Web of Science科研社区挖掘算法研究
2020-12-09杜伟静王宇宸刘学敏
杜伟静,李 翀,王宇宸,刘学敏
1(中国科学院 计算机网络信息中心,北京 100190)2(中国科学院大学,北京 100049)
1 引 言
科技成果是评价一个国家社会发展程度的重要指标,通过对科技成果数据分析可以了解科研发展态势,对指导国家科研投入和产业布局有重大意义,其中论文是最重要的科研成果转化形式之一.本文主要针对WOS(1)https://webofknowledge.com/.网站中科院论文数据展开研究.
目前多数科研人员对论文的应用还仅限于微观,如通过阅读论文了解科研动态确定研究方向,而对论文宏观数据价值研究及各维度关联关系挖掘十分欠缺.部分已有研究仅停留在应用软件阶段,直接生成统计结论[1].目前应用最广的软件为陈超美博士研发的CiteSpace(2)http://cluster.ischool.drexel.edu/~cchen/citespace.,用于科学文献的识别并显示科学发展新趋势和新动态.文献[1]应用CiteSpace软件进行数据导入,选择对应算法得出结论,这在一定程度上不能按需定制,应用范围受限.另外当前针对论文数据的研究还存在一些问题:如文献[2]中数据分析维度单一,缺乏多样化,研究分析不具有实时与长远性,不能反映热点学科变化趋势.除此,当前研究在热点学科预测及潜在人才发现机制方面还处于欠缺状态.
鉴于以上问题,本文以多维度论文数据为依托,对数据进行了多角度的计量分析,确定了当前研究热点.实验采用Neo4j(3)>https://neo4j.com/.图数据库进行存储,利用优化后的Louvain社区发现算法(CommunityDetection)[3]对研究热点背后活跃学术圈进行挖掘.最后本文通过PageRank算法发现合著网络中的权威学者,了解其科研合作行为与合作关系,给科研学者与专家提供合作选择依据,从而促进科研合作的健康发展.
2 数据来源及相关技术基础
2.1 数据来源及数据格式
本文论文数据来源于WOS核心合集,分为艺术与人文(Arts&Humanities)、生命科学与生物医学(LifeScience & Biomedicine)、自然科学(Physical Science)、社会科学(Social Science)、应用科学(Technology)5大类.在数据收集过程中,本文采用网站数据直接导出并存储至HBase(4)https://hbase.apache.org/.的方式.最终收集了时间范围在1900-2019年来自中科院的论文数据共638177条.
本文随机筛选了其中60606条详细论文数据作为实验样本.这些数据经整理得到了73个数据字段.实验主要应用了以下核心字段:AF(作者全名)、TI(文献标题)、DE(作者关键词)、C1(作者地址)、NR(引用参考文献数)、TC(Web of Science 核心合集的被引频次计数)、U2(使用次数、DI(数字对象标识符DOI)、WC(Web of Science 类别)、SC(研究方向)等.
2.2 图数据库
论文数据之间有着复杂的关联关系,在关系型数据库中使用结构化形式一般不能直接表示这种联系.而图数据库没有模式结构的定义,在存储关联数据时采用非结构化的方式,数据关联特性表现的更加直接.常见的图数据库有Titan、Neo4j、OrientDB、JanusGraph、Trinity等.Neo4j与Titan和JanusGraph相比,用户生态更为完整;与Trinity相比,其边可以自带属性,同时Neo4j采用的操作语言Cypher直观易学习(5)https://www.cnblogs.com/zhongzihao/p/11328407.html, 2019-08-09..除此,Neo4j提供了完整的数据库特性,且存储结构均是单链表结构,在处理高度互连的数据时具有毫秒级响应的性能[4].Neo4j近年来发展迅速,应用范围越来越广,如文献[5]中用于磁盘图形处理算法的I/O开销测试;文献[6]中用于搜索问答系统底层数据存储.
Neo4j中实体(entity)、关系(relationship)示意图如图1所示.由于论文数据之间高度互联,背后隐藏关系错综复杂,这与Neo4j功能特性相吻合,故本文最终选择了Neo4j图数据库.
2.3 社区发现算法
社区发现算法是探寻社区内部节点关系紧密程度的一种方法.主要有两种思路,一种是凝聚方法,一种是分裂方法.GN[3]算法开启了社区发现领域的研究,主要是利用边介数删除边进行划分.随机游走算法是以某一个预设的概率作为转移概率,计算与相邻节点的距离,选择最小的两个社团C1和C2进行合并[7],但该算法应用范围受限.标签传播(Label Propagation)算法是一种自底向上的迭代算法,通过构造相似矩阵以及节点传播进行划分[8],但其在精度和稳定性等指标上还存在一些问题[9,10].
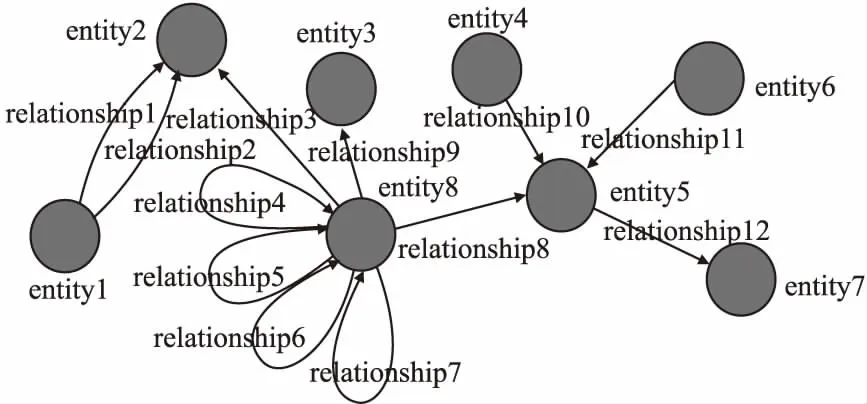
图1 Neo4j实体关系示意图Fig.1 Neo4j entity relationship diagram
Louvain算法是目前公认的运行速度最快的非重叠社区发现算法之一,采用模块度(Modularity)Q度量社区内部的紧密程度,算法通过两层迭代得到划分结果[11].近年来Louvain算法应用范围也越来越广,Jianping Zeng[12]等将其实现为可扩展的分布式算法,用于大规模的图数据社区检测;夏玮[13]等将其与流式处理框架相结合,应用于推荐系统;Ghosh[14]等对分布式Louvain算法委托分区进行优化,来确保处理器之间的工作负载和通信平衡.
根据实验数据特征及效率两方面考虑,本文最终选用了Louvain算法.
2.3.1 Louvain算法思想
Louvain算法是基于模块度的一种社区发现算法,是基于贪婪策略的优化方法[9],可以发现不同层次的社区结构[6].Louvain算法实现过程如图2所示,其两步迭代步骤如下.

