多尺度特征融合的煤矿救援机器人目标检测模型
2020-11-26翟国栋任聪王帅岳中文潘涛季如佳
翟国栋,任聪,王帅,岳中文,潘涛,季如佳
(1.中国矿业大学(北京) 机电与信息工程学院, 北京 100083;2.湖北工业大学 电气与电子工程学院, 湖北 武汉 430068;3.中国矿业大学(北京) 力学与建筑工程学院, 北京 100083;4.神华信息技术有限公司, 北京 100011; 5.智能矿山(煤炭行业)工程研究中心, 北京 100011;6.闽江学院 福建省信息处理与智能控制重点实验室, 福建 福州 350121)
0 引言
煤矿灾害事故具有灾难性、突发性、继发性和破坏性等特点,救灾时效性强,但救援人员进入井下施救易遇到二次爆炸等危险状况[1-3]。为保障救援人员安全和提高救援效率,可在发生煤矿灾害事故后第一时间安排救援机器人进入灾害现场,进行灾后复杂环境的信息采集和相关救援工作。
煤矿灾后环境复杂,救援机器人要想完全代替人员自主完成搜救任务,首先需要通过相机实时采集灾后环境图像,然后根据图像对周围环境进行解析,最后借助视觉检测算法进行目标检测,以实现自主运动。传统的目标检测模型[4-5]首先通过不同大小的滑动窗口从图像中生成目标候选框,然后在目标候选框内进行特征提取,最后对提取的特征进行分类。该模型采用基于滑动窗口的候选框生成策略,时间复杂度高,检测速度较慢,且提取的基本是人工设计的目标特征,对于目标变化没有很好的鲁棒性,导致检测精度较差。基于深度学习的目标检测模型能够自适应地从大量图像中学习目标特征,具有检测精度高和鲁棒性好等优点,已逐步在不同领域的目标检测任务中广泛应用。基于深度学习的目标检测模型主要分为两阶段目标检测模型[6-8]和单阶段目标检测模型[9]。两阶段目标检测模型首先生成1组稀疏的目标候选框,然后通过卷积神经网络进行目标分类和位置回归,最后输出目标的检测类别和位置坐标;该类模型具有较高的检测精度,但在目标候选框生成上需要消耗大量时间,不适合部署在具有实时检测需求的应用场景中。单阶段目标检测模型将目标检测问题转换为回归问题进行处理,不需要生成目标候选框,具有检测速度快的优点,但在煤矿救援机器人应用场景下,获取的图像信息较少且目标特征不明显,导致目标检测效果较差。
