多异构社交网络的全局建模及应用例证
2020-12-18王艺霖仲兆满樊继冬
王艺霖,仲兆满,樊继冬,管 燕
(1.江苏海洋大学海洋科学与水产学院,连云港,222005;2.江苏海洋大学计算机工程学院,连云港,222005;3.江苏省海洋资源开发研究院(连云港),连云港,222005)
引 言
诸多媒体包含了大量的用户及用户创造的内容,包括Facebook、Twitter、MySpace、LinkedIn、Google+、微博、人人网、论坛、贴吧以及微信等,这类媒体被称为在线社交网络(Online social net‑works,OSNs)。单个社交网络包含了不同类型的实体以及实体之间建立了不同的关联,是典型的异构社交网络,即网络上的实体或者关系是多类型的。在单异构社交网络的基础上,多个社交网络通过某些实体产生关联,比如用户账户、发表的信息等,这样多个社交网络又建立了更加复杂的网络结构。Bartunov 等[1]的研究表明,约有84%的互联网用户拥有多于一个的社交网站账户。2015 年,Global Web Index 面向50 个社交媒体的调研发现,每个人平均拥有5.54 个账号,经常活跃在2.82 个社交网络上。由于社交网络信息传播性强,具有复杂网络的结构特征,内部蕴含了丰富的潜在有价值信息,近几年引起了学术界和产业界的高度重视。跨多个社交网络的研究可以有效连接不同社交网络的独立异构数据,实现网络的深层融合和数据的综合利用。在多异构社交网络的研究过程中,以用户为中心的分析方法相对充分,尤其是同一自然人在多个社交网络的对齐关联。因为人们更多地关注了用户在多个社交网络的社交圈子、社交行为、生活习惯和兴趣爱好,在兴趣推荐、社区发现以及特殊人员监控等领域有着广泛的应用价值。
1 相关工作
1.1 单异构社交网络表示模型
异构社交网络是指网络中包含了不同的实体以及实体之间形成了不同的关系。因此,单异构社交网络的表示模型多是围绕网络中的对象及其关系加以描述。根据单异构社交网络表示模型包含的要素个数,可分为二元组、三元组以及多元组等模型。二元组是对社交网络的节点及其关系的直观抽象描述形式。Yang 等[2]在研究社交推荐系统的协同过滤时,提出的社交网络模型为有向图G=(U,F),U是用户集合,F是朋友链接集合。Chen 等[3]面向问答型社交网络,将网络描述为一个由用户、问题及类别3 种节点,用户之间、用户与问题之间、问题与类别之间3 种联系边的异构网络。Seo 等[4]定义的异构信息网络为二元组G={V,E},V是信息对象,E是信息对象之间的关系。
有些研究者对社交网络的节点和边进行了细分,或者为边添加了权重,进而形成了异构社交网络的 三 元 组 表 示 模 型 。 Li 等[5]定 义 社 交 网 络 为 三 元 组 SNL=
针对特定研究目标,一些研究者进一步对社交网络的对象进行了更精细化的描述,由此形成了包含了 4 个要素以上的多元组表示模型。Vu 等[13]在总结了 Facebook、Twitter、LinkedIn 及 Google+等媒体特点的基础上,定义了社交网络模型的5 个主要维度,分别是包含了用户名、描述、城市、E‑mail、性别和地点的用户背景,用户之间建立的朋友关系,包含了用户的群组、用户兴趣以及用户发表的帖子。Kundu 等[14]提出了模糊粒社交网络的概念FGSN,融合了粒计算理论和模糊邻居系统,将有向的社交网络表示为四元组S=(C,V,GIN,GOUT),其中V是网络中的节点,C⊆V是粒表示的有限集,GIN是入度关系的有限集,GOUT是出度关系的有限集。已有的社交网络表示模型将个体作为活动节点,但FG‑SN 可以从不同的粒度出发重新定义节点,比如将一些个体形成的群体作为活动节点。吴奇等[15]将社交网络描述为五元组G=
