基于植物油三维荧光光谱的茶油鉴定模型
2020-12-04卢先勇何文绚陈昊聪张燕杰
卢先勇,何文绚,陈昊聪,黄 睿,张燕杰
1. 福建省测试技术研究所, 福建 福州 350003 2. 闽江学院材料与工程系,福建 福州 350108 3. 福建省中国漆新型材料工程研究中心(闽江学院), 福建 福州 350108
引 言
高价植物油有橄榄油、茶油等,低价植物油如大豆油、玉米油、棕榈油、棉籽油等。 茶油的脂肪酸组成与被誉为“黄金液体”的橄榄油相似,有着“东方橄榄油”的美称[1],是联合国粮农组织推荐的优质食用油之一,在中国和亚洲一些国家越来越受欢迎。 一些不法商家在高价油中掺入低价油、地沟油等来谋取暴利,严重侵犯了消费者的权益,也危害了食用者的安全。 建立高效的茶油鉴定方法对于防止茶油掺伪、维护消费者权益具有重要意义。 植物油鉴定主要基于对特征成分如脂肪酸构成、甾醇、生育酚检测[2-4]进行判定。 主要的检测方法有荧光光谱、红外光谱、拉曼光谱、色谱、核磁共振等[5]。 近年来也发展了化学计量学方法与上述检测方法结合的植物油鉴定技术。 荧光光谱灵敏度高,选择性强。 植物油的主要荧光物质是不饱和脂肪酸、维生素E和色素[6]。 方晓明等[7]利用同步荧光光谱仪在250~720 nm的激发波长下,采集分析了多种掺杂特级初榨橄榄油的同步荧光光谱图,研究结果显示: 依据同步荧光光谱能将大部分掺杂特级初榨橄榄油与橄榄油区分,但由于大豆油与特级初榨橄榄油的同步光谱基本相同,该法无法鉴别掺入大豆油的掺假橄榄油。 三维荧光光谱描述了荧光强度同时随激发波长和发射波长变化的关系,因此能完整地描述物质的荧光特征。 方惠敏和黄秀丽等分别对多种植物油的同步荧光光谱和三维荧光光谱进行了分析研究,研究结果表明: 三维图谱具有指纹识别能力,比同步荧光光谱提供的信息更加直观,但三维荧光光谱除了与植物油品种有关外,还与植物油加工工艺、果实原料来源等因素有很大关系。 多个研究表明: 植物油脂中的荧光物质具有高度相似性,本研究团队研究了多品牌茶油、大豆油、玉米油以及掺伪茶油的三维荧光光谱,发现很难通过观察三维荧光光谱直观地区别茶油与其掺伪油。 三维荧光光谱的指纹识别能力,对于植物油鉴定,有明显优势,一些学者已经应用荧光光谱结合化学计量学方法对植物油的分类及掺杂进行了研究[8],其中平行因子分析法(PARAFAC)是目前最常用的三维荧光光谱数据分析方法[9]。 考虑到掺假茶油与茶油的三维荧光光谱差异较小,PARAFAC数据分析方法还有不足,限制了其进一步应用。 