C4.5决策树算法的阈值自适应色谱峰研究与实现
2020-12-23廖建平李志军陈昊旻楚金伟
廖建平,单 杰,李志军,,陈昊旻,楚金伟,万 福
(1.中国南方电网有限责任公司 超高压输电公司,广东 广州 510663;2.国电南京自动化股份有限公司,江苏 南京 211153;3.重庆大学 输配电装备及系统安全与新技术国家重点实验室,重庆 400030)
0 引言
油中溶解气体分析(dissolved gas analysis,DGA)是诊断油浸式高压电力设备故障的重要手段[1]。在线色谱技术是实现油浸式变压器实时监测的关键技术。油浸式变压器在线色谱峰定性是确定某色谱峰所对应的特征气体,主要任务是从有干扰的色谱信号中提取特定组分气体谱峰的信息,包括峰的起始点、峰的顶点、峰的结束点等。
目前,色谱峰定性分析方法很多,包括时间窗法[2]、导数法[3-4]、匹配模式法[5]、灰色关联度分析法[6]以及反向传播(back propagation,BP)神经网络法[7]。文献[5]利用模式匹配技术进行变压器色谱峰定性,会出现不合理的负相关以及不同参数的选择导致不同的结果。文献[6]是对文献[3-4]的改进,但是关联度数值设定过于刚性化。文献[7]采用的BP神经网络是对斜率门限阈值和窗口区间阈值的确定,存在色谱峰漂移难以辨识的问题。故时间窗法和导数法是目前的主流方法,但其根据保留时间设定每个成分的窗口区间从而进行成分定性[8],在实际应用中存在的缺点是辨识范围较小,抗假峰能力差。色谱仪器长时间运行之后,色谱峰会出现不可避免地漂移,若漂移范围超过窗口区间则出现无法识峰或识峰错误的故障。文献[9]引入模糊数学来解决这一问题,但隶属度函数一般根据经验选区,具有很大的主观性,容易导致误判。
针对以上问题,本文将C4.5决策树算法引入电力变压器油色谱定性领域,对色谱峰的有效定性起到一定的作用。
1 算法原理和研究流程
决策树是一种常见的机器学习方法。C4.5决策树算法是数据分类算法中比较常用的经典算法之一,得到的结果较为准确,理解性强,容易看懂[10]。该算法同时也是一种监督学习,首先给定多个样本,每个样本都有一组特征属性和一个类别,这些类别是事先确定的,通过监督学习得到一个分类器(决策树模型)。这个分类器能够对新出现的对象根据其特征属性给出正确的分类[11]。
本文色谱数据来源于国电南京自动化股份有限公司NS801B变压器油中溶解气体在线监测装置,该装置基于气相色谱检测技术,能按预设的周期实时监测变压器油中溶解的H2、CO、CO2、CH4、C2H2、C2H4和C2H6等特征气体浓度和增长率,通过故障诊断专家系统分析潜伏性故障及故障类型,便于实时了解变压器运行状态。装置内采用的色谱分离模块可采集上述7种气体,色谱曲线图如图1所示。

图1 色谱曲线图
NS801B装置利用导数的辨识峰算法获得的峰位置达上百个,只知道峰位置,不知道这个峰到底是哪个组分。该装置采用的方法是根据保留时间设定窗口区间来定性组分,即对于每个成分,根据该成分的标准保留时间预先设定其窗口变动区间阈值,只要实际色谱分析所得的保留时间在标准保留时间的窗口变动区间内,便定性该组分峰。然而色谱分析流程是多因素耦合的复杂非线性系统,由于变压器油色谱在线监测装置在长期运行过程中,色谱峰受载气流量、色谱柱老化、环境温度、气敏检测器、油气分离等多因素影响,导致色谱图会出现非规则、不确定性变化,如峰位的前后移动、峰形的扩展收缩。显然,如果此时仍然采用固定阈值对色谱图分析处理就会产生较大的误差,易出现对气体色谱峰的误判和漏判现象,影响检测的正确性和准确性。

