基于改进高分辨率网络的人脸性别和年龄识别
2020-11-26张瑶瑶
肖 红, 张瑶瑶, 原 野
(1. 东北石油大学 计算机与信息技术学院, 黑龙江 大庆 163318;2. 中国石油勘探开发研究院 测井遥感所, 北京 100083)
人脸特征包含性别、 表情、 年龄等信息, 具有自然性、 方便性和非接触性等优点, 在公共社会安全、 经济财产安全、 军事、 反恐刑侦、 人机交互等电子信息安全领域应用广泛. 目前, 对人脸特征年龄、 性别识别的研究已取得许多成果. 在年龄估计方面, 传统方法主要通过计算年龄特征[1]、 建模[2-3]、 采用Gabor特征[4]及分类器[5-6]等方法估计人脸图像的年龄, 但基于手工设计特征难以提取, 不能有效提升年龄跨度较大的图像准确识别. 因此, 越来越多的学者将机器学习应用于年龄估计中, 主要有流形学习方法[7]和深度学习方法[8]. Rothe等[9]提出了一种深度期望模型, 采用卷积神经网络对单个人脸图像进行年龄估计, 随着样本容量的增加, 性能提升明显; Ng等[10]研究了皱纹对面部年龄估计的影响, 并提出混合老化模式(HAP)用于面部年龄估计, 取得了较好的效果. 在性别识别方面, 性别分类方法常与特征提取算法相结合. Sun等[11]通过获取局部二值模式(LBP)直方图, 应用Adaboost分类器进行性别分类; 在此基础上, Shan[12]在自然场景LFW数据库下应用Adaboost分类器及支持向量机(SVM)和增强的LBP特征, 获得了94.81%的识别性能; 随着深度学习的发展, Levi等[13]首次使用了深度卷积神经网络对人脸年龄与性别分类进行研究, 解决了传统方法需人工提取特征的难题; Duan等[14]应用卷积神经网络和极限学习机的混合结构, 集成了两个分类器的协同作用进行年龄和性别分类, 取得了较高的识别准确率; Afifi等[15]根据面部及其上下文特征组合训练深卷积神经网络, 应用前景广阔.
人脸特征的年龄分类和性别检测在真实场景下受很多因素影响. 一方面, 由于个体衰老程度不同, 且存在化妆、 生活环境等影响, 年龄的识别仍很难; 另一方面, 复杂光线环境、 姿态、 表情及图片自身的质量等因素都会导致识别困难. 采用深度学习方法虽然大幅度提高了识别准确度, 但对图像进行多次特征提取后, 图像分辨率不断减小, 特征提取更困难, 且网络计算复杂度较高, 资源消耗较多. 针对上述问题, 本文基于高分辨率网络[16]进行改进, 改进后网络含有高低不同的4种图像分辨率, 对不同尺度特征进行信息交换, 融合MobileNetV3[17]结构, 减少了网络参数.
1 预备知识
1.1 残差网络
自提出深层卷积神经网络VGG[18]和Google Net[19]后, 由网络深度增加而导致的梯度消失及网络退化等问题已引起人们广泛关注. He等[20]提出了一种深度残差网络(ResNet), 通过加入捷径链接构成基本残差块, 连接浅层网络和深层网络, 解决了梯度消失的问题, 从而在很大程度上提升了网络性能. 捷径链接区别于一般网络结构中由输入直接经过卷积层得到输出的结构, 而是将两个卷积层所得到的输出加上网络的输入.
