多策略驱动的动态手势识别算法
2020-12-22项俊王超沙洁麻建
项俊,王超,沙洁,麻建
(中南民族大学 电子信息工程学院&智能无线通信湖北省重点实验室,武汉 430074)
动态手势识别(Dynamic gesture recognition)旨在从连续的图像序列中提取鲁棒的时空域特征,进而识别出序列所携带手势的类别.动态手势识别在手语识别、智能驾驶、智能家居等领域有着广阔的应用前景,难点是处理背景干扰、光照变化以及类内差异性大等问题[1].当前动态手势识别主流方法均采用了深度学习技术,其核心是利用神经网络强大的非线性表达学习能力,从输入手势序列中挖掘最具判别性的动态手势特征以提高手势识别率.
多模输入是增强特征鲁棒性的有效手段.不同的模态携带不同的信息,如图1所示, RGB图片包含丰富的颜色和纹理信息,深度图片包含物体的轮廓和深度信息,光流分别描述了像素在x和y方向的运动信息.这些数据在信息描述上具有互补性,融合后信息能够有效弥补单一模态数据的局限性,显著提高手势的辨识度.例如文献[2, 3]利用RGB 序列和Depth 序列共同描述手部的运动过程,文献[4, 5]基于RGB 序列、Depth 序列和Flow 序列的融合特征进行动态手势识别.

图1 各模态手势图片示例Fig.1 Examples of multi-modal hand images
然而上述多模态输入方法忽略了手势类别在局部与全局信息上的差异性.一般而言,全局信息体现完整的手势序列信息,包含背景变化、手部运动信息以及非手部人体部件的运动过程;局部信息则仅体现手部的运动过程.不同手势类别对全局或局部信息依赖程度存在差异性,如需要借助人体姿态大幅变化的“挥舞”动作,更适合采用全局信息;而对“勾食指”等微小运动的手势,局部信息更具有辨别性,因为食指小区域的位移很可能被人体大区域干扰移动掩盖.显然,利用全局与局部信息的互补性,有助于提高识别算法的鲁棒性.
另一方面,融合策略是基于多模态输入算法中的一个重要问题,常见的融合方式有数据级融合[6]、特征级融合[4, 5, 7]和决策级融合[2, 8].数据级融合保留了完整的输入数据信息,但存在大量冗余信息,算法复杂度高.特征级融合克服了数据级融合的不足,但其融合后特征易丢失多模态之间的关联信息.决策级融合先通过各模态数据独立预测手势的类别分布,再采用取均值方式获得最终的
手势预测结果;决策级融合有效克服了前面两种方式的缺点,但均值操作决策忽视了在识别中起关键性作用的特征信息.为此文献[9]提出自适应融合策略,受文献[9]启发,本文将决策级融合思想统一嵌入到多模态特征建模网络,以网络端到端的学习方式,自适应学习每类手势在各模态数据上的决策权重,提高决策级融合的灵活性.
针对上述问题,本文在深度学习框架下提出于一种基于多策略驱动的动态手势识别算法:采用多线索输入策略,在多模输入基础上融合各模态数据的局部信息与全局信息以提高动态手势的描述能力;构建基于2DCNNs与3DCNNs级联框架(2D/3D CNNs)的动态手势的特征提取网络;设计自适应融合模块学习每类手势在各模态数据上的决策权重,并嵌入到特征学习网络中,更好的利用各自信息的优势.
1 方法
本文多策略驱动动态手势识别算法整体框架如图2所示,主要由3部分组成:多模态多线索输入、2D/3D CNNs深度特征提取模块、自适应融合网络.多模态多线索输入策略从多方面提供对动态手势的描述信息;2D/3D CNNs深度特征提取模块首先利用2DCNNs提取图片的低级特征表达、再利用3DCNNs提取对对应线索的空间时序表达;自适应融合网络最大限度地利用各线索提供的空间时序对手势做出最终的类别预测.
1.1 多模态多线索输入
多模多线索输入策略不仅利用了各模态数据之间的互补性,还利用了每个模态数据的全局信息与局部信息之间的互补性,通过丰富输入网络的信息量,增强算法的判别能力.如图2所示,本文分别使用RGB序列和Depth序列描述手势序列.RGB序列、Depth序列由数据集直接提供,原始的RGB序列和Depth序列分别描述了人体发生手势时的全局信息,包括对人体与背景变化的整体描述、对手部区域的粗略描述.在此基础上,本文利用手部检测器从原始序列中逐帧检测出手部区域并组成一个新的序列,该序列详细描述了手部运动的细节信息,以增强对环境变化的鲁棒性,其中手部检测器建模参考文献[10].将每一个输入到2D/3D CNNs网络的序列称为一个线索,因此本文使用RGB序列和Depth序列的全局信息与局部信息构成4个线索来描述一个动态手势,每个线索都提供了手势类别的判别依据.