本文在主流的单阶段目标检测模型YOLO V3的基础上,提出了一种多尺度特征融合的煤矿救援机器人目标检测模型。该模型利用特征提取模块获得输入图像特征,得到不同尺度的特征图,再通过特征融合模块实现不同尺度特征图的有效融合,从而提高目标检测精度和速度。
1 多尺度特征融合的煤矿救援机器人目标检测模型
1.1 特征提取模块
基于深度分组卷积提出了一种轻量型特征提取模块,用来替代YOLO V3中的Darknet-53[10],结构见表1,其中c为特征图通道参数,用来平衡模型检测精度和速度。特征提取模块由5个阶段连接起来构成,其中阶段2—阶段5均由1个空洞瓶颈子模块、多个多尺度卷积子模块和1个下采样子模块组成。
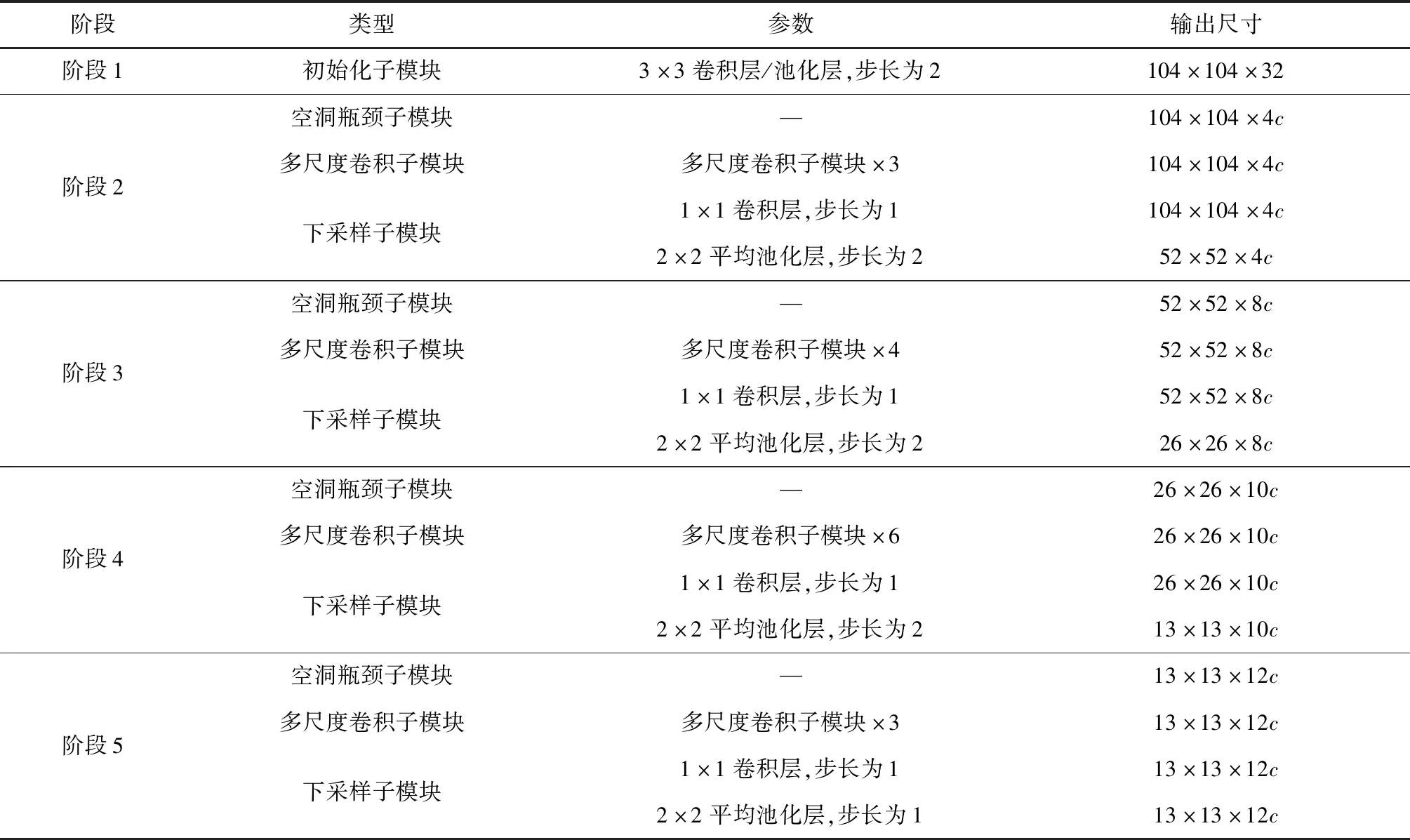
表1 特征提取模块结构Table 1 Structure of feature extraction module
(1) 初始化子模块。在阶段1中,受Inception V4[11]和DSOD(Deeply Supervised Object Detector)[12]的启发,设计初始化子模块,用于对输入图像进行4倍下采样并扩展特征图通道数至32,如图1所示。首先将输入图像经过步长为2的3×3卷积层进行2倍下采样;然后采用双通道来获得不同大小的感受野,一个通道采用1×1卷积层和3×3卷积层堆叠来学习大尺度目标的特征,另一个通道采用步长为2的最大池化层来学习小尺度目标的特征;最后通过通道合并和1×1卷积层控制模型维度,减少模型计算量。
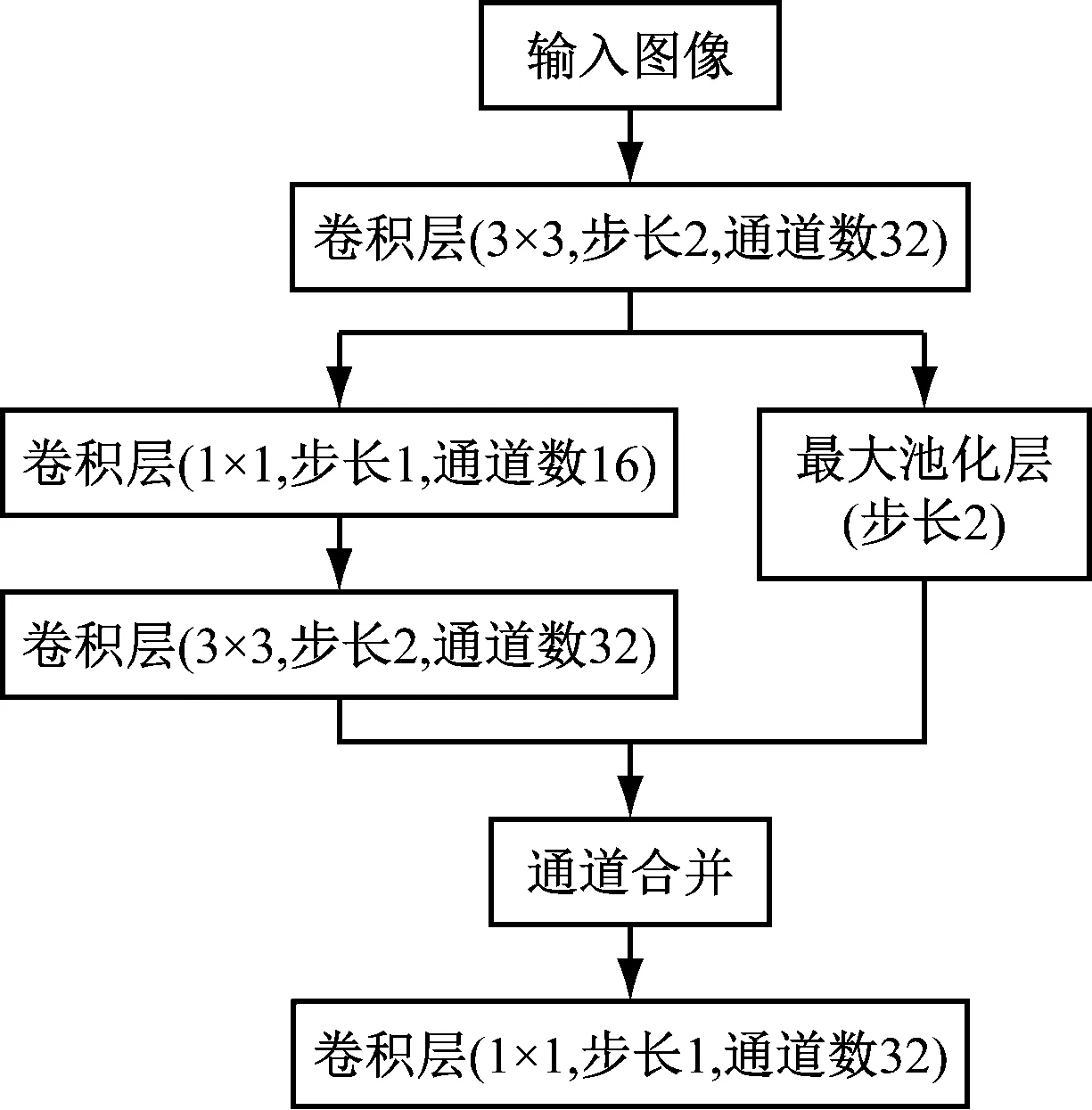
图1 初始化子模块结构Fig.1 Structure of stem block submodule
(2) 空洞瓶颈子模块。为获得丰富的特征信息,在空洞卷积[13]的基础上构建空洞瓶颈子模块,如图2所示。首先上一层特征图通过1×1卷积层进行特征图通道压缩;其次采用分组数为2的3×3空洞卷积层进行特征提取,以提高模型计算效率和增大浅层网络的感受野,保留目标的特征信息;然后利用3×3卷积层增强目标特征语义信息;最后利用残差连接将层次较低的上一层特征图与经过3×3卷积层后的特征图相结合,增强目标特征表达能力。

图2 空洞瓶颈子模块结构Fig.2 Structure of hole bottleneck submodule
