基于标签迁移和深度学习的跨语言实体抽取研究
2020-12-17余传明黄婷婷林虹君安璐
余传明 黄婷婷 林虹君 安璐

收稿日期:2020-05-31
基金项目:国家自然科学基金面上项目“面向跨语言观点摘要的领域知识表示与融合模型研究”(项目编号:71974202)。
作者簡介:余传明(1978-),男,教授,研究方向:数据挖掘、商务智能与信息检索。黄婷婷(1995-),女,硕士研究生,研究方向:数据挖掘与信息检索。林虹君(1995-),女,硕士研究生,研究方向:数据挖掘与信息检索。安璐(1979-),女,教授,研究方向:可视化知识发现。
摘 要:[目的/意义]从跨语言视角探究如何更好地解决低资源语言的实体抽取问题。[方法/过程]以英语为源语言,西班牙语和荷兰语为目标语言,借助迁移学习和深度学习的思想,提出一种结合自学习和GRU-LSTM-CRF网络的无监督跨语言实体抽取方法。[结果/结论]与有监督的跨语言实体抽取方法相比,本文提出的无监督跨语言实体抽取方法可以取得更好的效果,在西班牙语上,F1值为0.6419,在荷兰语上,F1值为0.6557。利用跨语言知识在源语言和目标语言间建立桥梁,提升低资源语言实体抽取的效果。
关键词:知识获取;实体抽取;跨语言;深度学习;标签映射
DOI:10.3969/j.issn.1008-0821.2020.12.001
〔中图分类号〕TP391 〔文献标识码〕A 〔文章编号〕1008-0821(2020)12-0003-14
Research on Cross-lingual Entity Extraction Based on
Tag Transfer and Deep Learning
Yu Chuanming1 Huang Tingting2 Lin Hongjun1 An Lu3
(1.School of Information and Safety Engineering,Zhongnan University of Economics and Law,
Wuhan 430073,China;
2.School of Statistics and Mathematics,Zhongnan University of Economics and Law,Wuhan 430073,China;
3.School of Information Management,Wuhan University,Wuhan 430072,China)
Abstract:[Purpose/Significance]This paper explores how to better solve the entity extraction problem of low resource languages from a cross-lingual perspective.[Method/Process]With English as the source language,Spanish and Dutch as the target language,an unsupervised cross-lingual entity extraction method combining self-learning method and GRU-LSTM-CRF network is proposed based on the idea of transfer learning and deep learning.[Result/Conclusion]Compared with the supervised cross-lingual entity extraction method,the unsupervised cross-lingual entity extraction method proposed in this paper can achieve better results.In Spanish,the value of F1 is 0.6419,and in Dutch,the value of F1 is 0.6557.Cross-lingual knowledge is used to build a bridge between source language and target language to improve the effect of entity extraction of low-resource languages.
Key words:knowledge acquisition;entity extraction;cross-lingual;deep learning;label mapping
实体抽取(Entity Extraction,EE),又称为命名实体识别(Name Entity Recognition,NER),是指识别文本中具有特定意义的实体[1],包括人名[2]、地名[3]、机构名[4]和专有名词[5-7]等。实体抽取在信息抽取的总体任务中起着至关重要的作用,有效识别命名实体,不仅是关系抽取[8-9]和构建知识图谱[10]的基础,而且可以显著提高问答系统[11]和文本挖掘[12]等应用的性能。随着大数据的迅速发展,各种语料在不同语言中的分散化和多样化日益严峻,跨语言情境下的实体抽取任务受到越来越多的关注。实体抽取任务在中文和英文等语言情境中,存在较为丰富的标注语料,与此相关的实体抽取模型相对简单;而在阿拉伯语和维吾尔语等语言情境中,标注语料相对稀缺,存在标签语料很少和手工标注标签昂贵且费时等问题,与此相关的实体抽取模型相对复杂,面临更多挑战。在标注语料丰富的源语言和标注语料稀缺的目标语言之间建立桥梁,将源语言的标签数据迁移给目标语言,以丰富目标语言的标签数据,通过建立跨语言的命名实体识别模型,提升低资源语言实体识别模型的效果,成为一个亟待解决的研究问题。
