基于大数据的新闻内容生产效能评估
——以上海某媒体为例
2020-12-10李开宇
唐 铮,李开宇
(1.中国人民大学 新闻学院,北京100872;2.清华大学 计算机系,北京100091)
媒体融合带来了新闻内容生产的组织机制重构,将新闻生产者大量转化为全媒体生产者,由此促进了新闻生产力的提升。而随着融合背景下的媒体日渐增加且内容产品日益丰富,如何对新机构下的新内容产品进行效能评估便成为摆在眼前的迫切问题。既有的媒体效能评估大多基于单一媒介类型的单一新闻产品,并长期处在随机性和任意性较强的状态下,难以适应媒体融合下内容生产力改造后的实际需求。本研究力求从大数据角度出发,基于媒体运行的真实数据,将新闻从生产者的特性进行量化建模,从“人力—产出”的角度为这一实际困境提出或可实践的解决方案。
一、融合背景下的新闻内容生产效能
融合格局下,传统媒体在宣传理念、新闻生产模式、传播技术、载体更新等各方面实施组织重构和业务再造。在这一过程中,新闻工作者逐渐告别新闻常规,即日常完成新闻工作的一系列模式化的、常规的、重复的实践和形式(1)Shoemaker,P.J.,Reese,S.D. ,“Mediating the message”.London:White Plains Longman.1996,p105.,新闻生产也随之进入“一次采集、多次生成”的融合生产模式。
融合型记者成为大势所趋,单个新闻工作者常常肩负着同时生产不同体裁、不同形式新闻作品的任务。在这一过程中,有新闻工作者成长为全媒体生产者的自我提升,也有组织调整例如搭建“中央厨房”的结构性助力。以上融合机制重构均以媒体能够持续地产出高质量、跨媒体形态的融合性内容产品为目标。随着内容生产者的素质提升、内容生产平台的科学化以及一些更为先进的内容管理系统的引入,新闻生产的单位时间越来越短。尼格伦(Nygren)在2009 年的调查表明,传统媒体的记者一天可以制作2 到3 条新闻,但在网络媒体工作的记者效率最高的可以达到一天5 到10 条(2)Preston.P,“Making the news:Journalism and news cultures in Europe”,New York:Routledge,2009,p.66.。
新闻内容作为高流动性的信息综合体,其生产过程高度机动而不可控,在生产中需要包含结构化的经验,独到见解,对经验的反思以及有价值的、整合的相关信息(3)Davenport,T.H.,Prusak,L.“Working knowledge:How org-anization manage what they know”,Boston:Harvard Bus-iness School Press,1998,p.108.,完成创造性工作是新闻从业者的核心价值所在。正因其显著的创造性、灵活性和机动性,此前包括媒体在内的内容生产机构一直无法针对新闻内容生产设立精准的效能评估方法。传统媒体的内容生产机制和考核标准,是以专业机构持续稳定地生产单一属性的新闻产品为前提,内核是沿用“信息收集—把关人筛选—分发”的机制模式,效能衡量体系也相应地为原有载体服务,采用工作量统计和打分评估等手段,对于新闻生产者进行评价。
目前媒体使用较为广泛的新闻生产效能评估方式主要有以下几种:(:(1)完全按量评价;(;(2)完全按质评价;(;(3)质、量结合评价。这三种主流衡量方式分别对应知识组织效能评估的三种主流视角,即行为视角、效果视角和能力视角。
行为视角下的效能被定义为“一套与组织或个体所工作的组织单位的目标相关的行为”(4)Murphy G.“Human Resource Management”,NewYork:Internantional Journal of Project Management,1993,pp.3-12.。在行为论视角下,行为被视为效能的最核心体现。使用这种方式的媒体效能评估单纯以新闻发布数量(条数、字数、时长等)为衡量指标。
