基于梯度提升树算法的玉米施肥模型构建
2020-12-21严海军
卓 越,严海军
(中国农业大学 水利与土木工程学院,北京 100083)
1 研究背景
化肥使用对于提高农作物产量具有重要作用。但是长期以来,我国化肥投入结构不合理,肥料利用率低,造成养分比例失调。过度施用化肥不仅增加了生产成本,还导致产量下降,同时对环境和农作物造成严重污染[1-2]。实践证明,精准施肥可以节约肥料、增加粮食产量、均衡土壤养分、减少环境污染[3-4],然而如何确定最佳施肥量是精准施肥的难点。因此,探究作物产量与施肥量等因素之间的关系,合理构建施肥模型、寻找最佳施肥量、实现精准施肥是被关注的研究热点之一。
施肥决策模型主要有目标产量法、营养诊断法和肥料效应函数法[5]。其中肥料效应函数法是通过大量的田间试验获得施肥量与产量的关系,进而确定最优施肥量,为目前广泛应用的一种施肥决策方法[6]。为了模拟施肥量等因素与产量之间的非线性关系,很多学者使用神经网络的方法构建模型。马成林等[7]先采用数据包络分析法对数据进行预处理,再通过BP神经网络建立模型,最终确定了最佳施肥方案。于合龙等[8]通过bagging算法生成多个BP神经网络并通过拉格朗日乘子法进行集成从而建立模型,指出该方法优于常规BP神经网络,并通过模型得到了最佳施肥方案。杨晓辉等[9]分别使用模拟退火算法和遗传算法对BP神经网络进行优化,进一步提高了施肥模型的拟合精度。王福林等[10]在模型输入中加入玉米种植密度,使用BP神经网络建模,得到了最佳种植密度与最佳施肥量模型,并进行了模型验证。Dong等[11]采用小波神经网络建立施肥模型,指出该方法的拟合精度优于随机森林回归与支持向量回归,并使用模型确定了最佳施肥量。
以上研究表明,使用BP神经网络或优化BP神经网络可以描述施肥量等因素与作物产量之间的关系,从而制定施肥方案。然而BP神经网络存在两大缺陷。第一,BP神经网络是一种个体学习器,有性能提升的瓶颈[12]。第二,BP神经网络是一种“黑箱”模型,无法评估每个特征对输出结果的影响程度,模型的可解释性差[10,13]。梯度提升树是一种常用的集成学习算法,该算法训练多个个体学习器,再通过一定的策略结合,从而形成一个强学习器,具有拟合精度高、解释性强等特点[14-17]。使用梯度提升树算法建立的模型能有效地解决上述问题。本文以玉米“3414”试验数据作为训练样本,通过插值算法对数据进行扩充,采用梯度提升树算法建立施肥模型,并与常见的几种建模方法进行对比。通过分析施肥模型求解出最大产量与最优施肥量,以期提供施肥指导。
