基于领域本体和依存句法分析的主观题自动评分方法
2020-12-03王金水郭伟文唐郑熠
王金水,郭伟文,唐郑熠
(1.福建工程学院 信息科学与工程学院,福建 福州 350100;2.福建工程学院 大数据挖掘与应用技术重点实验室,福建 福州 350100)
随着大数据、物联网和人工智能的新兴技术不断向教育领域、工业领域等渗透,在教育领域中人工智能技术愈发普及使得其发挥着不可或缺的作用。在教学过程中,将人工智能应用到教学辅助学习中,可以有效地提高工作效率并提高教学质量。通过自动评分系统的应用,教师不仅可以减少阅卷的工作量,而且可以使阅卷结果更加公平公正。主观题自动评分系统的实现也是目前广大学者研究的重点和难点[1-2]。现有的自动评分系统已经解决了客观题的评分问题,但对于主观题评分的实现,困难更多且要求更高。一方面,主观题自动评分系统的建立需要较为成熟的自然语言处理技术以及人工智能技术等;另一方面,答案文本的多样性和灵活性造成计算机对于文本的理解和人类对于文本的理解出现偏差。因此,构建具有普适性的主观题自动评分系统的难度系数非常大。研究者通过分析现有的主观题自动评分系统中的运用技术和评分模型,可以更深入地理解自动评分系统。而且自然语言处理以及本体和知识图谱的快速发展也为研究者提供了新的研究思路和研究方式。
主观题自动评分方法基于学生答案文本与参考答案文本的相似度进行评分。两者的相似程度越高,则学生答案的得分就越高[3]。现阶段,词语相似度和句子相似度是主观题自动评分系统评分的主要依据。词语相似度计算大体分为基于语义词典的方法[4]和基于大规模语料库统计的方法[5]。其中,基于语义词典的方法在自动评分系统中的应用最为广泛。特别地,汉语主观题自动评分方法多数使用知网语料库和同义词词林作为词语相似度计算的语义知识源。对于句子相似度,很多学者从不同角度提出各种计算方法,主要有基于相同词汇的方法[6]、基于编辑距离的方法[7]、基于向量空间的方法[8]、基于词语语义的方法[9]和基于句子结构分析的方法[10]等。
目前,自动评分系统大多无法识别用于电力系统分析领域的专业术语,且在评分过程中易遗漏文本间的语义关系,从而导致其评分结果与人工评分结果的偏差较大。针对这一问题,本文将电力系统分析领域本体和同义词词林作为词语相似度计算的语义知识源,增强评分系统对专业术语与语义关系的辨识能力。此外,现有的主观题评分方法仅考虑文本的少量特征信息,不能较为全面地衡量学生答案与参考答案在不同角度的相似度。本文综合考虑词语的表层信息和结构信息、词语之间的语义关系以及依存句法的结构信息,进而更加准确地进行句子相似度计算。针对主观题自动评分方法存在的不足,本文根据词语相似度计算方法和句子相似度计算方法,提出基于领域本体和依存句法分析的主观题自动评分方法,将专业术语相似度计算和多个重要特征信息考虑在内,有效地提高了主观题自动评分结果的准确性。
1 相关工作
近年来,自然语言处理的应用领域愈发广泛,并成为众多领域的研究热点[11]。国内外学者在主观题自动评分过程中引入自然语言处理技术,以提高答案文本间相似度计算的准确度。