基于效果视角,特别是以实践为导向的效能评价体系中,大多将绩效理解为结果。BerMrdin 将绩效定义为“在特定的时间内,由特定的工作职能或活动产生的产出纪录,工作绩效的总和相当于关键和必要工作职能中绩效的总和(或平均值)”(5)理查德·威廉姆斯:《业绩管理》,赵政斌译,大连:东北财经大学出版社,1999 年版,第81 页。。使用这种方式的媒体效能评估单纯以新闻发布质量(版面位置、时段、社会评价)为衡量指标。
而McBer 咨询公司和Spencer 倡导从能力角度衡量效能,认为基于能力的判断是“向前看”的绩效管理方式(6)French W.“Human resource management”.Boston:Hongton Miffin Company.1990,Chapter20.,这一观点将效能进行了更为立体化的解构,将其对应为与组织战略目标、用户满意感及投资相关的过程与结果的综合体。使用这种方式的媒体效能评估既计算新闻产品的发布数量,同时通过打分、定级等方式界定质量,再计算综合指标得到最终结果。
然而,以上三种方式在媒体融合背景下都出现了障碍,无法有效地界定内容生产的效能。“效果视角”注重衡量目标与结果,但融媒体新闻生产工作是创造性的、独特的、机动的,几乎不可能在内容生产前就清晰明确地做出结果定义。目标只能是在进行中不断调整、修正和明确。因而,仅仅以效果为导向有明显的不足之处。“行为视角”把新闻生产者的作品数量作为重点衡量目标,这与新闻生产者的熟练程度、努力程度和资源驾驭能力直接相关,但完成创造性工作是新闻从业者的核心价值所在,单纯以数量定江山,是对新闻生产的简单化和庸俗化。而在新闻生产中,生产者的能力、潜力往往难以从其工作的过程或工作表现中体现出来,特别是在媒体融合时代,“中央厨房”式的集约化社会化生产日成主流,一则新闻产品往往由整个团队甚至由外部支援来支撑,所以“能力视角”也难以完成对新闻内容生产效能的准确评估。
以上分析证明,目前传统媒体内部在融合背景下尚未形成一种有效的绩效评价管理机制,难以配合媒体深度融合转型发展战略目标的实现。
大数据技术的完善和媒体融合的不断推进,给效能评估的进一步量化提供了可能。移动媒体时代,新闻信息从生产、发布、反馈等各环节的效果都是可定量化分析的。根据后台数据,媒体不但可以监测到新闻内容的点击率、浏览量、转载率、评论情况、情感极性(7)Alexandra Balahur, Hristo Tanev:“Detecting Event-Related Links and Sentiments from Social Media Texts”,Sofia, Bulgaria: ACL (Conference System Demonstrations)2013:pp.25-30.,从而了解读者阅读偏好,把握报道节奏,策划报道内容,也能够将大数据应用于媒介组织架构和效能评估,使得新闻生产者和媒体组织之间通过更科学的评价体系,建立互信、支持和协作的“双向依赖”关系。
建立科学而全面的效能评估体系是一个长期而综合的过程,需要大量数据支撑。本研究旨在使用定量方式,基于媒体真实运行数据的推演,将上海某媒体的真实内容生产及人力运转数据用于构建模型,将真实数据代入模型进行“空转”,这一设计参考了我国在重庆、上海进行的“房地产税空转”体系实践,以及借鉴了人民日报“中央厨房”从无到有的机制搭建经验。把真实的数据带入到仿真体系中加以验证,能够从一定程度上看到效能模型在媒体现有体系下运行时的真实状况,进而提出媒介融合背景下媒体调整和改进效能评估机制的新模式。