图2 Louvain算法示意图Fig.2 Louvain algorithm diagram
1)将每篇论文看为一个社区,社区内部节点间连边权重初始为0.首先遍历所有论文节点,针对每个节点查找其所有邻居节点,并计算把该节点加入其相邻节点所在的社区所带来的模块度收益,最终选择收益值最大的邻居节点社区进行加入[15].
2)对步骤1中形成的社区重新折叠为一个新的单点,计算该新生成的“社区点”与其他社区点之间的连边权重,并计算该“社区点”内部节点间的连边权重之和,然后进行下一轮判断,直至结果达到最优[15].
2.3.2 评价模型
1)模块度
社区性强弱的衡量采用社区模块度指标Q表示,其定义如公式(1)所示[16].
(1)
m为论文语义图中节点间边的总数量;ki表示所有指向论文节点i的连边权重之和;kj表示所有指向论文节点j的连边权重之和;Ai,j表示论文节点i,j之间的连边权重;Ci是论文节点i的社区;δ(Ci,Cj)函数返回1表示论文节点i和论文节点j在同一个社区内,否则返回0[17].简化公式如公式(2)所示.
(2)
∑in表示社区C内部边的权重之和;∑tot表示与社区C内部节点相连的所有边的权重之和[17].
2)模块度增益
模块增益度是评价迭代效果好坏的数值化指标,这是一种启发式的优化过程,类似决策树中的熵增益启发式评价,如公式(3)所示.
(3)
ki,in代表由节点i入射集群C的权重之和;∑tot代表入射集群C的总权重;ki代表入射节点i的总权重[16].
2.4 数据计量分析
本文按5大类别分析了中科院论文发表增长趋势,如图3所示.结果表明应用科学论文发表数量年增速最大,在此基础上利用关键词共现、编辑距离算法等技术对研究热点进行了分析,其中计算机科学(Computer Science)论文发表增长速度较为突出,本文后续实验将针对计算机科学这一研究热点的论文数据展开.

