一种面向非受控场景的视频船舶水尺识别方法
2020-12-23岳益锋夏亮明王群英程永林郭东岩
岳益锋,夏亮明,王群英,张 方,程永林,郭东岩
(1.华电电力科学研究院有限公司新技术研发中心,浙江 杭州310030;2.浙江工业大学计算机科学与技术学院,浙江 杭州310023;3.福建华电可门发电有限公司,福建 福州350512)
船舶运输是远洋运输中最常见的方式之一,其最大的优点是载货量大,运输成本低,在每次运送货物之前都需要计算货物重量,目前都是利用船舶水尺计重方式计算货物重量,其中最关键的一步就是精确读出船舶水尺的吃水值.1 cm读数误差会造成数吨的货物重量计算差异.因此提高刻度读数的精度至关重要.
目前水尺刻度尺读取方法主要有人工观测法、超声波测量法,压力传感器测量法,以及基于图像处理检测法等.人工观测法需要观测船舶6个面的水尺,耗时耗力,而且夹杂着观测人员的个人因素,误差时大时小;超声波测量法是通过测量船舶甲板到水面的距离来计算船舶吃水深度,但超声波传播速度易受空气密度等外界因素的影响,精度不稳定;压力传感器测量法需要在船舶6个面的水尺上装有压力传感器,此方法误差比较小,但是传感器常年浸泡在有腐蚀性的海水中,使用寿命不长,后期维护成本高;基于图像处理检测法多年前已被提出,沈益骏等[1]提出的一种基于图像处理的船舶水尺标志识别方法和罗婧等[2]提出的一种视频图像船舶吃水线自动检测方法,是采用模板近似匹配算法识别水尺刻度字符;郭秀艳[3]提出的船舶水尺吃水值检测方法和吴海[4]设计的基于机器视觉的船舶吃水线检测系统,是采用霍夫线检测算法检测水位线;Takahiro T等提出了利用Canny算子[5]检测水位线的算法.这些传统方法都是先将一整张图像进行灰度化,二值化处理,再去识别字符,检测水位线,然而一张图像可能包含多种色彩,二值化效果不佳;船体上也会出现水尺以外的其他标志、水际线等,容易出现识别和检测错误.误差较大.以上方法存在各方面的不足,使用场景受限.
面对以上约束,本文提出了面向非受控场景下的船舶水尺智能识别方法,采用基于EAST模型的文本检测算法[6]对水尺刻度字符进行识别,图像语义分割算法[7]实现分割水位线,最小二乘法曲线拟合算法准确的预估出船舶吃水线的值.以往的图像预处理都是对整张图像进行操作,本文提出的新方法,是将水尺刻度字符从图像中单独抠取出,逐一预处理.与其他水尺刻度值读取方法相比,提出的算法是目前精度最高的,且鲁棒性强,综合成本低,操作过程简单.
1 方法实现原理与步骤
本方法实现步骤分为四部分:1)准备图像数据源;2)水尺刻度字符检测与识别;3)水位线分割;4)最小二乘法预估吃水值.其中图像数据源准备包括数据采集和图像增强;预估吃水值包括图像刻度字符抠取,逐个字符二值化,滤波,边缘检测,最后采用最小二乘法曲线拟合算法预估水位线吃水值.实现流程如图1.
1.1 准备数据源
1.1.1 数据采集

图1方法实现流程Fig.1 Implementation flowchart
本方法使用的文本检测算法和水位线分割算法都是基于机器视觉中的卷积神经网络模型,训练神经网络需要大量图像数据.通过手机,无人机等设备拍摄录制了不同船体,不同环境下的水尺图像及视频,如图2.图像的质量在一定程度上会影响到最终的计算精度,因此采集图像时尽量让相机靠近船体水尺,避免强烈抖动.

图2图像数据采集Fig.2 Image acquisition
1.1.2 数据集制作
1)数据标注.将拍摄的水尺视频逐帧拆成图像,对每一张图片通过图像标注工具labelme对图像进行标注,标注任务包括两部分,标注水尺刻度字符和标注水和船体.
2)数据增强.为了让使用的神经网络模型具有更强的鲁棒性和泛化能力,将原数据图像进行数据增强,方法包括图像缩小,图像放大,图像对比度调节,图像旋转四种方式,效果如图3.通过这一方式变向扩充了数据集,提高了数据集的表现能力.
1.2 水尺刻度字符检测与识别

图3数据增强Fig.3 Data augmentation
传统采用的基于图像处理的水尺刻度字符识别方法,都是先将一张水尺图像灰度化,二值化,再通过字符模板匹配识别字符[1-2],然而水尺图像中包含的色彩像素不止一两种,有不同的刻度字符颜色,船体颜色,水的颜色等,甚至多达五六种,此类图像在进行二值化时,效果不佳,同时长期浸泡或者海水腐蚀性会导致字符褪色、字体不全,再进行模板匹配时就匹配错误,误差较大.针对这些问题,本方法使用的是基于EAST模型的文本检测算法[6],能够快速的检测多个方向的文本字符.EAST模型是一个全卷积神经网络,其网络结构如图4.

