一种基于用户和商品属性挖掘的协同过滤算法
2020-12-23夏景明刘聪慧
夏景明 刘聪慧


摘 要: 为了解决传统协同过滤算法数据稀疏而导致的推荐不准确等问题,引入商品属性值的概念,根据改进后的用户相似度填充用户?属性矩阵,最后对物品兴趣程度及商品属性评分和进行加权推荐。通过在电影数据集MovieLens上的实验表明,改进后的算法能够显著提升推荐准确率。
关键词: 协同过滤; 商品属性评分; 用户兴趣评分; 推荐算法; 混合推荐; 实验分析
中图分类号: TN911.1?34; TP183 文献标识码: A 文章编号: 1004?373X(2020)23?0120?04
Abstract: In order to solve the problem of inaccurate recommendation caused by sparse data in traditional collaborative filtering algorithm, the concept of commodity attribute value is introduced. The user attribute matrix is filled according to the improved user similarity. The degree of interest and commodity attribute is graded and weighted recommendation is carried out. The experiments on movie dataset Movielens show that the improved algorithm can significantly improve the recommendation accuracy.
Keywords: collaborative filtering; commodity attribute score; user interesting score; recommendation algorithm; hybrid recommendation; experiment analysis
0 引 言
近年来,各个电商平台的发展推进了推荐算法的发展,协同过滤算法[1?3]是推荐算法之一。然而数据稀疏[4?5]导致推荐不准确的问题依然存在[6],这些问题一直是专家研究的热点,文献[7]提出隐藏语义信息的推荐方法对用户和项目标签进行建模;文献[8]提出了一种基于信任度的相似性算法来改善推荐算法中数据稀疏性问题;文献[9]通过结合两种或两种以上的混合方法进行推荐,以解决冷启动等问题,利用对物品兴趣程度和商品属性评分和进行加权推荐。文献[10]利用基于用户的协同过滤算法计算兴趣点的相关性;文獻[11]提出协同过滤相似性度量方法改进来提高推荐效果。
以上推荐效果有了明显的改进,但是却忽略了对商品属性的挖掘。本文通过挖掘商品属性特征,通过计算用户对包含某一属性值的商品的打分得到用户?属性评分矩阵;通过分析用户的属性对Pearson公式进行改进,最后对物品兴趣程度和商品属性评分和进行加权推荐。
1 用户相似性度量方法
本文对传统的User?Based CF算法中的Pearson公式进行改进,Pearson公式如下:
传统的User?Based CF有以下两点问题:
1) 用户很少主动对商品进行评分,数据稀疏的问题会对用户相似性的计算产生很大的影响。
2) 没有对商品属性进行挖掘,本文将计算用户对商品属性喜爱程度来挖掘用户对属性的总体偏好。
2 基于商品属性的协同过滤改进算法的实现
2.1 基于用户对属性评分的协同过滤算法改进
构建用户?属性评分矩阵。根据用户?商品评分数据、商品属性数据以及用户评论商品个数计算用户对商品属性的评分。
1) 商品属性矩阵[X]
商品[i]有多种属性,每种属性又可以分为多个属性。[amn]表示商品[i]第[m]种属性的第[n]个属性,如果该商品有此属性,则[amn]=1,否则等于0。