高思丹等[12]利用动态编程模式的方法设计了句子相似度计算方法,对句子进行浅层的句法结构分析,但该方法存在评分准确度不高的问题。苏方方[13]运用句框架技术并引入本体库,在此基础上提出了一种基于句框架的自动评分方法,从而提高了评分结果准确度的精度。张均胜等[14]结合人工制定文本相似标准、词语集合及词语次序和同义词的短文本相似度计算方法,设计并实现相应文本主观题阅卷系统,使得自动阅卷结果接近人工阅卷结果。田久乐等[15-16]提出了基于同义词词林和知网语料库的词语相似度计算方法,通过扩充可计算词语的范围,提高了词语相似度计算的准确率。曹建奇[17]引入相似词计算模型,并提出了成分关系相似度计算方法,从而改进了句子相似度计算方法的准确率。陈贤武等[18]从关键词、句法、语义三方面的文本特征建立以语义为核心的多特征相似度计算模型,提出了基于语句相似度的主观题自动阅卷评分方法。王逸凡等[19]基于语义相似度以及命名实体识别目标关键词两方面,提出了一种主观题自动评分方法,该方法解决了过长文本词语相似度计算匹配效率低的问题。郭炳元[20]引入具有权重的语义依存树,提出了基于语义树的短文本相似度计算方法的自动评分系统。
虽然现有的评分方法能够实现对主观题的自动评分,但是对于一些专业性较强的领域,不论是采用基于改进的同义词词林的方法还是基于知网语料库的方法,都难于准确地计算专业术语之间的相似度。由于领域本体与通用词库之间存在极强的互补性,因此可以在评分过程中将两者进行结合,不仅能够准确地识别答案文本中的专业术语,还能有效地利用文本间的语义关系计算学生答案与参考答案的相似度。
2 基于领域本体和依存句法分析的评分方法
2.1 主观题自动评分模型
基于词形相似度和搭配词对相似度,本文提出了一种可用于电力系统领域的主观题自动评分方法。自动评分模型如图1所示。首先,将电力系统分析领域的专业词汇导入汉语处理包(Han language processing, HanLP)的词典中,以提高系统对专业术语的分词能力,并利用HanLP对文本数据进行中文分词、词性标注、句法分析等预处理操作。其次,可将答案文本所包含的词语分为专业术语和通用词语,并利用电力系统分析领域本体和同义词词林分别计算专业术语之间以及通用词语之间的词语相似度。再次,通过结合词形相似度和搭配词对相似度的计算结果,得到学生答案文本与参考答案文本的句子相似度。最后,从学生答案文本与所有参考答案文本的相似度计算结果中取出最大值,将其作为学生答案的最终得分。
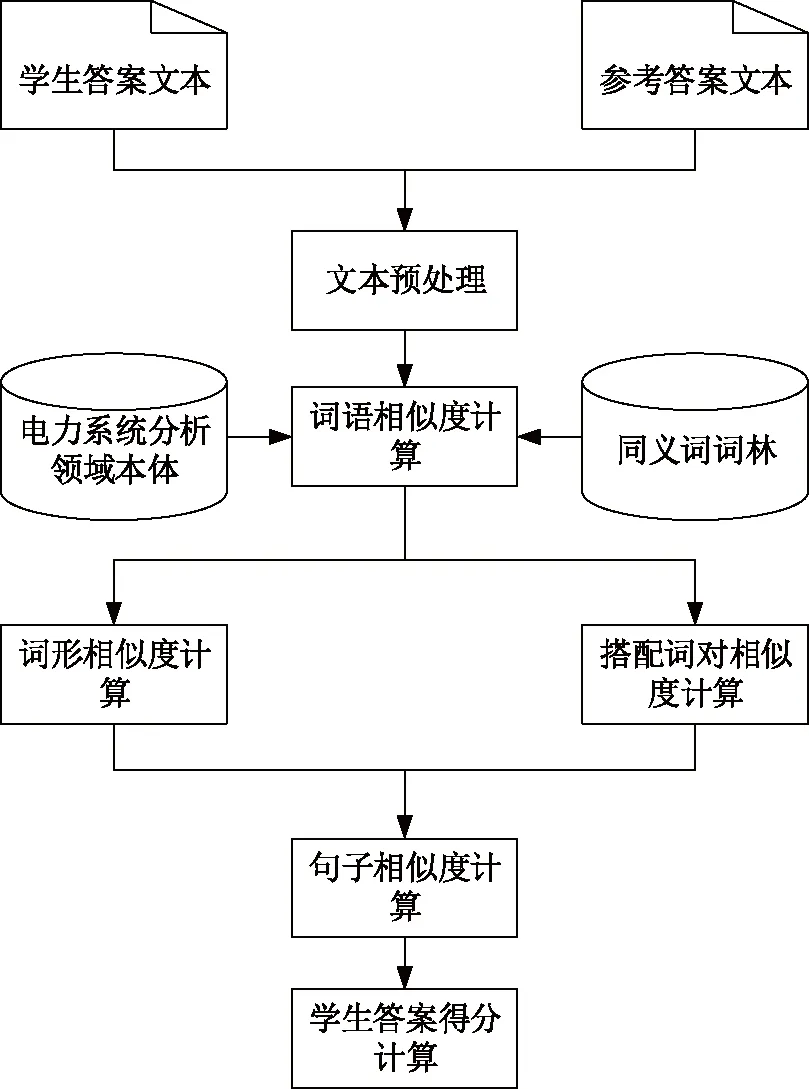
图1 主观题自动评分模型
2.2 词语相似度计算方法
2.2.1专业术语相似度计算
专业术语相似度是通过引入电力系统分析领域本体进行计算。领域本体可以看成有向图G(V,E),表示专业术语间的关系,其中:V表示在有向图上所有节点集合,每个节点代表领域本体的概念;E表示有向图中边的集合,每条边表示概念间的某种语义关系。专业术语相似度计算综合了节点距离和节点信息两个因素。
在有向图中,计算节点距离相似度需确定有向边的权重和节点间的最短路径。其中,影响节点有向边的因素有节点间的关系、节点深度和节点密度。综上所述,节点h和节点k之间的有向边权重可表示为式(1):
W(h,k)=φ1×Wr+φ2×Wp+φ3×Wd。