二、效能模型建构原则及数据来源
(一)建构原则
基于既往数据的相对缺乏和内容生产的机动性,构建这个初级模型时暂且排除了其他更为复杂的变量,而只是以“人力—产出”的逻辑来推导内容生产的效能最优。
这一模型基于下述逻辑:如果将新闻生产视为人的创意性生产,那么,新闻产出与人力(包括时间、精力、创意性生产的工作状态等)直接相关,而这种相关性可以用具体的具有可解释性的模型来描述。同时,假设新闻生产的数量在非重大影响(例如重大自然灾害、重大突发新闻等)的情况下,在一定程度上是存在周期性的。也就是说,持续增加的工作时间并不能使得新闻产量无限量扩张,新闻产量在受到人力限制的同时还会受到新闻资源的限制。另外,新闻工作者一旦不眠不休地进行新闻生产的话,会因为创造力下降而影响新闻的产量。因此对于实际新闻生产而言,通过建立模型来找到关键性节点,以便确定生产效能,是有意义的。
因而,模型以真实新闻生产量为基础参考值,以生产周期为变量,可以得出现阶段新闻内容生产力下的呈理想化状态的新闻产量。进而在工作人数不变的前提下,可以获知实际新闻生产量和理想化产量之间的逻辑关系,由此为制定科学的新闻效能产出提供依据。
(二)数据来源
于2014 年提速建设的媒体融合改革为研究提供了可靠的数据源。自2014 年媒体融合全面提速以来,新闻生产的硬件配置及软件配备全面升级,全面的数字化和线上化成为各个媒体在融合时的必要项。本研究所采集的数据,便源自上海某媒体近年来的相关真实数据:
1.使用线上签到工具,统计记者的日均工时和年均工作日。这部分数据能够提供该媒体从事新闻生产的人员的准确数量,并提供他们的工作时长。
2.使用多媒体处理系统,统计新闻产品的生产周期。这部分数据来自于媒体的数字化处理系统。按照媒体的要求,所有内容产品都要在该媒体的多媒体数字化处理系统上上传并签发,通过“大花脸”功能记录全部流程。由此可以记录新闻作品从入库提交、修改、签发的全过程中每个节点的时间,从而得知新闻作品的生产时长。
3.该媒体2017 年8 月3 日至2019 年12 月31 日的每月新闻生产量。这部分数据来自于数字化处理系统的后台统计功能。根据这一功能,能够准确列出该媒体在此期间的每日新闻生产量,并根据需求进行相应的分类和归并。
(三)数据清洗与梳理
根据该媒体的大数据记录进行清洗和梳理后,得出的数据如下:
1.根据媒体稿件入库记录,获得该媒体2017 年8 月3 日至2019 年12 月31 日共881 天的数据。
2.根据线上签到工具上的数据记录,该媒体共有新闻生产者126 人,平均工作时长为9.7 小时(法定工作时长8 小时),年平均工作日为304.3 天(2018 年法定工作日为252 天,2019 年法定工作日为250 天)。
3.根据多媒体处理系统上的数据记录,2017 年8 月3 日至2019 年12 月31 日该媒体共计生产新闻作品40 673 件,分为文字稿件、图片稿件和音视频稿件三类,并得到这三类稿件在2017 年8 月至2019 年12月的每天的新闻产量。
4.通过新闻编辑文稿系统修改功能,能够记录每篇稿件的入库、修改过程、签发过程等每一步骤的时间。在媒体融合进程中,多数媒体已经实现了这一功能的实现及运用。这一功能被媒体俗称“大花脸”功能,可以被用来界定每篇新闻的生产周期长度。根据“大花脸”功能,对以上三类新闻的生产周期进行统计,取平均数±5%的区间,得到如下结果:文字稿件的生产周期为4.9~25.7 小时,图片稿件的生产周期为2.4~4.5小时,音视频稿件的生产周期为14.3~48.9 小时。