图4 EAST模型网络结构Fig.4 Structure diagram of the EAST model
从网络结构图中可以看出该网络主要分为特征提取,特征融合,结果输出三大模块.特征提取模块基于VGG16骨架模型,提取4种不同尺度的特征,这对于不同尺度的图像,不同大小的字符识别具有鲁棒性.
再将不同尺度的特征上采样、融合,最后让网络根据相应损失函数对图像特征进行评分,采用非极大抑制(NMS)算法筛选最优特征,输出识别图像.
只需将标注好的数据集送进网络训,再用训练模型识别水尺图像.得到结果输出如图5所示.该模型不仅识别了图像中每个刻度字符的值,而且将字符框住并记录了每个矩形框4个点的像素坐标.

图5刻度字符识别结果Fig.5 Output of the mark identification
1.3 水位线的语义分割
船舶水位线的检测,传统都是采用霍夫线检测[3-4],边缘检测[5]等方法检测水位线与船体的边缘,再寻找色彩像素变化跨度较大的一条长线.但实际情况复杂得多,船体因长期浸泡会出现水际线;一些船体有多种颜色,色彩像素跨度多变,致使水位线检测不准确.本方法所采用的语义分割算法是基于ResNet-GCN改进的一种神经网络[7],网络结构如图6所示.
网络结构分为两大部分,全局卷积网络(GCN)和边缘细化网络(BR).上图中(B)部分可以看出GCN采用K×1和1×K的卷积核,其中K可以取9、11或13,相比传统小尺寸的卷积核,增大网络感受野,适用于细长的目标,同时K×1+1×K=2K远远小于K×K,参数少,计算量大大减小.(C)中BR采用侧边残差连接对边缘细化.整个网络提取4个不同尺度特征经过GCN网络,BR网络,再融合特征进行反卷积操作.
为了进一步提高分割算法的精度,将图像中包含水位线、水尺关键信息的部分图像裁剪出来,效果如图7所示.在通过之前的刻度字符检测识别算法获取到每个字符矩形框的坐标,取最下方字符(即最接近水位线)矩形框的一个坐标,作为裁剪图像中心点,在原图上裁剪出一定高度和宽度的图像,并做相应的图像放大.
将裁剪后的图像制作成数据集送进网络训练,再用训练模型对图像进行分割,只需分割两类——船体和水,再利用Sobel算子提取出水和船的分界线,并记录水位线的每个像素点坐标.处理结果如图8所示,中间图为二类分割,右图为水位线提取.

图6语义分割网络模型Fig.6 Structure diagram of ResNet-GCN and the block GCN,BR

图7图像裁剪Fig.7 Image cropping
图8水位线分割与提取Fig.8 Waterline segmentation and extract
1.4 最小二乘法预估吃水值
最小二乘法曲线拟合算法需要多个点坐标,需要得到图像中每个刻度字符的像素位置坐标,算法步骤包括:1)抠取刻度字符;2)图像二值化、高斯滤波、边缘检测;3)预估吃水值.
1)抠取刻度字符.一张图像包括的色彩有多种,有的船体还含有刻度字以外的其他标志,如果直接对一整张大图像二值化处理,效果不理想,这也是传统方法误差较大的原因之一.因此本方法将每个刻度字符抠取出,逐一处理.在之前的刻度字符检测与识别结果中,可以得到图像中每个字符矩形框的像素坐标,根据坐标截取每个框即可.效果如下图9所示.

图9刻度字符抠取Fig.9 Extracting the mark
这样复杂问题就得到简化,每个小图像中出现的颜色通常不会超过三个,很大程度上减小后续处理的误差.
2)滤波、二值化、边缘检测.对每个刻度字符小图像进行高斯滤波、二值化处理和边缘检测.高斯滤波对于抑制服从正态分布的噪声非常有效,二值化过程采用的是经典的最大累间方差法(即Otsu法),Otsu法是依据图像所有灰度级统计特性计算最优旳适应阈值,对于色彩不多的图像效果非常好.边缘检测采用经典的Canny算子.处理结果如图10所示.然后记录每个字符轮廓上边界和下边界的像素位置坐标.