图3 5大学科文献论文发表趋势图Fig.3 Trends in publications of five university literatures
3 算法优化
3.1 数据结构优化
1)本实验最初设计的实体为作者,即作者与作者之间进行关联,关系为workwith,存储形式为“作者-workwith-作者”.实验中由于作者众多出现关系爆炸情况,导致计算效率低、关系杂乱不明显.为了解决这个问题,本文加入论文作者署名排序,采用第1作者与论文直接关联,除第1作者外的作者与第1作者形成workwith关联关系,如图4所示.这降低了关联关系密度,同时提高了主要贡献者地位,有利于形成模块度较高的社区.
2)实体关系创建过程中,如果以作者全名为唯一标识会导致大量的重名作者错误的连接到论文和机构中,污染整个图数据关系结构.为了解决这个难题,本文计算“作者全名”+“作者所属全部机构”的hash值作为唯一标识“author_hash”来区分作者,提高作者的识别率,避免了图数据重名关系污染.

图4 作者署名排序实体关系图Fig.4 Entity relationship diagram of author signature
本文以2000条论文数据进行实验,以论文作者全名进行统计共得到14738位作者,以“author_hash”作为标识共得到18191位作者,结果表明重名率高达19%,重名现象严重.优化2)的应用有效的解决了该问题.
3)在创建实体关系的过程中,需要进行大量的属性对比,严重拖慢关系创建速度.Neo4j提供了索引功能[15],可以针对实体或实体属性建立索引,提升查询速度.本文根据数据特点建立了论文、机构、作者3个索引.

图5 步长为200的实体关系创建时间对比图Fig.5 Entity relationship creation time comparison chart with a step size of 200
本文结合以上3条优化策略进行了对比实验,以2000条实验数据为样本,每200条数据为间隔进行一次时间测量,实验结果如图5所示.结果表明数据插入性能显著提升(最高性能提升高达16倍),且随着数据量的增加,性能差距会进一步拉大.
3.2 关系属性优化
Louvain算法可通过关系权重(weight)调优提高实体间关联程度的计算精度,从而更加精确的挖掘社区[15].本文在作者间建立的workwith基础上添加属性weight,共采用了3种weight计算方式,第1种如公式(4)所示.即作者间合作次数为属性weight的值,随着合作次数的增加,作者间亲密度得到提升,属于同一社区的概率增加.
weight=作者间合作次数
(4)
公式(4)的weight计算方式过于简单化,没有多角度反映作者间关联程度,例如作者间合作强度、不同权威作者彼此间影响力、作者所属机构关系等.故本文实验第2种计算方式如公式(5)所示.利用Salton方法[18,19]度量合作关系强度,加入合著论文数量在作者学术生涯中占比.
(5)
hi,j指作者i与作者j合著论文数量,hi指作者i发表的所有论文数量,hj指作者j发表所有论文数量[18,19].
方法2中未考虑合著作者所属机构关系影响,对于同一机构内作者,作者间合作几率会相对较高,不同机构作者间合作几率会相对较小,所属机构不同不能同等看待.为解决该问题,本文在Salton方法基础上添加了合著作者间所属机构影响,即第3种计算方式,如公式(6)所示.
(6)
oi,j指作者i与作者j属于同一个机构的数量(一个作者可能属于多个机构),oi指作者i所属机构数,oj指作者j所属机构数,k为机构影响系数.
4 实验验证与分析
4.1 实验环境
操作系统:CentOS 7 64位,KernelLinux 3.10.0
开发环境:python3.7.3+Neo4j 3.5.13
芯片:IntelXeonSilver 4114@2.20GHz 40核心
内存:100GB
4.2 实验过程及结果分析
实验章节分为两个部分,首先详细描述了图数据库中实体关系创建及优化过程,其中数据结构优化参考3.1节.其次详细描述了针对Louvain社区发现算法的优化及应用,具体算法优化可以参考3.2节.