继而,基于数据清洗技术(8)Xu Chu, Ihab F. Ilyas, Sanjay Krishnan, Jiannan Wang:“Data Cleaning: Overview and Emerging Challenges”, San Francisco:SIGMOD Confer⁃ence ,2016,pp.2201-2206.对数据的空值与非法值进行了清洗与修正,使得数据的取值在合理的范围内,之后在底层使用MongoDB 作为基本的数据管理引擎。
(四)模型选型
建模过程中引入人工智能领域的前沿技术——神经网络技术,从既有的数据当中通过机器学习算法,得出规律,继而通过数学模型来描述人力与产出之间的关系。神经网络技术模拟人脑的神经元结构,通过构造多层次的网络结构,来表征数据特征(输入)与因变量(输出)之间的关系(9)Lecun Y,Bengio Y,Hinton G,“Deep Learning”,No.521(7553),Nature,2015,p.436.。
举例来讲,如果想要知道一处房产的属性与房价之间的关系,可以将属性X(建筑面积、使用面积、城市、地段、楼层、朝向和是否有电梯等)作为自变量,而将房屋的价格Y 作为因变量。假设因变量和自变量之间存在某种关系满足Y=f(X),当今后给定一个新的房屋的基本属性值时,便可以预测该房屋的房价。机器学习中的回归问题(10)Ripley,Brian D,“Pattern Recognition and Neural Networks”.Cambridge:Cambridge University Pess,2009,pp.97-118.,也就是如何在给定一部分真实数据情况下(同时包含因变量与自变量),去寻找一个最可能真实的模型f。而深度学习理论假设函数f是由一个网状的神经元结构组成的,以自变量作为第0层,网状结构的每一层会对上一层的输入进行一次非线性的变换,从而计算出最终的结果。
本文将基于以上理论和数据,寻找合适的自变量表达方式,去对媒体内容生产者工时投入进行量化。同时寻找合适的网络模型参数,通过机器学习算法确定一个最为合理的模型,从而建模出生产者工时与产出模型,用于完成媒体产出效益最优化的预测。
三、计算原理和研究方法
本节着重研究这样一个问题“给定一个媒体生产组织(例如,某上海媒体),已知其过往的具体工时X与真实产出数据Y,如何寻找模型f,可以近似描述工时与产出的关系,即“Y≈f(x)”。
(一)初级问题定义
模型的雏形出于最朴素的逻辑“人力—产出”,也就是说,无论媒体形态和最终产品发生了什么变化,现阶段的新闻内容生产仍然基本全部依靠于人力,因此“新闻工作者的数量和产能——新闻内容产品”之间存在紧密的正相关性。而后一层层对问题进行具象化,不断在机器学习的过程中加入各种参数和影响因素,最终得到可解释性较高的“新闻发稿量预测模型”。
首先,建模中考虑一种简单的映射关系,假设共有n个生产者(实际数据为126),定义每天的工作时长为X(小时)=[X1,X2......Xn],其中Xi表示第i个生产者本日的工作时长。相应的总产量为Y=[Y1,Y2,Y3],Y1,Y2,Y3分别表示文字稿件,图片稿件和视频稿件的产出。如果两者之间存在简单的映射关系,则可以表示为简单的Y=f(X),即给定X即可通过其映射关系找到Y。
其中的函数f可以使用多种方式来表达,其中最简洁的形式是使用线性模型进行回归分析,拟合出X与Y的关系。本模型使用更复杂的方式,即深度神经网络,给予足够多的网络层数,通过调参技巧学习出精确的模型参数。