机器翻译研究的发展在一定程度上缓解了目标语言语料稀缺的问题,但采用机器翻译来解决跨语言实体抽取仍面临一些挑战。首先,在源语言翻译成目标语言的过程中,即便在机器翻译达到很高准确率(即源语言文本与目标语言文本具有很好的语义一致性)的情况下,由于在目标语言中词汇语序被调整,且存在对源语言词汇进行拆分(源语言词汇与目标语言词汇之间为一对多的关系)或合并(源语言词汇与目标语言词汇之间为多对一的关系)的情况,很难准确地建立词汇标签(如B、I、O等)从源语言到目标语言之间的一一对应关系,如何在机器翻译基础上自动化地构建目标语言的语料标签仍然是一个严峻的问题。其次,目前应用较为广泛的免费在线翻译系统(如谷歌和百度翻译等)并不支持所有语言,针对稀缺资源语种(如蒙古语和维吾尔语等),如何在没有机器翻译的情况下自动化地构建目标语言的文本(并在此基础上自动化地构建标签)也是一大挑战。
为解决上述问题,本文将自动化的双语词典构建应用到跨语言实体抽取任务中,利用迁移学习和深度学习的思想,开展跨语言实体抽取的实证研究。
1 相关研究现状
1.1 实体抽取的传统模型
实体抽取的传统模型包括早期基于规则的方法、统计机器学习的方法以及近年来基于深度学习的方法,其效果不断得以提升。
1.1.1 基于规则的实体抽取
基于规则的实体抽取方法是指人工构造规则或者借助机器自动生成规则,然后从文本中找出匹配规则的字符串。为了解决乌尔都语实体标注语料稀缺的问题,Riaz K[13]提出一种基于规则的命名实体识别方法,首先从Becker-Riaz语料库中选取200篇文档,人工为时间、地名、机构名等6个实体标签制定规则;并选出2 262篇文档进行实验,该方法的召回率为90.7%,准确率为91.5%,F1值为91.1%。由于人工构造规则需要消耗较多的人力和物力,所以研究者們尝试借助机器自动生成规则的方法。Collins M等[14]先构造种子规则,再根据语料对该种子规则进行无监督的训练迭代得到更多的规则,将这些规则用于实体抽取,该方法在人名、地名和机构名3种实体抽取任务中取得很好的效果。周昆[15]提出一种基于规则匹配的命名实体识别方法,首先,将中文人名、知识按照不同类别和不同层次进行组织,可提高知识库的可维护性;然后分别制定20种人名识别规则和9种地名识别规则;最后构建具有自主学习能力的实体识别系统,能在识别实体的基础上,产生新的规则反馈给规则库,该方法有效提高了实体抽取的准确率和召回率。基于规则的实体抽取方法在小规模语料库上,训练速度快且模型效果好,但需要制定大量的规则,导致该类方法的可移植性较差。
1.1.2 基于统计机器学习的实体抽取
在基于统计机器的方法中,实体抽取被视为序列标注问题。序列标注问题中当前的预测标签不仅与当前的输入特征相关,还与之前的预测标签相关,预测标签序列之间具有强相互依赖关系。目前常用的统计机器学习方法有:隐马尔克夫模型(HMM)、最大熵隐马模型(MEMM)、条件随机场模型(CRF)等。CRF是计算整个标记序列的联合分布概率,在全局范围内进行归一化处理,不仅克服HMM输出的独立性假设问题,而且有效避免了MEMM的标记偏置问题。如冯艳红等[16]提出一种基于词向量和条件随机场的领域术语识别方法,将领域词语的语义特征和领域特征融入CRF模型中,在渔业领域语料、通用语料和混合语料上进行实验,该方法均取得较好效果。李想等[17]将农作物、病虫害和农药名称的词性、偏旁部首、左右指界词、附近数量词等特征融入CRF模型,建立特征与命名实体类别和词位间的关联关系,从而识别出命名实体,对农作物、病虫害、农药命名实体识别的准确度分别达97.72%、87.63%、98.05%。基于统计机器学习的实体抽取获得了较好的结果,但是该方法需要人工选择的特征作为模型输入,实体抽取的效果严重依赖特征选取,且模型的泛化能力不强。
1.1.3 基于深度学习的实体抽取
深度学习技术成为研究命名实体识别问题的热点方法,能够有效地解决人工选择特征的不足和高维向量空间带来的数据稀疏问题。近年来,基于深度学习的实体抽取主要思路是,首先采用字粒度、词粒度或者混合粒度将文本进行向量表示,然后用长短期记忆网络(LSTM)、循环神经网络(RNN)和卷积神经网络(CNN)等网络进行文本的语言特征提取,最后用条件随机场(CRF)输出最优标签序列。如Huang Z等[18]首次提出融合LSTM和CRF的端到端的命名实体识别模型,与基线方法相比,该方法具有较强的鲁棒性,对词语特征工程的依赖性较小。在此基础上,Lample G等[19]提出两种命名实体识别模型:一种是基于双向LSTM和CRF的命名实体识别模型,一种是基于转移的命名实体识别模型,在没有人工处理特征和地名录的前提下,英语、荷兰语、德语和西班牙语数据集上均取得较好的结果。Zhang Y等[20]提出基于Lattice LSTM的中文命名实体识别模型,该模型对输入字符序列和所有匹配词典的潜在词汇进行编码。与基于字符的方法相比,该模型显性地利用词和词序信息,与基于词的方法相比,Lattice LSTM不会出现分词错误。在多个数据集上证明Lattice LSTM方法优于基于词和基于字符的LSTM命名实体识别方法。目前,大部分神经网络都是使用Word2Vec和Glove工具训练词向量,所得到的词向量没有考虑词序对词义的影响,Google在2018年10月发布BERT语言表示模型,在各项自然语言处理任务中都取得了最先进的结果。王子牛等[21]提出基于BERT的中文命名实体方法,首先用BERT训练大量未标注语料,得到抽象的语义特征,然后结合LSTM-CRF神经网络,该方法在《人民日报》数据集上的F1值达到94.86%。此外,深度学习方法还被广泛应用于历史事件名抽取[22]、电子病历实体抽取[23]、商业领域实体抽取[24]、在线医疗实体抽取[25]等应用场景。值得说明的是,基于深度学习的实体抽取方法,在英语和中文等高资源语言中取得很好的效果;对于维吾尔语、蒙古语等低资源语言,实体抽取的效果有待提高。
1.2 跨语言情境下的实体抽取研究
跨语言的实体抽取主要目标是提升低资源语言的命名实体识别效果。值得说明的是,跨语言实体抽取不能理解为“单语言实体抽取”与“机器翻译”的简单拼接。从研究现状来看,目前主要包括以下两点:一是基于标签数据迁移的跨语言实体抽取;二是利用基于语言独立特征迁移的跨语言实体抽取。