(1)
式中:Wr表示节点关系权重,Wp表示节点密度权重,Wd表示节点深度权重;φ1、φ2、φ3为调节因子,取值范围为(0,1),且φ1+φ2+φ3=1。综合考虑节点间的关系、节点密度和节点深度在电力系统分析领域本体和节点距离相似度计算中的地位和作用[21], 调节因子φ1、φ2、φ3可分别设置为0.6、0.2、0.2。
确定有向边的权重后,节点与节点之间的语义距离就是路径中有向边权重的总和。定义父节点Ph和节点h的语义距离公式如式(2):
(2)
则节点h和节点k的语义距离计算如式(3):
D(h,k)=D(h,L(h,k))+D(L(h,k),k)。
(3)
式中:L(h,k)表示节点h和节点k的最低公共祖先;D(h,L(h,k))表示节点h到L(h,k)的路径中的所有有向边的语义距离总和。
综上,可得到节点距离相似度如式(4):
(4)
式中,dmax是本体有向图中节点的最大深度。
在本体的有向图中,节点间共享的信息量越多,说明相似度就越大。本文根据最低公共祖先表示节点信息相似度。对于本体有向图中的两个节点h和k,节点信息相似度如式(5):
(5)
式中,I(L(h,k)),I(h),I(k)分别是最低公共祖先节点、h节点和k节点的信息量。
综合考虑节点距离相似度和节点信息相似度,得到专业术语的相似度如式(6):
Sonto(h,k)=ω×Sd(h,k)+θ×Si(h,k)。
(6)
式中:ω、θ为调节因子权重,取值范围为(0,1),并且ω+θ=1。考虑到节点距离相似度和节点信息相似度的贡献是一致的,将ω、θ都设置为0.5。
2.2.2通用词语相似度计算
对于通用词语相似度计算,本文使用改进的同义词词林相似度计算方法。同义词词林通过五层树形结构来构建词林,根据从底层到高层(D1→D2→D3→D4→D5)的顺序,对连接上下两层的有向边语义距离给予不同权重。参考朱新华等[16]的实验设计,将有向边的权重分别设置为W1=2.5,W2=1,W3=2.5,W4=0.5。词语y1和词语y2的语义距离计算如式(7):
(7)
在改进的同义词词林方法中,词语的连接路径是影响词语相似度的主要因素,而最低公共父节点的节点密度N和间隔距离K属于次要因素。因此,可将节点密度N和间隔距离K作为调节因子加入到词语相似度计算中,那么通用词语y1和词语y2的基于同义词词林的相似度计算如式(8):
(8)
2.3 句子相似度计算
2.3.1搭配词对提取改进算法
通过依存句法分析等预处理后,能提取文本中词语间的关系,将词语间的关系定义为搭配词对。搭配词对是由中心词、依存词和词语的关系构成,表示形式为(中心词,关系类型,依存词)。
改进的搭配词对提取算法流程如图2所示。通过该提取方法,可以降低语义冗余,提高评分算法的准确性。答案文本经过预处理后,可表示为:S=((x1,r1,x2),(x3,r2,x4),…,(xi,rj,xi+1),…,(xn,rm,xn+1))。S表示句子,xi和xi+1表示一对搭配词对,xi是中心词,xi+1是依存词,rj是搭配词对的关系类型。
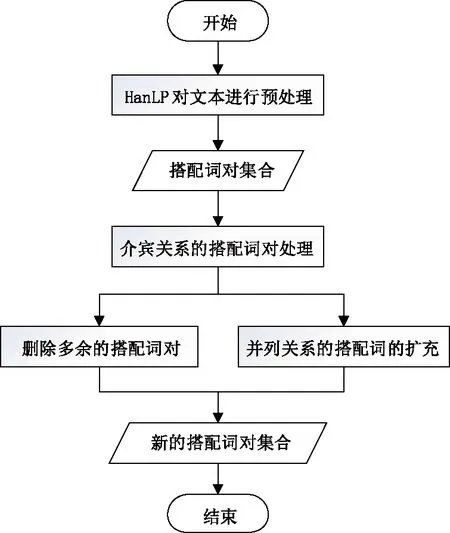
图2 搭配词对提取的改进算法流程
2.3.2词形相似度计算
