基于深度学习的电网负荷预测技术研究
2020-12-23童准
童 准
(国电永福发电有限公司,广西桂林541805)
1 电网负荷预测技术研究背景
全球经济飞速发展的同时,带来了能源供给不足,引起全球气候变暖、环境恶化等现象[1-2],建立环保、安全、高效、可靠的电力系统成为电力行业研究的热点。据国家能源统计局数据显示,我国每年都会有几十亿度电能浪费[3]。因此,寻求一种准确的电能负荷预测方法,可以准确预测电能的供需峰值,降低电能对环境造成的不良影响,同时节约电能。电网负荷预测是以历史时间序列数据为数据源,利用数据挖掘、深度学习等技术建立电网负荷预测数学模型,预测未来时间段的电力负荷,方便电力部门科学有效地管理电能供需量,减少电能浪费[4]。
2 基于深度学习的电网负荷预测技术研究
2.1 基于K-means的用户聚类
本文基于给定时段用电特征数据集,利用K-means聚类算法,对居民用户进行聚类。
2.1.1 聚类流程分析
(1)数据输入:输入给定时段居民用电数据。
(2)数据预处理:首先对采集数据进行清洗,然后根据居民日用电数据的不同,建立多维用电特征数据集。
(3)确定居民类别的数量:对居民用电特征数据集进行降维,根据降维确定居民类别数,该数值即为K-means中最佳簇集数k。
(4)确定初始聚类中心:选取用户用电特征、密度、距离权重最大的前k个居民为初始聚类中心。
(5)聚类分析:计算各聚类中心的居民用户所属簇集中用户与聚类中心之间的距离(距离计算采用欧式距离[5]),进而划分簇集。
2.1.2 聚类实验及分析
本次实验选用某小区90户居民,采集9月1日、9月2日、9月3日3天的用电量作为数据集,对90户居民进行K-means聚类,最终产生4个簇集,聚类结果如图1所示,用户被分成四大类。
2.2 基于LSTM的电网负荷预测模型构建
以聚类分析为研究基础,针对不同类别的居民、小区,提出基于LSTM的电网负荷预测技术,通过智能仪表采集居民用电数据作为模型的数据源,确定LSTM网络参数,然后对居民进行K-means聚类分析,对不同类别的居民建立相应的用电负荷预测模型,汇总最终的预测结果为小区总负荷的预测值。
2.2.1 模型构建流程
LSTM模型构建流程如图2所示。