1.2 多异构社交网络表示模型
由于单个异构社交网络包含的信息量有限,面向多个异构社交网络的融合问题是近期研究的热点。在单一的社交网络的表示模型基础上,已有的融合多个异构社交媒体的研究多是以围绕用户的对齐关联展开的。
Kong 等[17]首 先 提 出 了 以 用 户 为 中 心 的 多 个 社 交 网 络 对 齐 的 概 念 ,g=((G1,G2,…,Gn),(A1,2,A1,3,…,A1,n,A2,3,…,A(n-1),n)),其中,Gi=(Vi,Ei)(i∈{1,2,…,n})是单一的包含了各种类型节点和链接的社交网络,Ai,j是Gi和Gj锚链接集合。如果Gi和Gj的所有用户都存在锚链接,Gi和Gj是全对齐,否则,Gi和Gj是部分对齐。现实中的社交网络用户之间多是部分对齐。Zhan 等[18]选取了Four‑square 和Twitter 进行了跨社交媒体的链接预测的研究。在借鉴文献[17]定义的社交网络对齐概念的基础上,将社交网络的节点和边细化为G=({U∪L∪W∪T},{Eu,u∪Eu,l∪Eu,w∪Eu,t}),其中U、L、W和T分别是用户集、地点集、文本集和时间戳集,Eu,u、Eu,l、Eu,w和Eu,t分别为用户链接集、地点链接集、文本链接集和时间戳链接集。通过采集用户在Foursquare 主页上的Twitter 账号,使得用户在两个平台上的信息对齐。Buccafurri 等[19]定义了社交互联网络图为G=
Shi 等[25]系统地论述了当前异构网络分析的现状和存在的不足,指出需要进一步研究的方向包括不同异构网络信息的融合、实体间关系的清晰梳理、面向不同应用的异构网络挖掘方法等。
1.3 存在的问题
已有社交网络表示模型的研究存在的问题概述如下:
(1)对单社交网络而言,表示模型仍然以包含了节点和边的二元组、三元组为主,部分研究者根据不同社交网络的特点,对节点和边进行了一定的细化分析,进而形成了包含4 个要素以上的多元组表示模型。已有研究多是面向特定的目标而构建社交网络表示模型,在研究目标的约束下,构建的表示模型多是为特定研究内容服务,没能根据社交媒体具有的宏观和微观特点进一步揭示其包含的各种复杂实体和联系。
(2)对多社交网络的融合而言,同一自然人在不同社交网络的账号对齐关联是研究重点,因此面向多个社交网络构建的表示模型也受限于此。跳出研究目标的约束,系统地梳理不同社交网络的内在本质联系,面向各种类型社交媒体的全局建模方法还没有文献提及。
2 多异构社交网络全局建模
基于OSNs 的用户空间、内容空间的关联以及不同OSNs 之间的分类关系,在理清每个OSN 包含的节点及其关系的基础上,给出的多异构社交网络(Multi‑heterogeneous social networks,MHSN)的全局表示模型如图1 所示。MHSN 从纵向和横向两个角度刻画了多个社交网络OSNs 的关联关系。显然,用户及内容在不同OSNs 的关联与传播,构建了更加复杂的多异构社交网络。多异构社交网络MHSN 全局表示模型描述如下:
