基于动态知识图谱的大规模数据集成技术
2020-11-28倪路
倪路
如何在海量数据之上将动态的数据进行关联融合,同时满足融合快速、融合无信息丢失等业务要求,并将新增的数据快速融入到当前的图谱中,不间断提供知识服务是目前的业界难题。百分点利用动态知识谱图技术,将模型与数据进行解耦,采用灵活的元数据管理方式,即使元数据变更,已入库数据也无需重新入库。
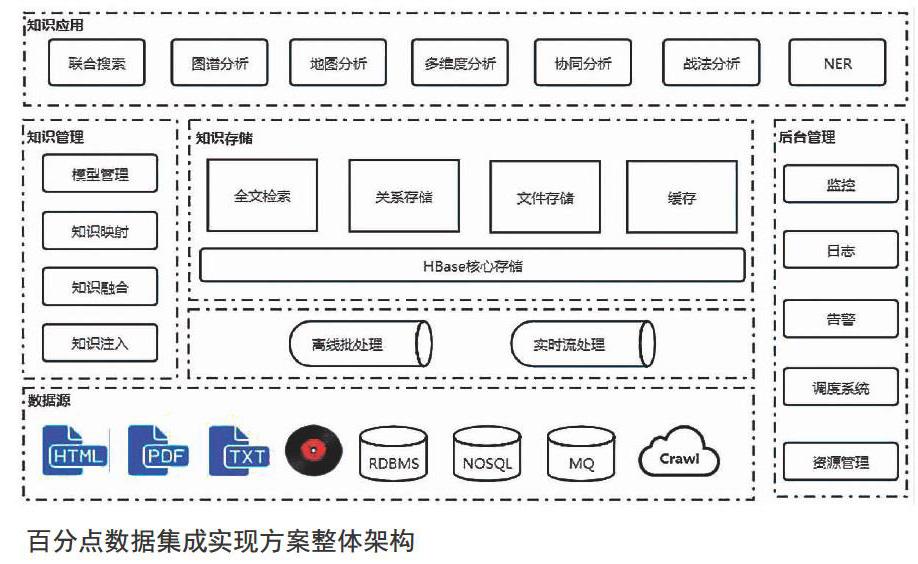
百分点数据集成实现方案整体架构,包含五个部分:
数据源:原始数据,支持各种类型的数据,如结构化数据,也可能是各种半结构化的数据。同时,系统也支持配置URL,通过互联网爬取的网页数据。
知识管理:知识管理的核心在于对多源异构的数据建立统一的模型。
知識存储:核心的知识库,原始数据经过离线或实时ETL处理后的转换为知识,并与库中存量数据按照模型的配置进行知识拉通、融合、冲突解决后,供上游系统消费。
后台管理:实现对系统的监控、告警、日志审计以及资源管理、调度管理,并对采集到的数据进行统计分析,以改善整个动态知识图谱的运作效率。
知识应用:支持全局知识库联合搜索、图谱分析、地图分析、知识的多维度分析、多人多机协同分析以及战法分析,除通用的各种分析手段外,还支持特定行业的定制化分析应用。
以知识管理为核心的
知识图谱建模
本体模型是数据世界对现实世界的映照,同时也是一种数据的分类、建模方式。在实际项目中,用户面对着海量多源的、异构的数据,非常难以进行数据分析。
为了解决这一问题,百分点引入了本体模型,对异构数据进行统一建模,并在字段级别进行了归一化,多源异构数据源通过抽取、转换、清洗变成统一的本体模型后,可为上层应用或分析人员提供更加友好的接口,从而提供便利。值得注意的是,在本项目中,本体模型是由业务人员进行配置的。
业务人员可以建立四种类型的本体,包括实体、事件、文档、关系,具体解释如下:
实体指能够独立存在的人或事物。事件指有时间属性,视为一种特殊的关系,用于连接实体与实体,实体与文档。
事件主要指现实生活中的内容,如发邮件、发短信、转发帖子、发表评论等。
文档特指非结构化文档,如邮件中的各种格式的附件,包括但不限于PDF文档、Word文档,以及各种格式的视频、音频。
关系指用于连接实体之间,实体与事件、文档等的相互关系,如人与人之间的亲属关系,人与物品之间的拥有关系,人与事件之间的主导关系。
以车管所数据为例,通过车管所的数据可以建立一种人-车-罚单的本体模型,人与车之间为拥有关系;人与罚单之间通过“闯红灯”事件相连接,而罚单本身则以文档的形式展现。完成本体模型后,就完成了对元数据的描述。接下来,就需要将真实的数据映射到本体模型上。同时,要在字段级别上对多源异构数据进行归一化。
通过以上建模过程,在应用侧就建立了一个多源数据的统一的逻辑视图,即从分析人员的角度对所有数据构建成了一个图模型,分析人员无需关注底层数据源差异和存储细节,只需关注如何在此图模型上进行分析即可。对于知识库的存储设计,由HBase核心存储、Elasticsearch全文索引、neo4j关系索引组成。
四种数据集成架构
以上内容描述了整个数据模型构建的过程,任何数据要集成进来,必须先进行以上过程,在元数据层面进行拉通、融合。接下来的问题就是如何将客户的数据快速接入知识库的存储中去,以提供统一的数据查询服务,也就是数据层面的集成。
