基于语义分析的PHP Webshell 检测方法研究*
2020-12-23岳子涵沈兴文吴毅良
岳子涵,薛 质,沈兴文,吴毅良
(1.上海交通大学,上海 200240;2.上海市浦东新区大数据中心,上海 200240;3.广东电网公司江门供电局,广东 江门 529099)
0 引言
随着互联网的不断发展,Web 应用逐渐广泛应用于人们的生活、娱乐以及工作,因此安全问题随之而生[1]。PHP 凭借成本低、速度快、可移植性好等优点,成为Web 开发中最受欢迎的脚本语言之一。但是,由于攻击面广和攻击技术多,PHP 语言存在一些安全问题。Webshell 是一种动态脚本形式存在的后门程序[2]。攻击者可通过访问该程序得到命令执行环境,进而达到控制服务器的目的,对用户产生了巨大威胁。因此,PHP Webshell 的检测方法研究是备受学术界和业界共同关注的Web 安全研究主题之一。
传统的Webshell 检测方法主要包括静态分析、动态分析以及这两种方法的有机结合[3]。基于静态分析的检测方法是指对攻击者上传的Webshell 文件通过基于规则和特征码匹配的方式发现Webshell[4]。这种方法资源占用小,检测快速方便,但存在漏检率过高的问题,无未知风险对抗能力[5]。动态检测方法是对Webshell 文件执行时特有的HTTP 请求或响应进行检测[6]。这种方法误判率较高且系统资源和实践消耗较大。此外,由于攻击者利用代码混淆隐藏技术使得Webshell 的变体层见叠出,传统的特征提取检测方法局限性较大[7]。可见,研究可抵御混淆绕过技术且误报率低的Webshell 检测系统具有重要的实用价值。
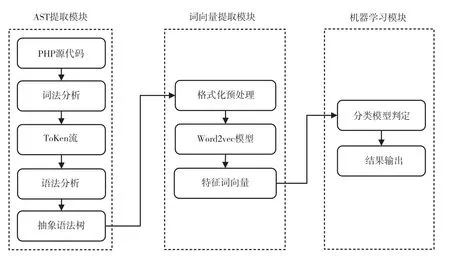
图1 Webshell 检测模型设计
由于混淆前后的Web 恶意代码在语义结构上具有一定的相似性,因此针对PHP 文件,本文以代码的语义结构为切入点描述脚本,提出了基于语义分析的Webshell 检测方法。该方法与当下热点研究机器学习相结合,将PHP 代码的语义结构作为文本特征,结合机器学习构建恶意Web 代码检测模型。
1 系统模型
基于语义分析的Webshell 检测系统的训练流程如图1 所示,由抽象语法树提取模块、词向量提取模块和机器学习模块3 部分组成。本系统的输入为PHP 文件的源代码。首先,提取输入样本的抽象语法树,并保存为文本文件。其次,对其进行预处理,使用Word2vec 算法提取行为特征,生成对应的词向量。最后,将其输入到机器学习模型中,分析并判断是否为Webshell。
1.1 抽象语法树提取
抽象语法树(Abstract,Syntax Tree,AST)是程序语言源代码经过词法分析和语法分析后获得的树状解析表示[8]。树的每个节点表示源代码中的一个结构。AST 一般为编译器语法分析阶段的产物,只提供主要结构。与直接使用源代码相比,使用AST 进行处理的主要优点是AST 是对代码分段后的结果的总结[9]。树结构反映了代码的实际执行顺序,操作符周围的值显示在每棵树的相应参数中。通过将PHP 代码转化为AST 后执行字向量转换,基于底层代码的特征集合,避免了技术干扰方法的影响,实现了对未知Webshell 的检测。