图2 算法整体框架示意图Fig.2 The overview of the proposed method
1.2 2D/3D CNNs深度特征提取
性能优越的特征提取器是手势识别算法的核心,其任务是从输入序列中挖掘出有利于识别的空间和时域信息.3D卷积(3DCNNs)模型能有效建模时序序列中的时空域特性,被广泛应用于人体行为识别领域[11].然而时序图像中存在着大量干扰信息,3D卷积在兼顾时序信息的同时无法实现对2维信息的优化学习.为此本文提出基于2DCNNs、3DCNNs级联的深度特征提取器,首先利用2DCNNs提取每帧图片中最具代表性的外观底层信息,有效去除冗余;随后引入3DCNNs进一步建模手势外观的时空域特性.2D/3D CNNs深度特征提取模块充分利用二维与三维表达学习的优缺点,能够自动地从视频帧中学习高效的特征表达,而且对姿势、光照和复杂背景具有不变性,有效提高特征表达的鲁棒性.
图3给出了2DCNNs和3DCNNs级联的特征提取器框架.输入手势序列V,为了去除连续视频帧中的信息冗余、首先采用稀疏采样策略[12]对序列进行预处理:将输入视频均匀分为N等份V=[v1,v2,…,vN]再从每份视频段vi中随机采样一帧图片si(i=1…N)作为2DCNNs的输入,N张采样帧之间不相关.这种随机选取数张图片来代替整个序列对手势进行描述,不仅可以大幅降低计算开销,并且由于随机抽样增加了选取帧的未知性从而增强了算法的鲁棒能力[12].

2DCNN由若干层卷积层、池化层、激活层以及全连接层组成,本文采用Inception v2[13]作为二维卷积模块,具有表达能力强,参数量少的优势.3DCNNs由若干层3维卷积层、3维池化层、激活函数和全连接层组成,借助3维卷积核的三维特性可以从序列中高效提取空间时序特征.一般而言,增加网络深度可以增强网络的特征表达能力,但过度增加深度易导致网络退化问题;而ResC3D[14]可以在增加网络深度的时候保证算法的性能至少不降低.本文基于ResC3D搭建3DCNN.以上两个网络具体结构可分别参见文献[13, 14].
1.3 自适应融合决策
对于多输入动态手势识别算法,目前很多研究者采用决策级均值融合方法,其实质是为各模态数据的预测结果分配相同的权重.这种融合方法对一些在识别中起关键作用的输入线索没有予以充分重视,进而影响手势识别的效果.本文提出一种自适应融合模块,通过网络学习为每一个线索分配不同的权重.
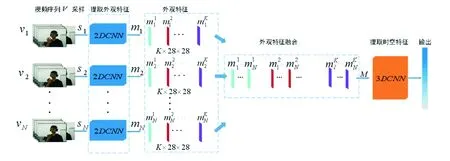
图3 特征提取框架Fig.3 The diagram of the proposed deep feature extractor

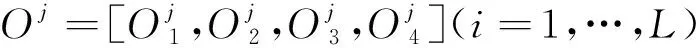
(1)