1.2 高分辨率网络
深度卷积神经网络性能优异, 现有的方法多数通过一个网络(通常由高分辨率到低分辨率的子网串联而成)传递输入, 然后提高分辨率. 高分辨率网络(HRNet)能在整个过程中保持高分辨率表示. 高分辨率子网作为第一阶段, 逐步增加高分辨率到低分辨率的子网, 并将多分辨率子网并行连接. 在整个过程中, 通过在并行的多分辨率子网上反复交换信息进行多尺度特征的重复融合. 网络有4个阶段, 除第一阶段的高分辨率子网外, 第二、 第三和第四阶段通过重复模块化的多分辨率块形成. 多分辨率块由多分辨率组卷积和多分辨率卷积组成, 如图1所示. 多分辨率组卷积是组卷积的简单扩展, 其将输入通道划分为若干通道子集, 并分别在不同空间分辨率上对每个子集执行常规卷积, 如图1(A)所示. 多分辨率卷积则以全连接方式连接不同卷积操作分支, 输出通道的每个子集为输入通道每个子集的卷积输出之和, 如图1(B)所示.
网络使用重复的多尺度融合, 利用相同深度和相似级别的低分辨率表示提高高分辨率表示, 并提高结果准确度. 但网络结构复杂, 参数量较大.
1.3 MobileNetV3
MobileNetV3是在MobileNetV1和MobileNetV2的基础上构建的. MobileNetV1[21]将空间滤波与特征生成机制分离, 引入深度可分离卷积将标准卷积分解成深度卷积和逐点卷积. MobileNetV2[22]引入了线性瓶颈和倒置残差结构, 将输入的低维压缩表示首先扩展到高维, 并用轻量级深度卷积进行滤波, 随后用逐点卷积将特征投影回低维表示. 普通残差结构先将通道数压缩, 再进行特征提取, 最后将通道数扩张回初始状态. 而倒置残差结构, 先对通道进行提升, 获得更多特征, 特征提取后再将通道压缩回初始状态. 考虑到ReLU函数会对通道数较低的张量产生较大的信息损耗, 因此采用线性瓶颈, 即用线性层替换通道数较少层后的ReLU函数. 当且仅当通道数量相同时, 输入和输出由捷径链接相连.
基于MobileNetV2结构, MobileNetV3将基于挤压和激发的轻量级注意模块(squeeze and excitation networks, SE)[23]引入瓶颈结构. SE模块通过学习的方式先自动获取每个特征通道的重要程度, 然后根据该重要程度增强有用特征, 并抑制对当前任务作用较小的特征. MobileNetV3使用这些层的组合作为构建块, 将最后一步的平均池化层前移并移除最后一个卷积层, 引入h_swish激活函数. 网络采用轻量级模块, 参数量较小, 但由于对特征图像的层层提取, 导致图像分辨率较低, 信息融合受限.
2 改进的高分辨率网络
为解决上述问题, 本文通过在HRNet中融合MobileNetV3结构, 对高分辨率网络进行改进. 在改进后的网络(IHRNet)中, 采用具有线性瓶颈和倒置残差结构的可分离卷积, 并增加SE模块, 同时修改部分非线性激活函数为h_swish, 使用Adam自适应优化函数等策略提升IHRNet的性能. 改进的网络不仅可通过执行重复的多尺度融合提高性能, 而且参数量大幅度减小.
2.1 IHRNet的网络结构
IHRNet网络共有4个并行连接的高低分辨率子网, 从上至下通过步长为2的卷积进行下采样, 分辨率缩小为上一级的1/2, 通道数扩大2倍. 网络共包含4个阶段: 阶段1包含4个瓶颈残差块; 阶段2、 阶段3和阶段4分别包含1,4,3个多分辨率块, 每个多分辨率块的多分辨率组卷积部分分别包含2,3,4个分支, 每个分支包含4个改进后的IHRblock, 每个IHRblock包含2个具有倒置残差和线性瓶颈结构的可分离卷积, 激活函数为h_swish, 最后一个IHRblock前加入SE结构. 所有卷积层均使用批量归一化层. 优化器使用Adam自适应优化函数. 通过上下采样将4个不同分辨率的特征不断进行融合, 最后通过1×1卷积将1 024个通道转换为2 048个通道, 然后进行全局平均池操作. 输出的2 048维表示被输入到分类器中. 网络结构如图2所示.