(1)多异构社交网络表示为MHSN=(G,R),其中G表示不同社交网络类OSN 和实例osn 集合,R表示不同OSNs 建立关联关系的集合;
(2)最高层 OSNs 类表示为 OSNs=(US,CS,RUU,RCC,RUC,T),以用户空间US和内容空间CS为实体类型,进而在用户之间、内容之间及用户和内容之间形成了3 种关系RUU、RCC和RUC,以时间戳集合T刻画OSNs 类的动态特性;
(3)不同的OSNs 类之间通过继承形成了分类关系,ER={(OSNiExtend OSNj)|OSNi,OSNj∈G,i≠j};
(4)社交网络OSNi,OSNj通过用户的对齐形成了关联关系,UR={(u1Alignu2)|u1∈ OSNi,u2∈ OSNj,i≠j},u1,u2是同一自然人在不同社交媒体的账号描述;
(5)社交网络 OSNi,OSNj通过内容的对齐形成了关联关系,CR={(c1Alignc2)|c1∈ OSNi,c2∈ OSNj,i≠j},c1,c2是同一信息内容在不同社交媒体的呈现描述;
(6) 社 交 网 络 类 OSNi通 过 实 例 化 生 成 具 体 的 社 交 网 络 实 例 osni,OR={(osnijObject OSNi)|OSNigenerates object osnij,OSNi,osnij∈G}。
每个社交网络都包含了复杂的实体及其关系。比如,Twitter 包含用户和tweets 两种实体,用户与tweet 之间存在发表、回复、转发和点赞关系,tweets 之间可以建立回复和转发关系,用户之间可以直接建立关注关系,并通过tweet 建立用户间的回复和转发关系。又如,百度贴吧包括贴吧、帖子和用户实体,用户与帖子之间存在发表、回复和收藏关系,帖子之间可以建立回复关系,用户之间可以直接建立关注关系,并通过帖子建立用户间的回复关系。同一用户在不同社交媒体上有不同的表现形式,但对应的都是同一自然人。基于MHSN 用户空间的关联,可以分析多个OSNs 上用户的社交行为和影响力,可以进行全面的用户画像描述。图2 是同一真实用户在多个不同社交媒体的对齐关联示例。
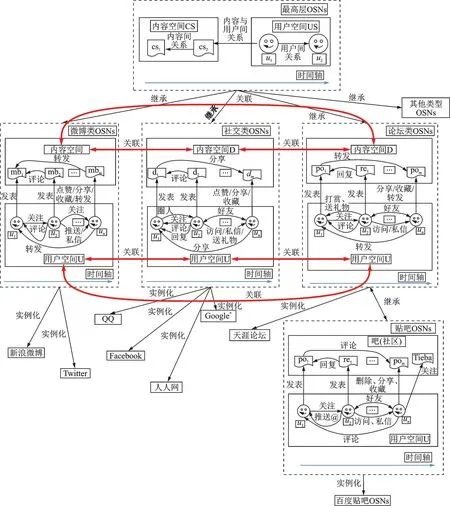
图1 多异构社交网络MHSN 全局表示模型Fig.1 Global representation model of multiple heterogeneous social networks
网络上的内容在不同社交媒体的呈现有两种模式:一种是显式的,指同一篇信息在不同网络上的传播,比如新浪媒体发表的一篇新闻在贴吧、微博中以转发的形式进行传播;另一种是隐式的,指对同一内容的描述采用了不同的表达方式,比如不同用户对同一突发事件从不同侧面进行了描述和分析,各个内容是独立的,但又内在关联到了同一突发事件。不同的社交媒体产生的内容有所差异,总体上包括文本、图片和音视频等类型。基于MHSN 内容空间的关联,可以分析信息在不同OSNs 上关联的用户数,阅读、评论及转发数,进而可以全面地计算信息的影响力、热度值等。图3 是社交媒体显式内容对齐关联示例。
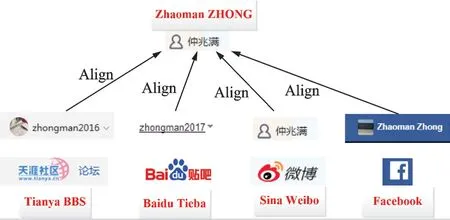
图2 MHSN 用户对齐关联示例Fig.2 User alignment association example of MHSN
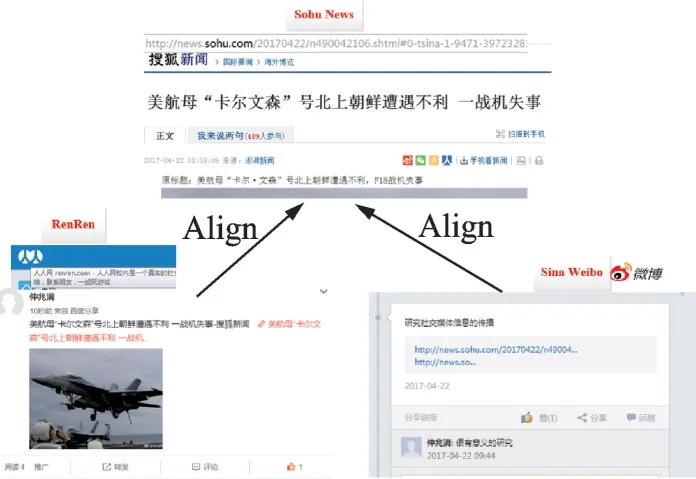