图2 采用C4.5决策树算法对组分峰进行定性的研究流程
本文采用C4.5决策树算法对组分峰进行定性,在决策树对根结点选取时,采用二分法对连续属性进行离散化处理,从而得到特征属性的自适应阈值;接着利用特征属性作为结点进行决策树分类,得到7个组分峰;再按照预定顺序对7个组分峰进行定性,从而避免利用保留时间设定的窗口区间所带来的识峰错误。采用C4.5决策树算法对组分峰进行定性的研究流程如图2所示。
2 研究方法
2.1 数据准备及特征选取
为了充分说明本文算法,收集了NS801B装置监测的不同油中溶解气体浓度的7组数据,其数据编号分别为20190605152550、20190605162730、20190605172741、20190605182731、20190605187462、20190605111772和20190605162435。NS801B变压器油中溶解气体在线监测装置辨识的每一组数据中的峰个数分别为363、183、172、221、145、179和156。本文将第1组数据作为训练样本集D,共计363个;将剩余组数据作为测试样本集,分别为Q1、Q2、Q3、Q4、Q5和Q6。
NS801B变压器油中溶解气体在线监测装置可以测得的峰属性包括:起始点、中间点、结束点、峰高、峰宽、峰面积、高宽比(峰高/峰宽)、峰间距和峰类型等。本文将其属性分为两类:第一类为决策特征属性(用于决策树算法的数据分类);第二类为无效属性,即非第一类属性。定义决策树算法峰定性的特征属性集为:
U={峰高,峰宽,峰面积,峰中点位置}。
2.2 C4.5决策树模型的构建
经过数据准备及数据选取之后,本文得到了训练样本集D,测试样本集Q1~Q6以及特征属性集U。充分利用特征属性集,选择最优的特征属性进行组合,建立分类规则,分类出有效峰。
2.2.1 特征属性阈值的自适应
传统方法根据经验固定阈值大小,而本文算法特征属性集U中的4个特征属性(峰高、峰宽、峰面积和峰中点位置)都是连续值,将数据进行预处理(即离散化),从而自适应阈值。本文利用二分法对连续属性进行处理[12],得到自适应阈值。
定义h、w、s和p分别为训练样本集D中特征属性峰高、峰宽、峰面积和峰中点位置的连续属性。h、w、s和p在训练样本集D上出现了V个可能的取值(V≤363),将这些取值从小到大进行排序,分别记为:
峰高:{h1,h2,h3,…,hV};
峰宽:{w1,w2,w3,…,wV};
峰面积:{s1,s2,s3,…,sV};
峰中点位置:{p1,p2,p3,…,pV},
各个V值根据数据真实情况各不相同。
以峰高h为例,基于划分点t可将训练样本集分为Dt+和Dt-,其中,Dt-包含峰高不大于t的样本,Dt+包含峰高大于t的样本。显然,对相邻的属性取值hi与hi+1来说,t在区间[hi,hi+1)中任意取值所产生的划分结果相同。因此,对连续属性峰高h,本文考察包含(V-1)个元素的候选分点集合
(1)
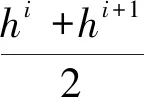
2.2.2 基于信息增益比率的C4.5决策树结点特征属性选择
C4.5决策树算法采用自顶向下的贪婪搜索历遍可能的决策树空间[13]。该算法的构造过程从“特征属性集U中哪一个特征将在树的根结点被测试”的问题开始,分类能力最好的特征属性将被选作树的根结点,然后为该根结点特征的每个可能值产生一个分支,并将训练样本集D排列到适当的分支之下(即样本的特征属性值对应的分支);重复整个过程,用每个分支结点关联的训练样本来选取在该结点被测试的最佳特征[14]。特征参数集U中共4个特征参数(h,w,s,p),利用C4.5决策树算法的增益率来选择最佳的划分特征属性,以峰高h为例,具体步骤如下。
步骤1计算信息熵。信息熵是度量样本集纯度最常用的一种指标。当前训练样本集D中有效峰所占的比例为Pk(k=1,2),则D的信息熵定义[12]如下:
(2)
其中:Ent(D)的值越小,D的纯度越高;训练样本集D中包含有效峰和无效峰。
步骤2根据2.2.1小节进行数据离散化处理之后,计算出用特征属性峰高h对训练样本集D进行划分所获得的信息增益[12]:
(3)

步骤3C4.5决策树算法是从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。增益率定义[12]如下:
(4)
其中:
(5)
IV(h)称为特征属性h的固有值。一般来说属性h的可能取值越多(即V越大),则IV(h)的值通常会越大[15]。
步骤4比较Gain_ratio(D,h),Gain_ratio(D,w),Gain_ratio(D,s),Gain_ratio(D,p)的大小,选择最大的值作为最佳划分点,即根结点。接着在每个分支结点循环以上过程。
结束条件:数据分类结束或者所有True决策点样本总数和为7。
2.2.3 决策树形成
训练编号为20190605152550的第1组数据,对特征属性“峰高”,在决策树学习开始时,根结点包含19个训练样本(363个数据值中除去重复峰宽值所得到的真实样本)。故由式(2)得Ent(D)=0.949 452。根据式(1),该属性的候选划分点集合包含15个候选值:T峰高={0,0.002 342,0.008 358,0.019 199,0.033 967,0.918 968,1.968 109,4.132 203,6.571 499,10.679 400,15.141 897,18.746 905,22.110 970,22.893 356,31.650 967}。由式(3)可计算出特征属性“峰高”的信息增益较高的划分点为0.918 968,对应信息增益为0.485。最后,由式(4)得该划分点的增益率为Gain_ratio(D,h)=0.486。
同理,得到其余特征属性划分点和增益率为:
峰宽:92.509,Gain_ratio(D,w)=0.588;
峰面积:80.318,Gain_ratio(D,s)=0.484;
峰中点位置:4 022.5,Gain_ratio(D,p)=0.511。