网络采用SoftMax分类器, 年龄分为8种类别, 所以有8个输出节点, 性别识别只有2个输出节点. 全连接层到SoftMax层可表示为{(x(1),y(1)),(x(2),y(2)),…,(x(N),y(N))}, 其中:x(i)表示全连接层的输出特征向量;y(i)为样本的真实年龄或性别;N为标签数量. 前向传播后, SoftMax分类器的输出可表示为

(1)
其中: 对于性别和年龄识别输出,K取值分别为2和8;wi是全连接层中的神经元与SoftMax分类器第i个输出神经元相连接的权重参数;hw(x(i))是一个概率向量, 向量中的各项之和为1, 每一项表示该标签属于对应类别的概率值, 取概率最大的类别作为SoftMax的分类结果. 损失函数采用交叉熵, 即
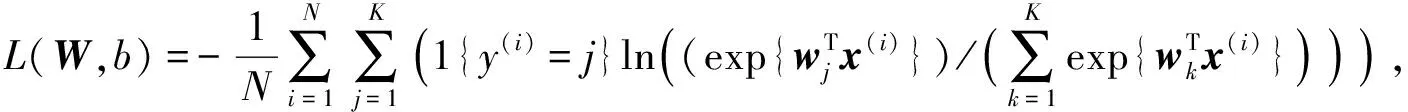
(2)
其中, 1{y(i)=j}表示当第i个标签的类别属于j类时输出为1.
改进后的网络将标准卷积替换为可分离卷积, 有效减少了网络计算量. 标准卷积层的计算量为
C1=DK·DK·M·N·DF·DF,
(3)
其中:M为输入通道数;N为输出通道数;DK为卷积核大小;DF为输出特征图大小. 深度可分离卷积的计算量为
采用SPSS 18.0进行统计分析,负性情绪、生活质量及疾病不确定感得分均采用均数±标准差表示,组间比较采用t检验,以P<0.05为差异有统计学意义。
C2=DK·DK·M·DF·DF+M·N·DF·DF,
(4)
即深度卷积与1×1的逐点卷积之和.
通过将卷积分为滤波和组合的过程得到计算量的缩减为

(5)
使用3×3的深度可分离卷积相对于标准卷积可减少8~9倍的计算量.
2.2 非线性激活函数
Swish[24]是Google提出的一种新型激活函数, 其原始公式为

(6)
具有不饱和、 光滑、 非单调性的特征, 能有效提高网络精度. 为减小计算量, 本文采用非线性激活函数h_swish[24]. 该函数使用ReLU6(x+3)/6代替sigmoid函数, 公式如下:
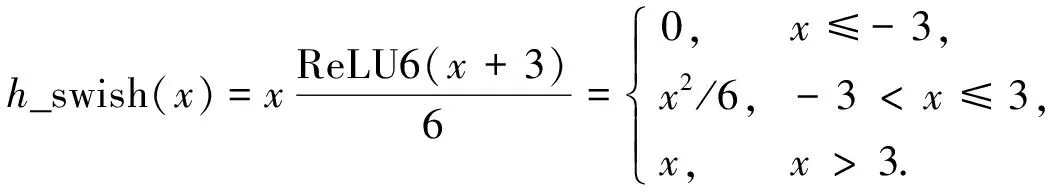
(7)
h_swish函数具有很多优势, ReLU6函数在众多软硬件框架中均可实现, 不仅量化时避免了数值精度的损失, 且运行速度更快.
2.3 SE模块
SE模块基于Squeeze和Excitation两个关键步骤: Squeeze操作对空间维度进行特征压缩, 将每个二维的特征通道变为一个实数, 实数表示在特征通道上响应全局分布, 使靠近输入的层也可获得全局的感受野; Excitation操作通过调节参数为每个特征通道生成权重, 参数被用于显式地表示特征通道间的相关性. Reweight操作将Excitation输出的权重作为特征选择后的每个特征通道的重要性, 通过乘法逐通道加权到原来的特征上, 完成在通道维度上对原始特征的重标定.