词形的相似度反映句子的词语信息,是用学生答案和参考答案两组文本的相似词汇的个数来衡量,反映句子的表层词语信息。参考答案文本S1和学生答案文本S2的词形相似度计算如式(9):

(9)
式中:G(S1,S2)表示文本S1和文本S2相似词汇的个数,H(S1)表示文本S1的词汇总数,H(S2)表示文本S2的词汇总数。
2.3.3搭配词对相似度计算
影响搭配词对相似度计算的因素有两点:一是两组搭配词对关系类型的匹配程度;二是搭配词对的中心词和依存词的语义权重。在同一关系类型中,中心词在句子中是作为逻辑关系的枢纽,而依存词更多地体现搭配词对中结构信息和语义信息的特征。因此在搭配词对相似度计算时,赋予中心词的权重和依存词的权重是不一致的,并且中心词的权重要小于依存词。
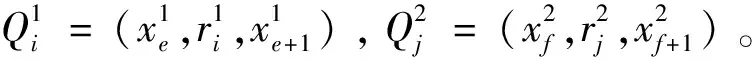
(10)
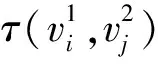
文本S1有m组搭配词对,文本S2有n组搭配词对。将文本S1所有的搭配词对和文本S2所有的搭配词对进行相似度计算,得到搭配词对相似度矩阵如式(11):
(11)
然后遍历矩阵N(S1,S2),取出每行相似度最大的搭配词对,得到Nmax(S1,S2),如式(12):
Nmax(S1,S2)={SQmax1,SQmax2,…,SQmaxp}。
(12)
文本S1和文本S2在搭配词对层面的相似度计算如式(13):
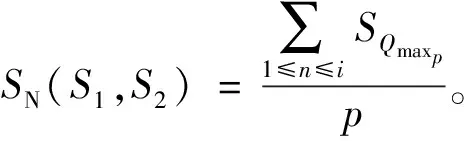
(13)
式中,p表示Nmax(S1,S2)的容量,当p=0时,文本S1和文本S2相似度为0。
2.3.4句子相似度计算
考虑到答案文本的多样性,为了避免造成较大的文本相似度误差以及语义组合带来的差异,本文综合考虑专业术语、通用词语、词形相似度以及搭配词对相似度等关键因素,得到参考答案文本S1和学生答案文本S2的相似度计算如式(14):
ST(S1,S2)=α×Swf(S1,S2)+β×SN(S1,S2)。
(14)
式中,α和β分别是句子的词形相似度的权重系数和句子搭配词对相似度权重系数,α、β取值范围为(0,1),且α+β=1。
2.4 学生答案得分计算
由于在主观题考试中,往往存在同一问题拥有多个参考答案的情况。考虑到预先给定的参考答案无法包含学生所有的答案文本,因此通过构建参考答案集,将学生答案文本与不同的参考答案文本进行相似度计算,最后取其中的最大值作为学生的最终得分。学生答案得分计算公式如式(15):
SF=max{ST1,ST2,…,STn}。
(15)
式中,ST1,ST2,STn分别表示学生答案文本与第1个参考答案文本、第2个参考答案文本以及第n个参考答案文本的相似度计算得分。
3 实验与分析
3.1 实验数据
为了验证本文所提出的主观题自动评分方法的有效性,本节通过实验将该方法与基于汉语依存句法分析的评分方法(评分方法1)[22]、基于短文本相似度计算的评分方法(评分方法2)[14]、基于语义相似度及命名实体识别的评分方法(评分方法3)[19]进行比较。实验数据来自一场《电力系统分析》课程的主观题期末考试,考试包含10道简答题。该考试于2020年1月进行,有76名福建工程学院电气工程及其自动化专业的本科生参与此次实验。最终,我们随机抽取10份学生提交的答卷,并使用教师人工阅卷的评分结果作为基准数据,以此作为本次实验分析的数据集。
