基于LHPN算法的手势姿态估计方法研究
2020-12-24周全甘屹何伟铭孙福佳杨丽红
周全 甘屹 何伟铭 孙福佳 杨丽红


摘 要: 随着广大用户越来越追求人工智能产品的体验,手势姿态估计存在广阔的应用前景,但也是当今计算机视觉的难题。针对目前自顶向下的姿态估计模式容易受视觉传感器与目标检测精度的影响,本文提出基于轻量级手势姿态网络(Lightweight Hand Pose Net,LHPN)算法的手势姿态估计方法,该算法采用Convolutional Pose Machines(CPM)算法的多层次顺序结构,在每个阶段后隐式地将上下文信息融合,并设计了轻量级主干网络,以提升手势姿态估计的综合性能。基于STB数据集对比分析不同内部结构的LHPN算法性能,并与典型算法进行对比。实验结果表明,LHPN算法能够对手势姿态进行准确估计,与CPM算法相比,在AUC方面提升了0.5%,在每帧图像运算时长方面减少了0.1358 s。
关键词: 手势姿态估计;Lightweight Hand Pose Net;Convolutional Pose Machines;轻量级
中图分类号: TP391.41 文献标识码: A DOI:10.3969/j.issn.1003-6970.2020.07.013
本文著录格式:周全,甘屹,何伟铭,等. 基于LHPN算法的手势姿态估计方法研究[J]. 软件,2020,41(07):66-71
Research on Hand Pose Estimation Using LHPN Algorithm
ZHOU Quan1, GAN Yi1,2, HE Wei-ming1,2, SUN Fu-jia1, YANG Li-hong1
(1. College of Mechanical Engineering, University of Shanghai for Science and Technology, Shanghai 200093, China;2. Department of Precision Mechanics, Faculty of Science and Engineering, Chuo University, Tokyo 〒112-8551, Japan)
【Abstract】: As users increasingly pursue the experience of artificial intelligence products, gesture pose estimation has broad application prospects, but it is also a difficult problem in computer vision. In view of the fact that the current top-down hand pose estimation mode is easily affected by visual sensors and object detection accuracy, this paper proposes a hand pose estimation method based on (Lightweight Hand Pose Net, LHPN) algorithm. The algorithm uses the multi-level sequence structure of Convolutional Pose Machines (CPM) algorithm, implicitly combines the context information after each stage, and designs a lightweight backbone network to improve the comprehensive performance of hand pose estimation. Based on STB dataset, the performance of LHPN algorithm with different internal structures is analyzed and compared with typical algorithms. The experimental results show that LHPN algorithm can accurately estimate hand pose. Compared with CPM algorithm, it improves AUC by 0.5% and reduces computation time of each frame of image by 0.1358 s.
