基于机器学习方法的电动汽车价格预测
2020-12-23孙一飞夏帆唐晨添赵陆亮
孙一飞 夏帆 唐晨添 赵陆亮
摘要:运用多种机器学习方法对给定电动汽车数据建立了模型,对比发现了逻辑斯蒂回归模型的性能最好,精确度达97.33%,最终选择逻辑斯蒂回归模型用于对电动汽车的价格进行预测。
關键词:价格预测;机器学习;精确度
中图分类号:F426
文献标识码:A 文章编号:1674-9944(2020)14-0266-03
1 引言
1.1 研究意义
伴随着国家政策的实施和民众消费偏好的转变,电动汽车市场进入了蓬勃发展时期。但是在受到国家补贴促进作用的同时,电动汽车市场的发展对国家补贴政策的依赖性也逐渐加深。钟财富[1]发现由于补贴大幅度下降,2019年,电动汽车销售量10年来首次降低。以往较大力度的补贴政策,导致电动汽车的定价具有一定程度的不合理性,当补贴作用下降的时候,消费者会比以往更加关注电动汽车的价格。因此本文希望运用多种机器学习方法,通过对电动汽车数据建立模型,选取最有效的模型对电动汽车的价格进行预测,让企业更合理地定价,以促进电动汽车行业的发展。
1.2 文献综述
目前各种机器学习方法研究成果颇丰,Erhan Bergil等[2]使用KNN方法研究分析了6种不同手部运动的双通道肌电图记录,取得了不错的效果;黄莹,任伟[3]使用多分类逻辑斯蒂回归对允让构式进行分析,发现允让构式具有统计性先占特征;Mohammad Reza Pahlavan-Rad等[4]使用简单(多元线性回归)和复杂(随机森林)模型来联系协变量和渗透测量,发现随机森林预测根据视觉审查被判断为更接近现实;
2 研究内容与研究方法
2.1 研究目的
使用多种机器学习方法在测试集上建立模型,比较各个方法在测试集上的精确度[1],选择合适的模型,对电动汽车进行价格预测。
2.2 假设条件
特征的充分必要性:电动汽车的价格由且只由给定的电动汽车数据中的20 个属性共同来决定。这个假设条件没有现实意义上的必然性,但是由于获取到的数据的限制,只能做出这种假设。
2.3 模型设立步骤
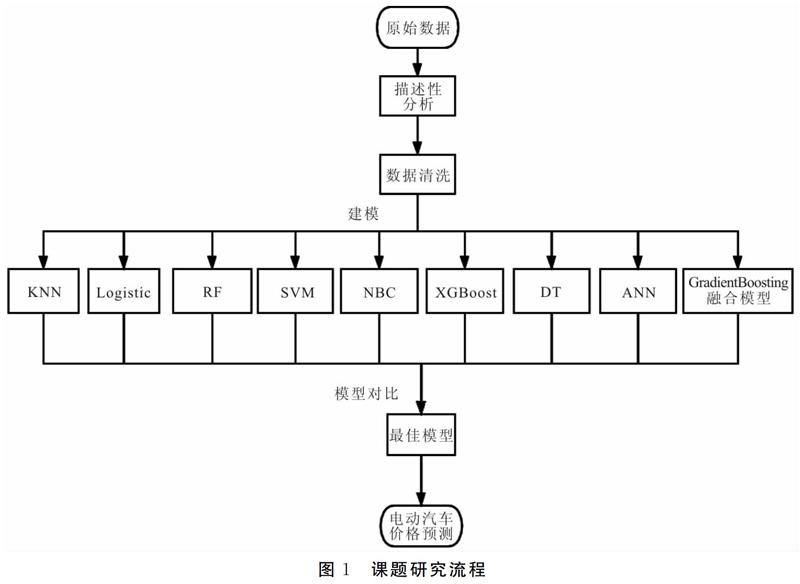
本文在假设条件成立的情况下,模型设立步骤如图1所示。
(1)首先对数据进行描述性统计分析,检查数据的平衡性、有无缺失值和异常值,然后进行数据清洗、填补等操作。
(2)选择K近邻(k-Nearest Neighbor,KNN)、逻辑斯蒂回归(Logistic Regression,LR)、随机森林(random forest,RF)、支持向量机(Support vector machine,SVM)、朴素贝叶斯(Naive Bayes Classifier ,NBC)、XGBoost、决策树(decision tree,DT)以及人工神经网络(artificial neural network ,ANN)8种方法建立模型,然后基于前8种模型构建GradientBoosting融合模型,进行比较。
(3)选取最优模型对电动汽车进行价格预测。
3 原始数据的描述性分析及数据清洗
3.1 数据来源