PHP 源代码通过图1 中AST 提取模块所示过程转换为抽象语法树。本文主要通过PHP-Parser将PHP 源代码转化为抽象语法树。PHP-Parser 是一个由PHP 编写的PHP 代码静态分析工具,可以生成指定PHP 源代码相对应的AST。它首先会列出所有的全局变量,其次根据代码的执行顺序拆分函数名和参数值,最后生成如图2 所示的AST。一个语句对应一个数组,数组的名字即为被调用的函数。数组中按顺序存放函数类型和函数值。

图2 一句话木马及其抽象语法树示例
1.2 词向量提取
Word2vec 是2013 年谷歌团队推出的一款开源词向量特征训练工具[10-11]。它使用向量运算代替文本内容处理,通过向量化文本中的单词,用向量空间的距离表示每个词之间的距离。距离越近,则出现在一定相邻范围中的概率越大。因此,文本语义上的相似度可通过向量空间的相似度表示。Word2vec 一般分为连续词袋模型(Continuous Bagof-Words,CBOW)和跳字模型(Skip-Gram)两种模型。它们的区别在于CBOW 根据某一特征词的上下文相关词预测该词的概率,Skip-Gram 则是基于某一特征词预测其上下文相关词的概率。由于该场景的样本中,各单词出现的频率随机分布于几十到上万之间,差异较大,故选择可较好处理低频元素的Skip-Gram 词向量训练模型,以得到更高的准确率。
对于生成的AST,使用Python 脚本处理得到格式化的文本序列(如图3 所示)作为模型的原始输入,便于特征提取。然后,对所有样本的文本序列进行分词,构成用于训练词向量的数据集,使用Word2vec 生成每个单词的词向量。对于每一个抽象语法树样本,对其包含的所有单词的词向量计算算术平均值得到该文本的向量。

图3 格式化文本序列
1.3 基于机器学习的入侵检测系统
将Word2vec 算法生成的文本词向量作为基于机器学习的Webshell 检测模型的输入。本文共选取随机森林、XGBoost 和SVM 这3 种机器学习算法进行训练。
1.3.1 随机森林
随机森林算法是机器学习算法中常见的一种决策树算法,利用多棵决策树,通过投票机制对样本进行训练和预测[12]。每棵树有放回地随机抽取训练样本,随机选取特征作为分枝依据,使得每个子决策树得到一个判断结果[13]。经由所有子决策树,根据其判断进行表决,得到随机森林的判定结果。由于是有放回地抽取样本且随机选择特征,它可以有效避免可能出现的过拟合现象。
1.3.2 XGBoost
XGBoost 是一种高效、可扩展的梯度增强框架实现[14],是一种集成学习。集成学习的目的是通过结合多个基学习器的预测结果[15],提高单个学习器的泛化能力和鲁棒性。XGBoost 以CART 树中的回归树作为基分类器,但不是简单地将几个CART 树进行组合。它将模型上次预测产生的误差作为参考进行下一颗树的建立,从而不断降低损失函数[16]。作为梯度增强回归算法的改进优化,XGBoost 算法是Tree Model 的一个特例[17]。
1.3.3 SVM
支持向量机(Support Vector Machines,SVM)是一种判别分类器算法,通过定义两个类之间的超平面,可以以最佳效果将所有样本分为两个不同类别的点[18],同时使得类间所有点的相对分离距离最大。支持向量机算法通过寻找最优解来寻找最优超平面参数。公差边界越大,错误分类点的个数越接近边界。但是,大多数其他数据点的距离会增加,惩罚系数会减小,以提高整体验证样本的准确性。
2 实验与结果分析
2.1 实验数据与环境