图3 MHSN 显式内容的对齐关联示例Fig.3 Explicit content alignment association ex‑ample of MHSN
3 多异构社交网络表示模型应用例证
本文选取基于异构社交网络的内容空间关联(突发事件检测)及用户空间关联(用户兴趣挖掘)的两个应用场景,阐述多异构社交网络全局建模的应用策略。
3.1 基于MHSN 的地域突发事件检测
3.1.1 多异构社交网络突发事件检测融合策略
本文使用的社交网络地域突发事件检测如定义1 所述。
定义1[26]地域Top‑k突发事件,形式化描述为一个三元组:LEE=(l,t,E),l表示地域,t表示时间段,E表示 Top‑k个突发事件集合,E={e1,e2,…,ek},ei={kw1,kw2,…,kwn}。从语义上讲,地域 Top‑k突发事件指地域l在时间段t发生的,产生较大影响的k个事件。多个社交网络的内容空间融合问题可以简化为两两社交网络的内容融合。基于内容空间的社交网络SN1、SN2突发事件检测融合策略如图4所示。从自上而下的角度看,单异构社交媒体的突发事件检测包含3 个核心步骤,可以完成各自的突发事件检测任务。从水平的方向看,两个异构社交媒体突发事件检测可以有3 种融合策略,分别是信息融合、突发词融合和突发词簇融合,不同的融合策略对突发事件检测效果的影响见3.1.4 小节结果对比部分。
基于内容空间的社交网络SN1、SN2突发事件检测融合策略描述如下:
(1)融合策略 1(信息融合)。假设SN1、SN2采集的信息集合分别为DS‑SN1、DS‑SN2,将DS‑SN1、DS‑SN2合并为一个信息集合DS‑SN。从信息集合DS‑SN计算得到突发词集为EW,后续可看作是基于同一社交网络的突发词聚类、词簇热度计算和Top‑k 突发事件排序输出。
(2)融合策略 2(突发词融合)。假设SN1、SN2计算得到的突发词集合分别为EW1、EW2,将EW1、EW2合并为一个突发词集EW。由于不同的社交媒体用户的活跃度不同,导致信息量、阅读数和关联用户等有较大差异,不能简单地根据计算的指标值直接排序选取,需要分别对EW1和EW2中的词突发值进行归一化处理,选取m个词构成突发词集合为EW,后续可基于EW进行聚类、词簇热度计算,进而排序得到Top‑k突发事件。
(3)融合策略3(突发词簇融合)。假设SN1、SN2计算得到的突发词簇集合分别为EWC1、EWC2,将EWC1、EWC2合并为一个突发词簇集EWC。在融合的过程中,需要计算两个词簇的相似度,达到一定阈值两个词簇应合并在一起,形成一个词簇。两个词簇ewci、ewcj相似度计算方法采用Jaccard 相似系数,有
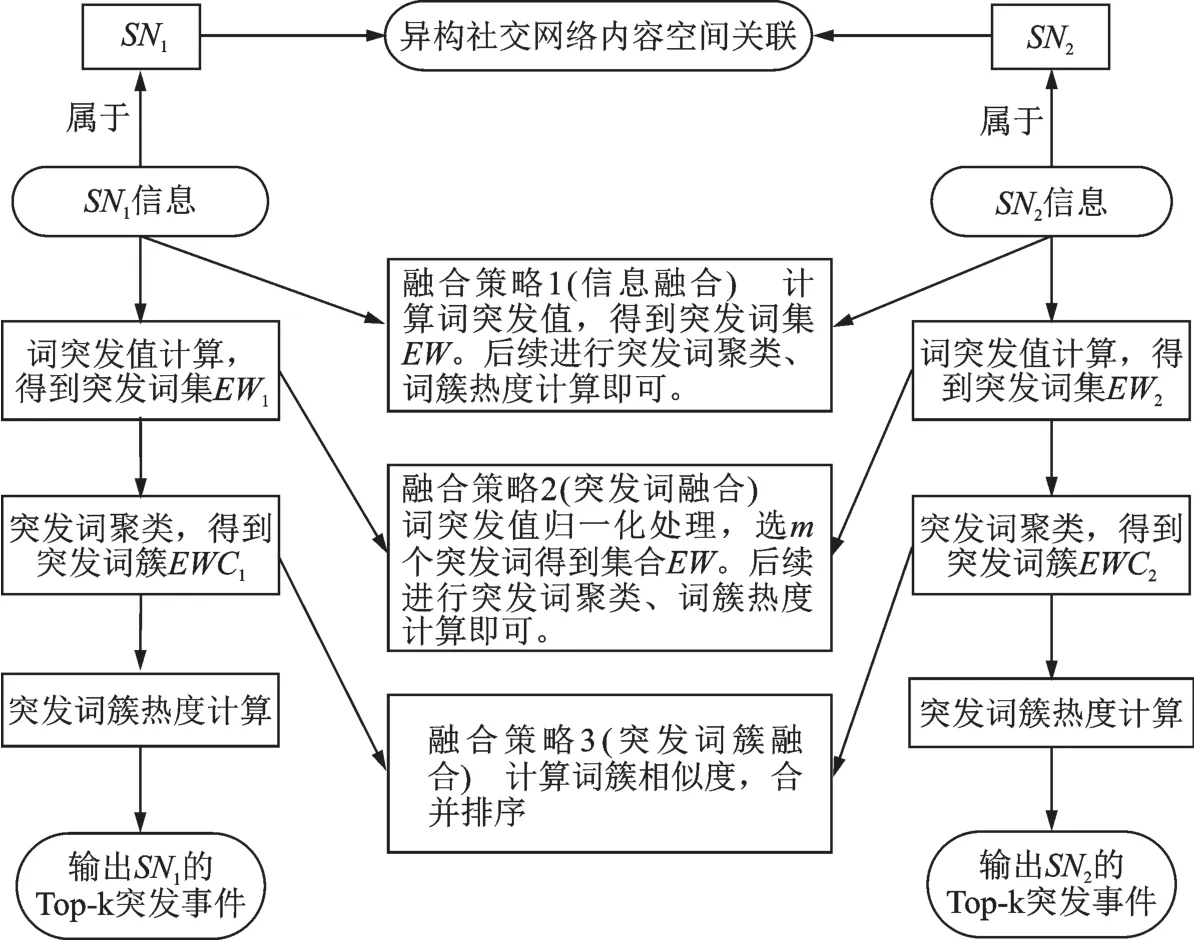
图4 基于内容空间的突发事件检测融合策略Fig.4 Emergency detection and fusion strategy based on content space
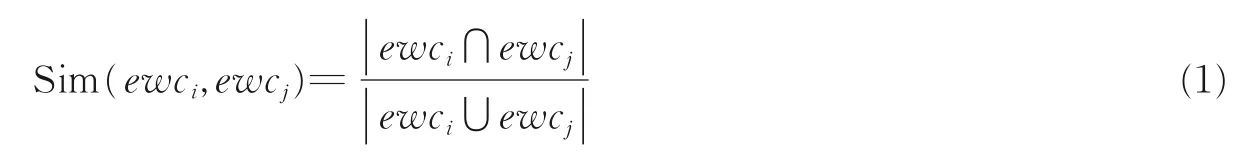
实验验证,当Sim(ewci,ewcj)≥0.6 时,两个词簇进行合并效果较好。
3.1.2 单异构微博网络的地域突发事件检测方法
2018 年,面向单异构微博社交网络,本文研究提出了地域Top‑k突发事件检测方法,简记为LocBED‑WB,详见文献[26]。该研究内容包含3 个核心步骤,简介如下:
(1)词突发值计算
词wi在k时间段的突发值为
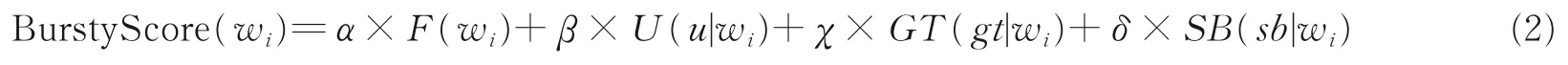
式中:F(wi)、U(wi)、GT(wi)、SB(wi)分别为词wi的频率突发性、用户突发性、地域突发性和社交行为突发性;α、β、χ、δ为权重系数,α+β+χ+δ=1,α≥ 0,β≥ 0,χ≥ 0,δ≥ 0。在实际应用中,可以根据社交网络的特点,对上述指标进行删减。计算得到每个词的突发值后,使用四分差选出m个突发特征词,按照词突发值进行降序排序,得到突发特征词集EW。
(2)突发词聚类
基于突发特征集EW,构建突发词关联网络EWN=(V,E),V是突发词集EW,E表示突发词之间的关联强度。突发词ewi、ewj关联强度是统计两个词在同一篇信息中共现的次数。突发词网络EWN构建完成后,使用开源的CLUTO 工具包对EWN进行聚类,获取突发词簇EWC={ewc1,ewc2,…,ewcq},假设有q个词簇。
(3)突发词簇热度计算
词簇ewci的热度值为
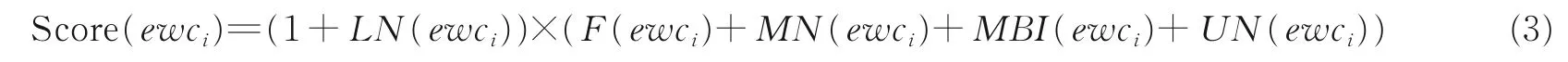
式中LN(ewci)、F(ewci)、MN(ewci)、MBI(ewci)、UN(ewci)分别为词簇ewci的地域、频率、关联博文、关联博文影响力和关联用户指标。
3.1.3 实验数据及评测指标
新浪微博数据集BEWeiboDS 为采集北京、南京两个大城市的 2016 年 12 月 1 日—12 月 30 日的带有地理标签的博文,采集连云港和日照两个中小规模城 市 2016 年 5 月 1 日 —10 月 31 日的带有地理标签的博文,形成微博数据集BEWeiboDS。百度贴吧数据集BETiebaDS 为采集北京、南京两个大城市的 2016 年 12 月 1 日—12 月 30 日的贴吧内容,采集连云港和日照两个中小规模城市2016年5 月1 日—10 月31 日的贴吧内容,每个市包括了区县级以上的贴吧,形成百度贴吧数据集BE‑TiebaDS。两个社交网络数据集的情况如表1所示。
采用精准率P@n作为评测指标。P@n是一个拟人化的指标,目前在搜索评测中用的较多。突发事件检测类似于从给定的批量信息中搜索挖掘出密切相关的地域突发事件。P@n指标关心的是返回的n个结果中,是否存在相关的信息,不考虑返回信息相关性的顺序。P@n=m/n,其中n指返回的突发事件个数,m指人工判断后符合突发事件检测结果的个数。由于Top‑k突发事件检测返回的事件数量很少,人工参与评测工作量并不大。
3.1.4 结果对比
本文使用5 种方法基于新浪微博数据集BEWeiboDS 和百度贴吧数据集BETiebaDS 进行突发事件检测对比。5 种方法简介如下。(1)方法1(LocBED‑WB):使用单异构社交网络新浪微博数据集BE‑WeiboDS,使用3.1.2 小节介绍的方法进行突发事件检测,具体方法详见文献[26]。(2)方法2(LocBED‑TB):使用单异构社交网络百度贴吧数据集BETiebaDS,使用3.1.2 小节介绍的方法进行突发事件检测。(3)方法 3(LocBED‑WB&TB‑BW):使用两个异构社交网络新浪微博数据集 BEWeiboDS 和百度贴吧数据集BETiebaDS,在突发词计算层面进行融合,然后进行突发事件检测。(4)方法4(LocBED‑WB&TB‑BWC):使用两个异构社交网络新浪微博数据集BEWeiboDS 和百度贴吧数据集BETiebaDS,在突发词聚类层面进行融合,然后进行突发事件检测。(5)方法5(LocBED‑WB&TB‑BEH):使用两个异构社交网络新浪微博数据集BEWeiboDS 和百度贴吧数据集BETiebaDS,在突发词簇热度计算层面进行融合,然后进行突发事件检测。