本文数据来自上海财经大学数学学院举办的全国首届研究生工业与金融大数据建模与计算邀请赛初赛C题:电动汽车价格预测相关数据。原始数据分为训练集和测试集两部分,其中训练集1500条数据,测试集500条数据,由于给定的测试集数据没有价格数据,难以计算精确度,所以本文拟将测试集数据按7∶3的比例重新划分出测试集和训练集两部分数据。
3.2 数据缺失情况分析
原始数据各标签有效数据均为1500条,缺失数据0条,没有数据缺失,是完整的数据集。
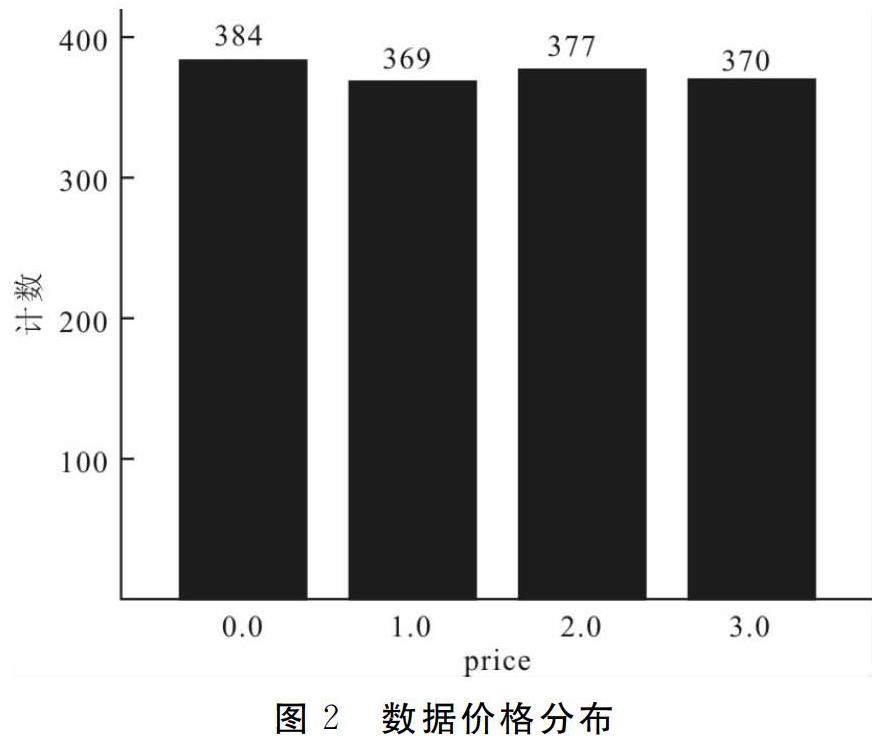
3.3 原始数据样本均衡情况分析
预测变量价格的4个等级类别样本量均在370个左右,原始数据样本分布平衡(图2)。
3.4 数据预处理
原始数据是完整的平衡样本,所以不需要进行异常值、缺失值以及不平衡数据处理。由于本文使用的一些机器学习方法对数据量纲比较敏感,所以会对数据进行归一化处理,消除数据量纲的影响,提高模型性能。
4 建模与分析
在对数据进行初步分析和预处理之后,开始构建模型,对模型进行优化分析。
4.1 KNN
建立KNN初始模型,使用网格搜索方法调整参数,通过交叉验证方式获得最终的KNN模型的精确度为93.33%。
4.2 Logistic回归
分别使用拟牛顿法、牛顿法、随机平均梯度下降法、改进的随机平均下降法构建Logistic回归模型,通过正则化方法消除过拟合现象,最终选择牛顿法求解的模型作为Logistic模型的代表,其精确度为97.33%。
4.3 随机森林
构造初始模型,对数据进行分类,获得该模型的精确度。调整参数n_estimators,通过交叉验证方式,确定随机森林里基评估器的最佳数目,使用网格搜索方法调整参数,将最后调整好的参数写入随机森林方法中构造最终的随机森林模型,通过交叉验证方式获得代表性的随机森林模型的精确度。最终构建基评估器为142、最大树深度为11、获得分枝时考虑的特征个数为10、使用信息增益方法选取特征的随机森林模型,其精确度为90.13%。
4.4 支持向量机(SVM)
由于数据中各个特征数据具有不同的量纲,数据存在十分严重的量纲不一问题,而SVM模型严重受到数据量纲的影响。为了消除数据量纲不一问题对SVM模型的严重影响,首先将数据进行归一化预处理,使用线性核函数(linear)、多项式核函数(poly)、高斯径向基核函数(rbf)以及双曲正切核函数(sigmoid),分别构建SVM模型并进行比较,选出对测试集数据预测拟合效果最好的模型作为SVM模型的代表。最终选择使用线性核函数构建的SVM模型,其精确度为94.89%。
4.5 朴素贝叶斯模型
分别使用高斯分布朴素贝叶斯分类器和多项式朴素贝叶斯分类器构造模型,对测试数据集数据进行预测,模型精确度都为82.08%和80.89%,
4.6 XGBoost
构造初始模型,对数据进行分类,获得该模型的精确度。调整参数n_estimators,通过交叉验证方式,确定XGBoost里弱评估器的最佳数目,使用网格搜索方法调整参数,将最后调整好的参数写入XGBoost方法中构造最终的XGBoost模型,通过交叉验证方式获得代表性的XGBoost模型的测试集精确度。最终构建弱分类器选定为梯度提升树(gbtree)、个数为153 个,subsample为0.75,reg_alpha为0.2,reg_lambda为0.65,gamma为0.2的XGBoost分类器,其精确度为92.60%。
