面向航天专网的敏感内容审查系统构建浅析
2020-12-23北京空间机电研究所刘丽玲范慧莉赵青青闫顺琪孙麒刘启贤
◎北京空间机电研究所 刘丽玲 范慧莉 赵青青 闫顺琪 孙麒 刘启贤
随着网络化、智能化技术的飞速发展,航天企业的信息化、办公自动化水平显著提升,与此同时,也给国家涉密信息的安全防护工作带来了新的挑战。在保密管理工作中敏感内容输出检查是一个重要的环节。目前,大部分航天企业对专网用户日常处理的信息进行监督和检查时,还只是通过对保密安全系统的入口进行监督和审计。近些年,为适应运营业务需要,航天企业建立了多种保密安全系统,由于系统入口数量多,各系统审计的颗粒度、审计标准不统一,给涉密信息内容的检查带来了诸多问题,因此构建面向航天专网的敏感内容审查系统,改进检查方法手段,加强对日常工作中传播文件敏感信息的识别与控制,在航天企业保密安全管理工作中显得尤为重要。
面向航天专网的敏感内容审查系统需要实现以下三方面的目标功能:
1、根据统一的敏感信息筛查规则,对所有客户端的打印内容进行自动检查,审计高密级文档按低密级打印等违规行为。
2、根据统一的敏感信息筛查规则,对所有客户端的刻录内容进行自动审查,审计高密级文档按低密级刻录等违规行为。
3、对定制化的敏感信息防护要求,能够对待检查的文件内容进行全文检索审查。
一、解决方案
设计面向所有应用系统的统一的接口协议,敏感内容审查系统通过调用统一的接口可以收集邮件系统、导入导出系统、打印系统等第三方系统的数据,基于数据解析技术、OCR识别技术,进行文本内容提取。利用全文检索技术,根据预先定义的敏感内容审查规则对数据进行深度的内容审查,通过上述的主要功能,构建一套集安全、可控、高效于一体的保密审查管理体系。

图1 内容审查管理系统架构图
敏感内容审查系统架构图如图1所示。
(一)审查内容同步
借助统一的接口协议,利用OCR内容识别提取技术、数据传输技术来自动同步邮件、导入导出、打印等办公应用系统的任务日志和任务内容文件,将同步的数据通过数据解析技术进行文字解析提取后保存在数据库中,用于后续的内容审查。
(二)保密审查员管理
系统管理员可根据实际管理要求,配置企业级保密审查员和多个部门级保密审查员,并配置审查员的相应权限和审查范围。通常审查范围要求如下:
所级审查员:具有定期对全企业各涉密系统、所有客户端文件检索审查的权限。
部门级审查员:具有对部门内所有客户端文件检索审查的权限,可以自定义审查规则。
(三)敏感内容筛查规则
保密审查员可以按照涉密等级、业务内容设定敏感内容、风险筛查点规则,其规则通常为关键主题词的集合,如密级、型号代号、型号名称等不同类型关键字或者具体的型号名称和型号代号值。
(四)审查报告生成
根据审查员设定的敏感内容筛查规则,自动对系统中存储的文本内容或图片进行全文检索,并生成风险报告。根据风险报告按照审查员预先设定的审查周期自动生成审查报告。生成周期分为日报、周报、月报、季报、年报。也可以根据实际业务需要,指定特定的时间范围进行手动生成审查报告。
(五)关键敏感词检索
保密审查员可以自定义关键敏感词进行全文检索,系统将含有关键字的所有文本内容显示在列表中,审查员可以根据需要显示检索内容的上下文,也可以查看任务的预览文件和下载原文。关键字在上下文及预览文件中全部以高亮显示,便于用户迅速查看定位,根据敏感词所处语境判断是否涉密。
二、关键技术
(一)OCR内容提取
敏感内容审查系统的OCR(Optical Character Recognition)内容提取采用的是光学字符识别技术,对图片中的图像数据进行转码、数据处理、字符识别、位置识别等。OCR的概念最早由德国科学家TauSheck在1929年首次提出,我国在“863”计划以后开始OCR技术的研究,经过近百年的发展,软件硬件的不断更新换代,目前对汉字的识别率已经超过98%[1-2]。在信息识别领域比较常用的有开源的Tesseract、OCRopus、Cuneiform等,商用的有汉王、ABBYY、ExperVision TypeReader等。