2) 用户?商品属性值分布
式中:[Puamn]表示用户[u]对属性[amn]的打分;[Iamn]表示具有属性[amn]的商品;[Iu]表示用户评分的商品;[r(I)]表示用户对商品[I]的评分;[rIamn]表示用户评价过的具有[amn]属性的商品平均评分,以此得出用户对属性的评分。
若用户评价过的项目过少,会造成打分偏差,如用户A评价过商品个数[I]过少,却对商品打分很高,用户就会对所有的该商品的属性有很高的评分,忽略了用户评论数量。[P]表示用户评论过的商品的数量,[Q]表示一共的个数。最终得到用户?商品属性值矩阵[R]。
2.2 基于用户特征的用户相似度计算改进
用户属性中引入了性别、年龄、职业属性。用户?属性矩阵中,[U]表示用户集合,[U={u1,u2,…,u}],[F]表示用户属性的集合,用户[U]的属性可以表示为[f={fu1,fu2,…,fun}]。
1) 用户相似度计算
[Sim(u,v)]是Pearson公式,用于计算用户相似度,将用户的年龄、职业、性别属性和Pearson公式进行加权混合,改进后的公式[simim(u,v)]如下:
式中:[Pred(u,i)]是用户[u]对商品[i]的评分;[ru]是用户[u]评价过商品的平均分;[rvi]表示邻居用户[v]对[i]的评分;[rv]表示用户[v]所评价商品的平均评分;[amn∈IPuamn]表示用户[u]对商品[i]的所有属性[amn]相加得到用户[u]对商品[i]的评分;[a]表示权重,[a∈[0,1]]。
2.3 基于项目属性的协同过滤算法改进流程
输入:商品属性矩阵[X],用户?商品评分矩阵
输出:目标用户推荐列表
Step1:随机将80%用户?商品评分矩阵作为训练集,20%作为测试集;
Step2:利用式(2)将用户?商品评分矩阵和商品属性矩阵转化为用户?属性矩阵;
Step3:进行用户相似性改进,具体见式(3);
Step4:利用相似用户对此用户属性矩阵[R]进行填充,见式(4);
Step5:进行用户推荐,目标用户对商品的评分是目标商品[i]通过邻居得到的预测评分和目标用户对该商品的属性值的和加权得到最后的预测评分,具体见式(5)。
3 实验分析
3.1 数据集
实验采用MovieLens数据集,有用户评分信息、用戶信息等。本文选用电影内容和电影地区属性。电影一共有18个属性:喜剧、儿童剧等;电影的地区有:美国、中国、英国等;用户的属性有:性别、年龄、职业。随机将80%用户?商品评分矩阵作为训练集,20%作为测试集。
数据集选取1 000个用户,100 210条评分数据,3 952个电影数据,如表1所示。
3.2 实验环境
实验环境是Windows 7操作系统,工具是Pycharm,语言是Python。
3.3 评估指标
1) [F]值是为了平衡准确率和召回率两者之间的结果,将准确率和召回率进行混合。定义准确率Precision、召回率Recall和[F]如下:
3.4 实验结果分析
3.4.1 参数值的确定
求改进后的用户相似度权重值[a1],[a2],[a3],式(5)的[a]初始定为0.5,后续根据实验进行调整。由表2可以看出,在[a1],[a2],[a3]值为0.25时,MAE取得最小值,比Pearson公式的MAE下降了4%。
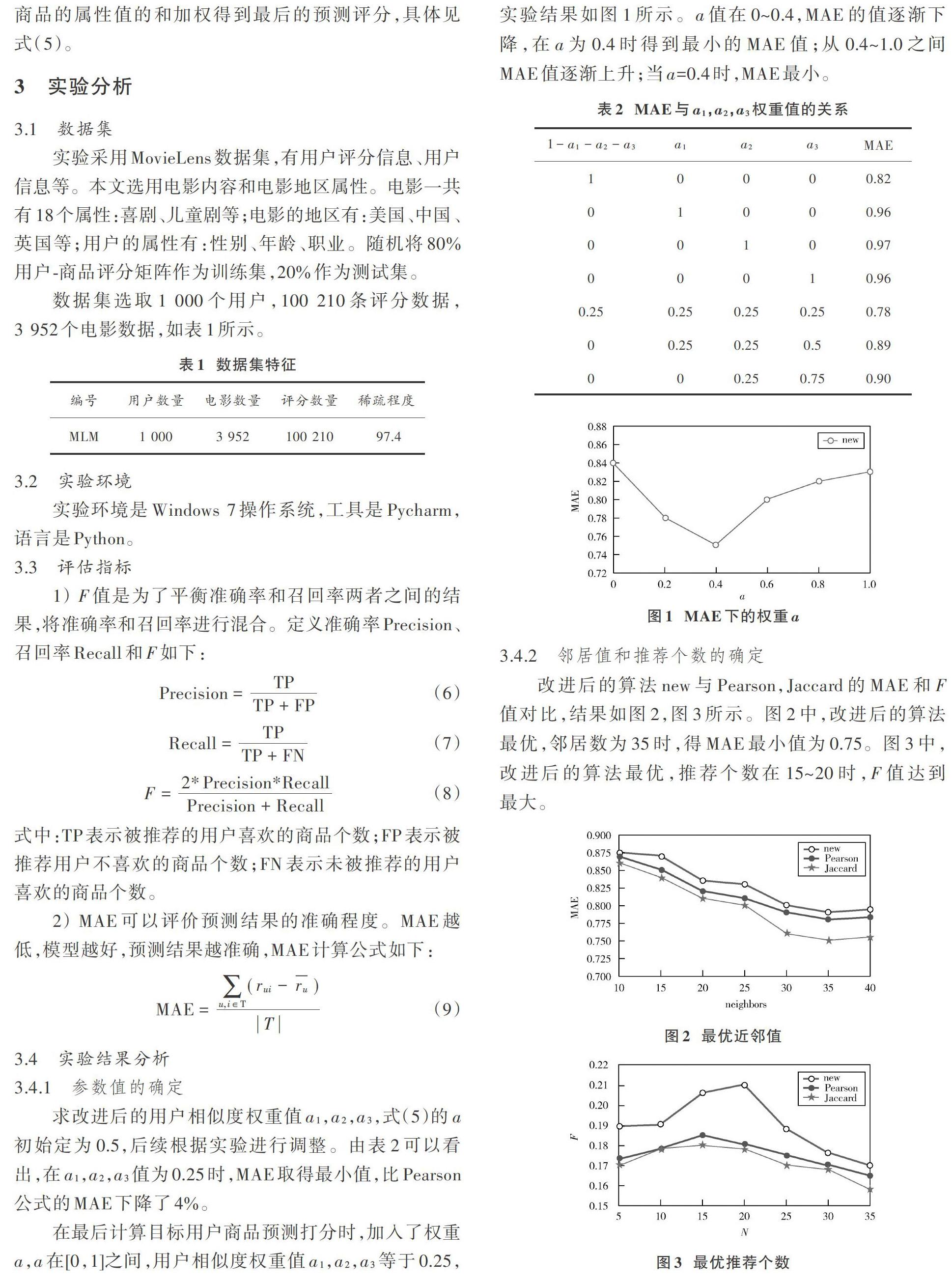
在最后计算目标用户商品预测打分时,加入了权重[a],[a]在[0,1]之间,用户相似度权重值[a1],[a2],[a3]等于0.25,实验结果如图1所示。[a]值在0~0.4,MAE的值逐渐下降,在[a]为0.4时得到最小的MAE值;从0.4~1.0之间MAE值逐渐上升;当[a]=0.4时,MAE最小。
3.4.2 邻居值和推荐个数的确定
改进后的算法new与Pearson,Jaccard的MAE和[F]值对比,结果如图2,图3所示。图2中,改进后的算法最优,邻居数为35时,得MAE最小值为0.75。图3中,改进后的算法最优,推荐个数在15~20时,[F]值达到最大。
4 结 语