2 材料与方法
2.1 数据集描述与处理
“3414”试验是国内普遍采用的研究肥料效应的田间试验方案[18],其中“3”指氮、磷、钾3个因素,“4”指不施肥、最佳施肥量的0.5倍、最佳施肥量和最佳施肥量的1.5倍4种施肥水平,“14”指共有14种处理。
本文建模使用数据来自吉林省榆树市10处玉米地的“3414”试验[19]。在试验区土壤类型、气候等条件基本一致时,影响作物产量的因素为土壤氮、磷、钾含量和氮、磷、钾肥施用量这6个因素。依据当地的实际生产情况和专家经验,得到氮、磷、钾的最佳施用量分别为180、75和75 kg/hm2。表1列举了10个试验区的土壤养分含量,表2列举了试验区1的“3414”试验处理与对应的产量。
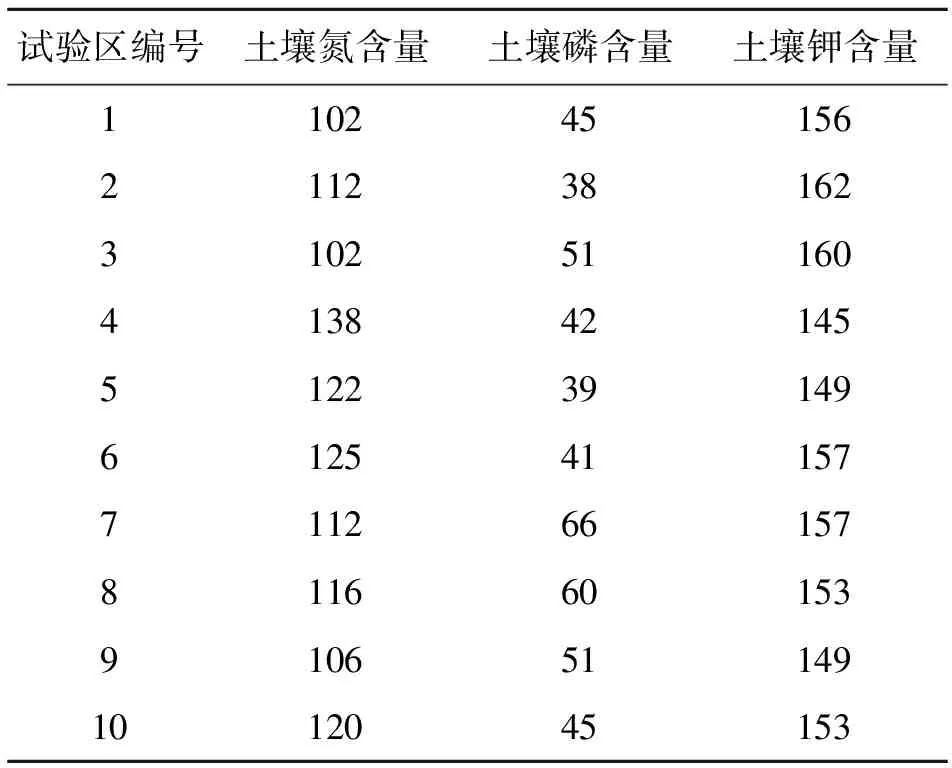
表1 各试验区的土壤养分含量 mg/kg
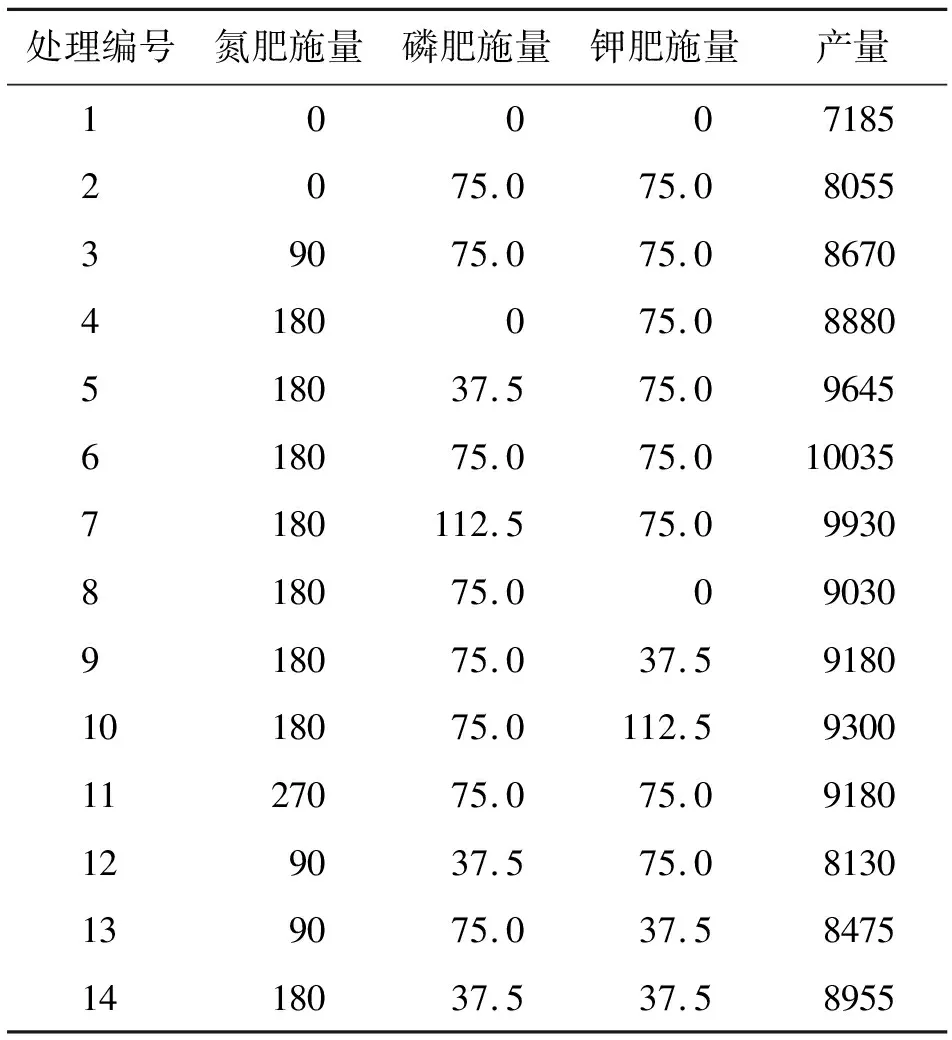
表2 试验区1的14种施肥处理与产量 kg/hm2
由表2可以分析玉米施肥量与产量的关系。第2、3、6、11组数据中磷肥和钾肥均处于最佳施用量,随着氮肥施肥量的增加,产量呈先增加后减小的趋势。观察第4、5、6、7组数据,在氮肥和钾肥处于最佳施用量时,随着磷肥施肥量的增加,产量也呈现先增加后减小的趋势。观察第6、8、9、10组数据,对钾肥也获得相同结果。这种现象与实际情况相符,表明通过“3414”数据构建施肥模型是合理的。
表2提供的施肥量与产量数据在构建施肥模型时样本数不够,为此,可以通过插值算法在一定范围内推求出新的数据点,进行数据集扩充[11]。常用的插值算法有线性插值法、多项式插值法和样条插值法。其中线性插值法快速简单但精度较差,而且在插值点处斜率会发生变化;多项式插值法是线性插值法的推广,精度有所提高,但是在区间边缘容易出现振荡现象;样条插值法使用特殊分段多项式进行插值,可以避免振荡问题,精度较高。为了获得更好的插值效果,本文采用2次样条插值法。