在使用数据集训练模型之前,需要先将整个数据集分为训练集、验证集和测试集。训练集是用来训练模型的,通过尝试不同的方法和思路使用训练集来训练不同的模型,再通过验证集使用交叉验证来挑选最优的模型,再通过不断地迭代,来改善模型在验证集上的性能,最后再通过测试集来评估模型的性能。数据集划分得越好,模型的应用部署就越强,但如果划分不好,则会大大影响模型的应用部署。在建模时,基于交叉验证的准则(11)周志华:《机器学习》.北京:清华大学出版社2016 年版,第210-219 页。将881 条数据进行切分,其中500 条用于训练,100 条用作验证集,其余281 条用于下一节进行最优产出模型拟合。在这一过程中,使用损失函数来描述模型的精准程度,即真实数据与预测值之间的误差。
(二)神经网络求解与特征工程
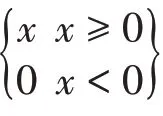
理论上来讲,随着模型训练的过程,参数将会越来越精准,相应的损失(LOSS)应该越来越小,然而,当下展示出的学习过程并没有明显使LOSS 变小,而当模型逐渐变得复杂,层数增多时,损失函数渐渐出现明显变化。这说明模型选择并不合理。应该进一步思考加入更为合理的系数,发掘更合理的模型。
结合实际情况则能够发现:一个部门的实际工作产出不应该只取决于新闻工作者的工作时间,还应当取决于当前这一天的具体时间属性。例如,这一天是周一还是周五对于新闻工作者来讲是不同的,不仅他们的工作热情不同,实际生活中,可供加工的新闻素材也可能不同。其次,要看这一个工作日是否是假日,是否是重大节日,这些信息都应当被编码在输入项X当中,因为是否是假日,个人工作热情应当不同,是否是节日,可能产生的新闻数量与话题度就不同,例如,重大的节日一般会有许多活动和纪念仪式可供报道。其次,还需要考虑一年当中各个月份中由于季节性,会导致新闻内容的具体产出出现差异(包含阳历、阴历)。因此,应该基于这样的考虑,增加时间属性特征的系数。
因此在不考虑随机扰动的情况下,额外编码了上述五种信息,编码规则如表1。

表1 基于时间属性的编码信息
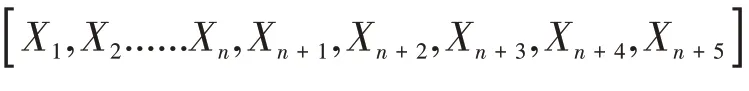
在实际情况中,具体的新闻内容生产过程其实相当于一个时序序列,因此在考虑某一个时间点的产量时,不可忽略前面若干个时间点的产量,也就是说,7 月12 日的新闻生产量其实对于7 月13 日是有影响的,两者并不是孤立的存在,其中存在时序关系。因此,应该基于这样的考虑,增加基于时序关系特征的系数。
根据这个因素,设定为第i天,Yi的产量应当同时取决于Xi和Yi-1,Yi-2,......Y1两个因素,由此得出的模型为:Yi=g(Xi|Yi-1,Yi-2,......Y1)。在实际中,为了简化模型,同时为了使模型具有更高的合理性,通常认为当前状态量只和前一状态量有关,即满足齐次马尔科夫性(12)张波,张景肖:《应用随机过程》,北京:清华大学出版社2004 年版,第28-59 页。,这一性质使得模型的求解更为便利,同时,假如采取递推的链式法则,第i- 1 个变量里面,实则已经包含了前i- 2 个变量的信息,因此,形如Yi=g(Xi|Yi-1)的形式对于求解参数更为方便。
(三)循环神经网络求解实际模型参数
经过数据工程方法处理,得到更全面的向量后,运用循环神经网络(RNN)进行建模。这是一种经过实践证明在处理时序序列时优于隐马尔科夫模型的一种方式。在经典的神经网络模型中,隐藏层的值只取决于x输入,然而在本例中,需要考虑到当前状态可能不仅与当前输入有关,还与上一状态有关,因此其相应的结构应该表达如图1 所示,其中y为实际产出,W 为相应的权重。最终计算得出的结果如图2 所示。
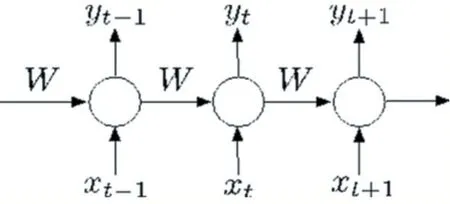
图1 循环神经网络(RNN)示意图
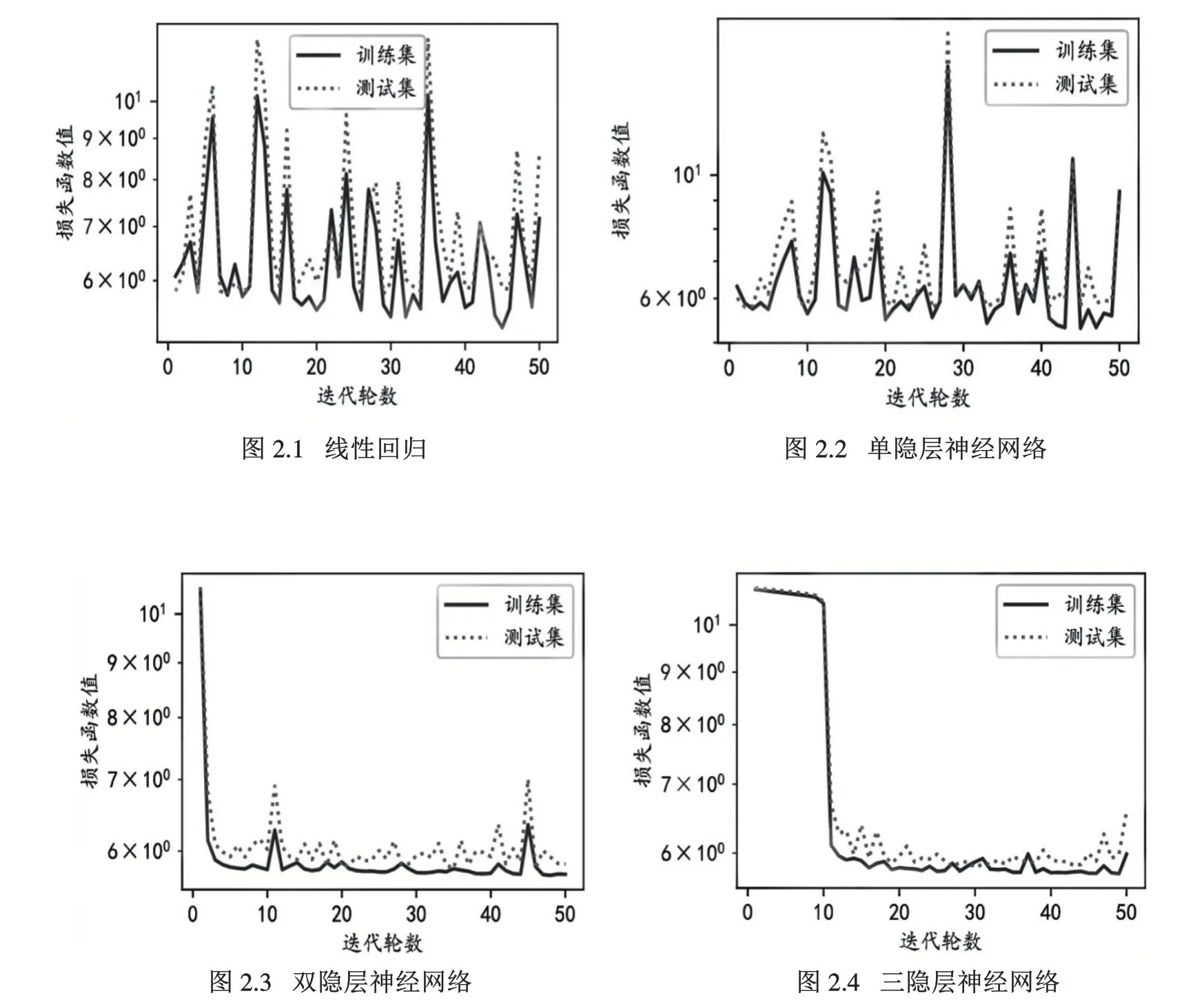
图2 损失函数在模型训练过程中的变化(越小代表性能越好):循环神经网络