1.2.1 基于标签迁移的跨语言实体抽取
基于标签迁移的跨语言实体抽取是指利用平行语料或者双语词典将源语言的标签数据迁移给目标语言,并在目标语言上建立实体抽取模型以完成实体识别任务。在基于平行语料的跨语言实体抽取方面,Ni J等[26]提出一种基于弱监督的跨语言命名实体识别方法,首先建立英语实体抽取模型,得到英语实体标签;然后通过包含對齐信息的平行语料库,实现英语与目标语言句子的对齐,并将英语的标签映射给目标语言;最后建立目标语言的实体抽取模型。其研究结果表明,目标语言实体抽取的效果好坏取决于英语实体抽取模型和平行语料库在词汇句子层面的对齐程度。徐广义等[27]为了解决柬埔寨语实体标签语料稀缺和命名实体缺乏明显标识特征的问题,根据英语和柬埔寨语的平行语料来构造双语图,获取柬埔寨语的实体类别分布特征,显著提高了柬埔寨语的命名实体识别的性能。上述实验结果表明,通过平行语料库将源语言标签迁移给低资源语言,能够有效提升低资源语言的命名实体识别效果。值得说明的是,由于构建平行语料库需要耗费较多的人力,所以从一定程度上限制了该方法的推广性。
在基于双语词典的跨语言实体抽取方面,Mayhew S等[28]利用“廉价”双语词典,将一种或几种高资源语言中可用的标签数据“翻译”为目标语言,并在廉价词典的基础上加入维基百科特征,显著提高目标语言实体抽取的效果。基于廉价词典的方法,其效果在很大程度上取决于双语词典的规模和质量,由于人工构建双语词典具有一定的困难,在处理真正低资源语言的命名实体识别问题上具有局限性。Xie J等[29]为了减少对人工构建双语词典的依赖,用种子词典进行词典规约得到包含更多单词对的双语词典,将源语言的标签数据迁移给目标语言;为了提高数据迁移过程中语序的鲁棒性,在神经网络模型中加入自注意力机制,在西班牙语、荷兰语和德语数据集上取得了较好的结果。与此类似,Ehrmann M等[30]尝试在没有任何平行语料库的情况下构建双语词典,通过无监督的方式对齐单语单词嵌入空间。值得说明的是,利用双语词典进行标签映射存在标签映射错误问题。为解决该问题,吴焕钦[31]提出一种基于软对齐的跨语言命名实体识别方法,通过建立跨语言神经网络模型,其中源语言句子、源语言标签和目标语言句子均用于预测目标语言的命名实体标签,从而实现源语言到目标语言的标签迁移,充分利用了源语言和目标语言的上下文信息。总的来说,一方面,基于双语词典的跨语言实体抽取方法摆脱了对于双语平行语料的限制,因而具有更广泛的应用;另一方面,如何减少对人工构建双语词典的依赖(即在处理低资源语言时能够准确、自动、快速地构建双语词典),又成为新的瓶颈问题。
1.2.2 基于语言独立特征迁移的跨语言实体抽取
基于语言独立特征迁移的跨语言实体抽取是指在一种语言上通过语言独立特征训练出模型,然后将模型直接迁移给其他语言。依照语言独立特征的不同,可以分为词簇特征、音韵特征、维基百科特征和共享词向量特征等。在词簇特性方面,“词簇”(Word Cluster)是指文本中2个或2个以上的词形以固定的组合关系(或位置)重复同现[32-33]。Tackstrom O等[34]将具有语言独立性的词簇特征加入直接迁移系统中,实现从英语到目标语言的语言结构迁移,在依赖句法分析和命名实体识别任务中,系统相对误差分别减少13%和26%。在上述研究的基础上,Tackstrom O[35]在命名实体识别任务中,通过加入多种源语言的词簇特征,并结合自训练学习目标语言的独立特征,显著提高目标语言实体抽取的效果。在音韵特征方面,Bharadwaj A等[36]提出一种加入音韵特征的神经网络模型,并结合自注意机制学习关注更有效的字符,预训练的模型能够很好地适应标注语料少甚至没有标注语料的目标语言中。在维基百科特征方面,Tsai C T等[37]将单词和短语链接到维基百科中的条目,并使用页面类别作为语言独立特征,实验表明,维基百科特征可有效提高命名实体识别的性能。在共享词向量特征方面,Ni J等[26]将源语言和目标语言的词向量投影到共享空间,将共享空间中的词向量作为语言独立特征,在源语言上训练模型并将其直接应用到目标语言中,实验表明该方法优于之前最先进的方法,并且缩小了与监督学习的差距。总体而言,基于语言独立特征迁移的方法,可以有效地将源领域的预训练模型迁移给目标语言,提高了模型在不同语言间的自适应性,但是该方法仍需要一定量的目标语言标注语料,对于真正低资源语言来说,具有一定的局限性。
值得说明的是,目前基于深度学习的实体抽取模型,较多地集中在单语言数据集上。在跨语言实体抽取任务上,一方面,由于机器翻译并不能完全解决标注语料缺乏的问题;另一方面,基于标签迁移的跨语言实体抽取较多地依赖于平行语料或双语词典的自动构建,这使得命名实体识别的效果提升仍然面临诸多挑战。如何有效地将源语言丰富的标注语料迁移给目标语言,成为当前亟待解决的研究问题。鉴于此,本文提出融合标签迁移学习和深度学习的跨语言命名实体识别框架。一方面,探究不同的标签映射方式和深度学习方法对跨语言命名实体抽取系统的影响;另一方面,探究迁移的数据量、双语词典规模和相似度计算方式对跨语言实体抽取系统的影响,以期为跨语言实体抽取相关研究提供借鉴。
2 研究框架与方法
2.1 研究问题
本文旨在探究跨语言情境下的实体抽取问题,参照Feng X等[38]关于低资源语言命名实体识别的研究,我们将英语假定为高资源的源语言,西班牙语和荷兰语为低资源的目标语言(即完全没有实体标注语料,只有少量或者完全没有双语词典),利用跨语言知识在源语言和目标语言之间建立桥梁,将源语言的标签数据迁移给目标语言,得到目标语言的训练集,然后建立目标语言的命名实体识别模型。具体而言,本文在特定的数据集上探究以下问题:①在跨语言实体抽取任务中,如何有效地将资源丰富语言中的标签迁移到低资源语言中?在有监督学习和无监督学习中,哪一种迁移方法更为有效?②在跨语言标签迁移的基础上,如何将深度学习正确地应用于命名实体识别模型?在卷积神经网络模型(CNN)、长短时记忆网络模型(LSTM)和门控循环单元(GRU)等神经网络模型中,哪一种更为有效?③在跨语言实体抽取任务中,如何合理地确定源语言训练数据的规模?源语言训练数据的规模是否越大越好?④如何合理地确定源语言和目标语言双语词典的规模?双语词典的规模是否越大越好?⑤在跨语言实体抽取任务中,如何选择合理的相似度方法来计算源语言和目标语言的对应翻译?