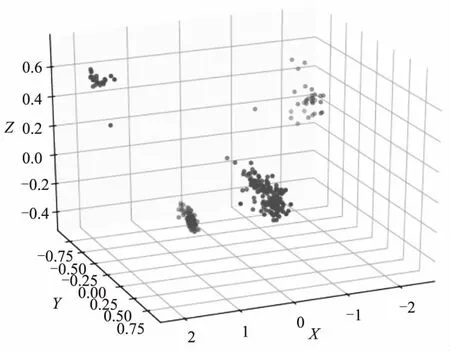
图1 K-means聚类结果图

图2 LSTM模型构建流程图
(1)数据预处理:对智能仪表采集的含噪声点的数据进行处理。本研究数据预处理采用归一化处理方法。
(2)构建输入层:选取经过处理的基于时间序列的历史用电负荷数据作为预测模型的输入,利用全连接的方法将隐藏层与输入层进行连接。
(3)构建隐藏层:设置隐藏层层数为2,连接方式采用全连接的方式。
(4)构建损失函数。
损失函数计算公式:

式中:Yi为电力负荷的实际值;yi为电力负荷的预测值。
LSTM网络通过不断训练,使模型的映射关系逼近真实输入与输出之间的非线性关系。
(5)确定LSTM网络优化器:经对比,本次选用计算效率较高的Adam训练器作为LSTM模型的网络参数。
(6)电力负荷预测值输出:Adam训练器根据损失函数梯度下降的方向,多次调整LSTM权重,直至损失函数达到最优值,此刻输出的基于时间序列的用电序列预测值映射为电网的负荷预测值。
2.2.2 电网负荷预测实验及结果分析
本次实验选取9月5日某小区电力负荷数据为数据源,选取LSTM隐藏层的单元数为10,样本大小为600个,Adam网络优化器,根据实验选取的LSTM网络学习率为0.6%,使用K-means算法对居民进行聚类分析,将用户分为商业、中青年、老年3类用户,建立3个对应的LSTM网络,对用电负荷进行预测实验,最后将3个LSTM网络的负荷预测值累加即为总预测值,预测结果如图3所示。
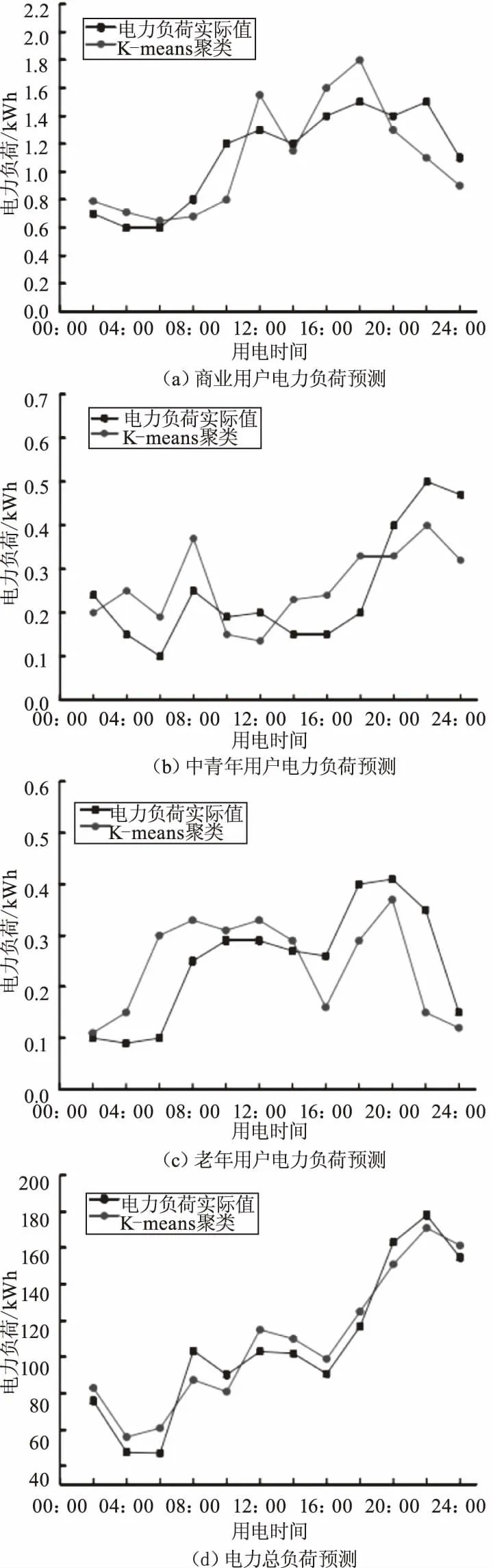
图3 不同类型用户电力负荷预测及电力总负荷预测
从图3中看出虽然有一部分分支预测结果与实际值有偏差,但是整体趋势预测值与实际值接近,尤其是在总负荷预测中,LSTM网络精确度高,预测效果好。
3 结语
电力作为国家重要的支柱产业,关乎到每个人的生活品质,人们对用电的需求日益增加,对用电质量要求日趋提高,因此,准确的电网负荷预测技术具有重要的研究价值。本文对用户进行聚类,将用户分为不同用电性质的用户,针对不同性质用户建立相应的LSTM负荷预测网络,最后将所有预测值进行累加即为总负荷预测值,该方法打破了传统的建立单一网络预测的手段,提高了电网预测的准确度,促进了我国电力行业的发展。
