基于不同优化算法的土壤水分特征曲线模型模拟性能分析
2020-12-21石文豪王铁军张永根
石文豪,李 奇,韩 琼,王铁军,陈 喜,张永根
(1.天津大学 地球系统科学学院表层地球系统科学研究院,天津 300072;2.天津市环渤海关键带科学与可持续发展重点实验室,天津 300072)
1 研究背景
包气带土壤水是陆地水循环的重要组成部分,是地球各圈层之间进行物质运移和能量交换的关键载体,对调节陆地生态系统平衡具有关键作用[1-2]。随着人们对环境问题的关注度日益提高,采用先进的模拟方法对土壤水分运动及溶质运移规律进行模拟研究已经受到越来越多的关注[3-5]。准确模拟土壤水分及溶质运移过程需要精确量化土壤水动力学参数,这些参数包括土壤水分特征曲线和非饱和导水率(渗透系数)曲线[6]。土壤水分特征曲线反映了土壤孔隙中水分质量(土壤含水量)与能量(土壤基质势)之间的函数关系,同时也间接反映出土壤内部的孔隙情况,而非饱和导水率曲线也可通过联合土壤水分特征曲线和导水率模型推导得出[7]。
近几十年来,研究者在确定土壤水分特征曲线方面进行了大量研究,总结起来主要包括两类,一类是测量土壤水分特征曲线上离散的数据点,并利用经验公式拟合实测含水量与土壤基质势之间的关系[8-9];另一类是利用间接的方法如土壤传递函数(soil pedotransfer functions),建立土壤基本理化性质与土壤水分特征曲线模型各参数之间的相关关系,用以解决实际测量土壤水分特征曲线过程中可能存在的采样难度大、成本高、实验周期长等问题[10-11]。其中,直接测量方法的准确度,以及经验公式的选取决定了间接方法的精度与预测能力,因此直接方法是间接预测方法的基础[12]。此外,利用经验公式拟合实测土壤水分特征曲线需要选取合适的拟合算法。已有研究表明,应用不同的拟合算法会影响模型对实测数据的拟合效果[13]。例如广泛使用的RETC软件[14-15](基于非线性最小二乘法)在拟合实测数据时,常存在参数初值设定难、无法收敛到全局最优解等弊端[16-17],使用高效稳定的全局寻优算法会显著提高模型的拟合效果[18-19]。因此,拟合算法的选取也是提高土壤水分特征曲线拟合效果的重要因素。目前土壤水分特征曲线与拟合算法相结合的研究大多集中于van Genuchten模型,而鲜有关于其他土壤水分特征曲线模型受拟合算法影响的相关研究[20-23]。在比较不同拟合算法的研究中,Yang等[23]选用4种土壤的实测资料比较了遗传算法、粒子群算法、模拟退火算法拟合van Genuchten模型的效果,认为三者的拟合效果相近。Wang等[19]使用RETC软件和遗传算法对6个滨海盐渍土土样的实测数据进行拟合,结果表明遗传算法对van Genuchten模型的拟合效果较RETC软件有较大提升。