5 种方法使用两个社交网络数据集,在P@1、P@2、P@3、P@4、P@5 和 Average 的评测指标结果如表2 所示。
如表2 所示,单独使用新浪微博数据集,方法LocBED‑WB 的平均准确率为0.79,精准率已经比较高了,说明单独使用新浪微博进行突发事件检测的优势。单独使用百度贴吧数据集,方法LocBED‑TB的平均准确率为0.56,精准率比较低,一方面百度贴吧活跃用户数相对少,发表的信息量偏少,另外贴吧发表的帖子没有地理标签的标记,检测的很多突发事件多是广域突发事件,地域特征型不强。使用两个社交网络,从3 个层面进行融合检测突发事件,第3 种融合策略,即突发词簇热度计算融合的方法,效果最理想,准确率达到0.84,比单独使用新浪微博数据集的方法LocBED‑WB 提高了0.05,比单独使用百度贴吧数据集的方法LocBED‑TB 提高了0.28。
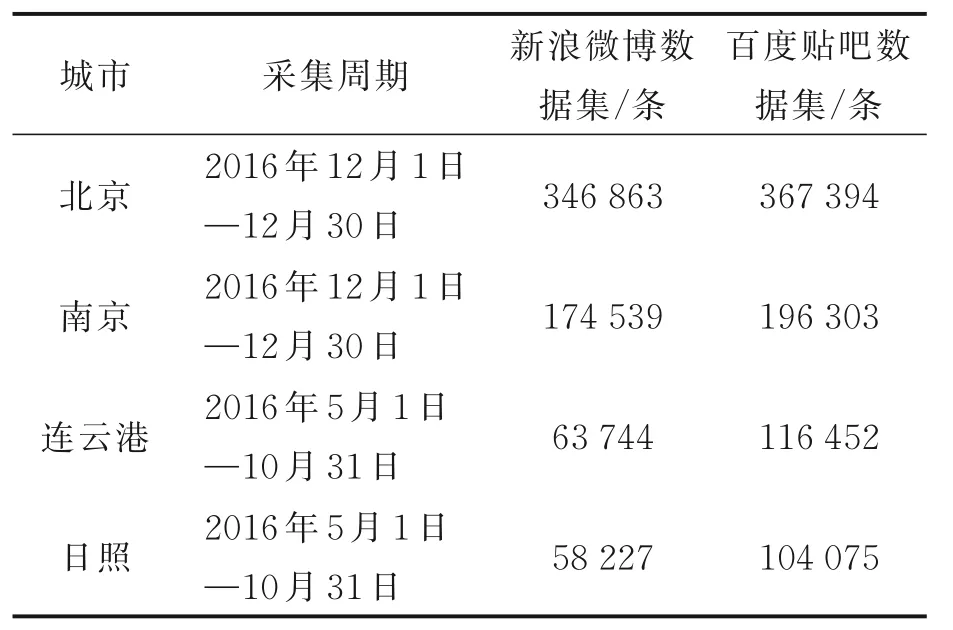
表1 突发事件检测的两个数据集Table 1 Two data sets for emergency detection
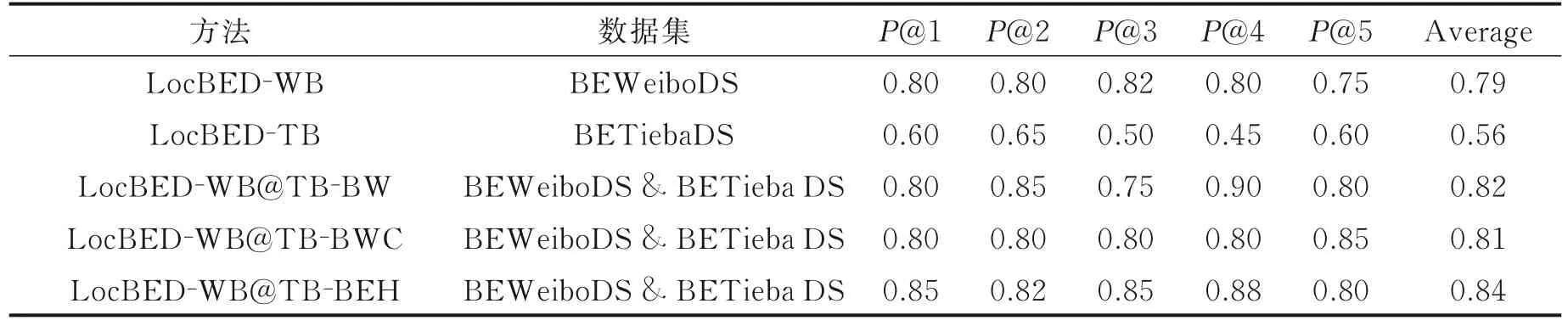
表2 5 个评测指标检测结果Table 2 Detection results of five evaluation indicators
3.2 基于MHSN 的用户兴趣挖掘
3.2.1 多异构社交网络用户兴趣挖掘融合策略
本文使用的社交网络用户兴趣表示模型如定义2 和3 所述。
定义2[16]用户静态兴趣是指从用户背景中挖掘出的兴趣点,UI={Int1,Int2,…,Intm},每个兴趣点是一个二元组Inti=(kwi,wi),kwi为关键词;wi为用户对kwi的喜好权重。
定义3用户动态兴趣是指从用户生成中挖掘出的随时间变化而变化的兴趣点,UI={Int1,Int2,…,Intm},每个兴趣点为一个三元组Inti=(topici,wi,T),其中,topici是由多个关键词组成的话题;wi为用户对topici的喜好权重;T={t1,t2,…,ts},ti为用户讨论话题 topici的各个时间点,即话题在不同时间点的分布情况。
同样,多个社交网络的用户空间融合问题可以简化为两两社交网络的用户融合。两个社交网络SN1、SN2在挖掘用户兴趣时,用户的静态兴趣可以从简介、标签和职位等背景信息方面融合,用户的动态兴趣可以从用户生成的内容方面进行融合。基于用户空间的社交网络SN1、SN2用户兴趣挖掘融合策略如图5 所示。单异构社交网络的用户兴趣挖掘分为静态兴趣和动态兴趣两类,使用社交网络上用户的背景和内容信息,可以完成各自的兴趣挖掘任务。对两个社交网络SN1、SN2而言,静态兴趣和动态兴趣挖掘都有两种融合策略,分别是背景和生成内容的融合,以及静态兴趣和动态兴趣的融合。不同的融合策略对用户兴趣挖掘效果的影响见3.2.4 小节结果对比部分。
基于用户空间的社交网络SN1、SN2用户兴趣挖掘融合策略描述如下:
(1)融合策略1(背景和生成内容的融合)。假设SN1、SN2用户的背景信息分别为profile1、profile2,SN1、SN2用户的生成内容分别为 content1、content2,将 profile1、profile2合并为一个背景信息 profile,将content1、content2合并为一个生成内容content。后续分别从profile 和content 中挖掘用户的静态兴趣和动态兴趣。
(2)融合策略2(静态兴趣和动态兴趣的融合)。假设SN1、SN2用户的静态兴趣分别为SN1‑SI、SN2‑SI,SN1、SN2用户的动态兴趣分别为SN1‑DI、SN2‑DI,将SN1‑SI、SN2‑SI合并为SN‑SI,将SN1‑DI、SN2‑DI合并为SN‑DI。在融合用户动态兴趣时,需要计算兴趣点的相似度,然后调整权重W和时间点T的 分 布 ,SN1、SN2用 户 的 一 个 兴 趣 点 分 别 记 为SN1‑DI‑Inti={topici,Wi,Ti}、SN2‑DI‑Intj={topicj,Wj,Tj},用户兴趣点相似度计算使用 Jaccard 相似系数,有
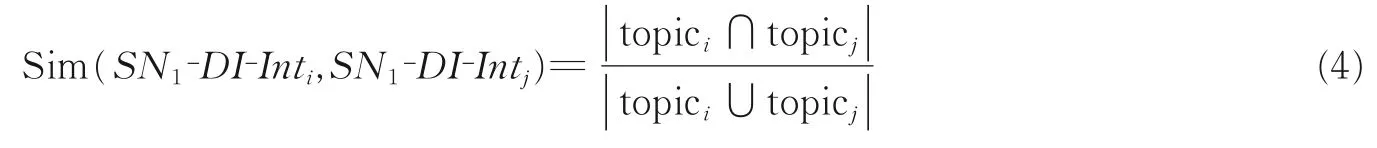
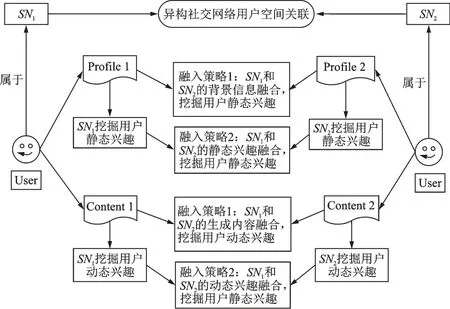
图5 基于用户空间的用户兴趣挖掘融合策略Fig.5 User interest mining and fusion strategy based on user space
实验验证,当 Sim(SN1‑DI‑Inti,SN1‑DI‑Intj)≥ 0.6 时,两个兴趣点合并效果较好。
3.2.2 单异构微博网络的用户兴趣挖掘方法
2017 年,作者提出了面向微博的用户兴趣静态和动态兴趣挖掘方法,简记为USDInt‑WB,详见文献[16]。该研究内容包含3 个核心步骤,简介如下:
(1)用户静态兴趣挖掘。挖掘新浪微博用户的简介、标签和职位等背景信息,得到用户的静态兴趣为 USInt={(kw1,w1),(kw2,w2),…,(kwm,wm)}。
(2)用户动态兴趣挖掘。挖掘用户原创、转发和评论等方式的微博,得到用户的动态兴趣为UDInt={(topic1,w1,T1),(topic2,w2,T2),…,(topicm,wm,Tm)}。
(3)用户兴趣相似度计算。两个用户兴趣相似度整合,有
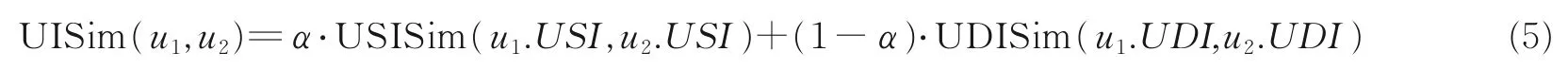
式中α是静态兴趣和动态兴趣权重系数,0≤α≤1。
用户u1,u2的静态兴趣相似度计算使用Jaccard 方式。用户u1,u2的动态兴趣中的两个兴趣点Inti,In⁃tj的相似度计算公式为
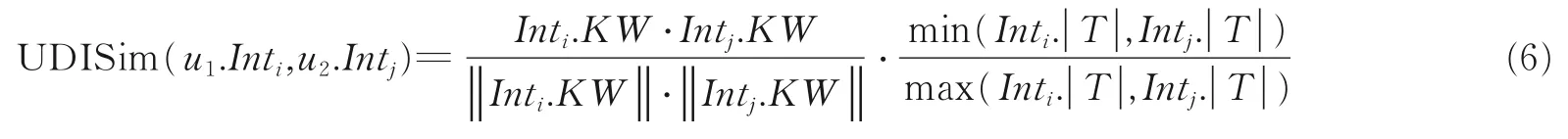
式中综合考虑了用户兴趣点内容的相似度和兴趣点的时间周期。
3.2.3 实验数据及评测指标
本文的研究内容没有涉及不同用户在跨社交媒体的对齐关联方法。因此人工选取了100 个用户,已知他们在新浪微博和百度贴吧的账号,然后从两个社交媒体中融合挖掘用户兴趣进行实验分析。对于100 个用户,采用滚雪球的方式分别采集其关注和粉丝用户共计2 层,即采集到了用户u1关注的关注集和粉丝的粉丝集。对于采集的用户,分别从新浪微博和百度贴吧采集用户背景和生成内容信息,每个用户的背景信息合并为1 条,得到的新浪微博数据集UserWeiboDS 和百度贴吧数据集UserTiebaDS情况如表3 所示。