瑞典Umetrics公司开发的一款多元变量统计分析软件SIMCA,其最新版本SIMCA15.0.2中的Orthogonal partial least squares discriminate analysis(OPSL-DA)非常适合于植物油类别鉴定。 本研究利用自编小程序,将三维荧光的二维函数表达转换成一维函数表达,尝试用这种新的方法表达三维荧光光谱数据,在SIMCA15.0.2软件平台上,利用OPSL-DA构建特异性、敏感性符合实际应用要求的茶油鉴定模型,为基于植物油三维荧光光谱数据,构建植物油快速鉴定模型,提供了一种新的思路。
1 实验部分
1.1 仪器、试剂、样本
F-4600型荧光分光光度计,日本株式会社日立高新技术公司; 石油醚30~60 ℃(分析纯),常熟市鸿盛精细化工有限公司。
(1)训练集样本: 54个训练集样本都购于大型超市,其中14个品牌茶油的17个样本(购自福建、江西、广西、浙江; 制作工艺全部是压榨); 10个品牌玉米油的19个样品(购自黑龙江、广东、福建、甘肃、陕西、河南等六个省份; 制作工艺全部是压榨; 19个玉米油样本中14个样本标注非转基因,5个样本未标注非转基因); 11个品牌大豆油的19个样品(购自黑龙江、山东、福建、吉林、陕西、河南等六个省份; 9个压榨,10个浸出; 10个样本标注转基因,9个样本标注非转基因)。 以上这些植物油样本,经气相色谱(GB/T 17377—2008)验证,其脂肪酸组成都符合相应植物油的中国国家标准。 训练集样本概况见表1。
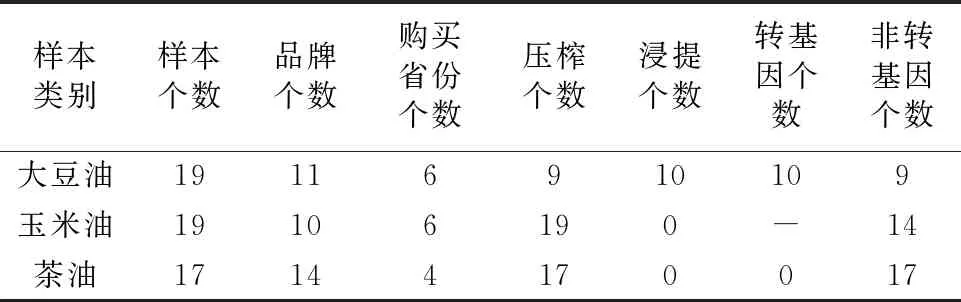
表1 训练集样本概况Table 1 Training set sample overview
(2)检验集样本: 27个检验集样本包括7个购于大型超市且与训练集样本非同品牌同批次的茶油样本; 18个掺伪茶油样本,它们是以茶油为主体油,在实验室中分别掺入大豆油、玉米油、棕榈油、棉籽油、混合油1(由大豆油、棕榈油、棉籽油、玉米油按1∶1∶1∶1体积比混合)和混合油2(由大豆油∶玉米油∶花生油按1∶1∶1体积比混合),配制成掺伪浓度分别为4%,10%和16%(体积比)的掺伪茶油; 2个购于乡村小店的盲样(Camellia-rural-1和Camellia-rural-2),这两个盲样经气相色谱鉴定,它们的脂肪酸构成不符合茶油设定值,是假茶油。
1.2 方法
1.2.1 植物油样本荧光光谱采集