Maggi[5]使用UNSODA 2.0数据库中的4个土壤样品的实测持水数据,比较了差分演化算法与RETC软件对van Genuchten模型的拟合效果,证明差分演化算法的拟合效果更好。虽然这些算法在van Genuchten模型中体现出较好的拟合效果,但对其他土壤水分特征曲线模型的适用性仍不确定,并且用于评价拟合效果的土壤实测数据有限。因此本研究将结合不同的拟合算法,使用含有世界各地土壤数据的UNSODA 2.0数据库分析4种应用较为广泛的土壤水分特征曲线模型对实测数据的拟合效果,并对不同土壤质地类型下各土壤水分特征曲线和拟合算法组合的适用性进行研究。
2 材料与方法
2.1 数据来源
本研究选取UNSODA 2.0数据库[24]对上述4种土壤水分特征曲线模型和4种拟合算法进行分析。该数据库包含世界各地共计790个土壤样品。由于本研究中选取的土壤水分特征曲线模型中最多拟合参数为5个(即Biexponential模型[28]),因此选取数据库中样品实测含水量个数大于等于5的土壤样品进行参数拟合计算。经筛选得到土壤样品共计557个,各土壤质地类型下的样品个数见表1。

表1 从UNSODA 2.0数据库中所选取的土壤质地类型及样品个数(分类标准参照美国农业部土壤质地类别)
2.2 土壤水分特征曲线模型
本研究选取了4种应用较为广泛的土壤水分特征曲线模型,分别为Brooks-Corey模型[25]、van Genuchten模型[26]、Kosugi模型[27]和Biexponential模型[28]。Brooks-Corey模型是于1964年提出的分段函数模型,该模型将土壤基质势(取正值)是否小于土壤进气压力(取正值)作为土壤饱和的判定条件,在土壤基质势小于土壤进气压力的条件下,土壤含水量达到最大,即饱和含水量;van Genuchten模型于1980年提出,为了更好地应用Mualem[29]所提出的土壤非饱和导水率预测模型,van Genuchten模型通常采用m=1-1/n;Kosugi模型基于土壤粒径服从正态分布的现象,并结合毛细管吸力方程,建立了土壤毛细吸力与土壤饱和度之间的函数关系;Biexponential模型对已有的指数模型进行优化,综合考虑了土壤质地和土壤结构因素对土壤孔隙的影响。上述4种土壤水分特征曲线模型的方程形式及相应参数见表2。

表2 4种土壤水分特征曲线模型方程形式及相应参数