(2)
第三,O与W相乘,O×W上的元素OjWi(i,j=1,…,L)表示第i类手势对应的权重值对4个线索在第k类手势上的预测值进行加权求和的结果.当j=i时,OjWi才是4个线索通过自适应融合策略对手势类别j的共同作用得分.因为O×W的尺寸为L×L,通过diag函数取其主对角线上的元素作为最终的融合预测结果,如公式(4)所示.最后加入一个softmax函数对预测结果进行归一化处理.
(3)
(4)
2 实验结果与分析
采用两个公开动态手势数据集SKIG[15]和IsoGD[16]来验证所提算法的性能.首先在SKIG数据集上研究采样帧数与算法性能的关系,并验证2D/3D网络框架在时空序特征提取上的优越性;然后在IsoGD数据集上依次研究多线索输入策略、自适应融合策略对动态手势识别的影响, 最后在IsoGD数据集上均给出了与其它主流算法的对比实验结果.
2.1 数据集介绍
本文研究涉及两个公开数据集,分别是SKIG和IsoGD数据集,详细介绍如下:
SKIG:SKIG一共包含2160个手势序列,其中有1080个RGB序列和1080个深度序列,它们分别被分成6份,以subject1、subject2、subject3、subject4、subject5和subject6的形式存放.该数据集对6个人通过Kinect传感器在3种背景和2种照明条件下收集得来,它一共有10个类别,如图4所示,分别是圆形(顺时针)、三角形(逆时针)、上下、左右、波形、“Z”、交叉、大方、转向和拍,为增加样本的多样性,每种类别的手势都通过三种姿势实现:握拳、伸出食指、平铺手掌. 在训练时,由于数据集样本量小,所以一般采3-交叉验证的方式来评价模型在该数据集上的性能.即第一轮训练时,subject1+subject2+subject3+subject4做训练集,subject5+subject6做验证集;第二轮训练时,subject3+subject4+subject5+subject6做训练集时,subject1+subject2做验证集;第三轮训练时,subject4+subject5 +subject1+ subject2做训练集时,subject3+subject4做验证集.最后取三次验证集上精确度的平均值为最终的评价指标.

图4 SKIG数据集Fig.4 The dataset of SKIG
IsoGD:IsoGD一共包含95866个手势序列,其中RGB序列7933个、深度序列47933个.RGB序列和深度序列是相互对应的,是对同一个手势在不同角度的描述.该数据集由21个人执行249种手势获得,每个视频里仅含有一个手势动作.为方便使用,数据库已被划分为三个子集:训练集、验证集、测试集.具体的划分情况如表1所示.

表1 IsoGD数据集Tab.1 The dataset of IsoGD
2.2 实验平台和参数
实验环境:CPU为2枚 Intel Xeon (R) @2.20GHz,内存为128GB,在ubuntu16.04操作系统下,采用pytorch编程实现本文算法.具体的参数设置如下:batch_size大小取10,初始学习率取0.01,每迭代20次,学习率下降到10%.
2.3 SKIG数据集上验证实验
由于SKIG数据集较小,我们采用3-交叉熵验证方法[15]来评估算法的性能,包括研究采样帧数对算法的影响;验证2D/3D CNNs特征提取器中各部件的有效性;与当前主流算法的对比实验.
(1)采样帧数对N算法的影响.分别在SKIG的RGB和Depth序列上做5组实验,保持其他训练条件一致,每组实验设置的采样帧数为4、8、16、32、64.图4中虚线展示了采样帧数N与时效性的关系:随着N的成倍增加,识别一个样本所需的平均时间大幅度增加,例如N=32所用时间是N=16的3至4倍.图5中实线表明算法的识别性能与采样帧数并非呈正相关关系,当N取4至32时,算法识别精度随着N的增加而提高;当采样帧数取32时,手势识别的精确度在RGB和Depth模态上分别达到最高值;但当N时,精确度在RGB和Depth模态上分别呈现不变或下降0.54%.这是因为某些手势类别太过相似,采样帧数过多将产生冗余,模糊了关键帧的识别信息.综上所述,采样帧数的增加导致算法时间复杂度提高,但却不一定对算法的性能产生正面影响.对于SKIG数据集,当只需考虑算法精度时,采样帧数N取32;若还需兼顾算法的时效性,则N取16.
(2)2D/3D CNNs各部件的有效性.以下通过与单独采用2D CNNs或3D CNNs进行对比,验证2D/3D CNNs的有效性,其中涉及多模态数据输入的,采用平均决策得分的方式获得最终类别判断,实验结果见表2.首先,单独以RGB(或Depth)序列为输入时,2D/3D CNNs的精确度明显高于2D CNNs,这是因为来自2D CNNs的特征中缺少相邻帧之间的时序信息.在2D CNNs的输入中加入光流Flow,并通过均值操作与RGB或Depth序列提供的信息融合在一起,2D CNNs的精度略高于2D/3D CNNs单独处理RGB(或Depth)的结果;但加入光流后2D CNNs算法运行时间是2D/3D CNNs单独处理RGB(或Depth)的5倍,且未考虑计算光流图片的时间开销. 以上结果证明了2D/3D CNNs提取出空间特征与时序特征的有效性和时效性.其次,与3D CNNs比较,2D/3D CNNs由于加入了2D CNNs导致处理RGB或Depth的时间增加50%,但同时也带来了识别精度的提高;这也说明2D CNNs的加入有助于提取图像鲁棒性特征的作用.