10 mm石英样品池用石油醚清洗干净,加入约1 mL植物油样。 荧光光谱采集实验参数: 激发波长范围200~580 nm,间隔10 nm; 发射波长范围250~700 nm,间隔10 nm; 扫描速度2 000 nm·min-1; 激发狭缝10 nm; 发射狭缝10 nm; 光电倍增管电压400 V; 响应时间0.5 s。
1.2.2 荧光光谱数据获取
(1)样本荧光光谱数据设定: 激发位置数=(580-200)÷10=38(个),构成矩阵横坐标; 发射位置数=(700-250)÷10=45(个),构成矩阵纵坐标。 由此条件获取样本荧光光谱矩阵二元数据集,共有对应激发-发射位置变量值=38×45=1 710个。
(2)通过SAS 9.4版软件编程方法,将样本荧光光谱矩阵数据集转化为1 710个变量值的一元数据集。 主要程序模块:
①按样本矩阵横坐标的激发位置数分解数据集,本案例生产38个分解数据集。
②将样本上述分解数据集,追加汇总,再转换为一元关系数据库。
1.2.3 茶油鉴定模型构建及评价
将各集样本数据导入Umetrics SIMCA15.0.2软件。 采用OPLS-DA算法,基于训练集样本构建茶油鉴定模型。 根据训练集样本茶油类别得分值,设定茶油得分值范围。 然后依据该模型预测检验集样本分值,基于检验集样本的预测结果,获取模型特异性及敏感性数据。
2 结果与讨论
2.1 各集样品设计
各种植物油主要成分相似,大豆油和玉米油的价格相对较为低廉,是最可能的掺伪茶油掺杂物。 因此,训练集样本由茶油、大豆油、玉米油三类植物油构成。 考虑到植物油的成分除了与其种类有关,还与植物的种植地和植物油的加工工艺有关。 多个品牌大豆油样本、购买地点涵盖我国东南、东北、西北、华中,加工工艺包含压榨与浸提这两种大豆油主要加工工艺,还包含10个转基因与9个非转基因样本; 多个品牌玉米油样本、购买地点涵盖我国东南、东北、西北、华中,19个加工工艺是压榨,14个标注非转基因,5个未标注; 市面上茶油都是采用压榨工艺得到的,所以茶油只有压榨工艺的样本,一般南方较多使用茶油,北方很少使用,多个品牌茶油购买地点都在南方。 经过以上设计的样本能较好地代表大豆、玉米、茶油。 模型特异性与敏感性数据来源于检验集的测试结果。 检验集样本与实际越符合,相关的数据越有代表性。 掺伪茶油通常是在茶油中掺入低价油或它们的混合油,分别选取大豆油、玉米油、棕榈油、棉籽油以及这四种低价油按等体积比混合得到混合油1,花生油是我国使用量最大的植物油之一,厨余油中花生油可能性大,因此选取大豆油、玉米油、花生油按等体积比混合得到混合油2,以上油添加到茶油中,配制成三个(4%,10%和16%)掺伪水平共18份掺伪茶油样本。 此外,在掺伪相对严重的乡村小店购买2个茶油命名为Camellia-rural-1和Camellia-rural-2。 再加上7个不同品牌的茶油(保证其与训练集茶油样本非同品牌同批次)。 这样,检验集中共有27个样本,如此设计的检验集样本能很好地代表目前植物油市场中茶油及掺伪茶油。