在拟合实测数据时,通常需要给土壤水分特征曲线模型的参数设定一个合理的拟合范围。本研究中所有模型的土壤残余含水量设定为0<θr< 0.2 cm3/cm3,土壤饱和含水量设定为0.2<θs< 0.8 cm3/cm3。为了确保达到最优的拟合效果,其他待拟合的参数尽可能设置在较大的范围内,其中Brooks-Corey模型中0.01 目前有关利用非线性最小二乘法对土壤水分特征曲线模型的拟合已有大量研究,且已证明最小二乘法在拟合中存在不易收敛、拟合效果较差等问题[15-16]。因此本研究拟选取拟合优化问题中较为常用的遗传算法[20]、粒子群算法[18,22]、模拟退火算法[23]和差分演化算法[5]对4种土壤水分特征曲线模型进行参数拟合。 2.3.1 遗传算法(genetic algorithm) 遗传算法依据自然进化论和遗传学的思想,通过不断繁衍和淘汰过程,生成种群中的近似最优个体。由于遗传算法并非基于指定路径进行探索,而是基于概率控制探索最优解,所以理论上遗传算法能够收敛于全局最优。 2.3.2 粒子群算法(particle swarm optimization) 粒子群算法是模拟鸟群捕食活动的仿生优化算法。将每只飞鸟概化为一个“粒子”,“粒子”具有搜索速度与方向两个属性,粒子的当前位置为优化问题的候选解,通过飞行过程搜索最优解。每个粒子所在的位置为当前个体极值,种群中最优的个体极值即为当前的全局最优解。 2.3.3 模拟退火算法(generalized simulated annealing) 模拟退火算法是基于退火过程。该算法在获得优化解的同时,还在一定程度上接受非优化解,这是该算法不会局限于局部最优解的关键。在拟合的初始阶段,模拟退火算法会接受较大的非优化解,随着拟合过程的进行,接受非优化解的范围逐渐变小,最终将不接受任何非优化解。 2.3.4 差分演化算法(differential evolution optimization) 差分演化算法的基本思想与遗传算法类似,通过模拟遗传过程中的杂交、变异、复制来设计算法过程,利用淘汰机制更新种群。差分演化算法与遗传算法之间的区别在于,遗传算法的变异操作是基于个体进行变异,而差分演化算法的变异操作是基于个体之间的差异进行。 2.3.5 拟合过程 本研究中拟合算法主要使用R程序中对应的程序包。为了尽可能达到最优的拟合效果,经测试后,各算法种群数量与迭代次数设定如表3所示。 表3 所选取的各拟合算法相关信息 模型的拟合效果以实测土壤含水量与模型模拟含水量的均方根误差(RMSE)和决定系数(R2)作为拟合效果的评价指标。具体公式如下。 (1) (2) 式中:xi为实测土壤含水量,cm3/cm3;xiest为采用土壤水分特征曲线模型在相应土壤基质势时模拟的土壤含水量,cm3/cm3;n为该样品实测土壤含水量测点的数量。 本研究通过比较均方根误差值(RMSE)、决定系数(R2)的大小判断拟合程度。均方根误差值越小且决定系数越接近1,即表明模型模拟值与实测值的偏差越小,即模型拟合效果越好。 本文利用上述4种算法对选取的4种土壤水分特征曲线模型进行拟合,发现土壤水分特征曲线模型与拟合算法的不同组合会导致拟合效果存在差异。