广西杉木人工林多形地位指数模型构建1)
2020-12-22张艺超赵天忠苏晓慧
张艺超 赵天忠 苏晓慧
(北京林业大学,北京,100083)
森林的立地质量影响着森林生产经营的多个方面,而立地质量评价是实现科学造林以及经营森林的关键[1]。立地质量评价有多种方法,地位指数法是以基准年龄下优势木平均高作为衡量立地质量的标准,优势木平均高受林分密度影响较小,而且相对易于获取,因此应用较为广泛。
地位指数模型有单形和多形两种。前者由导向曲线通过一定方法展开得到,所有地位指数下树木生长曲线形状相同;后者不同的地位指数下生长曲线形状不同,即不同地位指数下生长过程不同。多形地位指数模型由Trousdell K B, et al提出[2],被证明更符合树木生长的客观规律。段爱国等[3]采用差分法以6种生长方程为基础,探讨了拟合多形地位指数方程最佳表达式;Dario Martín Benito, et al[4]应用自适应差分进化算法,以Richards模型为基础,建立了黑松的非线性混合模型;高光芹[5]等以神经网络模型构建马尾松多形地位指数模型;施恭明等[6]采用Korf生长方程,通过改进的单纯形法,建立了马尾松多形地位指数模型。
综上所述,虽然国内对多形地位指数模型已有较多研究,但多以现有的生长方程为基础,构建参数模型进行拟合,所得模型都需经过迭代才能求出地位指数,应用上存在不便,且针对广西杉木人工林的多形地位指数模型研究还较少。本文以广西高峰林场为研究区域,分别以Richards方程和随机森林回归算法为基础构建多形地位指数模型,并对两个模型进行对比分析,力求在不同的场景下应用最适宜的模型,为广西杉木人工林立地质量评价提供参考。
1 研究区域概况
广西国有高峰林场是自治区林业局直属国有林场,林场场部位于南宁市兴宁区,属于大明山脉,地理坐标为北纬22°49′~23°15′,东经108°8′~108°53′。林场经营面积8.7万余hm2,森林蓄积量570多万m3,森林覆盖率达87%,是广西规模最大的国有林场。林场地貌多为丘陵与山地,分别占总面积的55.5%与38.7%。林场气候属于亚热带季风气候,年平均气温21 ℃,降水量1 200~1 500 mm[7]。广西高峰林场植被主要以次生人工林为主,主要树种为杉木(Cunninghamialanceolata),巨尾桉(Eucalyptusgrandis×urophylla),马尾松(Pinusmassoniana)等。
2 研究方法
2.1 数据来源
本文研究数据来自广西壮族自治区高峰林场提供的2010年二类调查数据,其中以杉木为优势树种的小班共有342个。本文应用广西高峰林场杉木树种因子与解析木数据建立多形地位指数模型。小班树种因子详细情况如表1所示。
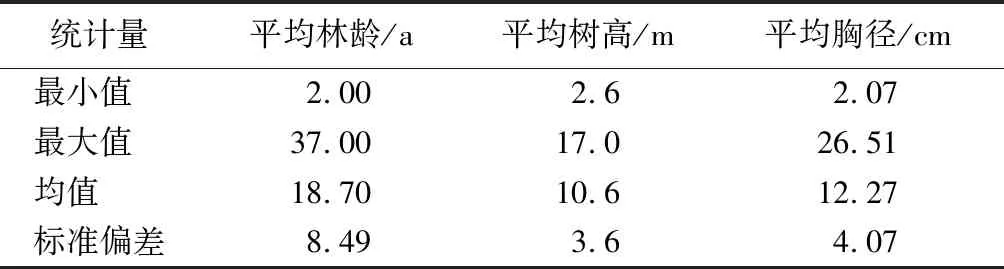
表1 小班树种因子统计
2.2 模型的评价标准
本文分别基于Richards方程与随机森林回归算法进行多形地位指数模型构建,为了便于模型比较,将数据分为模型构建数据集与测试检验数据集,其中测试检验数据集占总数据集的25%。模型的评价选用ERMS,EMA,R23个衡量指标,评价指标公式如式(1)、(2)、(3)所示。
均方根误差(ERMS):
(1)
平均绝对误差(EMA):
(2)
(3)
2.3 应用Richards方程的多形地位指数模型
Richards方程为“S”型曲线方程,其基本形式如下:
H=a(1-e-bT)c。
(4)
式中:H为树高(m),T为林龄(a),a、b、c为待定系数。
Richards方程为“S”型曲线,其拐点是可变的,相较于Logistic等固定拐点的方程更符合树木的生长特性,是目前应用最广泛的树木生长拟合方程之一。许多研究运用Richards方程模拟树木生长,并取得较好的效果[3,8-11],因此本文将以该模型为基础进行模型构建。