然而,目前的模型仍然包含两个重要缺陷:(:(1)从模型可解释性的角度,需要对于上述提出的方法进行进一步的改进,考虑到现实生活中,内容生产对于历史数据应当是具有记忆性的,即假如去年的10 月1 日印象发稿量非常大,那么将可以判断出今年10 月1 日的发稿量也会比较大。(2)模型进行学习的参数与前一阶段的数据有关,在具体实现中,由于神经元个数过多,特别容易出现参数累计相乘后出现数值膨胀或萎缩的情况,导致数值不稳定,出现所谓的“梯度爆炸”与“梯度消失”的情况,即当神经网络很深时,梯度呈指数级增长,不稳定的数值造成模型失当。梯度爆炸和梯度消失的问题在循环神经网络中最为常见。
针对上述两个问题,引入长短记忆神经网络(LSTM)予以解决(13)Greff,Klaus,Srivastava,Rupesh Kumar,Koutník,Jan,etc,“LSTM:A Search Space Odyssey”,NewYork :IEEE Transactions on Neural Networks&Learning Systems,vol.28(10),2015,pp.2222-2232.。该网络在1997 年被学者Hochreiter和Schmidhuber 引入,用于解决具有长依赖特性的时序数据建模。通过LSTM 可以对于有效的信息进行保留。从而解决对于模型输出预测的长依赖问题。如果将预测结果的误差求均值后作为偏差量,能够得出结果如图3。
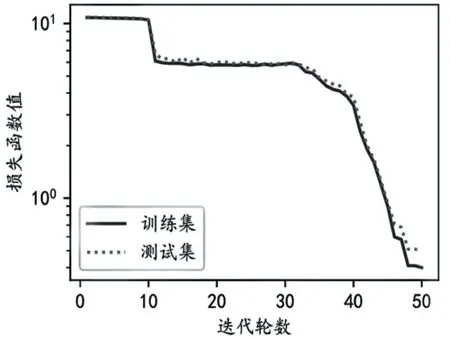
图3 损失函数在模型训练过程中的变化:LSTM 模型
在LSTM 模型中,损失越小代表性能越好。从图上可以看出,经过几次调整,模型已经逐渐收敛,误差值非常小。通过前期的参数调整与数据工程,这一模型在该数据集上可达到平均90%以上的准确率(Preci⁃sion)和召回率(Recall),据此可以使用这个模型去进一步预测新闻内容生产量及生产效能。
四、新闻内容生产的最优效能
根据此前得出的模型,本节将解决这样一个问题——“在假定人力不变的前提下,制定多少新闻内容生产数量时,效能是最优的”。
由于单日的新闻内容产量具有较大随机性,容易受到突发事件和各种偶然因素的干扰,因此在模型中把时间轴放宽至以月度为单位,依据上一节计算所得的模型,计算在未来一段时间内单月的新闻产量如何达到最优效能。
首先,在假定工作总人数不变的前提下,根据模型预测出该媒体后281 天的内容生产产出数量,作为输入值,并以真实的281 天数据作为输出值,在模型中拟合出预期产出与真实产出之间的关系,并对这一拟合结果进行观测和分析。这一拟合的实际意义在于:如果将预期产出理解为该媒体的管理者给新闻工作者下达的工作任务,那么根据预期产出对真实产出的影响就可以真切地观测出,在人力不变的情况下,新闻内容生产将在何时出现变化节点,又将在何时达到最优化的生产效能。因此,这一结果将有助于衡量真实的新闻工作,为媒体管理者在融媒体变化大势下更科学准确地下达新闻生产任务提供重要的参考。
其次,在融合媒体背景下,全媒体记者成为必需,一则新闻内容通常会由单人进行采写,随后以文字、图片或音视频等不同的方式单一发布或结合多种形式融合发布。不同新闻内容所耗费时间不同,会导致新闻产出量的差异。根据该上海媒体的真实数据,文字稿件的生产周期为4.9~25.7 小时(平均时间15.3 小时),图片稿件的生产周期为2.4~4.5 小时(平均3.45 小时),音视频稿件的生产周期为14.3~48.9 小时(平均31.6小时)。在计算中,使用平均数对新闻产出总量进行量化。根据生产周期的平均时间计算,文字、图片、音视频的新闻生产时长比例约为30:7:63。音视频新闻的生产时长是图片新闻生产时长的7 倍。在假定人力不变的前提下,这三类新闻内容的总量必然符合恒定的总工时所能出产的新闻产量,且三类内容呈现此消彼长的关系。