2.2 植物油三维荧光谱图分析
图1为训练集中某个茶油、大豆油、玉米油样本的荧光等高线图,由图1可知茶油、大豆油、玉米油样本谱图相似,三者比较,茶油没有明显的特征。 图2为茶油、添加6%低价混合油1的掺伪茶油、添加12%玉米油的掺伪茶油的三维荧光谱图,由图2可知添加12%玉米油的掺伪茶油与茶油的谱图几乎相同,添加6%低价混合油1的掺伪茶油与茶油谱图有差异。 图3为三个品牌茶油的荧光等高线图,其中福建沈郎乡茶油(a)与广西巴马茶油(c)颜色较浅是经过精炼的茶油,福建丰达牌茶油(b)颜色深是未精炼的,其谱图在色素位置有较强荧光峰,图3提示不同品牌茶油的荧光等高线图有差异,由于加工工艺不同或植物产地不同导致不饱和脂肪酸、生育酚、色素等类别荧光物质的构成不同,使得茶油样本之间三维荧光光谱有差异。 茶油、玉米油、大豆油最强荧光峰位置见表2。 表2 的17个茶油样本中有3个样本含有两个较强荧光峰,这3个样本都是颜色较深的未精炼茶油,其他14个样本是经过精炼的茶油只有一个较强峰。 总结图1、图2、图3以及表2得出: ①茶油与玉米油尤其大豆油的谱图差异小; ②添加12%玉米油的掺伪茶油其谱图与茶油基本相同; ③不同加工工艺的茶油其谱图有较大差异。 本文收集了大量样本,样本涵盖不同加工工艺、不同植物种植地,与已发表的文献相比,较全面地展示了三类植物油的三维荧光谱。 通过以上分析结果,可以得出仅通过观察样本的三维荧光谱很难进行茶油鉴定。
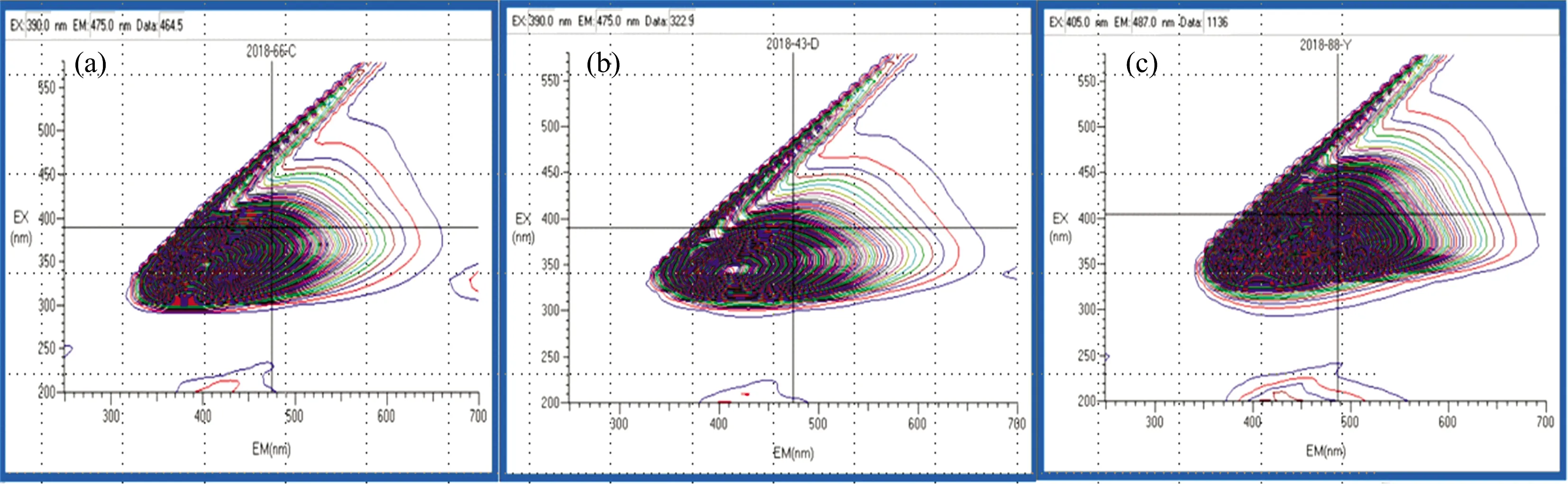
图1 茶油(c)、大豆油(b)、玉米油(a)荧光等高线Fig.1 Camellia oil (c),soybean oil (b),corn oil (a) fluorescence contour

图3 沈郎乡茶油(c)、丰达茶油(b)、巴马茶油(a)荧光等高线Fig.3 Fluorescence contours of Shenlang Xiang Camellia oil (c),Fengda Camellia oil (b), Bama Camellia oil (a)
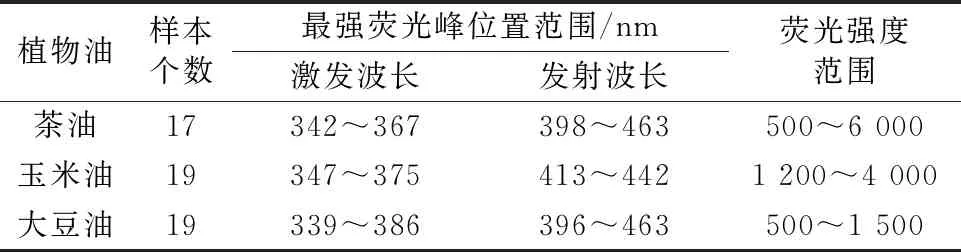
