. 基于 GIS 技术的动物物种管理及保护[J]. 软件, 2018, 39(12): 111-115.