知识图谱的资产关联模型构建和运用分析
2020-12-21任敬斌
张 磊 任敬斌 魏 丽
(国网甘肃信通公司,甘肃 兰州 730050)
0 引言
在市场体制快速改革的大背景下,参与跨行业、跨区域经营活动的企业数目有快速增长趋势,电网行业精确掌握企业生产实况的难度相应增加,很可能使授信工作推进阶段面对诸多阻碍。为了解除以上问题,合理地应用大数据技术,利用官方及相关数据建设模型于关联图谱。与常规图谱相比,关联图谱能真切地勾画出不同主体间形成的关联网络,特别是为带电网数据主体勾画出完整的“自画像”,在三维空间还原实际状况。
1 研究方法
1.1 知识图谱
从本质上分析,知识图谱为一类结构化、语义化的知识库,其以符号为载体阐述客观存在事物的定义、特性及其相关性。实体、相关性及与之相关的属性为只是图谱的基本构成单元,基于关系链条不同实体间形成一张知识网络。
1.2 Spark平台
在Hadoop 以后较为流行的新大数据处理平台——Spark平台,也可以将其看成是一个快捷的测算引擎,当下应用较为广泛。Spark 吸纳了Hadoop 的优势,在设计方面进行完善,和Hadoop 相比,其效率提升了100 倍左右,因此,在有Map Reduce 迭代需求的情景内适用性更强,数据挖掘、机器学习是典型代表。
2 采集数据
首先,剖析建设知识图谱的模式与目标对象,会涉及顶层定义、顶层事件内容,两者在社交、物权、运营等方面存在一定的相关性。其次,把持有的信息转型为对应的实体,存储于图数据库内并建设图节点;提获不同本体间的相关性并细化其所属类别,然后整体存于图数据库内,这是关联边建设的重要基础。这样一个知识图谱的大体轮廓随之形成,但是该图谱需要在他类数据的协助下拓展内容[1]。
3 构建数据处理系统的架构
3.1 数据源
在该系统内,数据源发挥了逻辑核心功能,结合数据需求差异性,本系统涵盖授权、爬虫及自有数据。
3.2 存储层
因该系统内有很多类型有别的数据源,持有高价值、权威性强的结构化数据,为了满足系统后续阶段提供的拓展需求与考评数据异构属性,该系统拟定整合NoSQL 与SQL 数据库的形式存储数据,NoSQL 内未设置有严格要求的表结构,简化了数据集表结构整改流程[2]。
3.3 计算层
计算层主要针对存储在计算机系统中的非结构化数据完成抽取信息、挖掘数据等任务。构建系统过程中需要综合应用数据挖掘、图计算和机器学习等诸多技术。
3.4 模型层
这是系统将自身核心价值充分体现出来的层级依托,促进多个用于阐述企业相关信息的模型产出过程,进而达到整体呈现企业数据“自画像”的目的。
4 建设资产关联模型
4.1 捕获与集成数据
内、外部都是获得数据的重要渠道,前者包括上级企业传送的数据、电子档案影像、视频及视频资料等;外部数据多是微博、网站等上发布的动态结构或非结构化数据、将来集中式购置的数据等。在ETL 工具的帮衬下,每日或定时收集平台有关数据源。
4.2 处理平台数据
以Hadoop 的处置集群为基础建设数据平台,存储、测算被采集数据信息是平台的核心功能。Hadoop 聚集了多种功能性构件;HDFS 作为分布式文件系统,以分布式形成存储大数据文件;在大批量数据测算过程中,YARN 发挥管理与调控资源的作用;Hbase 是持有拓展功能的NoSQL 数据库,结构及非结构化数据均可存储于其内;针对存留于HBase 内的数据,可采用Hve 查找、解读数据;Spark 作为快速通用型测算引擎,通用性、适用性均处于较高层次上(如图1 所示)[3]。
4.3 分析大数据
平台数据处理层整合、加工、测算大批量数据后,产出面向主题的数据集与多样化分析模型。对多源异构数据信息予以整合处理后,可以建设有阐述企业有关信息的数据模型,常见的有关系图谱、物理方位、诉讼惩罚等,进而整体呈现出活跃在资本市场环境内的企业数据“自画像”。
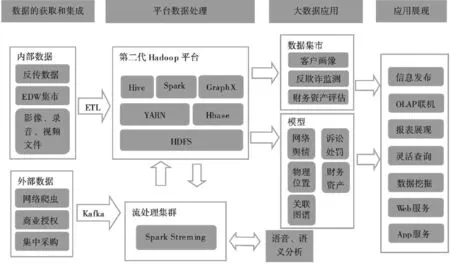
图1 资产关联模型图示
5 应用情景
5.1 辨识关联企业
很多企业间建设的关联关系具有极为显著的隐匿性特征,从表象上难以观察到,合理应用大数据分析系统能促进企业关系网复原过程。利用数据挖掘技术分析企业对内部、外部真实的担保状况、与诉讼相关的信息,结合不同企业之间发生的大型、不均等交易活动以及大事纪等诸多信息,历经互为印证过程判别企业间存在的关联性。当确定大数据分析系统全面掌握了不同电力公司间塑造的关联性行为后,就能够关联知识图谱内建设出不同主体之间的联系网络,同时将数值分别赋予各类关联联系,例如,赋予互为担保关系赋一个较大数值;小额度账户资金往来关联关系,通常赋予低值;而针对间接关联关系,通常分流程测算出关联关系值,最后测算出2 个不同主体间的相关性程度,并智能化做出标识,逾越预设阈值时将会智能传送出预警信号,披露企业之间存在的关联关系。
5.2 审批与管理
在办理授信审批业务过程中,对现场实地考评、结构化数据集审批人员的主观判断表现出高度依赖性,以无多维度、多样性数据为支撑,很难准确地辨识出客户群体的偿债能力。在知识图谱关联的协助下,能够减轻企业之间信息不对称的问题,协助企业能在短时间内快速了解客户的真实运营状况、经济效益、资金需求量。可以在资产关系模型的支撑下建设实时监测机制,通过挖掘信贷企业电表、水表、工资表等诸多信息,辨识出反常动向,依照现金流与上下游交易数据拓展对反常动向成因分析的深度性,特殊情况可通过自觉退离、调控抵押物等形式降低风险等级。
5.3 处置不良资产
例如,在处置人员案头分析过程中,需要通过多种渠道采集和债务人相关的基本信息,常规方法是于数个系统内逐一搜查。可以从企业内部系统探查信息,而诉讼与实施信息可以从法院系统内捕获,行中数据库是查找信息的主要渠道。以上信息来源渠道繁多,并且需要符合某些条件后方可捕获一些信息源,耗用大量的人力与时间资源。而大数据系统能深度挖掘数个数据库,并建设其间的关联性,这样相关人员就能在一个界面上快捷、精确的查询到以上所有数据源,明显降低了工作人员的作业量。
6 结语
知识图谱将多个类别的信息衔接为一而产出的关系网络,其提供站在实体“关系”视角去解读问题的能力,在阐述客观环境中不同实体之间相关性的基础上,还能为用户群体提供更多有实用价值的检索结果。该文在大数据技术的支配下,以数据建设关联图谱为支撑建设了资产关联模型,该模型对信息运维管理、完善网络过程均有一定促进作用,值得推广。