2.2 研究框架
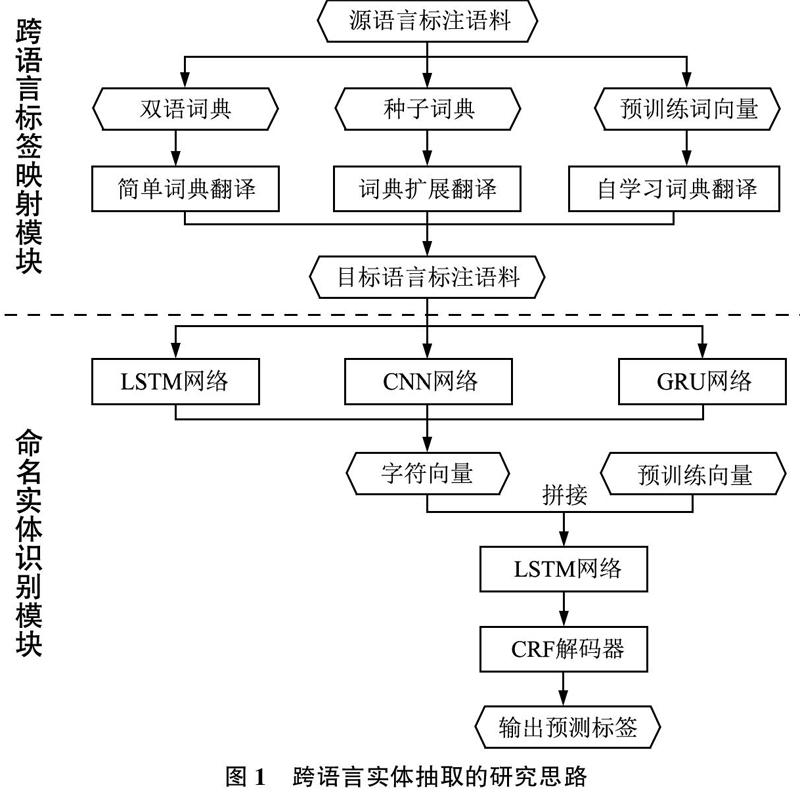
本文提出跨语言实体抽取(Cross-Lingual Entity Extraction,CLEE)框架,如图1所示,该框架由跨语言标签映射模块和命名实体识别模块构成。标签映射模块中,根据生成双语词典是否需要种子词典,将标签映射模块分为有监督学习和无监督学习两类,实现从源语言到目标语言的标签迁移,其中有监督学习包括简单词典翻译和扩展词典翻译;无监督学习包括自学习词典翻译。在命名实体识别模块,对目标语言建立基于深度学习的实体抽取模型。
2.3 跨语言标签映射模块
2.3.1 简单词典翻译
相对于平行语料库而言,双语词典是一种丰富且廉价的资源,将直接通过双语词典得到目标语言标签数据的方法称为简单词典翻译。该方法的主要思路是从Github网站下载Facebook官方提供的源语言和目标语言高度对齐的双语词典[39],通过双语词典将源语言的单词翻译成目标语言,并将源语言的标签数据直接映射给目标语言,得到带标签的目标语言训练集;然后根据双语词典得到的目标语言训练集,建立深度学习的命名实体识别模型。
2.3.2 词典扩展翻译
对于低资源的语言,当双语词典资源也很稀缺的情况下,可以利用种子词典进行词典扩展翻译。具体思路如下:首先通过种子词典学习源语言和目标语言词向量之间的正交性矩阵W,通过正交性映射将源语言和目标语言的词向量映射到同一向量空间;其次是进行词典规约(Lexicon Induction)[40],将预训练的源语言和目标语言词向量通过相似性局部缩放(CSLS)[40],得到包含更多单词对的双语词典;最后利用扩展后的双语词典,将源语言的单词翻译成目标语言,并将源语言的标签直接映射给目标语言,得到目标语言的训练数据集。
正交性映射的基本原理是假设有一个种子词典D={xi,yi}(i=1,2,…,d),其中xi为源语言的词向量,yi为对应目标语言的词向量,共有d个单词对。通过迭代训练式(1)得到正交性矩阵W,正交性矩阵W保证映射前和映射后的词向量方差保持不变。
minw=Wxi-yi2s.t.WWT=I(1)
相似性局部缩放(CSLS)的基本原理是源语言和目标语言的词向量通过正交矩阵W映射到同一空间后,根据最近邻找出同一向量空间下,目标语言词向量Y对应源语言词向量WX的翻译。余弦相似度可以计算源语言词向量WX和目标语言词向量Y之间的相似性,余弦值越大,说明源语言对应的目标语言翻译越正确。但该方法存在Hubness问题,即最近邻是非对称的,目标语言词向量Y是源语言词向量WX的最近邻,但源语言词向量WX不是目标语言词向量Y的最近邻。鉴于此,本文采用相似性局部缩放(CSLS)方法,计算公式如式(2)和式(3)所示:
CSLS(WXs,Yt)=2cos(WXs,Yt)-rT(WXs)-rs(Yt)(2)
rT(WXs)=1K∑Yt∈ηT(s)cos(WXs,Yt), rs(Yt)=1K∑WXs∈ηS(t)cos(WXs,Yt)(3)
rT(WXs)和rs(Yt)用于度量每个源语言和目标语言单词的Hubness问题的严重程度,如果一个单词和另外一种语言的单词都很接近,则r值就很高,那么CSLS(WXs,Yt)的值会变小。
2.3.3 自学习词典翻譯
词典扩展翻译依赖于小型种子词典,采用有监督的方法学习源语言和目标语言之间的映射矩阵。但对于真正低资源的语言,当源语言和目标语言之间不存在双语词典的情况下,利用不同语言的等价词具有相似性分布的原理,进行无监督的自学习词典翻译[41]。具体分3个步骤:
第一步:词向量的标准化。首先根据维度归一化源语言词向量X和目标语言词向量Y;然后均值中心化每个维度;最后重复维度归一化处理步骤。
第二步:完全无监督的初始化。利用标准化后的源语言和目标语言词向量去构建初始化词典D,词典D的行是来自于源语言X的单词(X1,X2,…,Xi,…);列是来自于目标语言Y的单词(Y1,Y2,…,Yi,…),如果Y中的第j个词是X中的第i个词的翻译,则Dij=1;否则Dij=0。由于X和Y是两种不同语言训练得到的词向量矩阵,无论是第i个单词Xi*和Yi*,还是第j个维度X*j和Y*j,它们之间都不是对齐的,故用相似矩阵替代词向量矩阵:MX=XXT和MY=YYT。对相似性矩阵的每一行都进行排序,在严格的等距条件下,排序后不同语言中相等的词会得到相同的向量。因此给出sorted(MX)中的任意一行,都可以在sorted(MY)中找到最相近的一行,从而找到对应词的翻译。
D=D11D12……
D21D22……
……Dij…
…………(4)
第三步:自学习训练过程。通过最大化当前字典D的相似性来计算最优正交映射WX和WY,计算公式如式(5)所示;并在映射后的词向量相似矩阵上计算最优的词典D,映射后的词向量相似矩阵为XWXWTZZT,如果j=argmaxk(Xi*WX)·(Yj*WY),则Dij=1,否则Dij=0。不断地重复上述训练步骤直到收敛。
argmaxWX,WY∑i∑jDij((Xi*WX)·(Yj*WY))(5)
2.4 命名实体识别模块
目标语言的命名实体识别可看作是序列标注问题,输入序列为X={x1,x2,…,xn},xi为该序列中的第i个单词;输出是与X相对应的标签序列Y={y1,y2,…,yn},yi为第i个单词的标签。本文的词表示编码器使用双向LSTM神经网络,可充分利用单词的上下文信息;解码器使用CRF,常见的解码器有CRF、HMM和MEMMs,而解码器CRF能够计算整个标记序列的联合概率分布,是在全局范围统计归一化,标签预测的效果较好。故该部分实验主要为了比较不同的字符编码器对目标语言的命名实体识别模型的影响。命名实体识别模块的框架如图2所示。
图2 命名实体识别模块架构图