SE模块在自适应平均池化后连接两个全连接层, 添加h_sigmoid函数, 组成一个瓶颈结构, 对通道间的相关性建模, 并输出与输入特征相同数目的权重. SE模块在网络中的结构如图3所示.

图3 SE模块结构Fig.3 Structure of SE module
网络保持了高分辨率表示, 即可提取更多的有效特征; 构建IHRblock轻量化结构, 极大减少了参数量和计算量; SE结构具有更多的非线性, 可更好地拟合通道间复杂的相关性; 非线性激活函数h_swish使网络计算速度更快, 量化更友好.
3 对比实验
3.1 实验数据及预处理
Adience数据集专门用于人脸性别和年龄的识别研究. 该数据库中的图像由用户在非限制性条件下使用手机拍摄, 上传到Flickr平台上, 且未经过滤波操作. 数据库中的人脸姿势、 光照条件及背景都存在差异. Adience数据库共包含2 284个不同个体, 26 580张人脸图像, 如图4(A)所示. 年龄标签共分为8个阶段: 0~2,4~6,8~13,15~20,25~32,38~43,48~53,60~100. 对Adience数据集进行数据清洗, 将年龄标签不在已划分8个阶段的图像, 选择相邻较小年龄段作为其标签, 通过OpenCV进行人脸检测, 删除未检测到的人脸及多个人脸的数据, 对数据清洗后的数据集通过裁剪、 翻转等方法进行数据增强.
IMDB-WIKI数据集是目前最大的非受限人脸年龄图像数据集, 通过爬虫技术从互联网电影资料库(IMDB)及维基百科(Wikipedia)获取共计523 051张人面部图像, 其中IMDB包含460 723张图像, Wikipedia包含62 328张图像. 每张图像具有性别和年龄标注, 年龄范围为0~100岁, 如图4(B)所示. IMDB-WIKI数据集上含有许多低质量图片, 如浓妆、 遮挡、 人物素描、 一张图片含有多个人脸以及标签年龄与实际年龄不符等, 严重影响网络学习能力. 因此对IMDB-WIKI数据集进行数据清洗, 删除标签为空的数据, 通过OpenCV进行人脸检测, 删除未检测到人脸及多个人脸的数据.

图4 Adience数据集(A)和IMDB-WIKI数据集(B)部分人脸图像Fig.4 Part of face images of Adience data set (A) and IMDB-WIKI data set (B)
3.2 实验环境
实验输入图片为3通道的彩色图片, 通过等比例缩放调整大小为224×224, 网络采用Pytorch框架, 在Win 10操作系统下进行编译, Linux操作系统下应用Nvidia RTX 2070 GPU进行训练及测试.
3.3 实验结果及分析
3.3.1 网络预训练 Adience数据集数据量较小, 直接将网络在其上训练易产生过拟合等问题, 针对此问题, 先使用数据量较大的IMDB-WIKI数据集对网络进行预训练, 得到性别、 年龄识别模型; 再在Adience数据集上加载预训练模型进行训练及测试. 由于显存限制, IMDB-WIKI数据集预训练时, 迭代次数(Epoch)和批量大小(Batch_size)分别设为50,16, 观察到数据集中男女比例相差较大, 因此采用五折交叉验证方法. Adience数据集进行训练时, 迭代次数(Epoch)和批量大小(Batch_size)分别设为100,16, 随机选取80%作为训练集, 20%作为测试集. 在Adience数据集的训练集上, 性别、 年龄识别的损失函数下降曲线如图5所示. 由图5可见, 未添加预训练的年龄识别损失函数值下降后又升高, 训练过程中出现了过拟合问题, 添加了预训练的网络损失函数始终保持下降趋势, 可见预训练过程有效减轻了数据量不足对网络造成的过拟合影响. 而且添加预训练性别和年龄识别的损失函数值下降较快, 收敛效果较好.