本小节选取UNSODA 2.0数据库中第729号土壤样品为例进行说明,如图1所示。 注:图中实测数据为UNSODA 2.0数据库中第729号样品;RMSE值为各算法下拟合实测数据的均方根误差,cm3/cm3。 由图1可见,土壤水分特征曲线模型与拟合算法的不同组合对曲线的刻画程度不同,尤其是在接近干燥和近饱和区的差异较大。在这些区域,由于缺少实测数据点,采用不同土壤水分特征曲线模型和不同拟合算法对完整的曲线形状有很大影响。此外,从图1中还可以看出,在近饱和区使用van Genuchten模型和模拟退火算法(图1(b))拟合得到的土壤含水量较其他算法明显偏高;而在Kosugi模型中使用遗传算法(图1(c))在近饱和区拟合得到的土壤含水量较其他算法明显偏低。下节将对本次研究中所使用的557个样品进行详细分析。 对筛选出的557个土壤样品进行计算分析,得出4种土壤水分特征曲线与4种拟合算法组合(共16种)在不同土壤质地类型下拟合实测数据的均方根误差RMSE和决定系数R2,分别见表4和5。 表4 不同土壤水分特征曲线模型与拟合算法组合在不同质地类型下的均方根误差RMSE 10-2(cm3/cm3) 表4中所有均方根误差RMSE的最大值均未超过3.5×10-2cm3/cm3,并且除Brooks-Corey模型外,其余3种模型在不同质地类型下的决定系数R2均大于0.9。表明除Brooks-Corey模型外,其余3种土壤水分特征曲线模型均表现出良好的拟合效果。但在不同类型的土壤质地下,不同模型对UNSODA 2.0数据库中实测数据的拟合效果存在差异,体现出不同模型对不同质地类型土壤的水分特征曲线的刻画能力不同。综合两种拟合评价指标的统计结果可以看出,van Genuchten模型和Biexponential模型为4种模型中拟合效果最好的两种,在多数土壤质地类型下计算得到的两类评价指标的平均值为该质地类型中最优(见表4、5中粗体数据)。其中van Genuchten模型在质地较细和较粗的土壤类型下拟合效果较好,而对壤土和接近壤土类型的土壤拟合效果欠佳。与van Genuchten模型相反,Biexponential模型对粉土、壤土和接近壤土类型的土壤拟合效果较好。Kosugi模型对土壤质地为粉砂质黏壤土和砂黏壤土的拟合效果较好,而Brooks-Corey模型在12种土壤质地类型中的拟合效果均为最差。同时,评价指标中还显示出4种拟合算法对土壤水分特征曲线拟合效果的差异。计算结果显示,4种拟合算法中粒子群算法和差分演化算法的拟合效果最好,且两种算法的拟合效果非常接近;模拟退火算法的拟合效果略逊于粒子群算法和差分演化算法;遗传算法的拟合效果最差。 