(3) 多尺度卷积子模块。在ResNet[14]结构的基础上,利用多尺度卷积增强网络特征提取能力,构建多尺度卷积子模块,如图3所示。首先通过1×1卷积层对上一层特征图通道进行压缩;其次均匀地将特征图分成n个特征图子集X1,X2,…,Xn,其中每个特征图子集与输入特征图具有相同的大小,但特征图通道数为1/n;然后在单个特征图子集内利用分组数为2的3×3卷积层进行特征增强,实现同一特征图子集内不同通道的信息融合,以提高目标分类精度;接着,在不同特征图子集间采用特征金字塔融合方式,即将特征图子集与上一个特征图子集求和后输入到分组数为2的3×3卷积层中进行运算,实现不同特征图子集间的信息融合;最后利用1×1卷积层对n个特征图子集输出的特征信息Y1,Y2,…,Yn进行充分融合来增强特征表达能力。
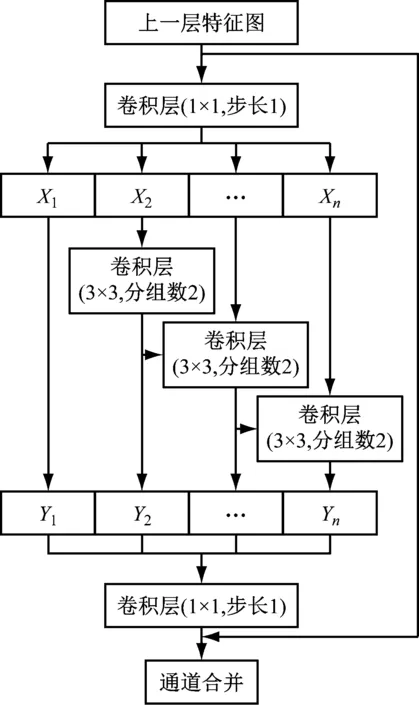
图3 多尺度卷积子模块结构Fig.3 Structure of multi-scale convolution submodule
1.2 特征融合模块
在YOLO V3模型特征金字塔的基础上嵌入空间注意力机制[15],构建特征融合模块,如图4所示。将高层特征图通过1×1卷积层实现特征图通道压缩;利用步长为2的2×2反卷积层对特征图进行上采样,上采样后的特征图通过空间注意力机制直接对位置特征进行增强,提高目标定位精度;将含有丰富位置信息的低层特征图通过3×3卷积层进行特征提取后与含有丰富语义信息的高层特征图进行通道合并,用于后续的目标分类与目标定位。

图4 特征融合模块结构Fig.4 Structure of feature fusion module
2 实验及结果分析
利用Python/C++联合开发多尺度特征融合的煤矿救援机器人目标检测模型,基于Ubuntu18.04搭建模型训练平台:CPU为I5-9600K,RAM为32 GB, GPU为NVIDIA GTX 1660 SUPER。设置模型检测阈值为0.5,特征提取模块中特征图通道参数c为32,特征图子集数n为4。采用迁移学习进行模型训练,主要分为预训练和迁移微调:预训练采用COCO数据集和VOC数据集中行人目标进行训练,得到模型的初始权重;迁移微调利用预训练阶段产生的初始权重作为输入,在煤矿行人检测数据集上进行微调训练,使模型能够充分学习煤矿环境下的行人目标特征。采用随机梯度下降法[16]和反向传播[17]来优化模型,权重衰减为0.005,动量为0.9,总迭代次数为20 000次,初始学习率为0.01,当迭代至18 000次时,学习率减小至0.001使模型收敛。