通过表2中的第2、3、6、11组数据可以建立试验区1的氮肥施肥量与产量的插值曲线,其结果如图1所示。从插值曲线上两个相邻的原始数据点之间选择4个插值点从而可以得到16组数据。使用同样的方法对磷肥施肥量、钾肥施肥量进行插值。去掉重复的数据再加上原始数据,每个试验区可以扩充为50组数据,对其余9个试验区的数据进行相同的处理,可以将数据扩充为500组。
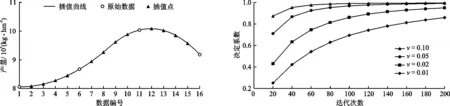
图1 试验区1氮肥施肥量与产量的插值曲线 图2 不同学习率下模型迭代次数与决定系数的关系曲线
2.2 梯度提升树
梯度提升树(Gradient boosting decision tree,GBDT)是由Friedman[20]于2001年提出的一种集成学习算法。其主要思想是每次建立的新模型都基于上一个模型损失函数的负梯度,通过多个弱学习器合成为一个强学习器。当弱学习器为回归树时,其计算过程如下[21]。
步骤1:输入训练数据集D={(x1,y1),(x2,y2), … ,(xN,yN)}。模型的输出为F(x),损失函数为L(y,F(x))。损失函数L的种类很多,常见的有平方差损失函数、绝对损失函数、Huber损失函数等。在梯度提升树算法中通常使用平方差损失函数。
L(y,F(x))=(y-F(x))2
(1)
步骤2:初始化模型F0(x)。
(2)
式中:γ为叶子结点输出值。
步骤3:对m= 1, 2, … ,M进行M次迭代,总共生成M个回归树。
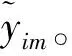
(3)

(3)计算回归树Tm叶节点的最佳输出值。
(4)
(4)更新模型
Fm(x)=Fm-1(x)+ν·γjm(x∈Rjm)
(5)
公式(5)中通常加入学习率ν来控制模型学习的速度,即每次更新Fm(x)之前,把叶子节点的输出乘以学习率ν(0<ν≤1),以小的步长逐渐逼近最佳结果。
步骤4:迭代结束,生成模型。
2.3 模型构建
