基于关联知识图的网络攻击检测技术研究与实现*
2020-12-23邹福泰
王 迪,邹福泰,吴 越
(上海交通大学,上海 200240)
0 引言
随着网络的迅猛发展和计算机性能的不断提升,大数据如今被应用在各行各业中,用以提升运作效率和精确画像。在这个数据爆炸的时代,网络入侵技术不断迭代更新。2020 年2 月,美国国土安全部的网络安全和基础设施安全局发布公告,一家未公开名字的天然气管道运营商,在遭到勒索软件攻击后关闭压缩设施达两天之久。攻击事件发生的具体时间未获公布。据悉,攻击始于钓鱼软件内的恶意链接,攻击者从IT 网络渗透到作业OT 网络并植入勒索软件。在关闭压缩设施期间,由于管道传输的依赖性,连带影响到了其他地方的压缩设施。2020 年4 月,葡萄牙跨国能源公司EDP(Energies de Portugal)遭到勒索软件攻击。攻击者声称,已获取EDP 公司10 TB 的敏感数据文件,且索要了1580 的比特币赎金(折合约1090 万美元)。
如何在海量的流量数据里捕获到恶意的网络攻击是当前的一个难题。最近十几年机器学习和深度学习被广泛应用于网络攻击检测,但是它们使用的数据集一般过于陈旧,不能反映当前网络的流量情况。此外,这种检测方式很难对海量数据集进行标定,只能在小范围流量内进行训练测试。基于此背景,本文实现了一种半监督的基于关联知识图和Spark 计算引擎的网络攻击检测技术,在不需全部标定海量数据的同时,通过聚类算法快速缩小检测范围,并通过污点传播Malrank 算法发现可疑节点,进而实现攻击路径的可视化。
本文组织结构如下:第1 章介绍了网络攻击检测技术的相关研究;第2 章分析了具体关联知识图的构建;第3 章介绍了聚类算法和污点传播算法的应用;第4 章从仿真实验的角度验证了整体设计的合理性;第5 章总结全文。
1 相关研究
1.1 机器学习在网络攻击检测中的应用
近年来,随着机器学习的发展,越来越多的相关技术被应用到网络攻击检测上[1]。
机器学习应用到网络攻击检测的技术主要有贝叶斯网络、聚类算法、决策树以及支持向量机(Support Vector Machines,SVM) 等。Jemili 等人提出了使用贝叶斯网络分类器的IDS 框架。这项工作在训练网络中使用了KDD 1999数据的9个特征。在异常检测阶段,正常或攻击判断由联结树推理模块做出,并分别在正常和攻击类别上达到88%和89%的正确率。在下一阶段,异常检测模块从标记为攻击数据的数据中识别出攻击类型。DoS、探测或扫描、R2L、U2R 和其他类别识别正确的概率分别为89%、99%、21%、7%和66%。其中,R2L 和U2R 类别的性能不佳是因为训练实例的数量比其他类别少得多。