表5 不同土壤水分特征曲线模型与拟合算法组合在不同质地类型下的决定系数(R2) 表4中每种土壤质地下均方根误差的均值能够表现出土壤水分特征曲线模型与拟合算法组合对实测数据拟合效果的平均情况,但未能清晰地反映出所有样品拟合效果的分布情况。因此采用小提琴图对土壤水分特征曲线整体拟合效果较好的van Genuchten模型和Biexponential模型的均方根误差RMSE进行统计。由于粒子群算法和差分演化算法的拟合效果相近,仅选取差分演化算法的计算结果进行展示,用于反映均方根误差值的概率密度分布特征,结果如图2所示。 图2 van Genuchten模型和Biexponential模型在差分演化算法下各土壤质地类型的均方根误差 图2中每个小提琴的绘制是基于对均方根误差值的核密度估计。核密度估计是一种研究数据分布特征的方法。该方法不预先设定样本的分布类型,只从数据出发对样本的分布特征进行研究。通过核密度可以更明显地反映出所有数据拟合得到的均方根误差的概率密度情况。从表4中van Genuchten模型和Biexponential模型与差分演化算法组合对各土壤质地的均方根误差可以看出,van Genuchten模型在黏土、粉砂质黏土、砂黏壤土、壤砂土和砂土下的拟合效果略好于Biexponential模型,其余土壤质地下Biexponential模型的拟合效果更好。而结合图2比较两个模型在各质地土壤类型下均方根误差的核密度分布可得出,van Genuchten仅在壤砂土和砂土质地下的均方根误差均值和分布较Biexponential偏小,在其余质地类型的土壤中van Genuchten获得较小均方根误差值的优势并不明显,而Biexponential获得较小均方根误差值的概率更大。综合可得,在不考虑模拟参数个数的情况下,利用Biexponential模型结合差分演化算法能获得更好的拟合效果。 对不同土壤水分特征曲线模型在4种拟合算法下的运算耗时进行统计,各个算法的种群数量、迭代次数如表3所示。4种拟合算法迭代次数均为1 000次,种群数目为1 000(模拟退火算法不需要设定种群数目),统计结果如图3所示。 图3 4种算法在各模型下的单次运算时间统计结果 由图3中各算法的运算效率来看,算法之间存在较大差别。模拟退火算法的运算效率是最高的,该算法的拟合耗时远小于其他拟合算法,平均耗时仅为0.26 s,其次为差分演化算法和粒子群算法,平均耗时分别为28 s和108 s,遗传算法所用时间最长,平均耗时为204 s。 对单个土壤样品进行拟合分析时,4种拟合算法的运算耗时相差不大,但当拟合数据较多时,算法在运算耗时上的差异会随着样品数量的增加逐渐显著。另外,在曲线拟合中加入交叉验证或者模型不确定性分析等计算时,耗时较短的拟合算法的优势会更明显地体现。