在构建模型之前首先要划分数据集,一般选取2/3~4/5的样本数据用于训练,剩余样本用于测试[22]。梯度提升树模型中很多参数需要调整,为了评估模型在不同参数下的效果,需要从训练集中选取一部分数据作为验证集,用于模型调整模型参数[23]。由于本试验的数据量较少,使用单独划分出的验证集进行参数调整不具有代表性,因此采用交叉验证的方式调整模型的参数。最终将500组数据随机分为400组训练数据和100组测试数据,以土壤氮、磷、钾含量和氮、磷、钾肥施用量为输入量,以玉米产量为输出量。采用5折交叉验证和参数搜寻的方法调整模型参数。
在调节模型参数的过程中,通过score函数计算模型的决定系数R2来评判模型的优劣。首先调节迭代次数M和学习率ν。这两个参数均可控制模型的拟合程度,改变其中一个参数会影响另一个参数的最佳值。通过参数搜寻的方式寻找迭代次数M与学习率ν的最优组合,不同学习率下迭代次数与模型决定系数的关系如图2所示。由图2可以看出,随着迭代次数的增加,模型的精度越来越高;学习率较小时需要更大的迭代次数才能使模型达到较高的精度。迭代次数过少会导致模型的欠拟合,过多会导致模型的过拟合并且增加计算时间,综合考虑选择迭代次数M=100,学习率ν=0.1。同样采用参数搜寻的方式可以确定回归树的最大深度为7,叶子节点最少样本数为5,最大特征数为3。
3 结果与分析
3.1 预测结果与模型解释
确定模型的最佳参数组合后使用全部训练数据重新训练模型,训练结束后使用测试集检验模型。为了便于观察,从100组测试数据中选取30组数据,将预测值与真实值进行对比,结果如图3所示。由图3可以看到产量的预测值与实际值基本吻合,只有少部分测试数据出现了偏差,表明模型的预测效果较好,准确度较高。
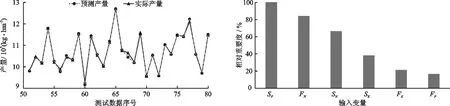
图3 部分测试集模型预测值与真实值对比 图4 模型各输入变量的相对重要度
梯度提升树模型通过每个变量在回归树中出现的次数来计算每个输入变量的重要度[15],从而使模型具有一定的解释性。图4展示了每个输入变量的相对重要度。可以看出,相对重要度最高的为土壤的含磷量SP,其次分别为施氮量FN、土壤含氮量SN、土壤含钾量SK、施钾量FK、施磷量FP。从氮、磷、钾各元素的角度来看,氮元素和磷元素对产量的影响较大,而钾元素对产量的影响较小。