通过标签映射模块,得到目标语言的训练集,对目标语言建立基于深度学习的命名实体识别模型。该模型包括编码和解码两个环节,在编码环节,首先采用门控循环单元(GRU)、卷积神经网络(CNN)或者双向长短期记忆模型(LSTM)得到每个单词的字符向量;然后通过加载预训练的词向量或者用Word2Vec工具训练维基百科语料库得到每个单词的词向量;接着将每个单词的词向量Wword和字符向量Cword串联得到联合向量表示Eword;最后采用长短期记忆模型(LSTM)获取每个单词的上下文特征。在解码环节,通过条件随机场(CRF)分析句子中标签之间的制约关系,加入标签转移概率矩阵,给出全局最优标签序列。
2.4.1 字符编码器(CNN/GRU/LSTM神经网络)
英语、西班牙语和荷兰语的单词都具有丰富的形态信息,如单词的前缀和后缀等,这些信息能够为命名实体识别任务提供有价值的信息,显著提高标签预测的效果。此外,研究表明,单词拼写对词性标注和语言建模等任务中的未登录词有很大的帮助。为了使单词表示对拼写敏感,本文采用字符编码器提取单词中的字符信息,探究以下3种字符编码器,即卷积神经网络(CNN)、长短期记忆神经网络(LSTM)和门控循环单元(GRU)在命名实体识别上的效果。
2.4.2 词表示编码器(LSTM神经网络)
循环神经网络(RNN)在训练过程中通常会出现梯度消失或梯度爆炸的情况,为了解决这个问题,长短期记忆网络(LSTM)应运而生,LSTM能很好地提升模型的长距离依赖的性能。LSTM和一般RNN的区别在于,LSTM增加了一个存储器块单元A,这个存储器块A包括3部分:输入门、遗忘门和输出门。输入门决定有多少新信息需要加入单元中,遗忘门主要用于控制单元内信息的存储,即决定丢弃什么信息,输出门是确定该单元A要输出什么信息。
2.4.3 条件随机场(CRF)解码器
Bi-LSTM层输出每个单词对应的各个标签的预测分值,可以挑选分值最高的作为单词的标签,但经常会出现一些不合法的标签序列。故在Bi-LSTM层的基础上加CRF层,CRF层能从训练数据中得到约束性规则,例如句子第一个单词以B/O开头,而不能从I开头;在B-label1和I-label2中,label1和label2要同类型;O和I-label不能组合在一起。标签序列中非法序列出现的概率大大降低,从而提高标签预测的准确性。
对于输入句子X={x1,x2,…,xn},对应的输出标签为Y={y1,y2,…,yn}。该标签序列的计算得分为:
s(X,Y)=∑ni=0Ayi,yi+1+∑ni=0Pi,yi(6)
其中,P是Bi-LSTM的输出得分矩阵,P的大小是n*k,k是不同标签的数目,Pi,j是代表第i个单词标记为第j个标签的得分。A是转移得分矩阵,Ai,j是同一句子中由标签i到标签j的转移分数。矩阵A是大小为k+2的正方形矩阵,k是标签的个数。对这个分数进行指数化和标准化,可以得到标注序列y的概率值p(y|X)。
p(y|X)=es(X,Y)∑∈YXes(X,)(7)
在式(7)中,YX表示句子X的所有可能的标签输出序列。
3 实验结果与讨论
3.1 数据集
本次实验中,以英语作为源语言,數据来源于CoNLL2003公开数据集[42];以西班牙语和荷兰语为目标语言,数据来源于CoNLL2002公开数据集[43]。3种语言的训练集、验证集和测试集已划分好。例如,英语的训练集、验证集和测试集中分别包含单词数为204 567个、51 587个和46 666个。具体统计如表1所示。
3种语言均使用BIO标注法,其中,B表示实体词的开始,I表示实体词的内部,O表示实体词的外部(不是实体词),在B和I的后接实体类型以区分不同的实体。CoNLL2003和CoNLL2002数据集包含4种类型的实体,分别为人名(Person)、地名(Location)、机构名(Organization)和其他实体(Miscellaneous)。例如:
3.2 实验及参数设置
为探究本文提出的研究问题,在跨语言命名实体识别的任务中,将比较标签映射方式、命名实体识别方法、迁移数据量的大小、双语词典的大小以及求最近邻的方法5个因素对跨语言命名实体识别系统的影响,相关实验设置如表3所示。
在命名实体识别算法中,从向量维度、训练设置和超参数3个方面设置相关参数,遵循以下原则:一是可比性,即不同模型的参数设置最大可能具有一致性,如保持相同的词向量维度和字符向量维度等;二是兼顾可用性和效率性,参照相关研究工作的参数设置[44],使得模型有较好的实体抽取效果,并尽可能地减少存储空间的开销和运行时间的耗费。具体参数设置如表4所示。
3.3 基线方法
本文提出融合自学习词典翻译和GRU-LSTM-CRF网络的实体抽取方法,为了检验该方法的有效性,假定英语为高资源语言,西班牙语和荷兰语为低资源语言(完全没有实体标注语料)。跨语言标签映射模块中,以简单词典翻译、词典扩展翻译为基线方法;命名实体识别模块中,以CRF、CNN-LSTM-CRF、LSTM-LSTM-CRF为基线方法。具体来说,将所提出的方法与11种基线方法进行比对,如表5所示。
3.4 本文方法与基线方法的对比实验
在本文方法与基线方法的对比中,以英语为源语言、西班牙语和荷兰语为目标语言,探究跨语言实体抽取(CLEE)框架的有效性。具体而言,在跨语言标签映射模块,通过双语词典将英语的CoNLL2003训练集迁移给西班牙语和荷兰语,得到目标语言的训练集。在命名实体识别模块,用迁移的目标语言训练集训练命名实体识别模型,并用西班牙语和荷兰语的CoNLL2002验证集和测试集对模型进行验证和评估。统计出实验结果的准确率(P)、召回率(R)和F1值,具体实验结果如表6和表7所示。
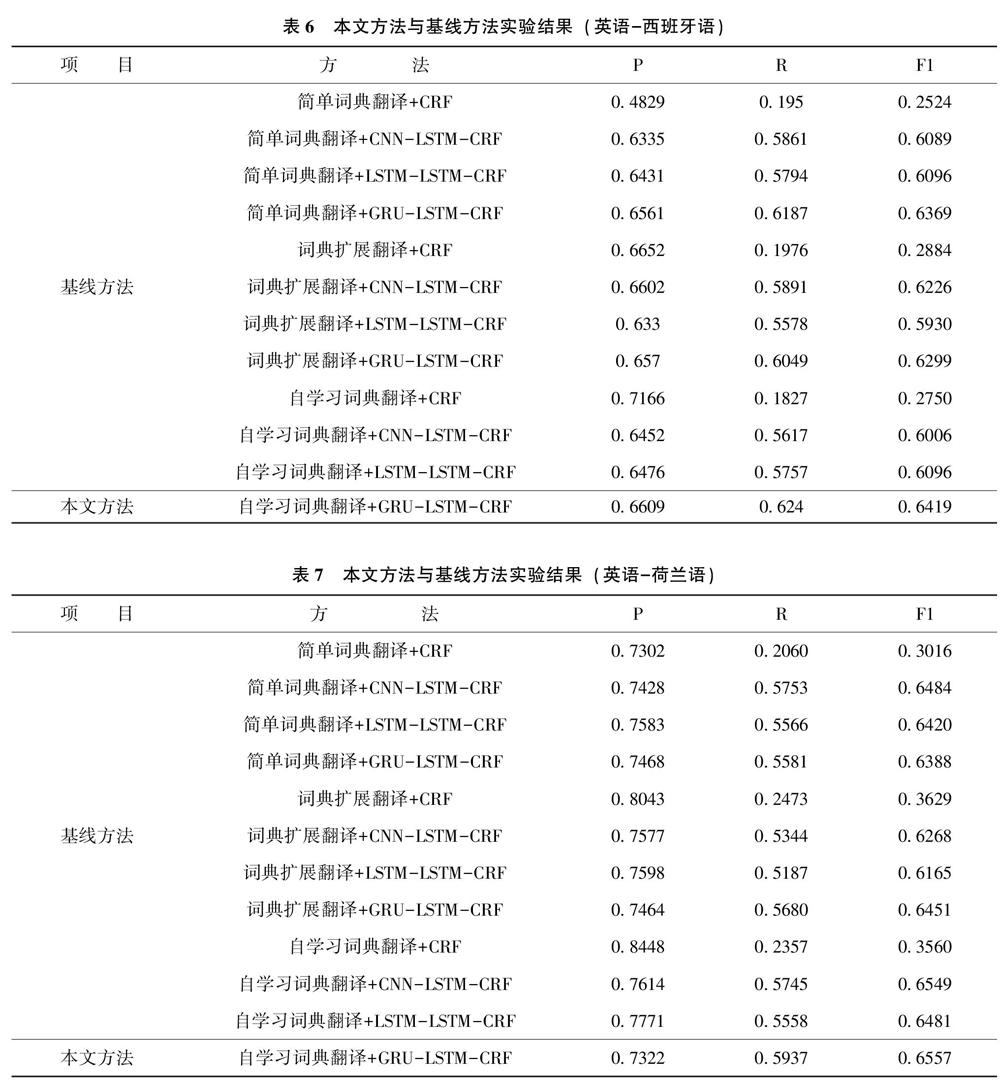
由表6可以看出,在“英语-西班牙语”数据集上,本文所提出的“自学习词典翻译+GRU-LSTM-CRF网络”的实体抽取效果优于其他基线方法,F1值达到0.6419。具体地,比较不同标签映射方式对实验结果的影响,固定命名实体识别模型为GRU-LSTM-CRF,得出自学习词典翻译效果最好,F1值为0.6419;其次为简单词典翻译,F1值为0.6369;词典扩展翻译排在最后,F1值为0.6299。