基于机器学习的网络攻击检测存在以下缺陷[3]。
(1)依赖于公开数据集的数据标定。目前研究主要使用的数据集仍然是1999 年的KDD 或是DRAPA1998,其数据不能够很好地反映如今的流量特征,且当前也不可能做到在大数据环境下进行全部标定。
(2)不同数据集一般抽取出的攻击特征不同,因此基于一个数据集训练出来的模型很难被应用在别的地方。
1.2 基于关联图的网络攻击检测
随着大数据的发展,为了计算海量的数据,获取更高的处理速度,SPARK 等大数据工具开始被应用在学术和工业领域。针对海量流量无法被全部标定获取测试样本集,近几年关联图技术结合大数据技术被应用在相关领域上。
Milajerdi 等人[4]利用图技术结合系统日志,实现了一种检测高级持续攻击(Advanced Persistent Threat,APT)的系统HOLMES。HOLMES 的目标是产生一个检测信号,表明存在着一系列的APT 阶段性活动。在总结抽象阶段,HOLMES 有效利用了攻击发生期间产生的可疑信息流之间的相关性。除了具有检测功能外,HOLMES 还能够生成高级图表,实时总结攻击者的行动。分析人员可以使用此图进行有效的分析检测。Phyu 等人[5]把关联图应用在社交网络的情感分析上,取得了良好效果。关联图技术首先被用来抽取Tweet 记录。以用户为点,Tweet中各种互动为关系构图。然后,以这张图为基础,将边上所带的Tweet 信息进行语义解析,分析所含情感。最后,通过情感分类器将整个社交网络图分成志趣相投的情感社区。
2 关联知识图构建
本文通过收集网关流量信息并处理来构建以流量中实体为节点、实体相关性为边的关联知识图[6]。
2.1 日志抽取
针对含有疑似攻击流量的Pcap 文件,为了获得构建关联图所需要的信息,使用Bro 框架[7]对Pcap 文件进行处理。
Bro 框架是一款开源的流量分析器,主要分为两个概念层。一是网络事件层(event engine),将原始的网络流量简化为高层的网络事件,如TCP 连接(TCP Connection)和UDP 数据流(UDP Flow)等;二是脚本解释器(policy scrIPt interpreter),用于解析和运行用户编写、实现定制化监测方案的Bro脚本。