当然,通过职业院校技能大赛,也反映出了我们在教学中的一些薄弱环节。如教学投入不足,教学实习和实训设备不够完善,选手不能适应竞赛中采用的现代企业新设备、新技术、新流程,或在规定时间内完成不了比赛任务;基础理论课教学与专业技能训练没有有机结合。应大力推行教学做一体化模式,使车间与教室合二为一,理论与实践有机融合,努力培养更多高素质、技能型专业人才和实践应用型能工巧匠。
3.2 模型比较
除了梯度提升树之外,BP神经网络(back propagation neural network, BPNN)、支持向量回归(support vector regression, SVR)、随机森林(random forest, RF)也是解决非线性问题的有力工具。为了进一步验证梯度提升树模型的效果,分别使用以上3种机器学习算法建立模型,并与梯度提升树算法建立的模型进行对比。为了便于比较,使用各方法建模时,均以土壤氮、磷、钾含量和氮、磷、钾肥施用量作为输入变量,使用产量作为输出变量,并使用相同的训练集进行训练。
与梯度提升树对比的3种算法中,BP神经网络使用3层前馈网络,隐含层个数确定为11[24],模型中加入L2正则化项防止过拟合,使用双曲正切激活函数,用牛顿法进行迭代,建模之前对数据进行归一化处理;支持向量回归模型中引入RBF核函数来解决非线性问题,使用训练集交叉验证和网格搜索的方式最终确定惩罚系数C=115,核函数系数为0.1;随机森林模型通过交叉验证逐步调整模型参数,最终得到回归树个数Mt=250,回归树的最大深度为19,最大特征数为5。
采用相对误差(RE)、均方根误差(RMSE)和平均绝对误差(MAE)作为模型的评价指标。图5分别展示了4种模型在相同测试集上的相对误差。由图5(a)中可以看,出梯度提升树模型的RE主要在0~1%的范围内波动,有少部分测试数据的RE在1%~2%,平均相对误差为0.46%。图5(b)中BP神经网络模型的RE主要在0~1%的范围内波动,有少部分测试数据的RE在1%~2%,有极少测试数据的RE为2%~3%,平均相对误差为0.54%。图5(c)中支持向量回归模型的RE波动较大,波动范围主要在1%~6%,平均相对误差为3.19%。图5(d)中随机森林模型的RE主要在0~2%的范围内波动,少部分测试数据的RE位于2%~6%,平均相对误差为1.00%。可以看出4种模型中,支持向量回归模型的相对误差最大,在数值上明显高于其他3种模型;而梯度提升树模型的相对误差最小。