比较不同命名实体识别模型对实验结果的影响,在不同的标签映射方法中,CRF模型实体抽取的效果均远远低于基于深度学习的实体抽取方法;当标签映射方式为简单词典翻译时,GRU-LSTM-CRF取得了最优结果,F1值为0.6369,比CNN-LSTM-CRF和LSTM-LSTM-CRF的F1值分别高0.028和0.027;当标签映射方式为词典扩展翻译时,GRU-LSTM-CRF取得了最优结果(0.6299),CNN-LSTM-CRF次之(0.6226),LSTM-LSTM-CRF结果最差(0.5930);当标签映射方式为自学习词典翻译时,同样是GRU-LSTM-CRF的方法效果最好,比CNN-LSTM-CRF和LSTM-LSTM-CRF大约高了4个百分点。
由表7可以看出,在“英语-荷兰语”数据集上,本文所提出的“自学习词典翻译+GRU-LSTM-CRF网络”的实体抽取效果同样优于其他基线方法,F1值达到0.6557。具体地,比较不同标签映射方式对实验结果的影响,固定命名实体识别模型为GRU-LSTM-CRF,得出自学习词典翻译取得最好的效果,F1值为0.6557,比简单词典翻译和词典扩展翻译分别高0.017和0.011。
比较不同命名实体识别模型对实验结果的影响,在不同的标签映射方法中,CRF模型实体抽取的效果均远远低于基于深度学习的实体抽取方法;当标签映射方式为简单词典翻译时,CNN-LSTM-CRF取得了最优结果,F1值为0.6484,LSTM-LSTM-CRF次之(0.6420),GRU-LSTM-CRF最差(0.6388);当标签映射方式为词典扩展翻译时,GRU-LSTM-CRF取得了最优结果(0.6451),比CNN-LSTM-CRF和LSTM-LSTM-CRF大约高了3个百分点。当标签映射方式为自学习词典翻译时,CNN-LSTM-CRF、LSTM-LSTM-CRF和GRU-LSTM-CRF 3种实体抽取方法的F1分别为0.6549、0.6481和0.6557,实验效果上整体相差不大。
综合表6和表7来看,自学习词典翻译在跨语言标签映射中具有一定优势。作为一种无监督的标签映射方法,自学习词典翻译方法不需要双语种子词典,而是根据源语言和目标语言的分布形态生成双语词典。当目标语言完全没有标注语料,且源语言和目标语言之间没有双语词典时,可通过该方法得到比简单词典翻译和词典扩展翻译更好的实验结果。此外,CRF统计模型的实体抽取效果远远低于基于深度学习的实体抽取模型;GRU-LSTM-CRF模型与其余两种深度学习模型相比较,在大多数情况下GRU字符编码器表现更好,可能是因为GRU的结构比LSTM更加简单,GRU能更快地趋于收敛,并且所需的Epoch次数更少,这使得迭代次数一致的情况下,GRU取得了更好的结果。
从实验结果和实际情况的比照来看,本文提出的“自学习词典翻译+GRU-LSTM-CRF”方法在不同的评价指标下均取得较好的结果,在多数情况下能够较好地识别出实体,但仍存在少数与实际情况不一致的结果。例如,在西班牙语句子“Sao Paulo(Brasil),23 May(EFECOM)”中,单词“Sao Paulo”的中文含义为“圣保罗”,被人工标注为地名,而实验结果将其判定为人名。通过对原始语料进行比对,发现在英语训练集中,单词“Sao Paulo”的实体标签存在地名和人名两种情况,由于待识别语句长度较短(上下文信息并不充分),可能导致分类错误。再如,在荷兰语句子“In Viangros Kan Het Vlees,in Welke Fase Van Het Productieproces Het Zich Ook Bevindt,Perfect Getraceerd Worden Aan De Hand Van Een Etiket”(译为“在Viangros,肉产品在生产过程任何阶段都可以通过其标签被完美地追踪”)中,單词“Viangros”被人工标注为组织机构名,而实验结果将其误判为地名。通过对原始语料进行比对,发现通过数据迁移得到的荷兰语训练集中介词“in”的上下文中存在较多地名,可能导致训练出的模型将单词Viangros误判为地名。
3.5 扩展实验
扩展实验部分,本文探究从源语言迁移不同大小的训练集给目标语言、双语词典大小以及计算最近邻的方法对跨语言的命名实体识别模型的影响。
3.5.1 源语言训练集大小对跨语言实体抽取效果的影响
标签映射方法为简单词典翻译,命名实体识别模型为CNN-LSTM-CRF,双语词典的大小为8 000,比较迁移不同大小的训练集对命名实体识别的影响。实验结果如表8和表9所示。
从表8和表9可以看出,总体而言,在目标语言为西班牙语或荷兰语时,随着迁移训练集数量的不断增加,F1值逐渐增加。具体而言。在源语言数据集规模由3 000增加到150 000时,F1值增加较为迅速;在达到150 000后,F1值增加开始放缓;
3.5.2 双语词典大小对跨语言实体抽取效果的影响
从源语言迁移的训练集大小为180 000,标签映射方法为简单词典翻译,命名实体识别模型为CNN-LSTM-CRF,比较不同双语词典大小对西班牙语命名实体识别的影响。其中双语词典大小为0时,实际是直接进行模型的迁移,用英语训练集训练得到模型后,并在西班牙语和荷兰语的验证集和测试集上进行验证和评估。具体结果如表10和表11所示。
由表10和表11可知,在西班牙语数据集上,当双语词典大小为8 000时,模型结果最优,F1值为0.6235;在荷兰语数据集上,双语词典大小为10 000时结果最好,F1值为0.6484。总体上看,随着双语词典大小的增加,F1值也不断增加。
在一定范围内,从源语言迁移到目标语言的标签数据越大,双语词典越大,包含的跨语言的知识也越多,跨语言的命名实体识别系统的性能也就越好。
3.5.3 相似度计算方法对跨语言实体抽取效果的影响
词典扩展翻译和自学习词典翻译在生成双语词典时,都利用相似度来计算源语言和目标语言的对应翻译。本文提出两种相似度计算方法,分别为余弦相似度和相似性局部缩放(CSLS),比较这两种标签映射方式中不同计算最近邻的方法对西班牙语和荷兰语命名实体识别的影响。实验结果如表12和表13所示。