传统的同形地位指数模型是由生长方程拟合的导向曲线展开得来的,不同地位指数的生长曲线形状相同,人为忽略了不同立地质量下树木生长曲线不同这一客观规律,因此多形地位指数模型优于同形地位指数模型[12]。树木生长曲线形状随立地质量变化,两者之间满足一定函数关系。立地质量由地位指数(IS)来衡量,不同立地质量曲线形状由RT表示,则有关系函数:
RT=f(IS)。
(5)
本文以Richards方程来模拟树木生长,由式(4)可知,方程有3个未知参数a、b、c,这3个参数决定了方程所代表的地位指数及其生长趋势,结合式(5)可知此3个参数均与IS存在函数关系,设a=f1(IS)、b=f2(IS)、c=f3(IS),可得:
H=f1(IS)(1-e-f2(IS)T)f3(IS)。
(6)
式(6)给出了不同立地质量下树高生长模型的基本公式,找出关系f1,f2,f3即可得到多形地位指数模型。
2.4 应用随机森林回归算法的地位指数模型
由2.3可知,树高(H),年龄(T),地位指数(IS)之间是满足某一函数关系的,而此关系为非线性关系。本小节将应用集成学习方法中的随机森林回归算法来构建此3个变量间的关系模型。
随机森林回归模型:随机森林算法由Breiman于1995年提出[15],该算法对Bagging算法进行了改进,利用Bootstrap方法从原始样本中随机抽取若干数量相等样本,从所有输入特征中选择若干子特征集,对每个样本使用分类与回归树(CART)作为弱学习器进行建模。对于回归算法,会取所有弱学习器结果的均值作为最终结果。
本次试验采用Scikit-learn方法库实现随机森林回归算法。Scikit-learn是一个Python第3方提供的非常强力的机器学习库,它包含了从数据预处理到训练模型的各个方面的算法实现。
模型的构建:2.3中,最终得到形如H=f(IS,T)函数关系式(6),当需要求在一定地位指数下,不同年龄对应的树高时,可直接求得。但是式(6)并不能写成IS=f(H,T)的形式,因此想要直接求得IS必须通过迭代求解。为了便于应用,本文分别以(IS,T)为输入变量,以H为输出变量、以(H,T)为输入变量,以IS为输出变量进行随进森林模型训练。
在Scikit-learn开发包中,采用sklearn. ensemble模块下的Random Forest Regressor类实现随机森林回归算法。Random Forest Regressor类中有两个主要参数:决策树数目(n_estimators)、寻找最佳分割时需要考虑的特征数目(max_features)。决策树数目越大越好,但相应占用的内存与训练和预测的时长将增加,达到一定值后对训练效果提升将持续减弱,本次试验以测试集R2为衡量标准,由1开始依次测试发现决策树数目接近300时,R2不再变动,因此选取决策树数目为300;本次试验训练数据特征维度较低,参数特征数目对结果影响较小,因此采用默认值,即取特征总数的开方。
最后进行模型训练,求出关系H=f(IS,T)与IS=f(H,T)的模型。
3 结果与分析
为了确定各小班地位指数,将小班平均树高与该小班平均年龄下各解析木树高进行差值运算,最终找到差值最小的解析木。以基准年龄为20 a[16],将基准年龄下该解析木树高作为小班的地位指数。重复以上步骤可以得到所有小班地位指数,为了减小误差,如果该小班树高与所有解析木树高差值都大于1 m时,应舍弃该小班不参与建模。
3.1 应用Richards方程的模型拟合结果
将数据中的地位指数按级距1 m进行分组,各组分别利用式(4)进行非线性回归,所用软件为SPSS 25.0,各组所得未知参数值及决定系数如表2所示。

表2 各地位指数组参数拟合结果
利用SPSS软件的曲线估计功能,选取几种常用的基本初等函数来拟合关系f1,f2,f3,进行量化探究,曲线估计结果如表3所示。