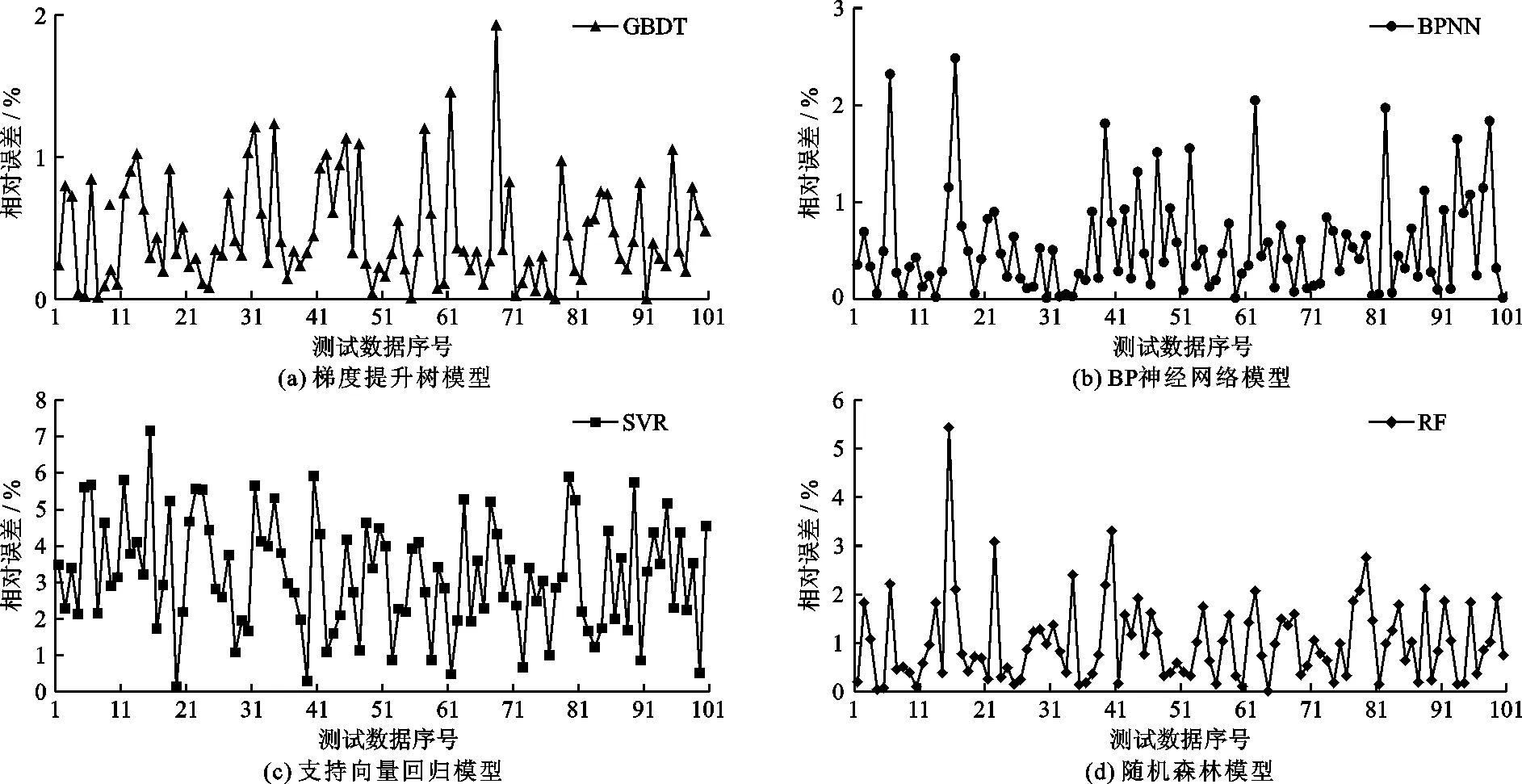
图5 4种模型在相同测试集上的相对误差
图6展示了4种模型(GBDT、BPNN、SVR和RF)的均方根误差与平均绝对误差。其中梯度提升树模型的RMSE和MAE分别为62.2和48.7kg/hm2,BP神经网络模型的RMSE和MAE分别为78.5和56.5 kg/hm2,支持向量回归模型的RMSE和MAE分别为371.6和337.5 kg/hm2,随机森林模型的RMSE和MAE分别为133.8和104.6 kg/hm2。支持向量回归模型的RMSE和MAE明显高于其他3种模型,梯度提升树、BP神经网络、随机森林3种模型的RMSE和MAE较小,其中梯度提升树模型的RMSE和MAE最小。
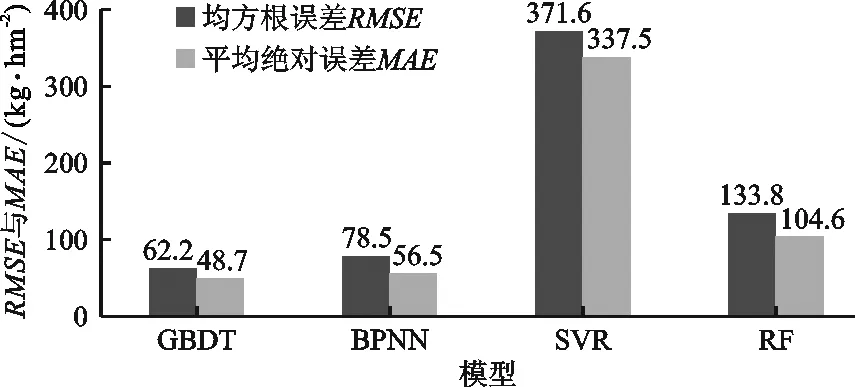
图6 4种模型的均方根误差与平均绝对误差
以上结果表明梯度提升树算法建模效果最优,BP神经网络和随机森林次之,支持向量回归最差。
3.3 确定最优施肥量
依据梯度提升树算法构建的施肥模型可表示为:
Y=F(SN,SP,SK,FN,FP,FK)
(6)
式中:Y为产量,kg/hm2;SN、SP、SK分别为土壤中氮、磷、钾的含量,mg/kg;FN、FP、FK分别为氮、磷、钾肥施用量,kg/hm2;F为产量与土壤氮、磷、钾含量和氮、磷、钾肥施用量的函数关系。
因此在给定土壤养分含量的情况下,通过求解非线性规划问题可以计算最大产量以及相应的施肥量。以试验区1为例,已知:
(1)Y=F(SN,SP,SK,FN,FP,FK)
(2)SN= 102 mg/kg,SP= 45 mg/kg,SK= 156 mg/kg
(3)0 经过计算,可得试验区1的最大产量与相应的最佳施肥量,即试验区1的最佳施氮量为193 kg/hm2,施磷量为80 kg/hm2,施钾量为73 kg/hm2,此时最大产量为10 161 kg/hm2。 使用相同的方法可以计算其他9个试验区的最佳施肥量与产量。表3列举了各试验区的最优施肥量与产量。 表3 各试验区的最优施肥量与产量 kg/hm2 由于梯度提升树算法基于回归树,因此在一定土壤含量范围内可能得出相同的最佳施肥量。