由表12和表13可知,在西班牙语和荷兰语数据集上,当迁移的训练集大小为180 000,命名实体识别的模型CNN-LSTM-CRF时,词典扩展翻译和自学习词典翻译这两种标签映射方式利用相似性局部缩放(CSLS)计算源语言和目标语言的相似性,效果均优于余弦相似度。CSLS可以计算不同语言间的单词相似性,并且考虑了源语言和目标语言的Hubness程度惩罚。比如当某个单词与另一种语言中的多个单词相似时,该单词的CSLS值会较小,可以有效抑制某些单词是很多单词的最近邻的情况。
3.6 讨 论
根据本文方法与基线方法的对比实验和扩展实验的结果,我们对2.1中所提出的研究问题进行探讨。针对问题1“在跨语言实体抽取任务中,如何有效地将资源丰富语言中的标签迁移到低资源语言中?在有监督学习和无监督学习中,哪一种迁移方法更为有效?”,从不同标签映射方式对实验结果的影响可以看出,在跨语言实体抽取任务中,使用不同的标签映射方式会在很大程度上影响模型效果。当标签映射方式为简单词典翻译,双语词典大小为10 000,通过双语词典将源语言的标签数据迁移给目标语言。当标签映射方式为词典扩展翻译时,首先双语种子词典的大小设为2 000,通过正交性映射和相似性局部缩放(CSLS),词典扩展到100 000个单词对,将源语言的训练集迁移给为目标语言。由于简单词典翻译和词典扩展翻译均为有監督的标签映射方式,其标签映射的效果很大程度上依赖于双语词典的质量和大小。而自学习词典翻译法是一种完全无监督的标签映射方式,利用源语言和目标语言的相似词向量之间具有相似的分布特征,通过不断地迭代训练生成包括100 000个单词对的双语词典,将源语言的训练集迁移给为目标语言。实验表明,无监督的自学习标签映射方法取得最好的效果。
针对问题2“在跨语言标签迁移的基础上,如何将深度学习正确地应用于命名实体识别模型?在卷积神经网络模型(CNN)、长短时记忆网络模型(LSTM)和门控循环单元(GRU)等神经网络模型中,哪一种更为有效?”,从不同命名实体识别模型对实验结果的影响可以看出,采用不同的深度学习命名实体识别方法,对实验结果产生不同的影响。分别采用CNN、LSTM和GRU 3种神经网络模型对字符向量进行编码,其中GRU神经网络的效果最好。虽然GRU神经网络的结构比较简单,但仍然能够取得相对较好的结果,表明在跨语言命名实体识别系统中,GRU-LSTM-CRF模型足以捕获目标语言的字符向量和词向量信息。
针对问题3“在跨语言实体抽取任务中,如何合理地确定源语言训练数据的规模?源语言训练数据的规模是否越大越好?”,从不同大小的训练集对实验结果的影响可以看出,在西班牙语和荷兰语数据集上,当固定双语词典大小不变,迁移的训练集大小在30 000~180 000之间,随着迁移的训练集增大,跨语言命名实体识别的效果呈现上升趋势。但是当迁移的训练集大小为210 000时,F1值反而下降。由于迁移的训练集过大,但双语词典大小有限,得到的目标语言训练集中的未登录词较多,从而影响跨语言命名实体识别系统的性能。因此,有必要合理地平衡双语词典大小和迁移标签数据二者的关系,使得跨语言命名实体识别系统达到最好的效果。
针对问题4“如何合理地确定源语言和目标语言双语词典的规模?双语词典的规模是否越大越好?”,从不同双语词典大小对实验结果的影响可以看出,随着双语词典的词数量增大,跨语言命名实体识别系统的性能越好。由于双语词典越大,包含源语言和目标语言间信息越多,将源语言的标签数据迁移给目标语言的更加准确。但是,随着双语词典的不断增加,跨语言命名实体识别的性能增长缓慢,故规模小但高度对齐的双语词典可有效提高跨语言命名实体识别的效果。此外,当双语词典的大小为0时,是将源语言训练出的模型直接迁移到目标语言,这种模型使用直接迁移的方法效果较差。
针对问题5“在跨语言实体抽取任务中,如何选择合理的相似度方法来计算源语言和目标语言的对应翻译?”,从不同计算最近邻的方法对实验结果的影响可以看出,在西班牙语和荷兰语数据集上,词典扩展翻译和自学习词典翻译两种标签映射方式均利用相似性生成双语词典,因此在扩展实验部分,在词典扩展翻译和自学习词典翻译中比较余弦相似度和CSLS两种相似度计算方法对跨语言命名实体识别系统的影响。由于CSLS考虑了源语言和目标语言单词的Hubness程度惩罚,生成源语言和目标语言间的双语词典对齐效果更好。
总体而言,与其他研究相比,本文所提出的框架具有以下优势:①相比于机器翻译模型,本文较好地解决了由于词汇语序被调整以及源语言词汇被拆分或合并等所带来的标签映射错误问题;②相比于基于平行语料的方法,本文方法节省了构建平行语料所消耗的人力与时间;③相比于其他基于双语词典的方法,本文提出无监督双语词典构建模型,能够更加便利地应用于无标注资源的小语种语言实体抽取。从理论上来看,当目标语言完全没有标注语料时,根据双语词典资源稀缺程度的不同,本文提出3种不同的标签映射方法。其中,针对一般低资源语言,可采用简单词典翻译和词典扩展翻译;对于完全无双语词典的语言,可采用自学习词典翻译。从实践上来看,我们通过实证探究迁移的数据量、双语词典规模和相似度计算方式在跨语言实体抽取任务中的影响,对于跨语言实体抽取实践具有借鉴作用。研究结果对于改进跨语言情境下的知识获取模型、促进知识获取研究等方面具有重要意义。
4 结 语
为了提升跨语言情境下低资源语言命名实体识别模型的性能,本文在跨语言实体抽取(CLEE)框架下,首先利用迁移学习的思想,将源语言的标签数据迁移给目标语言,然后利用深度学习的思想,建立目标语言的命名实体识别模型。本文将标签映射模块和命名实体识别模块的不同方法进行组合,并在西班牙语和荷兰语数据集上进行实证研究,论证了结合自学习词典翻译和GRU-LSTM-CRF网络的无监督跨语言实体抽取效果最好。实验结果表明,通过利用跨语言知识在源语言和目标语言之间建立桥梁,能显著提升低资源语言实体抽取的效果。