表3 用户兴趣挖掘的两个数据集Table 3 Two data sets of user interest mining
新浪微博数据集中用户u1的关注集记为u1.follower,作为标准答案。通过方法method1计算用户间的兴趣相似度选取出的关注集记为u1.follower‑method1,令 |u1.follower|=|u1.follower‑method1|,方法method1选取关注的准确率计算公式为

3.2.4 结果对比
本文使用4 种方法基于新浪微博数据集UserWeiboDS 和百度贴吧数据集UserTiebaDS 进行用户兴趣挖掘对比。4 种方法简介如下。(1)方法1(USDInt‑WB):使用单异构社交网络新浪微博数据集UserWeiboDS,使用 3.2.2 小节介绍的方法挖掘用户兴趣,具体方法详见文献[16]。(2)方法 2(USDInt‑TB):使用单异构社交网络百度贴吧数据集UserTiebaDS,使用3.2.2 小节介绍的方法进行用户兴趣挖掘。(3)方法 3(USDInt‑WB&TB‑PC):使用两个异构社交网络新浪微博数据集 UserWeiboDS 和百度贴吧数据集UserTiebaDS,在背景和生成内容层面融合,然后挖掘用户兴趣。(4)方法4(USDInt‑WB&TB‑SD):使用两个异构社交网络新浪微博数据集UserWeiboDS 和百度贴吧数据集UserTiebaDS,在静态和动态兴趣层面融合,然后挖掘用户兴趣。4 种方法使用两个社交网络数据集,在RUA 指标的评测结果如表4 所示。单独使用UserWeiboDS,方法USDInt‑WB 推荐用户准确率RUA 为0.61,说明单独使用新浪微博挖掘用户兴趣进行关注用户推荐已经比较准确。单独使用UserTiebaDS,方法USDInt‑TB 推荐用户准确率为0.37,准确率比较低,主要原因是百度贴吧中,用户往往对特定的贴吧感兴趣,用户之间的关注关系相对较少,不像新浪微博用户之间构建了丰富的社交关系。使用两个社交网络,从两个层面进行融合挖掘用户兴趣,第2 种融合策略,即在静态和动态兴趣层面融合,效果最理想,推荐用户准确率达到0.69。比单独使用新浪微博数据集的方法USDInt‑WB 提高了0.08,比单独使用百度贴吧数据集的方法USDInt‑TB 提高了0.32,比使用第1 种融合策略提高了0.04。

表4 RUA 指标的评测结果Table 4 Evaluation results of RUA indicators
4 结束语
本文在社交网络的用户空间和内容空间关联、不同OSNs 的分类关系的基础上,给出了多异构社交网络的全局表示模型,为面向多异构社交网络的后续研究提供参考。选取多异构社会网络的地域突发事件检测、用户兴趣挖掘两个应用场景,阐述了基于内容空间和用户空间的多异构社会网络的融合策略。以新浪微博和百度贴吧两大社交网络,进行了实验对比和分析。还需进一步提升的研究内容:(1)基于多异构社交网络的不同应用场景的抽象分析,以期为多异构社交网络的实际应用提供借鉴;(2)扩大社交网络分析的范围,选取主流的社交网络,进行更大规模的数据采集和分析;(3)基于隐式内容空间的社交媒体关联分析,使用自然语言处理、社交网络分析等技术,挖掘隐式内容在多异构社交网络的关联,进而实现突发事件、热点信息等的精准挖掘。