以本次研究计算为例,557个土壤样品利用模拟退火算法运算耗时仅需18 min,而遗传算法运算耗时则需要近124.5 h。 本研究涉及的4种土壤水分特征曲线模型与4种拟合优化算法的拟合效果均较为理想。其中van Genuchten、Kosugi和Biexponential模型拟合效果略优于Brooks-Corey模型。王愿斌等[7]基于8种土壤的实测数据对常用土壤水分特征曲线模型(未包含Biexponential模型)的评价表明,van Genuchten模型与Kosugi模型在拟合性能上优于Brooks-Corey模型,与本研究得出的结论一致,且本研究对557个土壤数据进行了研究,实测数据覆盖12种土壤质地类型,因此具有更好的普遍性。另外,所使用的拟合优化算法中,遗传算法在拟合效果与运算效率方面均不及其余3种算法。Hosseini等[30]也表示遗传算法容易过早收敛且该算法相比于粒子群算法拟合效果较差,与本研究得出的结论一致。本研究较Hosseini等[30]的研究添加了模拟退火算法与差分演化算法,得出差分演化算法与粒子群算法的拟合效果相近,且运算效率较粒子群算法显著提高。 不同土壤水分特征曲线模型与拟合算法对实测土壤持水数据拟合差异的原因分析如下: 从土壤水分特征曲线模型角度考虑:(1)模型是决定曲线形状的关键因素,在很大程度上决定了对实测值的拟合效果。土壤水分特征曲线本质上表现为“S”形,其中van Genuchten模型、Kosugi模型以及Biexponential模型均为“S”形曲线模型,因此对实测值表现出较好的拟合效果。Brooks-Corey模型在特定基质势范围内呈指数形式,可以较好地拟合实测点,但该模型在进气值处采取分段模型,与实际情况存在差异,因此在拟合效果中表现较差。(2)推导土壤水分特征曲线模型的基本假设与实际情况存在差异,可能影响了模型对实测值的拟合效果。例如Kosugi等[27]在Kosugi模型中假设土壤孔隙半径服从对数正态分布,从而推导出相应的土壤水分特征曲线模型,但实际土壤孔隙半径可能并非完全服从单峰的对数正态分布,可能存在土壤孔隙半径分布为双峰型曲线的情况,从而使得基于单峰型的土壤水分特征曲线模型的拟合效果不佳。Ebrahimi等[31]与Seki[32]认为目前基于双峰土壤孔隙结构建立的模型的拟合程度是否优于单峰型的模型仍存在争议。(3)实测土壤样品的尺寸、土壤自由膨胀率以及土壤水分特征曲线测量方法(如压力膜法、沙箱法、离心机法等)的差异也会对模型的拟合效果产生影响。例如,Ghanbarian等[33]证实了土壤样品尺寸对土壤水分特征曲线的影响;Javanshir等[34]认为土粒的膨胀特性会对土壤水分特征曲线的参数估计产生影响;Solone等[35]认为利用压力板测量土壤水分特征曲线具有局限性并讨论了产生误差的原因,他指出土壤样品是否达到平衡状态会严重影响实验数据质量,进而影响模拟结果。