然而各个试验区的土壤养分含量不同,因此其最大产量也有所不同。由表3可知,试验区7得到的产量最大,达到13 242 kg/hm2。 合理的施肥方案既可以提高作物的产量,同时也能减少环境污染。通过建立施肥模型寻找施肥量等因素与产量之间的关系,从而指导施肥是实现精准农业的关键。本文提出了一种基于梯度提升树算法的施肥模型,得到了适合当地的最佳施肥量方案。 在4种建模方法的对比中,梯度提升树算法建模效果最优,BP神经网络和随机森林其次,最后是支持向量回归,这和Dong等[11]的研究结果十分接近。梯度提升树算法和随机森林算法均为基于决策树的集成算法,建模精度较高。两种算法的不同之处在于梯度提升树的基学习器是串行生成,即每次生成的新学习器都是依据上一次的建模结果;随机森林算法中的基学习器是并行生成,基学习器之间是独立的。BP神经网络模型虽然也有较高的建模精度,但是相比其他3种方法,在建模过程中需要更多参数调整,并且不同的参数组合对建模结果有较大的影响,相比两种基于决策树的建模方法缺少可解释性。支持向量回归虽然可以通过引入核函数的方式解决非线性的问题,但是在拟合的精度上不如其他3种方法。通过模型计算得到各试验区的最佳施肥量尽管与当地的推荐量稍有不同,但在产量上有所提高,能够给当地施肥提供技术指导。 本文提出的施肥模型考虑了土壤养分含量和总施肥量,因此只适用于土壤类型、气候等条件基本一致的地区,存在一定的局限性。为了扩大施肥模型的适用范围,使其具有更好的泛用性,今后应该在更广泛的尺度上收集数据,并且在建模时考虑更多的影响因素。 (1)使用梯度提升树算法建立的施肥模型可以反映土壤养分含量、施肥量与作物产量之间的关系,并对产量进行较高精度预测。 (2)对比4种建模方法发现,梯度提升树模型最优,BP神经网络和随机森林模型次之,支持向量回归模型最差,在今后实际应用中可以优先采用梯度提升树算法进行建模。 (3)相比BP神经网络、随机森林和支持向量回归模型,梯度提升树算法建立的施肥模型具有更好的解释能力。通过分析本文建立的施肥模型发现,影响产量较大的因素是土壤含磷量与施氮量,钾元素对产量的影响较小。 (4)在已知土壤氮、磷、钾养分含量情况下,由施肥模型可以得到最优施肥量方案和最大产量,从而有效指导施肥。
4 讨 论
5 结 论