表1 实体关系属性表Table 1 Entity relationship attributeTable
第1部分实验从AF、C1、DI等WOS核心字段提取相关数据,创建实体及实体间的关系.实体类型为Author(作者)、Paper(论文)、Org(作者所属机构);实体属性包含name(全名)、community(所属社区号)、author_hash(作者哈希值)等;实体间关系为belong to、write、workwith.workwith中包含属性weight,如表1所示.最终实验中有论文数据60606条,作者423492位,机构103390个.其中计算机科学相关论文4199篇,作者为19200位,机构为26232个,生成workwith关系数为15799.

图6 机构影响系数变化图Fig.6 Change chart of mechanism influence coefficient
第2部分实验是对Louvain算法的应用,并对weight关系属性进行了3种方式的优化.针对公式(6)中机构影响系数的确定,进行了多次实验,实验结果如图6所示,当k为0.07时可得到最大模块度.

表2 weight优化前后模块度变化表Table 2 Modularity changes before and after weight optimization
实验以3.1节1)的优化为基础,对weight 3种不同计算方式进行了模块度对比,如表2所示.实验结果显示优化后模块度从0.5提升至0.9;在k为0.07且加入机构影响维度情况下模块度达到最优为0.9916.优化后比优化前模块度提升84.15%,提升效果明显.

表3 社区人数及社区中论文数量表Table 3 Number of communities and the number of papers in the community
最终实验共得到5005个社区,前10社区分布如表3所示.社区分布示意实例图如图7所示,其中大节点为论文,中节点为机构,小节点为作者.本文在挖掘出的科研社区基础上,利用PageRank算法对社区中权威优秀人才进行了挖掘,并计算出了每个作者的权威分数,最终筛选出科研高产出人才,如表4所示,其中前3名分别为“Yan,Zheng”、“Du,Jun”、“Ma,Wenping”.优秀科研人才的挖掘将帮助科研学者或专家了解科研合作行为及合作关系,并提供科研合作选择依据,从而促进科研工作快速发展.

图7 科研社区内部关系示意图Fig.7 Schematic diagram of internal relations in the research community

表4 权威科研工作者排名表Table 4 Ranking of authoritative researchers
5 总 结
本文对WOS中科院论文数据进行了多角度分析,首先利用数据计量分析得出应用科学为当前热点学科,计算机科学为学术界的研究热点.其次在研究热点基础上,利用Neo4j图数据库构建论文语义网络图,应用Louvain社区发现算法对科研社区进行挖掘,并针对关系属性weight的计算方式进行优化,进而提升了社区内部关联度.实验结果显示优化效果明显,模块度高达0.9916.最后以挖掘出的社区为基础,利用PageRank算法发现合著网络中的权威学者,了解其科研合作行为与合作关系,为科研学者与专家提供合作选择依据.
同时,本文研究工作还存在一些不足:如Louvain算法挖掘出的社区过大,人员和机构过多,后续将对社区进行二次挖掘.其次分析维度还不够全面,后续实验将加入基金专利数据,近一步提高数据分析精确度.除此,在下一步实验中将加入spark平台,通过机器学习算法构建模型,对潜在优秀人才进行挖掘,从而为国家人才培养提供参考性意见.