百分点经历多个大型数据集成项目洗礼后发现,通常高价值密度的数据,数据规模都不会太大。比如公安领域的重点人员数据、卡口设备数据、网络安全领域的高危IP、重点监控网站等“实体”数据,此类数据特征是数据量有限,价值密度高。
因此,针对不同的数据场景,百分点提供了不同的数据集成方法。整体数据集成架构如下:
小规模数据集成:这类数据往往是客户提供了小规模的样本,通过前台Import功能,直接上传各种类型的文件,即可导入。
高价值密度数据集成:通常是客户提供的关键数据,这类数据首先需要业务人员根据需求进行建模,然后通过后台离线/实时数据流将数据接入到本体库中。
低价值密度数据集成:通常是“事件”数据,数据量极大,并有一定时效性,需要定期House Keeping。当前的实现方式是通过存放在外部OLAP型数据库中,应用层通过直连的方式进行adhoc查询,将其中有价值的数据选择性地导入到本体库中。
互联网半结构化数据集成:通过给定URL,会启动后台爬虫,爬取对应的网页存入知识库,跟存量知识进行协同分析。
实现“动态性”的核心逻辑
百分点动态知识图谱实现“动态性”的核心逻辑在于,采用元数据与存储分离查询的方案,来赋予知识图谱“动态”特性,包含数据模型的动态性、模型变更的动态性、融合的动态性和“事件”数据的动态性。
数据模型的动态性 由于数据模型有一个专门的后台管理系统进行配置管理,业务可以根据实际客户需求进行模型设计与数据源接入,节省了大量开发成本。
模型变更的动态性 在新增字段、修改字段、删除字段,以及模型修改的时候,在应用端不用重新导入数据。本体库中的数据元数据的存储与物理数据的存储是分离的,应用层查询MySQL获取元数据并进行缓存,然后在Elasticsearch中检索到数据后,会在应用层的内存中进行元数据与物理数据的拼装。
因此,当元数据变更后,只需要更新MySQL数据库与应用层的缓存,无需对实际的物理数据进行变更。
融合的动态性 当融合规则变更后,只需要对特定表重建索引,无需重新导入用户数据。这是因为,在HBase中是按照每种本体类型一张表进行存储的,而需要融合的数据必然是多个源的数据写到HBase的一张表中,HBase的rowkey设计为MD5(PK),而column设计为数据源ID,因此若多源数据存在相同的主键,则会存储到HBase同一行的不同列中。而后续的ETL任务,则会将多列的数据按照融合规则进行融合后在Elasticsearch中建立索引。不同本体数据写入互不影响,而同一本体新增数据源,若发生融合,会写入到不同列中。此时下一次ETL任务就会用新的数据覆盖Elasticsearch中旧的数据,完成索引重建。
“事件”数据的动态性 由于本体库中的数据,是固化的高价值密度数据,而“事件”数据天然是低价值密度的,并且具有时效性。
因此,为了不“污染”本体库,在实现中将事件数据存放到单独的OLAP存储中,用户可以进行预分析,然后将其中具有价值的部分导入到本体库中。
受益于这种分离存储的架构,无需对客户数据提前进行大量转换、融合处理,单纯的写入OLAP存储是十分高效的,对1KB数据能轻松达到10万多 TPS。
在实际的场景中,客户当天提供的数TB数据,第二天就能完成建模、接入,实现应用端可见。