【Key words】: Hand pose estimation; Lightweight hand pose net; Convolutional pose machines; Lightweight
0 引言
所谓姿态估计,就是将关节点联系起来判断人体部位的状态和行为[1]。姿态估计分为自顶向下[17]与自底向上[16]的方法,自顶向下的方法相對来说比较流行且容易实现。目前大多数研究者借助特殊的视觉传感器进行自顶向下手势姿态估计,文献[2]提出利用多摄像头系统来训练关键点检测器,分析视图的相关联性,生成图像上手势的关键点。文献[3]提出基于单个深度帧将姿态参数分解为一组单个像素的估计,使用均值漂移来聚集局部的像素实现2D的手势姿态估计。但自顶向下姿态估计方法在很大程度上取决于视觉传感器的可靠性,且很容易受目标检测精度的影响,一旦检测目标过多,运行时间会呈线性增长[16]。
针对以上不足,本文提出一种自底向上的RGB图像手势姿态估计方法——基于轻量级手势姿态网络(Lightweight Hand Pose Net,LHPN)算法的手势姿态估计方法。LHPN算法采用Convolutional Pose Machines(CPM)算法[4]的多层次顺序结构,利用调节阶段数的方式来保证算法的精度;为了提升手势姿态估计的综合性能,本文还设计了轻量级的主干网络来保证算法的实时性。
1 CPM算法基本原理
CPM算法由一系列的多阶段卷积神经网络组成,形成一个多层次的结构,如图1所示。经过每个阶段卷积神经网络![]() 生成置信度图之后,用来预测阶段中每个关节点P的图像位置其中Z为图像中所有坐标(u,v)位置预测值的二维集合。对多层次顺序结构中的每个阶段,用t的集合来表示,t=1的阶 段在图1中称为初始化阶段,t>1的阶段称为强化 阶段。
生成置信度图之后,用来预测阶段中每个关节点P的图像位置其中Z为图像中所有坐标(u,v)位置预测值的二维集合。对多层次顺序结构中的每个阶段,用t的集合来表示,t=1的阶 段在图1中称为初始化阶段,t>1的阶段称为强化 阶段。
在t=1的初始化阶段,特征提取网络x从图像中位置z处提取特征,通过来为初始化阶段预测每个位置的置信度信息,其中,且。
对于任意阶段的CPM,使用特征提取网络重新提取原图像特征,与的前向特征映射融合,并在所有阶段重复相同结构,其中。在每个阶段t之后都计算阶段损失值,对算法性能进行局部的监督。
CPM算法具有以下缺点:
(1)CPM在特征提取网络上未统一,意味着在每次提取原图像特征上需消耗大量算力
(2)在CPM每个t>1的阶段,由于跳跃连接[5]时的尺寸不一致,需计算的前向特征映射,这种方式过于复杂且消耗算力。
2 手势姿态估计算法—LHPN算法
针对CPM算法的缺点,在保证手势姿态估计准确度的同时,本文提出Lightweight Hand Pose Net(LHPN)算法。该算法思路主要包括三点:
(1)使用更加轻量级(权重参数更少)的主干网络替代CPM原特征提取网络,且在结构上只对图像做一次主干网络的特征提取。
(2)在每个阶段使用多个小尺寸卷積来减少 参数。
(3)根据算法的实验表现,合理地设计强化 阶数。
LHPN算法遵循CPM的多层次顺序结构,其整体结构图如图2所示。在保持端到端姿态估计的前提下,LHPN算法使用主干网络生成特征图F,统一特征提取网络。
为了保证LHPN算法精度,针对每张原图像,在算法初始化阶段使用双线性插值算法[6]将原图像变换为统一尺寸的输入图像P,![]() 。
。
在算法每个阶段结束后引入类似残差网络的跳跃连接,将特征图F传递给下一个阶段,保证t(t>1)阶段的输入既融合了特征图F的特征,又有t–1阶段的上下文信息。该方法隐式地将上下文信息联系在一起,增大了卷积神经网络的感受野。
LHPN算法在初始化阶段与强化阶段使用3个卷积核尺寸为3×3的尺寸不变卷积,其优势为在保
损失函数的意义是通过式(3)求得每个阶段的预测值与真实值的L2距离(欧式距离)之后再利用式(4)进行累加。得到式(5),其中表示为输出的置信图上的坐标点,Z为所有z的集合。表示第t阶段预测的置信度图在第p个关节点的预测预测值。表示训练时置信度图中z坐标位置上第p个关节点的真实值。
为了进一步提升算法的速度,本文为LHPN算法设计轻量级网络,并将其与经典卷积神经网络进行参数量与计算量对比。借鉴MobileNet[7]中可分离卷积的思想,利用先深度卷积后逐点卷积的方法替代标准卷积,其原理如图3所示。
图3中,用M个维度为的卷积核去卷积对应输入的M个特征图。得到M个结果之后,这M个结果之间互不累加,生成的特征图尺寸为。接下来利用逐点卷积将N个维度为的卷积核卷积之前得到的特征图,最终得到。其一次分离卷积的计算量与参数量表达式为:
如图4所示为本文改进后主干网络结构图,由18层深度卷积层与逐点卷积层交错构成,为降低主干网络的计算量与参数量,进而提升算法整体的运算速度。该卷积神经网络输入与输出特征图的尺寸维度与原算法相同,保证算法能正常运行。
根据表达式(6)(7),该主干网络的计算量与参数量为:
为了进一步证明LHPN算法主干网络的轻量性,将该主干网络与经典主干网络对比参数量与计算量,如表1所示。
表1中VGG16[8]、GoogleNet[9]与AlexNet[10]分别为3种经典深度卷积神经网络模型。在对比之后发现,3种网络模型在参数量与计算量方面都高于LHPN算法主干网络,从而证明本文设计的主干网络模型较为轻量级。
3 基于LHPN算法的手势姿态估计
3.1 实验环境与训练参数设置
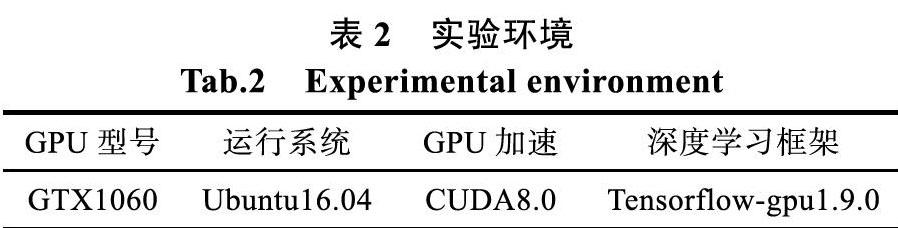
本文所提出的LHPN算法在文献[12]中提供的STB手势姿态估计公共数据集下进行实验,总共30000张训练图片和6000张测试图片。在GTX1060、Ubuntu16.04、Tensorflow1.9.0环境下训练,并利用CUDA8.0对GPU训练进行加速,如表2所示。
设置LHPN算法的最大阶数T为6,使用Adam优化器优化LHPN算法,Adam[11]优化器中的参数![]() 为0.9,
为0.9,![]() 为0.999。训练数据批处理大小(Batch size)为8,迭代次数(Iteration)为3000,如表3所示。权重参数初始化方法利用He初始化[13]。
为0.999。训练数据批处理大小(Batch size)为8,迭代次数(Iteration)为3000,如表3所示。权重参数初始化方法利用He初始化[13]。
3.2 实验结果对比与分析
在STB手势姿态估计测试集上,利用训练完的LHPN算法进行两组实验。第一组实验是对STB测试集进行手势关节点预测性能的评估,在算法的不同阶段t下,得到不同误差阈值下的PCK曲线。第二组实验则是将LHPN算法与现有姿态估计算法进行对比评估。
针对手势姿态估计的效果,本文通过三种指标来评估算法的性能:
(1)在像素上的平均节点误差(Endpoint Error,EPE)[14]。
(2)绘制在不同误差阈值下的正确预测关节点的百分比(Percentage of correct keypoints,PCK)曲线下的面积(Area Under Curve,AUC)[15]。
(3)每一帧图像手势姿态估计的运算时长。
EPE的计算为根据任意手指关节点,其真实值的像素坐标为,通过算法得到的像素位置坐标为,则其手指关节点的EPE表达式为
在STB测试集上对次训练完的LHPN算法进行6次评估,根据不同像素误差阈值,计算PCK的值,获得6个阶段的评估曲线,如图5所示。图5中显示在像素误差阈值15以内时,算法每个阶段的关节点预测表现有所不用,阶段数t越大,关节点预测准确率越高。从图5中还能看出,当t>4时,LHPN算法的AUC增长速度缓慢,几乎与前一阶段相同。
根据表达式(8)计算每个阶段t的EPE平均 值,并利用程序统计每个阶段的帧运算时长和图5中的AUC,结果如表4所示。
表4中AUC的值在t=4阶段增长缓慢,在t=6时的AUC较t=4时的AUC提升了0.3%,与图5曲线相吻合。但每帧手势姿态估计的运算时长在t=6时为0.0833 s,与t=4阶段相比增加约8%。由表4可知,t=4时LHPN算法的综合性能最强。
将LHPN算法与经典算法CPM、Openpose[16]在STB数据集上进行对比,如表5。
由表5可知,LHPN算法在AUC指标上超过CPM算法0.5%,在帧运算时长上减少了0.1358 s。与Openpose算法相比,LHPN算法在每帧图像运算时长上减少了0.0435 s。
LHPN算法在STB測试集上的手势姿态估计的实际效果如图6所示。
4 结论
本文在CPM算法的基础上,提出了基于LHPN算法的手势姿态估计方法,统一特征提取的主干网络,轻量化整个算法模型结构。在STB数据集下,本文分析了LHPN算法在不同结构下的性能,得出最优算法模型。通过LHPN算法与现有经典算法的比较可知,LHPN算法相对CPM算法在AUC上提升0.5%,在帧运算时长上减少0.1358 s,证明该算法针对手势姿态识别的有效性。
参考文献
-
Varun Ramakrishna; Daniel Munoz; Martial Hebert; James Andrew Bagnell; Yaser Sheikh. Pose Machines: Articulated Pose Estimation via Inference Machines[J]. Computer Vision – ECCV 2014, 2014, Vol. 8690: 33-47.