图10图像处理Fig.10 Image Processing
3)最小二乘法曲线拟合算法预估吃水值.通过上面的处理,获取到每个字符在抠取的小图像中的像素位置坐标,又由刻度字符检测与识别算法记录的矩形框坐标,可以计算出每个字符在整张大图中的像素坐标值,假设为(x,y),只需取其纵坐标y(在图像中的行数)计算.通过图11解释该算法.图中假设刻度字22M下边缘在整张图中的像素位置为y1,即它在图像中的y1行,对应的读数为22.0 m,得到一个坐标点(y1,22.0),为方便计算将水尺读数扩大10倍,则坐标为(y1,220).同理得到坐标(y2,221),(y3,222),(y4,223),(y5,224)等.多个点通过最小二乘法曲线拟合,得到一个曲线方程y=ax2+bx+c.在水位线的语义分割中记录了水位线的像素位置值,将其纵坐标(即行数)代入方程,最终计算得船舶吃水值.在计算字符像素位置值的过程中可能会出现一两个像素点坐标误差,但这对于多个坐标点的拟合算法几乎没有什么影响.
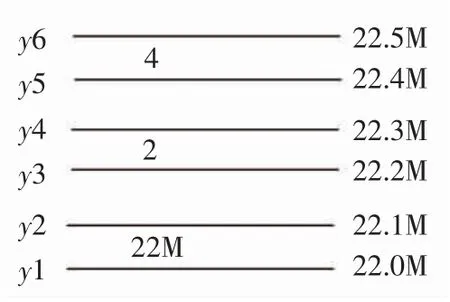
图11刻度坐标Fig.11 Coordinate pairs
2 实验结果展示
拍摄上百张图像,十几个短视频,将视频拆成单帧,一共获得5 000多张包含水尺信息的图像,用labelme工具标注.并且通过4种图像增强技术,将数据集扩充到30 000张图像.以6∶2∶2的比例将数据集随机划分为训练集、验证集、测试集三个部分.将训练集、验证集总共24 000张图像分别放入刻度字符识别网络和语义分割网络进行训练.训练时使用Adam优化器,设置300次Epoch,learning rate为0.01,并在每次Epoch结束后对用测试样本对模型进行评估,每5次Epoch储存一次当前训练的模型.在300次迭代训练结束后,根据在测试样本上评估的结果,从储存的模型中选取最合适的模型作为后续测试的模型.
利用已有模型分别实现水尺刻度字符的识别和水位线分割,再通过吃水值计算算法计算出最终的吃水值.部分实验结果如图12所示.

图12实验结果图(每张图左上角数值为相应吃水值)((a),(b),(c),(d),(e),(f)分别为17.589,21.101,21.727,21.298,18.191,22.077)Fig.12 Final results of the proposed method(The top left corner of each image shows the final draft value)
图12中,每一张图左上角为该图最终吃水值.(a)为17.589 m,(b)为21.101 m,(c)为21.727 m,(d)为21.298 m,(e)为18.191 m,(f)为22.077 m.该方法抛弃了最下面一个刻度字符的像素位置坐标,这是因为最下面的字符在被水面掩盖过多时,容易识别出错.
单帧图像的吃水值计算,一般适用于船舶停靠、水面平静的情况,但实际情况往往有风浪,单张图像只能表示某一时刻的船舶吃水值,不能作为最终计算货物重量的依据,需要录制有多个波峰的视频,对视频进行吃水值计算.本方法先将视频拆成单帧,然后计算每一帧图像的吃水值,取几个波峰之间所有帧吃水值的平均.计算公式为

式中,wi表示第i帧图像的吃水值;Result为n张图像的平均吃水值.用此结果作为视频吃水值.
3 测试数据与分析
为验证这套方法的准确度,进行一组实验,拍摄不同风浪情况下不同颜色船体的短视频,逐一完成吃水值计算,并与人工读数进行对比.对比结果见表1.

表1吃水值计算结果对比Tab.1 Comparison of experimental results
表1中,E表示本方法计算的吃水值,C表示人工读数,差异率A计算公式为

从表中可以看出,本方法计算水尺吃水值的差异率浮动在±0.5%范围内,符合水尺计重的准确度要求,当船载货物越多,水尺读数越大时,计算差异率越小.实验数据表明本文提出的吃水值计算方法能够有效解决准确度上的问题.
4 结论
得益于机器视觉领域深度神经网络模型在处理
数字识别和二分类分割问题上发展得已比较成熟,
以及结合本文提出的拟合计算吃水值算法,能达到
相当高的准确度.这套方法部署简单,实施高效,输入只需是一张图像或者一段视频,相比传统方法,大大减少了物质成本、人力成本和时间成本.