本文使用Bro 的日志抽取合文件还原功能。在对Pcap 包进行离线分析后,抽取其相关流量特征生成日志文件,如表1 所示。

表1 Bro 日志文件
2.2 构 图
在得到反映流量特征的日志文件后,基于Spark 大数据工具[8]抽取其中关键信息构建关联知识图G=(V,E)。其中,V∈{IP,Domain,File}。如果两个节点有一定的相关关系,则两节点间存在一边。每条边通过处理最终得到一个权重W(W∈[0,1]),代表节点间的相关性。W越大,代表节点间关系越紧密。
节点间的关系根据日志间的相互联系[9]分为直接关系和间接关系。
2.2.1 直接关系的构建
直接关系为对日志每行进行处理得到的实体之间的关系,如通过Conn.log 中的TCP 连接可以知道两个IP 之间存在直接相连关系。
不同类型的边本质上代表了不同相关性的关系,因此在初始阶段对不同类型的边赋予不同的初始权重代表它们的相关性。例如,Dns.log 中域名Domain与对应的解析IP之间的关系应该是强相关,因为访问该域名其实就是访问该IP。但与之不同的是,Dns.log 中域名Domain 对应请求解析该域名的IP 之间是访问的关系,可能存在偶然性,初始相关权重较小,因此针对几种初始相关权重较小的边种类,需要根据日志信息继续处理,即对任意两个节点之间的连接次数进行计数,记为c,每次该边对应的两个节点再次相连时c=c+1,最后将c用tanh函数归一化并赋值给权重。同时,为了减小c的影响,tanh 函数添加幂次0.03,即:

式中,W为权重。通过tanh 函数将c映射到[0,1]区间,以增大c比较小时对权重的影响和减小c比较大时对权重的影响。
2.2.2 间接关系构建
域名节点之间,文件节点之间按照日志每行记录没有直接关系存在,但是它们之间可能根据相似性存在潜在的间接关系,如恶意文件同属于一个家族。
针对域名间的相似性,本文使用Jaccard 相似度算法[10]。Jaccard 相似度常用于比较有限样本集之间的相似性与差异性。Jaccard 系数值越大,样本相似度越高。Jaccard 相似度算法认为,如果域名属于相同恶意家族,则存在大量相同的主机访问它们。访问主机具有较高重合度,重合度越高,域名属于相同团伙的概率越大。本研究通过计算两个域名之间的Jaccard 值,随后与预先设定的阈值s比较,若大于阈值s,即:
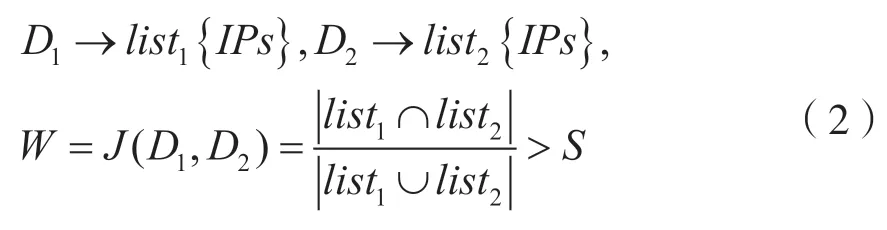