-
Simon, Tomas; Joo, Hanbyul; Matthews, Iain; Sheikh, Yaser. Hand Keypoint Detection in Single Images using Multiview Bootstrapping[J]. 30TH IEEE CONFERENCE ON COMPUTER VISION AND PATTERN RECOGNITION (CVPR 2017), 2017: 4645-4653
-
Wan, C.; Probst, T.; Gool, L. V.; Yao, A. Dense 3D Regression for Hand Pose Estimation[J]. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2018: 5147-5156.
-
Wei, S. -E.; Ramakrishna, V.; Kanade, T.; Sheikh, Y.. Convolutional pose machines[J]. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2016: 4724-4732.
-
Li, J.; Fang, F.; Mei, K.; Zhang, G.. Multi-scale residual network for image super-resolution(Conference Paper)[J]. Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), 2018, Vol. 11212: 527-542.
-
Wei, X.; Wu, Y.; Dong, F.; Zhang, J.; Sun, S.. Developing an image manipulation detection algorithm based on edge detection and faster R-CNN[J]. Symmetry, 2019, Vol. 11(10).
-
Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L. -C.. MobileNetV2: Inverted Residuals and Linear Bottlenecks[J]. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2018: 4510-4520.
-
Karen Simonyan; Andrew Zisserman. Very Deep Convolutional Networks for Large-Scale Image Recognition[J]. Computer Science, 2014.
-
Christian Szegedy; Wei Liu; Yangqing Jia; Pierre Sermanet; Scott Reed; Dragomir Anguelov; Dumitru Erhan; Vincent Vanhoucke; Andrew Rabinovich. Going Deeper with Convolutions[J]. Computer Science, 2014.
-
Alex Krizhevsky; Ilya Sutskever; Geoffrey E. Hinton. ImageNet classification with deep convolutional neural networks[J]. Communications of the ACM, 2017, Vol. 60(6): 84-90.
-
Diederik Kingma; Jimmy Ba. Adam: A Method for Stochastic Optimization[J]. Computer Science, 2014.
-
Jiawei Zhang; Jianbo Jiao; Mingliang Chen; Liangqiong Qu; Xiaobin Xu; Qingxiong Yang. 3D hand pose tracking and estimation using stereo matching[J]. arXiv, 2016: 11.
-
He, Kaiming; Zhang, Xiangyu; Ren, Shaoqing; Sun, Jian. Deep Residual Learning for Image Recognition[J]. 2016 IEEE CONFERENCE ON COMPUTER VISION AND PATTERN RECOGNITION (CVPR), 2016: 770-778.
-
Zimmermann, C.; Brox, T.. Learning to Estimate 3D Hand Pose from Single RGB Images[J]. Proceedings of the IEEE International Conference on Computer Vision, 2017, Vol. 2017: 4913-4921.
-
ZHAO Baojun, ZHAO Boya, TANG Linbo, WANG Wenzheng, and WU Chen. Multi-scale object detection by top-down and bottom-up feature pyramid network[J]. Journal of Systems Engineering and Electronics, 2019, Vol. 30(1): 1-12.
-
Cao Z; Hidalgo Martinez G; Simon T; Wei SE; Sheikh YA. OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields[J]. IEEE Transactions On Pattern Analysis And Machine Intelligence, 2019.
-
Fang, HS (Fang, Hao-Shu) 1; Xie, SQ (Xie, Shuqin) 1; Tai, YW (Tai, Yu-Wing) 2; Lu, CW (Lu, Cewu) 1; IEEE. RMPE: Regional Multi-Person Pose Estimation[J]. 2017 IEEE INTERNATIONAL CONFERENCE ON COMPUTER VISION (ICCV), 2017: 2353-2362.
-
Yi Lu; Yaran Chen; Dongbin Zhao; Jianxin Chen. Graph- FCN for Image Semantic Segmentation[J]. Advances in Neural Networks – ISNN 2019, 2019.