图3 峰定性的C4.5决策树
于是,“峰宽”被选为根结点划分属性,接着结点划分过程递归进行,然后对决策树修剪(修剪过程中发现本文所示的决策树已经不能再做任何修剪,修剪掉任何规则都会使分类精度降低,修剪方法见文献[10]),最终生成如图3所示的峰定性的C4.5决策树。
3 算法测试及结果分析

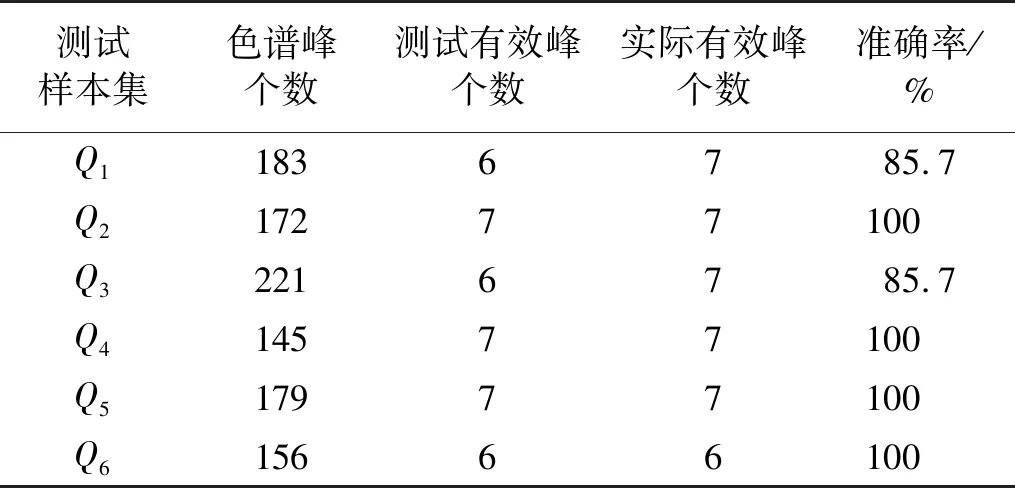
表1 基于C4.5决策树算法的分类精度结果
由表1可知:测试结果的平均准确率已经达到95.23%,但是仍未达到准确无误进行峰识别的预期。分析其原因,关键在于决策树中对于特征属性峰面积阈值的自适应设定。训练样本集D与测试样本集Q进行比较,发现训练样本集D所测气体浓度较高,导致峰面积较大,故在决策树算法中得到的自适应阈值较大(s=425.32)。这就导致测试样本集Q1和Q3在大阈值时的错误分类。为了解决这一问题,可以将峰面积的阈值人工修改为s=10,则测试样本Q1和Q3的准确率从85.7%提升为100%;或者进一步扩大训练样本集的容量,找到更为合适的自适应阈值,准确率也会提高。

图4 变压器油中溶解气体在线监测装置现场图
随后,将该算法应用于国电南京自动化股份有限公司NS801B变压器油中溶解气体在线监测装置中,该装置现场图如图4所示。对现场运行超过5年的20台装置的数据进行算法验证,其中一台装置编号为NS801B-20140623032的部分验证结果如表2所示。训练样本集为2014年的现场运行数据(训练样本D=36),验证样本集为2015年6月至2018年6月的数据(每2个月采集1次)。
由表2可知:在不人为调整峰位置、峰宽等参数的前提下,当训练样本集D≥30时就能避免自适应阈值不准确的问题(即上述s过大问题),此时该算法准确率在98.4%以上。同时,在数据整理过程中发现,该算法应用在20台装置上时,2015年的准确率明显高于2018年。可能是当装置运行时间过长时,由于各种原因峰位会向后漂移,造成算法的准确率下降。为进一步提高准确率,NS801B变压器油中溶解气体在线监测装置应用策略为每运行一个月,自动将前一个月的数据作为训练样本,使阈值重新自适应一次,叶子结点将重新生成,得到一棵新的决策树。此时该算法的准确率将接近100%。

表2 装置编号为NS801B-20140623032的部分验证结果
4 结束语
本文将C4.5决策树算法引入了变压器色谱峰定性领域,论述了基于C4.5决策树算法的峰定性原理,对该算法进行了研究、设计和测试分析。该算法通过多个特征属性的自适应阈值来进行决策,原理简单,有效峰定性准确,可有效避免因峰位的前后移动、峰形的扩展收缩导致的对气体色谱峰的误判和漏判等现象。