第三,研究中使用的全部是真实数据,实际新闻内容产量是由该媒体的126 名在职新闻工作者完成的,因此,预期新闻产量仍以126 人作为基础量,并在输入数值时折算为126 人的工作总时长。
基于以上三点,以预期生产时间作为横坐标,以实际产出作为纵坐标,进行拟合操作,拟合结果如图4所示。
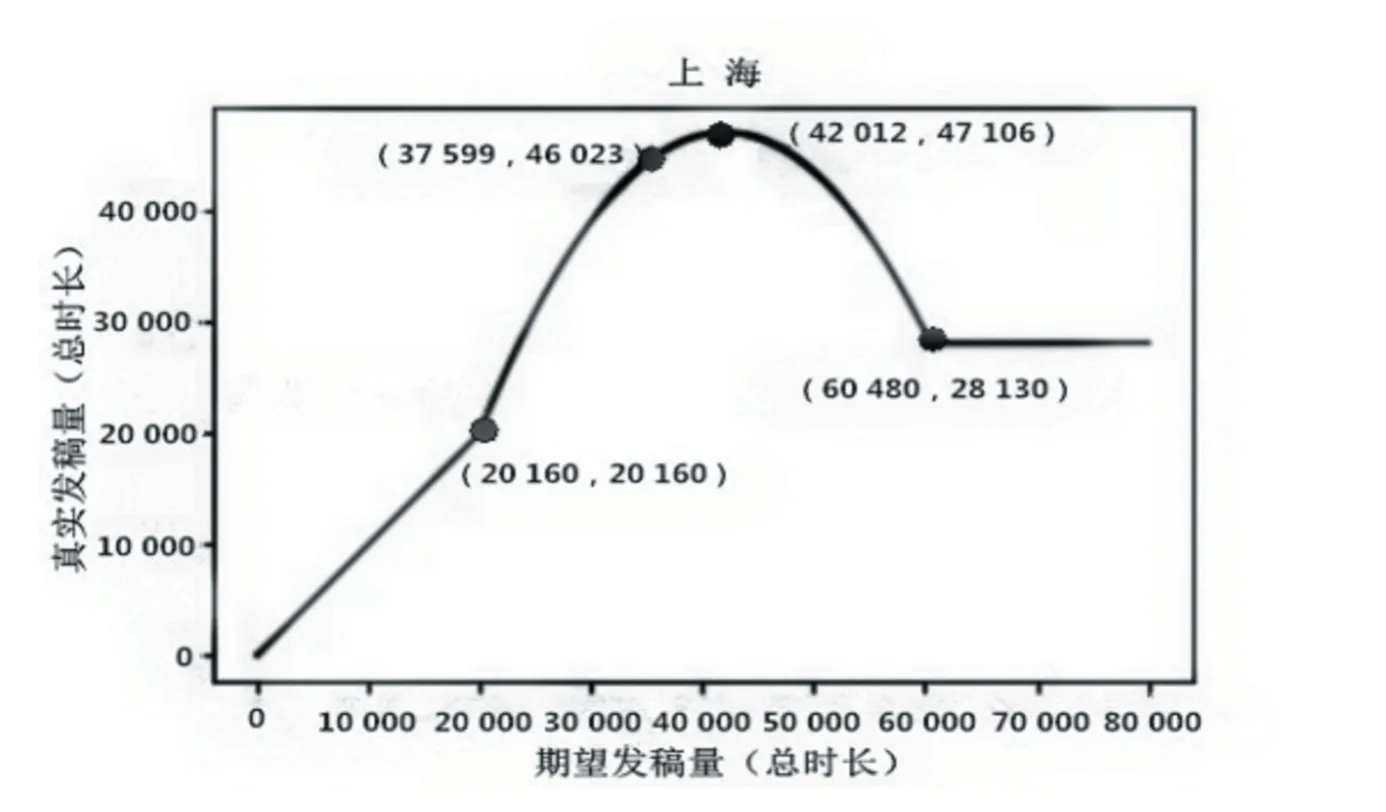
图4 期望发稿量与真实发稿量模型预测
拟合结果得到了四个坐标节点,分别是(20 160,20 160)、(42 012,47 106)、(60 480,28 130)和(37 599,46 023)。这四个节点标记了新闻内容生产效能的变化。在(20 160,20 160)之前,新闻内容的预期产出和实际产出呈45°直线。在(20160,20160)和(42012,47106)之间,新闻内容的预期产出和实际产出呈上升抛物线,并在(42 012,47 106)这一坐标点上达到最高值。在(42 012,47 106)和(60 480,28 130)之间,新闻内容的预期产出和实际产出呈下降抛物线,并在(60480,28130)之后,呈水平直线。在抛物线左侧(37599,46023)坐标点之前,导数值低于1,在此点之后导数值高于1。也就是说,(,(37599,46023)是抛物线与水平坐标轴的夹角呈45°的分界线。
由此,基于总工时则能够计算出三种不同形式的新闻内容的生产量。由于总工时确定之下,三种不同形式的新闻内容产量是互相约束、此消彼长的,便可以描绘出三种稿件的生产占用时间的比例随不同工作期望下的不同结果,如图5 所示。
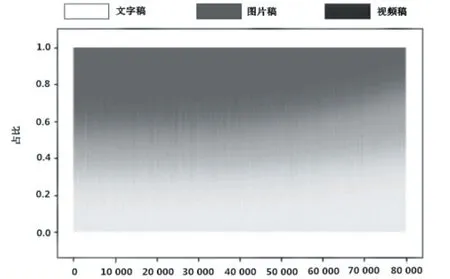
图5 各类稿件占比随月总工时的变化
根据图5,随着月度总工时的上升,文字类新闻的比例逐渐增加,音视频类新闻的比例则呈现逐步减少的趋势,图片类新闻基本保持恒定。
五、结论及不足之处
通过使用上海某媒体600 天新闻生产的真实数据,长短记忆神经网络(LSTM)模型计算后得到了对后续281 天新闻生产预期数据的推演,并与真实的281 天相比对,得到了期望发稿量与真实发稿量模型的预测结果。根据这一结果,可以得出以下结论:
(1)坐标点(20 160,20 160)约为126 名在职新闻工作者每天工作8 小时,每月工作20 天的总工作时长,与法定工作时间基本吻合。也就是说,在不需加班的情况下,真实新闻产量与预期呈现线性对应关系,所有预期的新闻产量都能够被如期完成。而坐标点(60 480,28 130)为126 名在职新闻工作者每人每天工作16 小时,每月工作30 天,这一工作时长形成了超平面,是新闻生产者的工作负荷极限。当预期新闻产量所需的工作时长超过这一负荷极限后,无论再怎么增加预期,都不能带来新闻真实产量的增长。这两个坐标点成为了工作时长的下限和上限。
(2)根据拟合结果,最优的预期新闻产量就是在预期总工时达到42 012 小时,即126 名在职新闻工作者大约每月工作时长约333 小时的时候,实际新闻产量可达到47 106 小时的效果,这一新闻产量也是实际内容生产总量的峰值。
(3)在(42 012,47 106)节点左侧,抛物线呈上升状态,表明提高预期对于新闻效能有正向的促进作用。而当超过(42 012,47 106)这一节点,抛物线呈下降状态,表明继续提高预期对于新闻工作者有负向的促进作用,真实新闻产量随着预期目标的上升而缓慢增长。