本文通过提取用户属性和传统计算用户相似度的算法进行加权得到改进后的用户相似度计算方法,再通过用户相似度填充用户?属性评分的稀疏矩阵,最后给目标用户推荐商品时,将邻居用户推荐商品的分数和用户自身对商品的评分混合加权得到最终推荐商品列表,通过实验表明,本文改进后的协同过滤算法较传统的协同过滤算法在推荐准确度上有明显的提高。
注:本文通讯作者为刘聪慧。
参考文献
[1] 孔艳莉.基于协同过滤算法的个性化推荐技术研究[D].北京:北京工业大学,2016.
[2] 项亮.推荐系统实践[M].北京:人民邮电出版社,2012:51?58.
[3] 张亮.基于协同过滤与划分聚类的推荐算法研究[D].长春:吉林大学,2014.
[4] 刘文佳,张骏.改进的协同过滤算法在电影推荐系统中的应用[J].现代商贸工业,2018(17):59?62.
[5] 郭宁宁,王宝亮,侯永宏,等.融合社交网络特征的协同过滤推荐算法[J].计算机科学与探索,2018,12(2):208?217.
[6] KIM S?C, SUNG K?J, PARK C?S, et al. Improvement of collaborative filtering using rating normalization [J]. Multimedia tools and applications, 2016, 75(9): 4957?4968.
[7] CHEN Chaochao, ZHENG Xiaolin, WANG Yan, et al. Capturing semantic correlation for item recommendation in tagging systems [C]// Proceedings of the 30th Conference on Artificial Intelligence. Phoenix, Arizona: AAAI, 2016: 108?114.
[8] CHEN Hao, LI Zhongkun, HU Wei. An improved collaborative recommendation algorithm based on optimized user similarity [J]. The journal of supercomputing, 2016, 72(7): 2565?2578.
[9] COVINGTO P, ADAM S. Deep neural networks for YouTube recommendations [C]// Proceedings of the 10th ACM Conference on Recommender Systems. Boston, MA, USA: ACM, 2016: 191?198.
[10] CHEN Xuefeng, ZENG Yifeng, CONG Gao, et al. On information coverage for location category based point?of?interest recommendation [C]// Twenty?ninth AAAI Conference on Artificial Intelligence. Austin, Texas, USA: AAAI Press, 2015: 37?43.
[11] AHN H J. A new similarity measure for collaborative filtering to alleviate the new user cold?starting problem [J]. Information sciences, 2008, 178(1): 37?51.
[12] 贺怀清,计瑜,惠康华,等.一种基于稀疏分段的协同过滤推荐算法[J].现代电子技术,2019,42(9):90?94.
[13] 杨丽丽,袁浩浩.基于组合优化理论的协同过滤推荐算法[J].现代电子技术,2018,41(1):139?142.