表2 茶油、玉米油、大豆油最强荧光峰位置及其强度值
2.3 基于三维荧光光谱数据的茶油鉴定模型构建及评价
为了更好地应用三维荧光光谱鉴定茶油, 引入化学计量学方法。 三维荧光光谱的数据是以 EEM矩阵表达,表征了特定激发波长、发射波长位置处的荧光强度。 每个样本用二元函数z=f(EI,EM)表达。 本研究探究用一元函数z=f(EI-EM)来表达样本三维荧光光谱,在此基础上在SIMCA15.0.2软件平台上应用OPLS-DA方法构建茶油鉴定模型。 为此,编写了小程序,在SAS软件平台运行该小程序将二元函数z=f(EI,EM)转换成一元函数z=f(EI-EM),每个样本用一维数据表示。 这样可用矩阵数据来表达各集样本,矩阵中第一行是EX200-EM250 EX200-EM260 EX200-EM270 … EX200-EM700 EX210-EM250 EX210-EM260 EX210-EM270 … EX210-EM700第一行的最后是EX580-EM250 EX210-EM250 EX580-EM260 EX580-EM270 … EX580-EM700共1 710个(EX***-EM***)位置值,第一列是样本号,其他单元格数值是各样本在对应位置的荧光强度值。 将训练集样本矩阵数据导入SIMCA15.0.2软件中,采用OPLS-DA构建茶油鉴定模型。 图4为OPLS-DA模型的二维得分图,图4显示茶油区域与大豆油、玉米油区域距离较远,茶油可以很好地与玉米油、大豆油区分,玉米油区域与大豆油区域很接近。 模型关键参数如图5,由图5可知代表拟合能力的参数R2=0.84; 代表预测能力的参数Q2=0.72,变量数=2,提示该模型是一个优秀的模型。 训练集样本中茶油在其类别的得分值都在0.70~1.15范围,因此将该得分值范围定为茶油的设定值。 用该模型对检验集样本进行预测,预测结果见表3。 表3显示模型对检验集样本的7个茶油得分值都在0.70~1.15范围,判定为茶油,判定结果全部正确; 掺伪茶油包括掺伪水平只有4%的混合油1、混合油2的掺伪茶油,它们的分值都不在0.70~1.15范围,判定为非茶油或掺假茶油,判定结果也全部正确; 两个购买于乡村小店的茶油分值不在0.70~1.15范围,判定为非茶油或掺假茶油,经过气相色谱分析,这两个样本的油酸及亚油酸浓度都不符合茶油国家标准(GB/T 11765—2018 油茶籽油)规定的设定值,是伪茶油,证明模型判定结果是正确的。 模型的特异性、敏感性及其水平数据见表4。 