面向航天专网的敏感内容审查系统在选择OCR引擎时,应主要考虑以下几个方面:
(1)完全断网使用。航天企业根据不同工作环境的限制,存在离线工作情况,所以OCR系统从图片识别,到授权方式必须支持在离线的环境中进行,且不能引入其他的硬件设备。
(2)词语识别准确率。经过调研发现,市场上存在的部分产品对拉丁语系的转换识别效果不错,对中文的识别准确率不高。对于排版不规整的图片,识别准确率相对较低。
(3)操作系统的适配。对军工企业,操作系统正在逐步国产化,OCR引擎开发需要兼容国产化的操作系统,可以适配Windows平台及国产化操作系统。
1、Tesseract技术原理
Tesseract OCR引擎功能强大,由于识别准确率高,多用于驾驶证识别、车牌识别、医学化验单识别、快递单号识别等领域,其主要功能概括地可以分为两部分:
(1)图像轮廓分析是字符识别的准备阶段。基于制表位检测的方法对页面布局进行分析提取,将图像的表格、文本、图片等元素内容进行区分。
(2)文本块分割和识别是整个Tesseract的核心,工作内容最为复杂。首先是文本块切割,包括粗略切分和精细切分两个过程:
粗略切分,就是利用字符间的间隔进行切分,得到大部分的字符文本块,也有粘连文本块或者错误切分的文本块。然后通过字符区域类型来判定识别字符,通过与字符库中的文本进行比对,完成第一次字符的识别。
精细切分,就是根据粗略切分识别出来的字符,对粘连的文本块进行二次切割,同时合并错误分割的字符,完成文本块的精细切分。
Tesseract OCR引擎识别步骤[3]:
如历代江西文学就是江西人民创造的优秀的文化遗产,发掘其深厚意蕴可以让青年学生了解江西文学、文化、历史的发展轨迹,江西对全国的贡献、江西在全国的地位,树立江西青年的自豪感、自信心、责任感,激发他们对江西的热爱之情,培养他们的乡土情怀,促进精神文明建设。
(1)字符轮廓区域分析,检测出图片字符区域,以及子轮廓,进一步将众多轮廓线集合为块区域。
(2)由字符轮廓和块区域得出文本行,并且通过字符间的空格识别出词语。对于固定间距的文本块利用字符单元分割出单个字符,而对百分号的文本通过模糊间隔来分割。
(3)使用具有学习能力的自适应分类器,逐次对每个单词进行分析。分析过程中将满足条件的字符记录到分类器中,这样越到后面识别的字符越准确。识别到页尾后,再对页首识别不准确的字符进行二次识别,识别精度越来越高。
(4)最后,借助其他方法,识别含糊不清的空格,如通过笔画高度识别小写字母、大写字母的文本。
2、Tesseract OCR 引擎的应用
文字识别引擎可应用于许多领域,包括输入文本、自动处理邮件以及自动获取文本的其他领域。这些领域涵盖零售商品价签信息提取、快递单号信息识别、银行支票的处理、身份证件识别、医疗化验单信息识别等很多场景,方便用户快速录入信息、提取信息、识别信息,提高各行各业的工作效率[4]。
(二)全文检索
面向航天专网的敏感内容审查系统其核心是对文本内容进行快速遍历检查,根据检查规则找出并定位到具体的关键词语。
内容审查分两个阶段:
1、在各类安全系统任务执行过程中,对单个任务的文本内容进行筛查,判断是否符合保密要求,给审查者提供意见。
2、在任务结束后,对大量任务的文本数据进行检索遍历。
在任务执行过程中进行简单的文字搜索,实现较为简单,可以满足第1个阶段的需求,但在第2个阶段,对大量的数据进行批量检索,耗时会比较长,无法满足日常保密审查应用要求。所以研究所在系统建设中引入全文检索引擎。全文检索引擎产品类型较多,包括基于Java的Lucene、ElasticSearch、Solr,C++的Xapian、 Sphinx,Python的Whoosh,Go的wokong等[5-6]。