3.2 评价指标
主观题自动评分方法的计算结果可以通过各种相关性和一致性的测量方法与教师评分结果进行对比,通过相关性和一致性结果评判不同评分方法的优劣。常见的测量方法包括平均绝对误差(mean absolute error, MAE)、均方根误差(root mean square error, RMSE)、对称平均绝对百分比误差(symmetric mean absolute percentage error, SMAPE)。这些测量方法的计算公式如下:
(1)平均绝对误差:
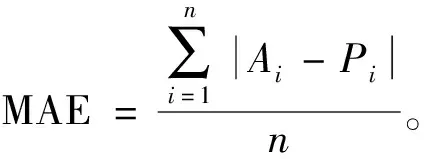
(16)
(2)均方根误差:
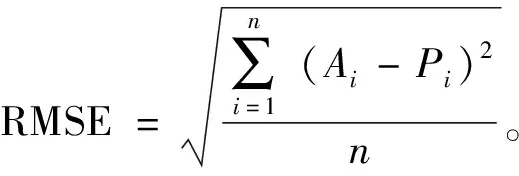
(17)
(3)对称平均绝对百分比误差:

(18)
其中:A和P分别代表实际值和预测值,n代表样本大小。MAE和RMSE的取值在(0,1)。另外,3个指标是负向得分,数值越低性能越好。
3.3 结果与分析
本文所提出的主动评分方法和其它评分方法的评分结果如表1所示。相对于其它评分方法,本文所提出的评分方法计算得到的分数与教师评分的分数拟合度最高。具体地,对于题号为5、7、9和10的题目,由于这些题目中涉及的电力系统分析领域的专业词汇较少,本文方法所引入的电力系统分析领域本体没有产生较大的影响,因此最终的评分结果与其他评分方法评分结果差异并不明显。然而,对于其它答案文本包含较多专业术语的题目,本文方法构建的领域本体以及改进的搭配词对的计算算法,能够准确地进行专业词汇相似度计算及句法分析,有效地提高语句相似度计算的准确性。相对地,由于其他评分方法无法准确地识别专业术语并遗漏文本间的语义关系,最终导致其评分结果与教师评分的结果偏差较大。

表1 主观题自动评分的实验结果
表2对比了4种评分方法在不同指标下的计算结果。从表2可看出,本文的评分方法在MAE、RMSE和SMAPE都能取得最小值,这说明了本文的评分方法相对于其它方法具有较为明显的优势。
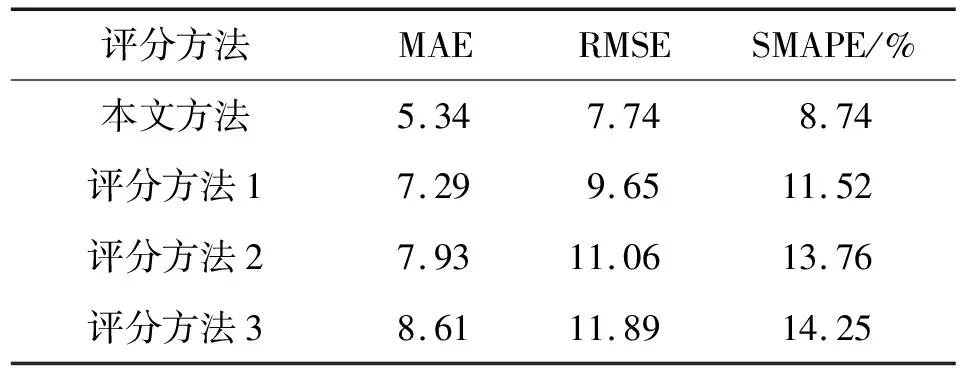
表2 4种评分方法的性能
4 结束语
针对现有主观题自动评分方法无法有效识别领域专业术语,以及在评分过程中易遗漏文本间的语义关系的问题,本文引入电力系统分析领域本体,并综合节点距离相似度、节点信息相似度、词形相似度和搭配词对相似度等特征信息,提出了一种基于领域本体和依存句法分析的主观题自动评分方法。实验结果显示,相对于其他3种自动评分方法,本文所提出的自动评分方法与教师的评分结果更为接近,并且在MAE、RMSE和SMAPE指标上都优于其它方法。但由于构建评分数据集需耗费巨大的人力资源,导致实验所使用的数据集规模较小且涉及的题目类型也较为单一,从而无法全面地评估自动化评分方法的有效性和普适性。因此,如何通过自动标注等方法构建一个可用于深度研究和对比各类自动评分策略的评分数据集,将是我们后续的一个研究工作。