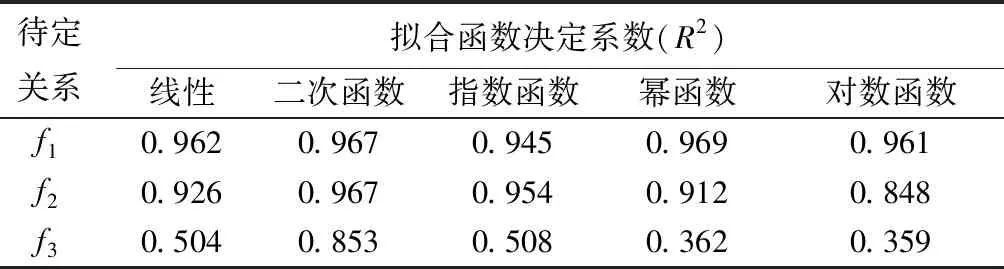
表3 参数拟合函数拟合决定系数
根据表2绘制散点图,并综合表3选取拟合函数。在满足精度的前提下,为了降低模型复杂度,优先选用形式更简单的基本函数。最终选取线性函数拟合f1,指数函数拟合f2,二次函数拟合f3。
将选定的参数拟合函数代入式(6)最终得出模型的最终式为:
(7)
式中:K1、K2、K3、K4、K5、K6、K7为7个待定系数,IS为地位指数,H为树高,T为年龄。
运用SPSS软件,进行公式(7)的拟合,拟合结果为K1=0.498、K2=11.401、K3=0.035、K4=0.071、K5=-0.002、K6=0.007、K7=1.867。由检验数据所求得各项检验指标为:ERMS=0.649,EMA=0.415,R2=0.906。
除上述评价标准外,根据地位指数的定义可知,当T为基准年龄时,H等于IS。由此可得基准年龄下的树高预测值,并可计算与地位指数之间的均方根误差。以2m为级距,地位指数由6~20m的树高预测值分别为:6.662、8.304、10.151、12.145、14.205、16.244、18.176、19.945m。计算得到与地位指数之间的均方根误差为0.298。
令IS=6、8、10、12、14、16、18、20,以年龄T为横轴,以H为纵轴可绘制各地位指数下树高生长曲线,结果如图1所示。
3.2 随机森林回归模型结果
分别以IS或H为输出变量,由验证数据所得评价结果如表4所示。

表4 随机森林回归模型检验结果
同理,由关系H=f(IS,T)可计算基准年龄下各地位指数等级树高预测值,并计算与地位指数之间的均方根误差。以2m为级距,地位指数由6~20m的树高预测值分别为:6.061、7.927、10.327、12.016、14.020、15.746、17.931、19.866m。计算得到与地位指数之间的均方根误差为0.159。
固定IS值,由关系H=f(IS,T)将各年龄下树高求出,以年龄T为横轴,以H为纵轴绘制散点图依次连接,也可得到树高生长曲线。但由于其无确定的表达式,应用上不如Richards方程模型方便。
3.3 两种模型结果对比分析
Richards方程模型最终拟合结果R2=0.906,ERMS=0.649,EMA=0.415;随机森林回归算法以H和IS为输出变量所构建模型R2均大于0.930,ERMS为0.510与0.530,EMA为0.352与0.281。除了传统检验方法,本文根据地位指数的定义,计算了基准年龄下两模型树高预测值的均方根误差来验证结果,最终得到预测误差值分别为0.298与0.159,均在较小范围内,进一步验证模型可行性。
与随机森林回归的这样的非参数模型相比,Richards方程模型具有明确的表达式,当需要预测树木生长趋势,并绘制树木生长曲线时,仅需要将相应地位指数代入公式,便可以得到生长曲线表达式,从而快速绘制平滑的曲线;随机森林回归模型比Richards方程模型有更低的误差值,ERMS降低了21%,EMA降低了15%,且具有更高的R2。该模型的另一个优势在于可以直接求得地位指数而无需通过迭代计算,求解效率更高。
4 结论
本文以广西高峰林场杉木人工林为研究对象,利用二类调查小班数据与解析木数据,分别采用Richards方程与随机森林回归算法构建多形地位指数模型。
结果表明,两种模型均具有可行性,且各有优势。Richards方程模型更加适合树木生长趋势预测,可以方便绘制树木生长曲线;随机森林回归模型优势在于具有更高的准确率与更低的误差值,可直接求得地位指数而无需迭代运算。后续将利用构建的模型,开发立地质量评价系统。根据两个模型的特点,结合不同需求选取不同的模型,以发挥每个模型的优势。
本文所构建的模型仅适用于有林地,后续将利用坡向、坡度、坡位、土壤因子等立地因子替代模型中的地位指数,构建适用于无林地的评价模型。