航天企业选型时需要从以下几个方面综合考虑:
(1)性能、稳定性、成熟度。全文检索引擎需要保存所有入口的文本内容,并创建一对一的索引,以便快速检索、定位,属于核心中间件。
(2)中文分词。拉丁语系是以空格作为语句单元分割,但对于中文就较为复杂,尤其是在应对新词的情况下,必要时在性能和准确性方面应有所取舍,建议优先考虑检索内容的可靠性。
(3)部署和可扩展性。支持多平台,在单服务器无法支持的情况下可以方便的横向扩展。
(4)选型时还要综合考虑成本、易用性等。
作者所在研究所选择使用ElasticSearch作为全文检索引擎。
对ElasticSearch进行简单的性能测试。测试样本为1.95GB的纯文本,共2001个文件,其中最大文件为31.1MB,对应Word文档约为12038页,1000万字。一次性对所有文本创建索引,三次平均耗时为29分43秒,期间CPU使用率在2%~18%间浮动。索引完成后,索引数据共3.21GB。索引创建完成后,按短语搜索的方式进行查询,同一字符,第一次搜索较慢,消耗在0.7s到2s间浮动,第二次及之后的耗时在0.2s以下。内存大小对检索速度影响较大。 (注:以上时间包含测试程序运行时间,HTTP RESTFul通信时间,ElasticSearch检索时间。测试机CPU:Intel(R)Core(TM) i7-3720QM CPU @ 2.60GHz,RAM 12GB。)
1、Elastic Search原理
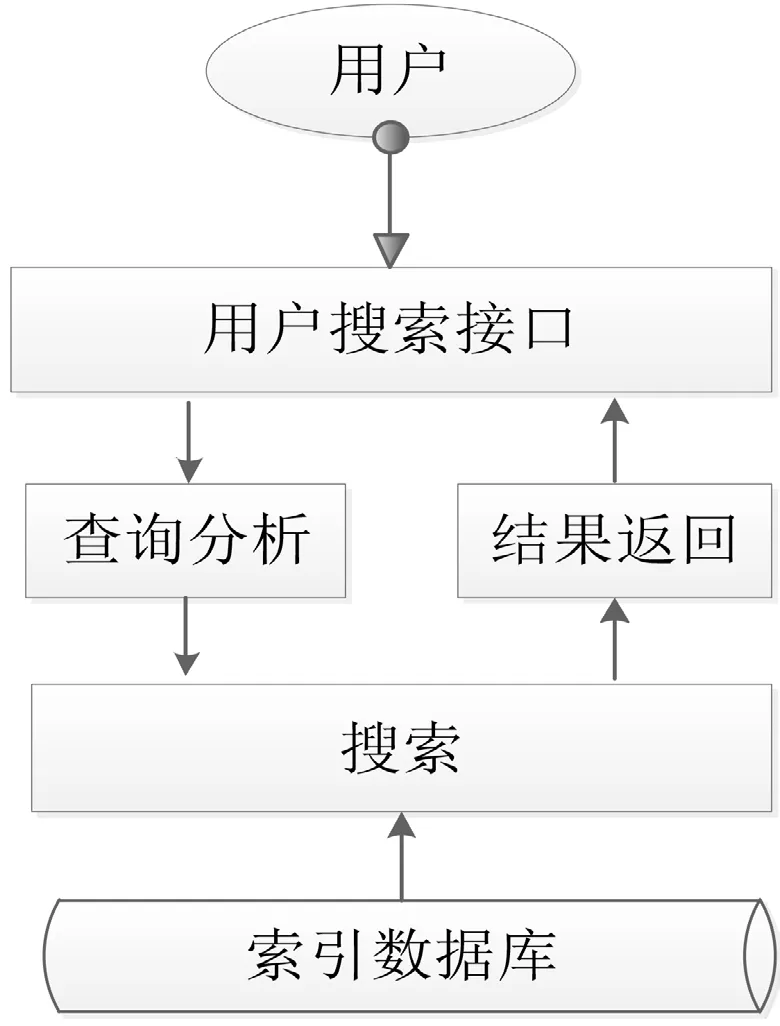
图2 Elastic Search全文检索原理图
Elastic Search(ES)是一个基于Apache Lucene构建的开源、分布式的全文搜索引擎,同时也是一个分布式文档库,库中的每个字段均是被索引的数据且可被搜索,能够扩展至数以百计的服务器,存贮与处理PB级的数据,可以短时间存储、搜索和分析大量的数据,具有高效搜索的能力,Elastic Search全文检索原理图如图2所示。
Elastic Search具有以下4个主要特点[6]:
(1)高度的可扩展性:增加一台机器,只需要添加集群配置,启动Elastic Search进行即可;
(2)分片机制:一个索引可以分成多个Sharding,提高处理效率;
(3)高可用性:每个分片可以设置多个备份,少量机器宕机不影响正常使用;
(4)不仅具有全文搜索能力,还可以按照字段进行结构化搜索、聚合分析。
2、Elastic Search的应用
Elastic Search多应用于热点图、交通情况信息图等需要实时数据搜索和显示的场景以及数据更新频繁的场景等。
(1)2 013 年初,GitHub放弃Solr,使用Elastic Search来做P B级的搜索。GitHub使用ElasticSearch搜索20TB的数据,包括13亿文件和1300亿行代码。
(2)维基百科启动以elasticsearch为基础的核心搜索架构。
(3)SoundCloud使用ElasticSearch为将近1.8亿用户提供即时且精准的音乐搜索服务。
(4)百度目前广泛采用ElasticSearch作为文本数据分析,收集百度所有服务器上的各类指标数据及用户定义数据,通过对数据进行多维分析展示,用来辅助定位分析实例异常或业务层面异常。目前已覆盖百度20多个业务线,包括casio、云分析、网盟、预测、文库、风控等,单集群最大100台机器,200个ES节点,每天导入30TB以上的数据。
(5)此外,新浪,阿里,有赞等著名公司也开始了ES方面的相关技术研发和实践。
三、结语
本文针对航天专网涉密信息审计存在多入口、人工审计成本高、效率低、审计结果不精准等问题,提出了通过信息化手段实现自动风险筛查的解决方案,辅助管理员审查敏感内容,提高审查效率。通过在本单位实际应用表明,敏感内容审查系统可以对保密安全管理提供有效的支撑。