则认为Domain1和Domain2之间具有间接关系,可在此两个域名节点之间建立关联边。
针对文件间的相似性,如果从文本角度分析,直接采用simhash 的方法过于简单。因此,本研究使用IDA+BinDiff 插件[11]对文件从函数层面上进行相似性分析,判断是否存在间接关系。
最终,整个关联知识图实体种类和相互关系如图1 所示。
3 攻击检测算法
在通过构图获得关联知识图后,需要基于此图进行攻击检测,发现潜在的恶意节点和攻击路径。本研究先通过社区算法,利用节点间的相关性缩小后续恶意检测的范围,然后使用基于半监督的污点传播算法发现更多的恶意节点或受害节点。
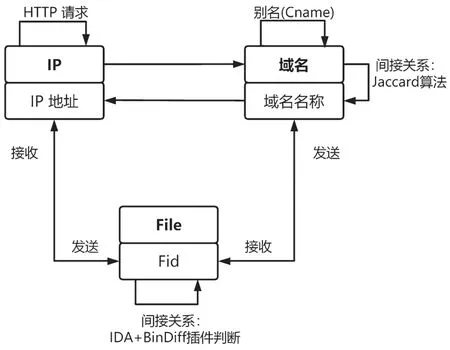
图1 关联知识图实体及相互关系
3.1 社区算法
社区算法主要有Louvain、GN 以及图卷积算法等[12]。因为Louvain 算法在速度方面有独特的优势,适合大数据分析且适合本研究通过边权值构成社区的情景,所以这里采用Louvain 算法作为社区算法。
Louvain 使用模块度Q代表是-1 和1 之间的标量值,表示社区内部链接相对于社区之间链接的密度[13]。模块度Q被定义为:
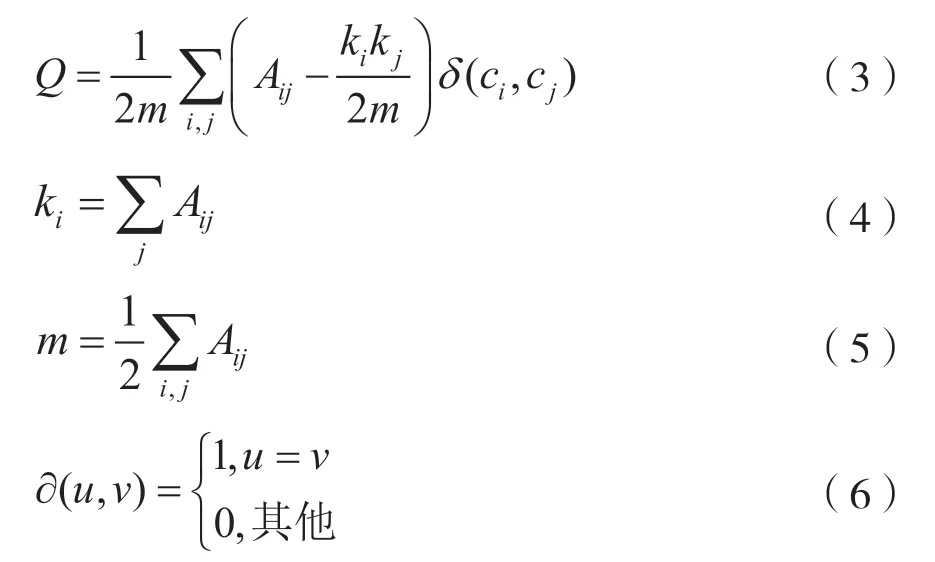
式中,Aij表示节点i和节点j所连边的权重,ki表示与节点i相连的所有边的权重和,m表示图中所有边的权重和,ci表示节点i所在的分区。
Louvain 算法步骤如图2 所示。
(1)通过使模块度Q最大,判断所有节点的最佳社区选择。
(2)将步骤(1)中的社区合并为一个超点,再次计算合并。
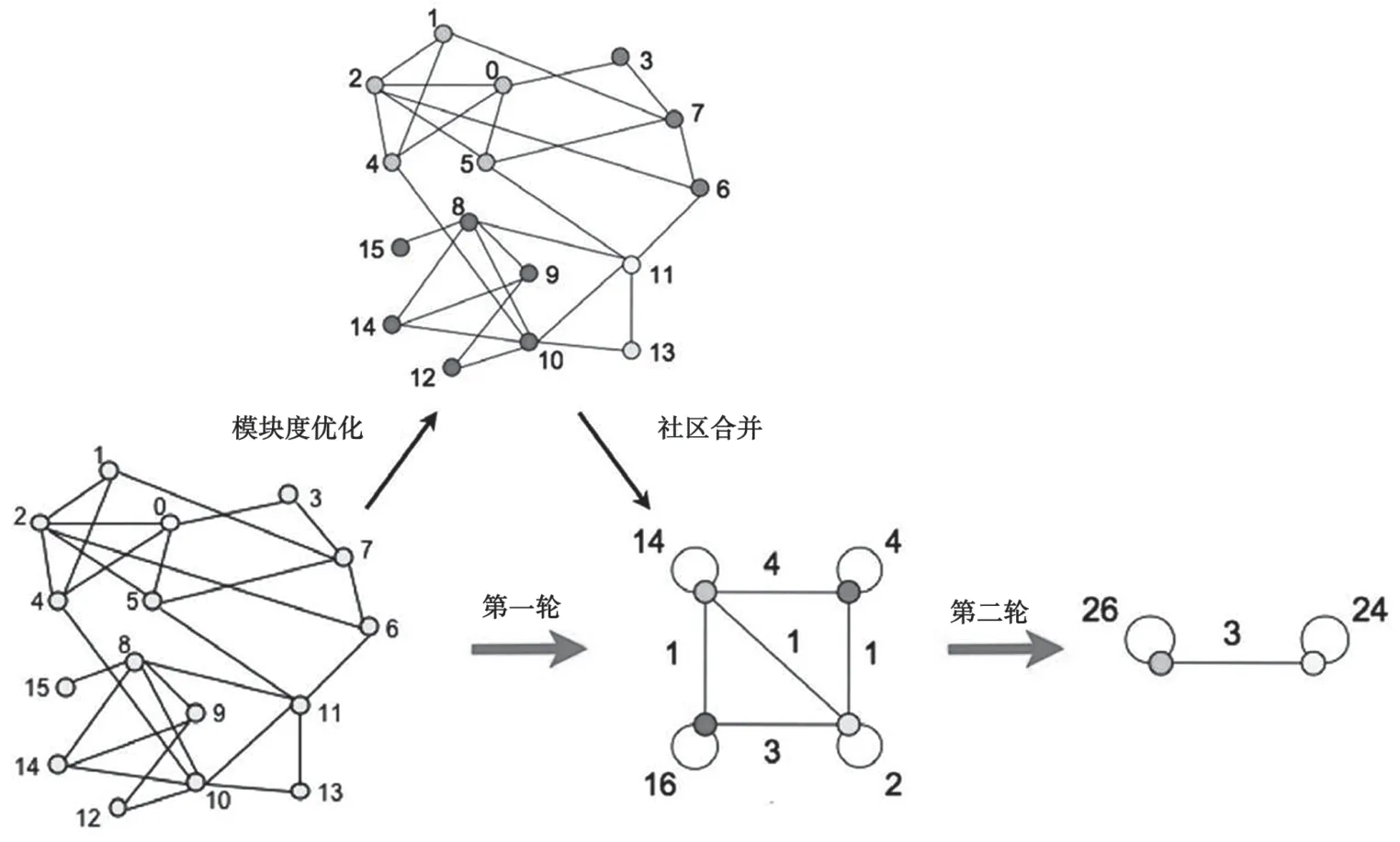
图2 Louvain 算法步骤
3.2 污点传播算法
Malrank 算法是一种基于有向图的半监督静态污点传播算法[3],根据节点与知识图中其他实体的关联,通过对初始边权重和初始恶意值的不断迭代来推断节点的真实恶意值。
根据Malrank 算法,假设节点x的恶意值为S(x),则S(x)第i+1 次的迭代可由式(7)计算得出:
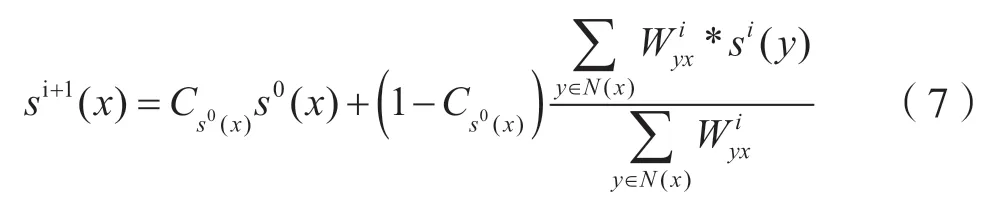
式中,S0(x) ∈[0,1] 表示节点x的初始恶意度。一般情况下,如果已知x为恶意节点,则令S0(x)=1,否则S0(x)=0.5。∈[0,1]表示S0(x)的初始可信度,N(x)表示节点x的邻居节点构成的集合,Wxy代表节点x对节点y的影响权重。