受制于实验条件,本文仅探究了与跨语言命名实体识别相关的5个问题。在后续研究中,将继续探究以下问题:①如何进一步优化研究方法,持续改进现有命名实体识别模型,使用BERT模型或者在模型中加入自注意力机制来提高跨语言命名实体识别的性能;②进一步探究HowNet义原词典、同义词词典以及反义词词典等语义工具对于跨语言命名实体识别效果的提升。
参考文献
[1]孙镇,王惠临.命名实体识别研究进展综述[J].现代图书情报技术,2010,(6):42-47.
[2]禤镇宇,蒋盛益,张礼明,等.基于多特征Bi-LSTM-CRF的影评人名识别研究[J].中文信息学报,2019,33(3):94-101.
[3]魏勇,李鸿飞,胡丹露,等.一种基于复合特征的中文地名识别方法[J].武汉大学学报:信息科学版,2018,43(1):17-23.
[4]关晓炟,吕学强,李卓,等.用户查询日志中的中文机构名识别[J].现代图书情报技术,2014,(1):72-78.
[5]余丽,钱力,付常雷,等.基于深度学习的文本中细粒度知识元抽取方法研究[J].数据分析与知识发现,2019,3(1):38-45.
[6]刘晓娟,刘群,余梦霞.基于关联数据的命名实体识别[J].情报学报,2019,38(2):191-200.
[7]马建霞,袁慧,蒋翔.基于Bi-LSTM+CRF的科学文献中生态治理技术相关命名实体抽取研究[J].数据分析与知识发现,2020,4(Z1):78-88.
[8]张琴,郭红梅,张智雄.融合词嵌入表示特征的实体关系抽取方法研究[J].数据分析与知识发现,2017,1(9):8-15.
[9]鄂海红,张文静,肖思琪,等.深度学习实体关系抽取研究综述[J].软件学报,2019,30(6):1793-1818.
[10]丁晟春,侯琳琳,王颖.基于电商数据的产品知识图谱构建研究[J].数据分析与知识发现,2019,3(3):45-56.
[11]安波,韩先培,孫乐.融合知识表示的知识库问答系统[J].中国科学:信息科学,2018,48(11):1521-1532.
[12]范馨月,崔雷.基于文本挖掘的药物副作用知识发现研究[J].数据分析与知识发现,2018,2(3):79-86.
[13]Riaz K.Rule-based Named Entity Recognition in Urdu[C]//Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics.Stroudsburg:ACL,2010:126-135.
[14]Collins M,Singer Y.Unsupervised Models for Named Entity Classification[C]//Proceedings of Joint SIGDAT Conference on Empirical Methods in Natural Language Processing and Very Large Corpora.Stroudsburg:ACL,1999:100-110.
[15]周昆.基于规则的命名实体识别研究[D].合肥:合肥工业大学,2010.
[16]冯艳红,于红,孙庚,等.基于词向量和条件随机场的领域术语识别方法[J].计算机应用,2016,36(11):3146-3151.
[17]李想,魏小红,贾璐,等.基于条件随机场的农作物病虫害及农药命名实体识别[J].农业机械学报,2017,48(S1):178-185.
[18]Huang Z,Xu W,Yu K,et al.Bidirectional LSTM-CRF Models for Sequence Tagging[EB/OL].https://arxiv.org/abs/1508.01991,2020-03-16.
[19]Lample G,Ballesteros M,Subramanian S,et al.Neural Architectures for Named Entity Recognition[C]//Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics.Stroudsburg:ACL,2016:260-270.
[20]Zhang Y,Yang J.Chinese NER Using Lattice LSTM[C]//Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics.Stroudsburg:ACL,2018:1554-1564.
[21]王子牛,姜猛,高建瓴,等.基于BERT的中文命名实体识别方法[J].计算机科学,2019,46(S2):138-142.
[22]唐慧慧,王昊,张紫玄,等.基于汉字标注的中文历史事件名抽取研究[J].数据分析与知识发现,2018,2(7):89-100.
[23]李纲,潘荣清,毛进,等.整合BiLSTM-CRF网络和词典资源的中文电子病历实体识别[J].现代情报,2020,40(4):3-12,58.
[24]丁晟春,方振,王楠.基于Bi-LSTM-CRF的商业领域命名实体识别[J].现代情报,2020,40(3):103-110.
[25]陈美杉,夏晨曦.肝癌患者在线提问的命名实体识别研究:一种基于迁移学习的方法[J].数据分析与知识发现,2019,3(12):61-69.
[26]Ni J,Dinu G,Florian R,et al.Weakly Supervised Cross-lingual Named Entity Recognition via Effective Annotation and Representation Projection[C]//Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics.Stroudsburg:ACL,2017:1470-1480.
[27]徐广义,严馨,余正涛,等.融合跨语言特征的柬埔寨语命名实体识别方法[J].云南大学学报:自然科学版,2018,40(5):865-871.