例如在高基质势状态下,土壤的非饱和渗透系数非常小,土壤往往难以达到真实的平衡状态,因而实验人员对土壤是否达到平衡状态的判断也会影响实验结果。 从优化算法角度考虑,本研究采用的4种优化算法均属于全局寻优算法,其中粒子群算法与差分演化算法表现较好。粒子群算法没有遗传算法的交叉和变异等操作,原理更为简单、参数更少[18];而差分演化算法相对于遗传算法所使用的交叉、变异、选择等算子与遗传算法相比都不同,可以认为是改进的遗传算法[5]。因此这两种算法可能更适宜于拟合土壤水分特征曲线。本研究选取的土壤水分特征曲线模型主要适用于土壤水分从饱和到土壤薄膜水之间变化,而从薄膜水到完全干燥状态下土壤水分的变化尚未考虑,而这部分土壤水分在干旱地区对土壤蒸发和根系吸水具有重要的作用。因此在今后的研究中,应当充分考虑土壤水分从饱和到完全干燥状态下的土壤水分特征曲线模型的拟合和性能分析。此外,不同的拟合算法在拟合效果和运算效率上有所差异,今后的研究可以将各个优化算法相结合,实现优势互补,提高优化性能。研究成果可用于建立土壤传递函数,为高效预测土壤水力参数提供依据。 本研究利用含有世界各地土壤水分特征曲线数据的UNSODA 2.0数据库,对4种土壤水分特征曲线模型和4种拟合算法的组合进行了研究。研究结果表明: (1)在分析的4种土壤水分特征曲线模型中,van Genuchten模型与Biexponential模型整体表现较好,Brooks-Corey模型拟合效果整体表现较差,Kosugi模型表现居中。van Geunchten模型在土壤质地较细和较粗的土壤类型中表现优异,而在中等粒度质地的土壤中表现欠佳;Biexponential模型在中等粒度质地土壤类型中表现优异,但在较细与较粗的土壤质地类型中表现欠佳。 (2)在拟合算法的比较中,粒子群算法与差分演化算法拟合效果最好,且两种拟合算法的结果差异很小,遗传算法在本次研究中效果最差,模拟退火算法略优于遗传算法。 (3)从运算耗时角度考虑,模拟退火算法用时远远小于其他算法,差分演化算法次之。当数据量较小时,建议使用差分演化算法;当数据量较大时,使用模拟退火算法可极大地缩短运算时间。2.3 拟合算法

2.4 拟合效果评价指标
3 结果与分析
3.1 实例计算
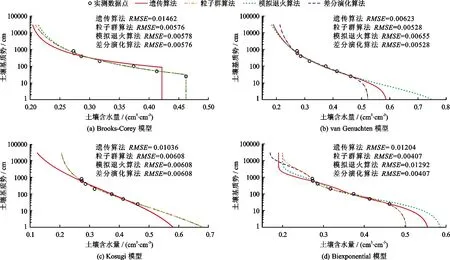
3.2 结果分析
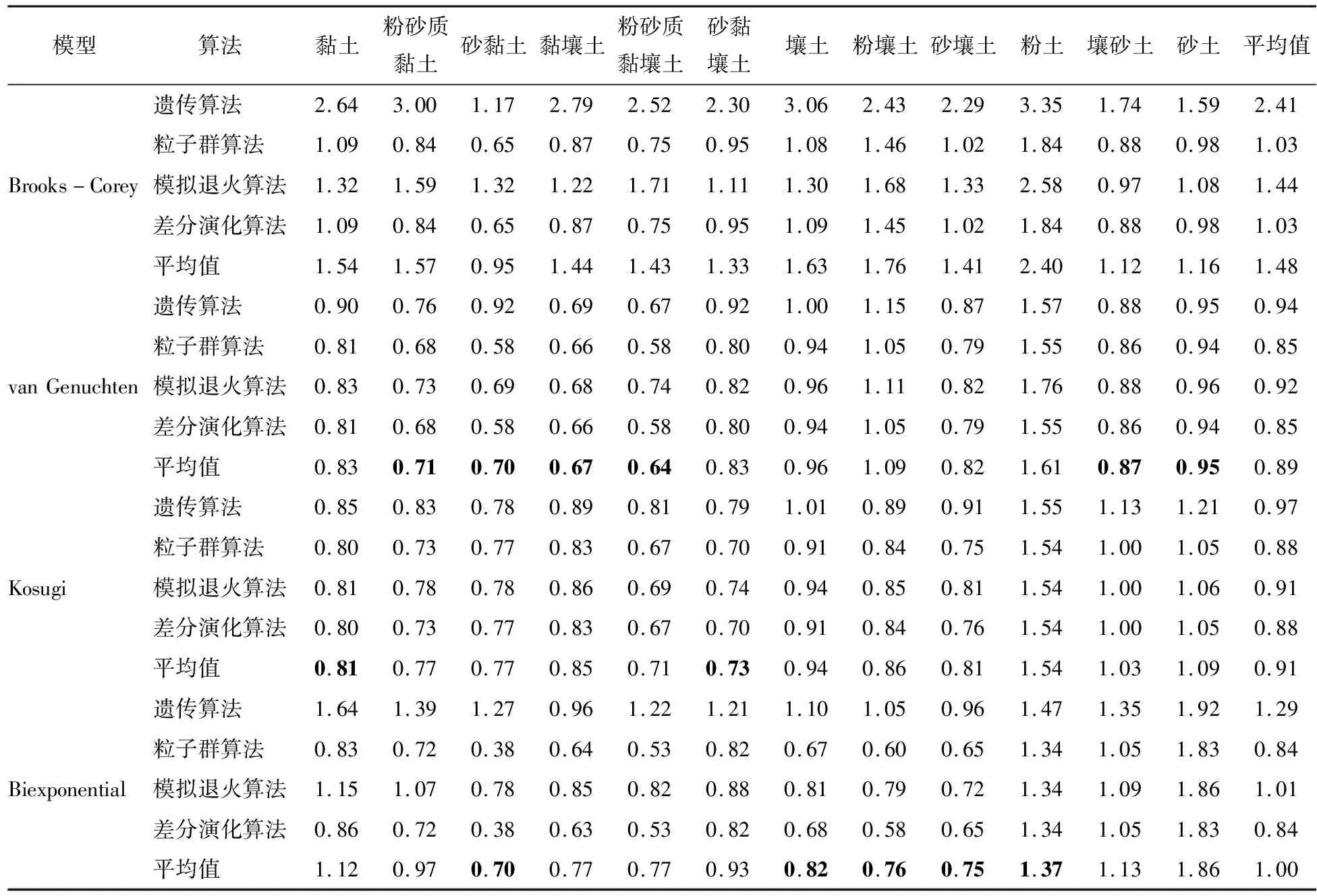

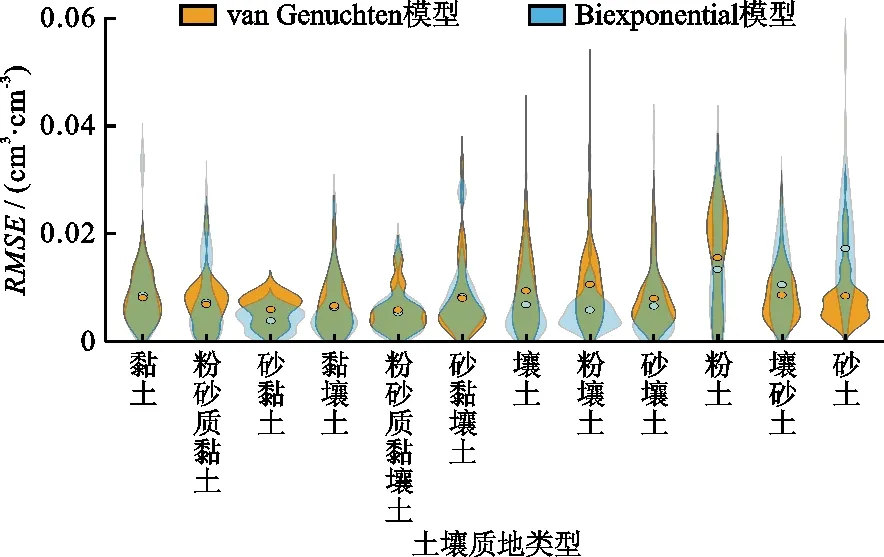
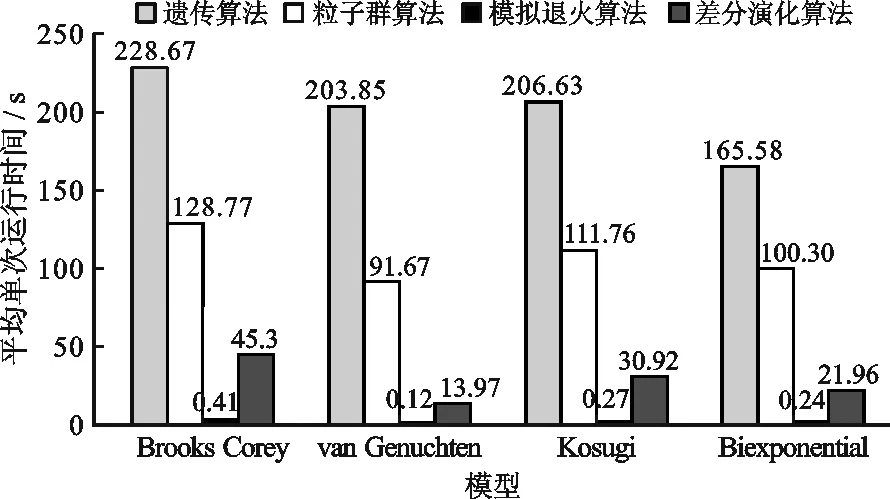
3.3 拟合运算效率
4 讨 论
5 结 论