本文的PHP 训练样本集大小为24389。其中:正常样本22400 个,主要来源于PHP 开源内容管理系统(Content Management System,CMS),如wordpress、phpcms 以及yii;收集异常样本1989 个,主要来源于github 上公开的数据。在实际的生产环境中,正常PHP 文件的数量远远大于恶意webshell文件的数量。因此,将正样本和负样本的比例大约设置为10:1,增加白样本的数量,以使模型对实际环境更具适应性,从而增强模型的鲁棒性和适应性。
实验环境的软硬件配置信息如表1 所示。在PHP 编译环境中,将PHP 代码转换成抽象语法树,之后的词向量提取、模型训练与检测均基于Python语言。词向量训练使用Genism 库,机器学习部分则采用sklearn(scikit-learn)实现。

表1 实验配置环境
2.2 实验评价指标
本次实验为二分类问题,实验结果可分为以下4 类。
(1)真正例(True Positive,TP):真实值为正常样本,预测值为正常样本。
(2)假负例(False Negative,FN):真实值为正常样本,预测值为Webshell 样本。
(3)假正例(False Positive,FP):真实值为Webshell 样本,预测值为正常样本。
(4)真负例(True Negative,TN):真实值为Webshell 样本,预测值为Webshell 样本。
本次实验采用十折交叉验证评估模型,评估指标采用精确率P、召回率R和准确率ACC,计算公式如下:
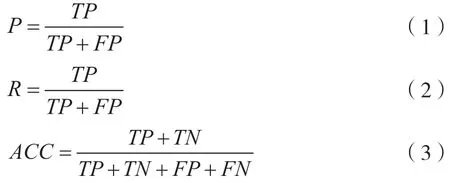
2.3 实验设计与结果分析
本次实验流程如图4 所示。
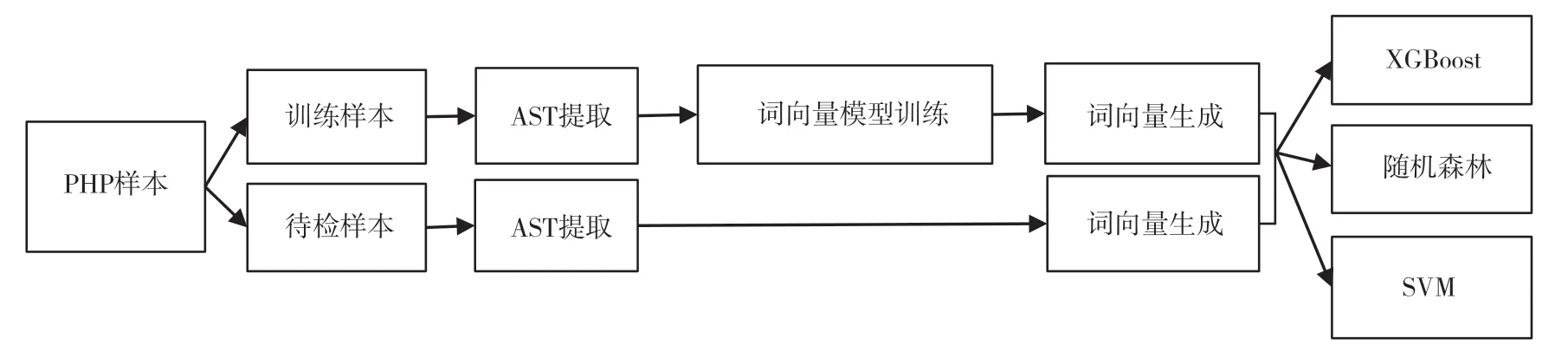
图4 实验流程
使用Word2vec 将AST 文本序列转化为数字向量作为输入数据,在输入相同训练特征的情况下,实验对比了XGBoost、随机森林、SVM 这3 种算法的准确率、精确率与召回率,结果如表2 所示。
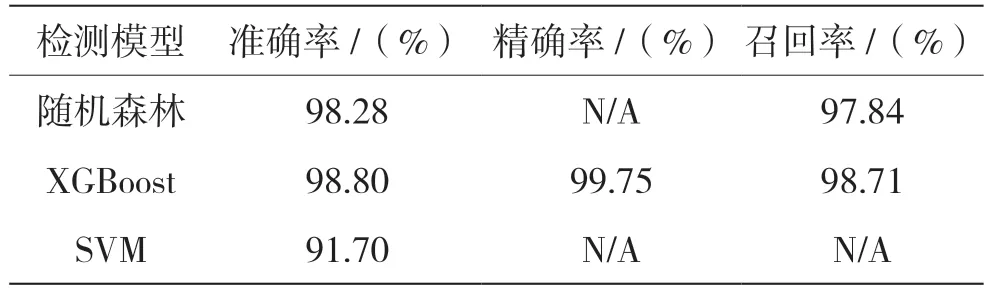
表2 Webshell 检测模型实验结果
结果表明,基于AST 的检测方法准确率可达98.82%,此外具有较高的精确率与召回率。此次实验中,XGBoost 模型各项指标均优于其他算法,因此选择基于XGBoost 算法的模型进行PHP Webshell检测。XGBoost 模型的参数设置如下:maxdepth=8,min-child-weight=1,learning-rate=0.1,n-estimators=1000,gamma=0。
此外,表3 显示了本文模型与PHP Webshell 检测相关工作的对比结果。由对比结果可得,本文模型在准确率、精确率和召回率等多个方面均有所提升。
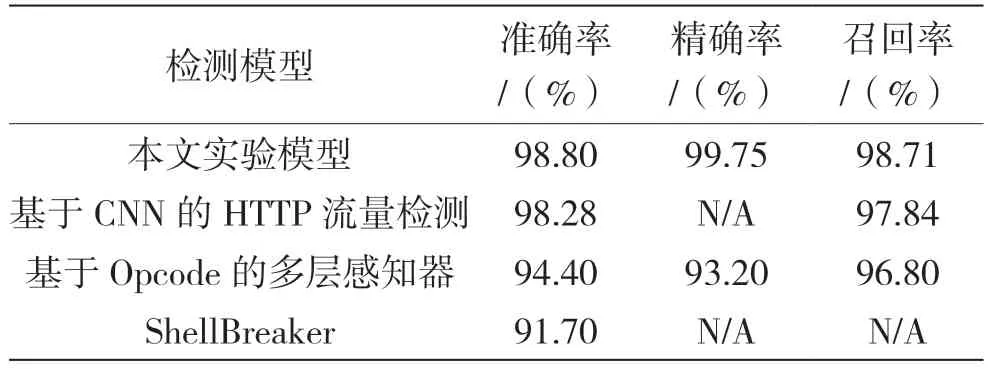
表3 相关算法性能比较
3 结语
为了更好地解决当前Webshell 检测中混淆恶意代码的检测问题,本文提出了一种基于语义分析的Webshell 检测系统。从PHP 文件的源代码中提取AST,使用Word2vec 将词法序列转换为词向量作为机器学习模型的最终输入,并对不同的机器学习算法进行验证,最终选择了性能最好、准确率最高的XGBoost 算法。在以后的计划中,将尝试同样的方法对JSP 文件进行检测,并尝试引入动态流量特征信息,结合两者检测方法来降低误报率,以开发一个基于机器学习和深度学习的全面入侵检测系统,从而有效保护网络。