图5 采样帧数对算法识别精度、时效性的影响(SKIG数据集)Fig.5 The impact of the number of frames sampled on recognition accuracy and time efficiency
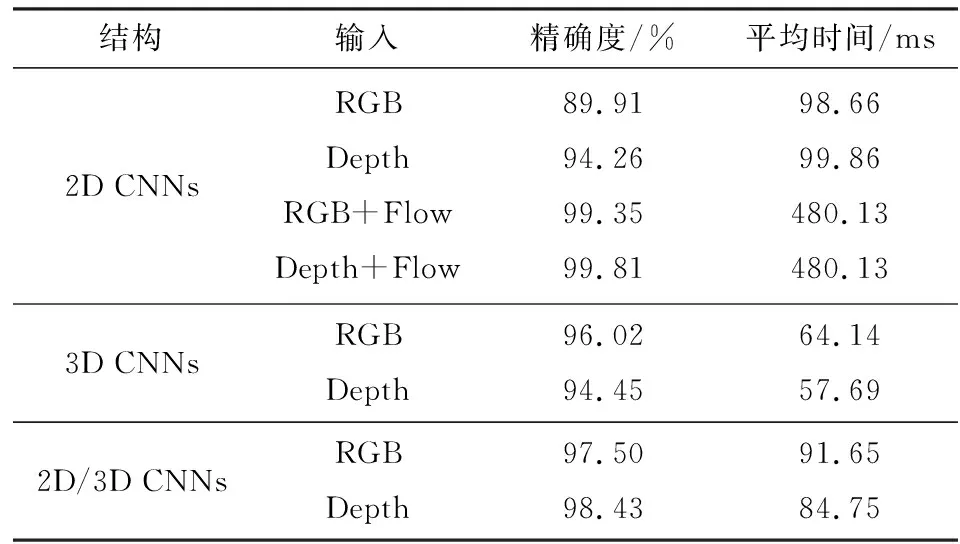
表2 不同网络结构的对比结果Tab.2 Comparison results among differentnetwork structures
(3)与其他算法的对比实验.表3给出了本文2D/3D CNNs结构与当前一些主流算法在SKIG上的对比结果.由于有些算法中加入了Flow序列为输入,为统一对比条件,我们也列出了在本文算法中输入Flow序列的结果,涉及到多模输入时,均采用平均决策融合方式.R3DCNN[3]首先使用C3D卷积神经网络学习空间时序特征,然后将矢量化的特征送入到RNN中;MRNN[17]先使用2D卷积神经网络学习视频帧的空间特征,然后将空间特征送入到MRNN中进行手势识别;M3D+LSTM[2]首先使用3D卷积神经网络学习视频片段的空间时序特征,然后将矢量化的特征送入到LSTM中学习整个视频的空间时序特征,最后经过空间金字塔池化SSP完成最终的手势识别.从表3可以看出,本文算法除了在输入仅为Depth序列时识别率略微低于M3D+LSTM方法(98.43%对98.7%),在其它各种输入组合下识别率均有优势.