在煤矿救援机器人嵌入式Jetson TX2平台上分别部署YOLO V3模型和多尺度特征融合的煤矿救援机器人目标检测模型进行测试,结果见表2。可看出与YOLO V3模型相比,多尺度特征融合的煤矿救援机器人目标检测模型的检测精度和速度均有所提高。
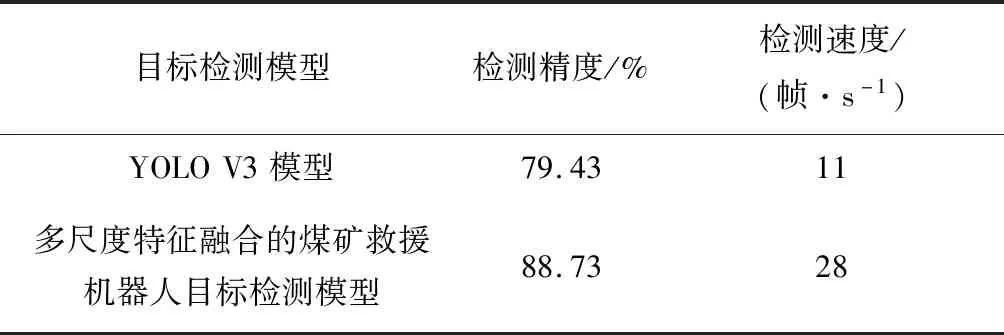
表2 目标检测模型测试结果对比Table 2 Comparison of test results of object detection models
针对煤矿灾后昏暗、灰尘和烟雾环境,YOLO V3模型和多尺度特征融合的煤矿救援机器人目标检测模型检测结果如图5所示。可看出YOLO V3模型可检测出部分行人,但在行人密度较大时存在大量漏检和误检现象;多尺度特征融合的煤矿救援机器人目标检测模型在不同环境下均可准确预测行人位置,具有更好的鲁棒性。

(a) 原始图像

(c) 多尺度特征融合模型检测结果图5 煤矿灾后环境目标检测结果对比Fig.5 Comparison of object detection results in coal mine post-disaster environment
3 结语
基于YOLO V3模型提出了一种多尺度特征融合的煤矿救援机器人目标检测模型。该模型主要包括特征提取和特征融合2个模块:特征提取模块采用空洞瓶颈和多尺度卷积生成含有丰富信息的不同尺度的特征图,增强目标特征表达能力,提高了目标分类精度和检测速度;特征融合模块在特征金字塔中引入空间注意力机制,对含有丰富语义信息的高层特征图和含有丰富位置信息的低层特征图的信息进行充分融合,弥补了高层特征图位置信息表达能力不足的缺点,有效提高了目标定位精度。将该模型部署在煤矿救援机器人嵌入式NVIDIA Jetson TX2平台上进行灾后环境目标检测实验,结果表明该模型具有较高的目标检测精度和速度,鲁棒性好,满足煤矿救援机器人目标检测的实时性和精度需求。