4.7 决策树模型
构建一般树模型,进行控制随机性和剪枝操作,每一步操作都用信息增益和基尼指数两种方法进行特征选取,构建六种模型,对比各模型的精确度,选出最优模型。最后选择进行剪枝处理的最大树深度为12的使用基尼系数方法进行特征选择的决策树模型,其训练精确度为98.86%,精确度为81.33%。
4.8 人工神经网络(ANN)
构建的多层感知机分类器神经网络的精确度为66.64%,精确度很低,说明模型拟合效果不理想。考虑到原始数据中各个特征数据具有不同的量纲,数据存在十分严重的量纲不一问题,所以对原始数据进行归一化处理,再建立模型拟合,模型的精确度为92.67%,归一化处理数据后,模型的拟合效果有了很大的提升。
4.9 GradientBoosting融合模型
为了获得性能更好的模型,尝试使用Blending 方法通过集成学习方法GradientBoosting根据上述8个模型的结果构造融合模型,分析是否会得到性能更好的模型,最终构成的融合模型的精确度为90.22%,模型性能一般。
5 结论与展望
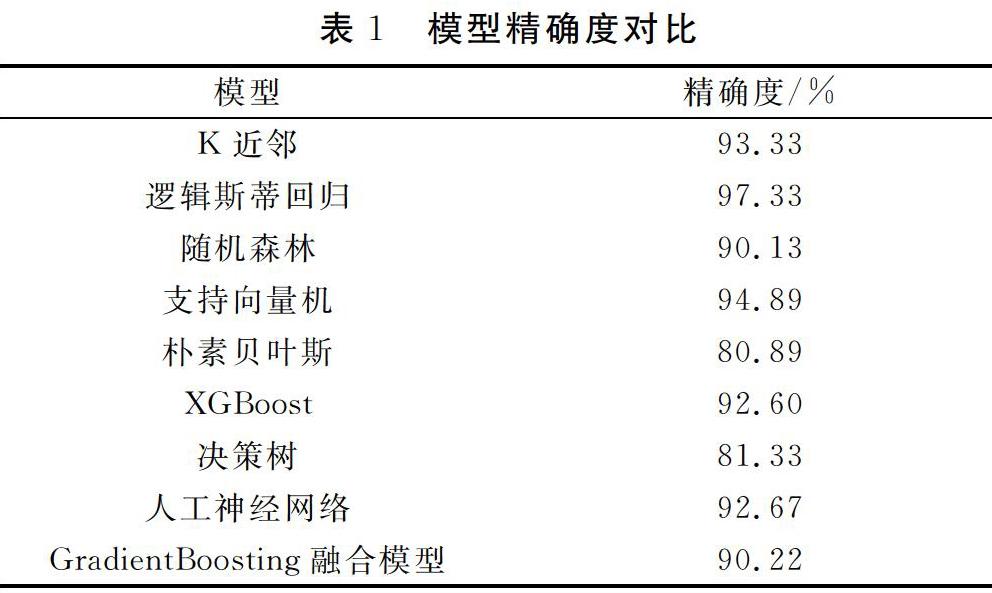
本文运用多种机器学习方法,通过对收集到的电动汽车数据建立模型,选取最有效的模型对电动汽车的价格进行预测。本文9种方法的精确度如表1所示。
逻辑斯蒂回归模型的性能最好,决策树和朴素贝叶斯模型的性能最差,最终选择逻辑斯蒂回归模型用于数据的预测。
参考文献
[1]钟财富.十字路口下的电动汽车行业[J].中国投资(中英文),2020(Z4):59~60.
[2]Erhan Bergil, Canan Oral, Engin Ufuk Ergul. Efficient Hand Movement Detection Using k-Means Clustering and k-Nearest Neighbor Algorithms [J]. Journal of Medical and Biological Engineering, 2020 (prepublish).
[3]黃 莹,任 伟.英语分析型允让构式的致使倾向研究——多分类逻辑斯蒂回归和多重对应分析法[J].外语与外语教学,2020(3):11~21,146.
[4]Mohammad Reza Pahlavan-Rad,Khodadad Dahmardeh, Mojtaba Hadizadeh Gholamali Keykha, et al. Prediction of soil water infiltration using multiple linear regression and random forest in a dry flood plain, eastern Iran[J]. Catena, 2020(194).