表3 与当前主流算法在SKIG上的结果对比Tab.3 The results of comparison with several state of the art approaches onSKIG dataset
2.4 IsoGD数据集上验证实验
为了兼顾精确度和时效性,采样帧数取为16.本小节有三个任务:验证多线索输入的有效性;验证自适应融合策略的有效性;验证本文算法的性能.
(1)多线索输入的有效性.图5展示了不同输入模式下对应的识别结果.将通过检测器分别从RGB序列和Depth序列中获得的两个新序列命名为“RGB_hand”和 “Depth_hand”,这两个序列来自文献[10]提供的数据集.将多模输入表示成“Multimode”,多线索输入表示成“Multiclue”,多模输入和多线索输入中均采用基于分数级的平均融合策略.由图6可知,多模输入的效果优于任何单输入的效果,证明了多模输入的有效性;多线索输入的精确度高于多模输入将近4%,这证实了采用全局信息与局部信息融合策略的正确性,多线索输入将各模态数据及其对应的全局与局部信息融合在一起,显著提升了算法识别性能.

图6 采用不同输入时,IsoGD测试集的精确度Fig.6 Comparison results of different input strategies
(2)自适应融合策略的有效性.将自适应融合策略与均值融合进行对比,图7给出了两种融合方案分别基于多模输入和多线索输入下的对比结果.可以看出,自适应融合的性能优于均值融合,这是因为均值操作使得每类手势对各支路的依赖程度相等,容易模糊掉某些关键支路上提供的信息;而自适应融合策略通过权重矩阵,为每类手势学习出在各条支路上的依赖度.

图7 均值融合与自适应融合的性能对比结果Fig.7 Comparison results between average fusion and adaptive fusion
(3)与其他主流算法的对比.表4给出了本文算法在IsoGD数据集上与其它主流算法的比较.可以看出,本文算法的精确度高于AUS[5]、XDETVP[4]和2SCVN+3DSSN[20],低于FOANet[9].AUS基于残差模块与C3D的优势使用ResC3D网络提取输入特征,并采用基于规范相关分析的融合方案融合多模输入对应的多模特征;与AUS相比,本文算法识别精度改善了8.61%,证明了从视频的2D外观特征序列中提取时序信息的优越性.FOANet算法与本文算法的思路一致,也是基于数据驱动、全局运动与局部运动相融合的动态手势识别算法,采用了文献[10]提供的手部检测结果;但该算法针对检测出来的手部,用骨架评估器分辨出是左手还是右手,然后组成左右手序列分别作为网络的输入,从而避免当涉及运动或双手的手势时,边界框的大小接近整个图像的尺寸.由于采用了对左右手分别进行检测,FOANet算法在精度上比本文算法高5.75%.

表4 与当前主流算法在IsoGD数据集上的对比结果Tab.4 The results of comparison with several state of the art approaches on IsoGD dataset
3 结语
本文在深度学习框架下提出了一种基于多线索驱动的动态手势识别算法.首先利用检测器从RGB序列与Depth序列中生成仅含有手部区域的序列,将生成的新序列与RGB序列、Depth序列一起作为网络输入,先通过2D卷积神经网络提取视频帧外观特征、再经过3D卷积神经网络提取视频帧序列的时序信息,最后采用自适应融合网络将各序列的预测概率融合在一起作为最终的手势识别结果.实验结果验证了多线索输入、2D/3D CNNs级联特征提取框架、自适应融合策略的有效性,同时在SKIG和IsoGD公开数据集上所提出算法取得了与当前主流算法相当或更好的手势识别效果.