在得到迭代通式后,Malrank 算法需要通过迭代完成相关权重和节点恶意值的重新计算,得到潜在的恶意节点。权重迭代的公式为[14]:
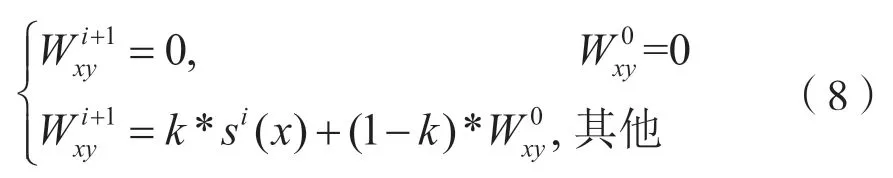
式中,k是限制初始相关权重对迭代时权重影响的因子。
4 实 验
4.1 实验数据
为了验证关联知识图结合攻击检测的效果,本研究在真实校园网环境中搭建了攻击环境,并模拟常见攻击的同时混杂正常流量,得到了约1 GB 真实流量。
本研究搭建攻击场景具体如图3 所示。
(1)Web 攻击。如攻击场景1,攻击方主机向受害主机发动SQL 注入攻击。
(2)Brute SSH+僵尸网络攻击+DDoS 攻击。如攻击场景2 和攻击场景3,攻击方(C&C 服务器)首先通过暴力破解SSH 的手段登录到受害主机内部,其次通过横向移动入侵内部别的虚拟机,最后控制这几台受控制的虚拟机向别的外网IP 发动DDoS 攻击。
4.2 实验结果
得到日志后,通过聚类算法发现构建的关联知识图涉及3 个攻击场景部分的节点分成了3 个子图,如图3 所示。以场景2 为例,在半监督的场景下,令bot 程序分发服务器和攻击笔记本为已知初始恶意节点,通过Malrank 算法得到的包含攻击场景2的子图中可以找到潜在的恶意僵尸肉鸡节点、恶意文件节点和受到DDoS 攻击的恶意节点。整个子图节点的恶意值分布如表2 所示。
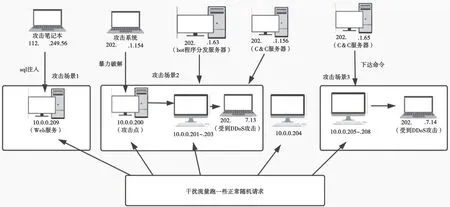
图3 攻击场景架构

表2 攻击场景2 节点恶意性分布
如表3 所示,除了检测效果优秀,基于Saprk的计算引擎和社区算法的缩小了范围,大大加快了整个检测过程的速度。

表3 检测速度对比
5 结语
本文主要研究了基于关联知识图的网络攻击检测方法,探讨并借鉴了国内外研究中常用的图技术检测方法。首先考虑到流量内各个实体的相关性,构建合适的关联知识图;其次,通过社区算法发现包含已知恶意节点的社区,缩小后续处理节点范围;最后,探讨并改进国外先进Malrank 污点传播技术,完成攻击检测。经过在校园网环境下的实验证明,该研究在做到快速处理的同时,检测到了隐藏的肉鸡主机和受害节点,并完成了攻击路径的可视化。
半监督的关联知识图结合污点传播算法具有很好的检测效果,也能辅助后续进一步的攻击分析,但是还需要在真实环境中进一步验证和改善。此外,基于构建的关联恶意子图的特征进行攻击的分类也是值得未来继续研究的一个方向。
