基于畜产品的大数据分析系统设计
2020-12-24杨毅
杨 毅
(河南牧业经济学院,河南 郑州 450000)
1 畜产品大数据的现状
在大数据时代下,人工智能、云平台和高性能计算等技术的高速发展为畜产品智能检测分析系统提供了重要的支撑。智能检测分析系统的建构,有利于提升畜产品检测的智能化,完善畜产品质量安全体系,推进农业信息化建设[1]。将畜产品检测与大数据技术相结合,利用现代信息技术,通过采集海量碎片化的信息数据,准确的进行筛选、分析,并最终归纳、整理出政府和相关机构需要的资讯,构建一套畜产品检测智能分析系统,实行及时有力的深度分析,整体提升畜产品检测监管能力和水平,促进畜牧业产业健康、可持续发展。
针对目前畜产品的检测,其数据处理主要存在3个问题:
(1)畜产品检测注重检测方法的使用和创新,检测设备的培训和升级,检测人员的指导和培训,而对检测数据分析不够重视,没有深度发掘测试数据的潜在价值。
(2)各类检测机构众多且互不统属,有传统的人工统计模式,还有利用软件进行简单分析的模式。此外实验室所用大型仪器,厂家不同,操作软件也不同,数据存储和处理也不同,测试数据分散,导致数据收集困难。
(3)畜产品数据的数据统计、分析与挖掘还比较滞后,需要向系统化、集成化、智能化的方向发展,缺乏相对应的畜产品检测数据分析系统。
2 大数据平台的数据处理
2.1 数据获取
数据获取是从数据源收集数据,数据源分为闭源数据和开源数据。闭源数据指的是和相关检测机构合作获取的内部数据,这部分数据可靠性比较高且不向外部公开,仅仅只作为分析统计使用,不能进行商业的应用。开源数据是指各检测机构通过网络发布的公开检测数据,比较分散,可以利用爬虫软件进行抓取[2]。
对开源数据进行收集时,首先是定时,每段时间对相关网站进行分析,观察所发布检测数据的更新情况。其次定量,要准确地识别出哪些是最新的、哪些是相关的内容。数据主要来源于国家、省、市、县和具有检测资质的企业等相关网站,这些数据都比较分散,需要进一步进行有意义信息的提取,比如:过滤冗余信息,集成互补性信息。这其中还存在很多问题,如信息的质量问题,哪些信息是有价值的、可信赖的。可以从可信溯源(信息的不同来源进行分析,省市级的信息比较重要和真实)、动态轮询(根据后期分析和预测结果对数据源之前的重要性权重进行动态更新)做出判断。采集数据分为结构化数据和非结构化数据,要区别对待。
2.2 资源聚合
考虑到不同数据来源中数据特性的不同,对于结构化相对较好、关联相对简单的检测机构知识库数据,重点关注检测指标实体(如样品编号、测量对象、浓度等)的识别与消歧;对于采集的非结构化数据,重点关注基于所识别的测试指标实体,抽取数据中的命名实体及其实体之间的关联。最后,研究知识融合方法消除知识元素间的知识冗余、知识冲突,以保证知识的精准性与可行度,构建可靠的畜产品检测知识图谱。
针对复杂、迭代式的信息抽取与知识融合,使用具有高可扩展性、可容错性的MapReduce架构(开源Spark系统),实现并发处理与调度。以研究人员为中心,针对数据的局部性,设计合理划分策略,将大的数据集分为若干个容易处理的子数据集。根据划分的策略,针对不同子数据集的特点,设计特有的清洗方法,提升局部数据质量。设计整体清洗策略,清洗多个子数据之间存在的错误、不一致等问题,提升整体数据质量。由于分区的清洗策略充分的考虑了数据的局部特征与整体特征,将显著提高清洗效率和效果[3]。
2.3 对多源异构数据的融合分析
畜产品检测数据之间存在潜在的信息互补和信息冗余,对这些大规模数据进行融合分析和产品动态画像的构建,能更加全面、有效地分析出畜产品质量异常发生的季节、地点、产生的原因等。针对数据的融合分析,本课题从两个方面进行处理:(1)为了过滤掉畜产品数据之间的冗余信息,并且对有意义、高质量的互补信息进行提取,采用主成分分析(PCA)和知识图谱的嵌入向量融合的方法,最终得到更加全面、准确的畜产品特征表示。(2)为了提高在下游任务中的性能,采用集成学习的思想对不同弱分类(或预测)器进行决策层的融合,比如在Flume的基础上结合Spark实现梯度提升决策树(GBDT)以及随机森林(RF)算法的快速分布式融合。
3 数据仓库系统设计
数据仓库能够以不同的维度(如区域,时间等)、不同的粒度级别存储数据,同时具有方便的扩展性,因此课题拟使用基于Hive的 MapReduce+Spark 双计算引擎混合架构进行数据仓库系统设计,通过和机器学习技术结合,无须人工干预和停机就能自动调优、修补、升级、监视和保护数据库,以帮助疫病预测和制定战略决策[4-5],系统设计如图1所示。
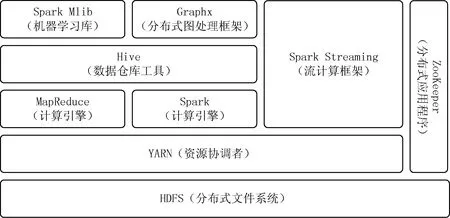
图1 数据仓库系统设计
数据仓库的主模块包含HDFS、YARN、MapReduc、Spark和Hive。首先系统将多源异构数据汇聚到HDFS分布式文件系统,通过YARN对Hadoop 集群和Spark集群的资源进行分配和管理,然后再利用Hive工具进行数据的管理和索引,再通过上层MapReduce和Spark计算引擎对数据进行查询分析和计算。双引擎的好处在于,可以依据业务计算需求的不同,通过配置或简单命令随时切换Hive计算引擎。MapReduce采用了多进程模型,便于细粒度控制每个任务占用的资源,但会消耗较多的启动时间,对实时性要求不高或对稳定性要求较高的场景下使用MapReduce计算引擎;而Spark采用了多线程模型,虽然会出现严重的资源争用,但有效地减少了中间数据传输数量与同步次数,对实时性有一定要求时使用Spark计算引擎。
此外,根据项目的实际需要,添加以下模块:
(1)考虑到业务的扩展性,添加组件ZooKeeper,按需对集群节点进行扩容。
(2)考虑到病情预警所需要的实时性,添加组件Spark Streaming对数据进行流处理,为实时流处理提供平台。
(3)考虑到数据源多样性,添加组件Graphx对图片类型数据进行处理。
(4)考虑到和机器学习技术结合,添加机器学习库Spark Mlib。
4 结语
传统产业与现代信息技术结合,已经成为畜牧业创新发展的制高点。大数据时代,畜牧业在产前、产中、产后各链条、各环节产生大量的数据,如何分析、挖掘、开发和利用大数据技术对海量数据进行相关分析,对畜牧业发展做出准确预测,对畜牧业生产经营管理者进行正确指导和选择合适的技术行为,是畜牧大数据开发的关键,畜产品检测作为畜牧业安全保障的关键一环,需要加快信息资源整合,让数据转起来、用起来,让决策有依据,大数据分析必不可少。