模型的主要参数值及检验集样本的预测结果都表明,用本文首次提出的一维函数表达的三维荧光光谱结合正交偏最小二乘判别分析,可以构建特异性、敏感性符合实际要求的茶油鉴定模型。 目前最通用的三维荧光光谱数据降维、提取方法是平行因子法,其处理数据时收敛非常慢,完成三维荧光谱的数据分析需要太长的程序; 此外需要精确的估计组分数,否则将导致模型产生很大偏差[10-11],由于本文研究的茶油鉴定模型对检验集27个样本的预测全部正确,且对掺入与茶油脂肪酸构成极为相似的玉米油、大豆油以及各种混合油,掺入量4%即可检出; 对于两个盲样的预测结果也是正确的,说明用一元函数z=f(EI-EM)替代目前通用的二元函数z=f(EI,EM)来表征三维荧光数据,既简单、方便又可以很好地体现茶油的类别特征,结合正交偏最小二乘判别分析,可以构建符合市场要求的茶油鉴定模型。

图4 训练集样本二维得分图 红色玉米油; 蓝色大豆油; 绿色茶油Fig.4 Two-dimensional score map of training set samples red corn oil; blue soybean oil; green tea oil
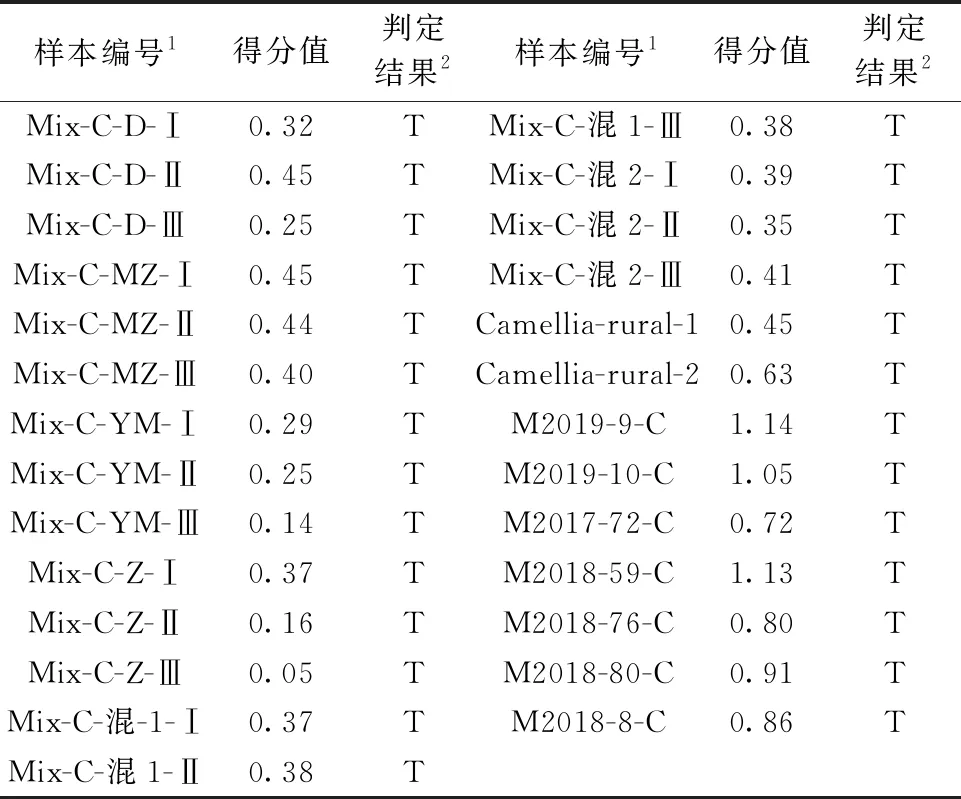
表3 检验集样本茶油类别得分值Table 3 Camellia oil category score valuesof the samples in test set
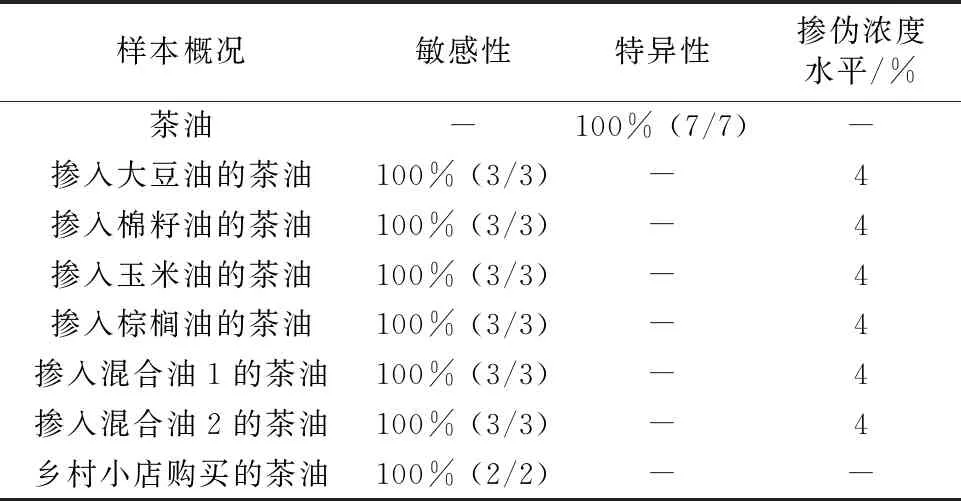
表4 OPLS-DA茶油鉴定模型特异性、敏感性及其水平Table 4 Specificity, sensitivity and its level of camellia oilidentification model (OPLS-DA)
3 结 论
通过编写小程序将样本三维荧光光谱的二维函数表达转换成一维函数表达,形成训练集、检验集样本数据矩阵,再结合正交偏最小二乘判别分析,构建基于植物油三维荧光光谱数据的茶油鉴定模型,该模型对27个检验集样本的鉴定结果全部正确,能够鉴别添加量仅为4%,且掺杂物主要成分与茶油非常相似的(如玉米油、大豆油、混合油)掺伪茶油,为应用植物油三维荧光光谱进行快速植物油鉴定,提供了一种新的思路。 与现有的平行因子数据处理方法相比,本文建立的处理方法,过程简单、模型预测效果好,但在解释各成分贡献方面不如平行因子法。 本法适用于筛查掺伪植物油,不适用于分析掺伪量及其掺伪成分。 今后将通过分析更多的植物油种类,探究有效数据区域,进一步扩大应用领域。