(4)在抛物线左侧,(,(37 599,46 023)坐标点之前的导数值高于1,在此点之后导数值低于1。这意味着,在(37 599,46 023)点之前,增加预期对新闻工作者的激励作用比45°对角线的效率更高。这一节点,即126名在职新闻工作者大约每月工作时长约298 小时的时候,实际新闻产量可达到42 012 小时的效果。而在(37 599,46 023)至(42 012,47 106)这个区间内,即使真实发稿量仍能够随着期望发稿量呈现正向增长,但是其增益速度已经低于期望的增长速度。也就是说,如果在这一区间内再继续给新闻工作者加压,他们虽然还能根据预期目标增加新闻产量,但是已经显示出力有不逮,难以继续。
综上,这一模型的拟合结论提供了一个全新的视角:按照既有的真实数据计算,126 名新闻工作者在法定工作时间内能够完成所有预期任务,且呈现出工作量不饱和、积极性未被充分调动激发的状况。在达到法定的工作时长并继续调高预期目标后,拟合曲线呈现抛物线上升,这证明了适度的工作压力反而能够更加充分地调动和激发新闻工作者的工作积极性,达到更高的效能。然而,这种超出预期的实际工作量增长并不能长时间持续,抛物线增长渐趋平缓,在到达(37 599,46 023)坐标点时角度小于45°,这表明新闻工作者在持续增加的预期目标压力之下无法保持足够的工作积极性,真实新闻产量逐渐放缓。进而,抛物线在到达顶峰后进一步下降。这是由于新闻业是一个创造性的工作,过高的预期产量会造成新闻工作者的过度焦虑、体力不济等,反而会伤害新闻效能。最终,当工作压力超出新闻工作者的能力,形成超平面,届时预期新闻产量对于实际不起作用。
因此,根据拟合结果,管理者日常的最优预期效能目标可以制定在抛物线起点至45°角的坐标点之间,即工作时长在每月20 160 小时到37 599 小时之间。当遇到重大新闻或者重要突发事件时,可短暂将最优效能目标调高至抛物线45°角至顶点之间,即工作时长在每月37 599 小时和每月42 012 小时之间,但总工时42 012 小时是总工作量的极限峰值。
根据图5 即各类稿件占比随月总工时的变化图可以观察出,当工作时间的预期要求较短时,新闻生产者一般会保持一个合理的生产数量,三类新闻产出的比例比较均衡。而当预期任务要求过高时,生产者会为了追求更多的新闻产量,刻意选择生产周期更短的新闻类型,即生产更多的文字稿件和图片稿件,而减少视频类稿件的产出,这从新闻内容生产上讲是一种不健康的规划方式。因此管理者应当制定适中的工作计划,以期达到合理的生产比例。
本研究主要做出了两个贡献:首先,提出将媒体的生产特征量化的方式并使用真实数据进行建模。在量化的过程中同时考虑了某媒体的基本属性和时序属性,基于此,做出的模型可以预测每日的发稿数量。本文使用的方法可以对更为复杂场景下的异构数据生产进行预测,在基于更大的数据量与更多维的数据描述下,可以得到更为精准的模型。其次,根据模型拟合了预期投入与真实产出之间的关系,因此可以更为科学和准确地制定出新闻内容生产量的预期目标。如果在相应数据支持下,这一模型可以应用于类似于新闻生产的知识性生产环境,如著作、文章等,针对具体情况,给出期望情况下能获得最高产出的产量预期。
本研究还存在以下几点改进空间:
(1)在应用循环神经网络进行产出预测时,需要提取更多的特征,来更加多维地建模描述一个媒体的生产能力。(2)目前的模型可以相对较准确地对单个新闻机构或知识生产型单位进行效能评估,但无法在更大的范围内使用。未来可以对内容产出进行更加细化的分类,进一步精准测算各类产出之间的约束关系(相关系数),如规制、外界影响等,以期得到更好的预测结果。(3)目前的新闻生产效能模型主要基于“人力—产出”这一逻辑,而忽视了近年来越来越多的机器人写作或其他智能化新闻生产方式,且新闻产出仍以传统的文字、图片、音视频类作品为主。当新闻生产环境随着科技发展而发生变化,或当AR、VR等实验性新闻产品的比例增加时,本模型无法对于届时的新闻生产效能做出评估。