图5 性别、 年龄识别的损失函数下降曲线Fig.5 Decline curves of loss function of gender and age recognition
数据集随机划分的数据具有偶然性, 不能有效将识别难易程度不同的人脸图像均匀划分到训练集和测试集, 从而影响实验结果, 因此再次将Adience数据集的训练集和测试集依次按90%和10%,80%和20%,70%和30%的比例进行划分, 性别、 年龄识别准确率列于表1. 由表1可见, 数据集的划分具有偶然性, 当划分数据集的训练集和测试集比为9∶1时, 网络对性别和年龄的识别准确率最高, 这是由于训练集训练数据较多时, 网络能提取到更多特征, 增强了学习能力.

表1 Adience数据集不同比例划分下性别、 年龄的识别准确率
3.3.2 网络训练与测试 为得到网络对人脸性别、 年龄识别的最佳方案, 确定网络超参数的选取, 加载改进的IHRNet预训练模型, 在Adience数据集上对性别、 年龄识别进行以下实验: 划分训练集和测试集比为9∶1, 迭代次数(Epoch)、 批量大小(Batch_size)分别设为150,200和16,32; Adam自适应优化函数学习速率分别设为10-3和10-5, 实验结果列于表2. 由表2可见, 当网络迭代次数为150, 批量大小为16, Adam自适应学习优化算法学习速率为10-3时, 网络较稳定. 随着迭代次数的增加, 易产生网络退化问题, 减缓网络收敛速度, 网络并未出现更好的效果. 较低的优化算法初始学习率, 使网络学习速度大幅度减小, 收敛缓慢. 因此, 网络超参数的选取应根据网络结构、 数据集大小等进行调整.
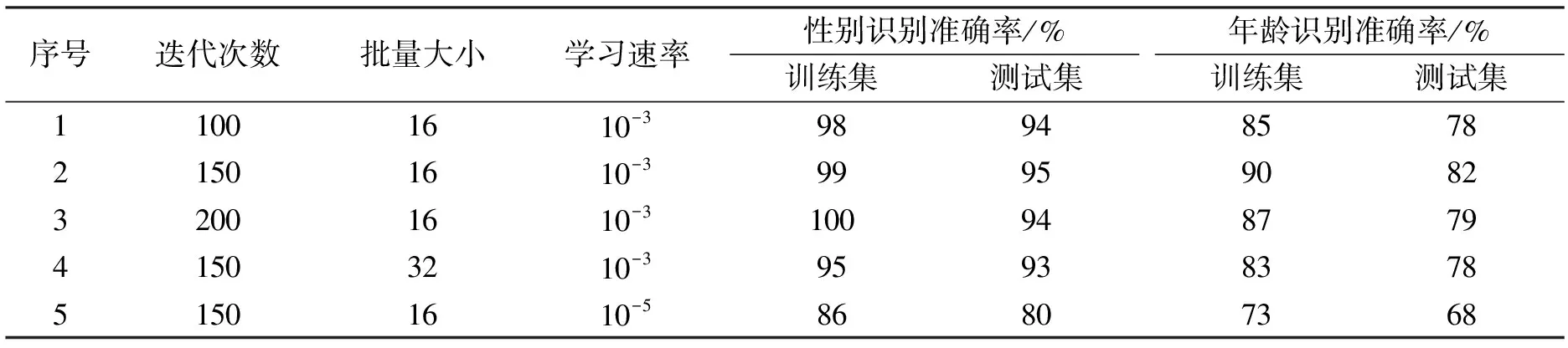
表2 不同参数下Adience数据集中性别、 年龄的识别准确率
3.3.3 方法对比 为验证本文方法与现有方法相比的优势, 将ResNet50,HRNet,MobileNetV3以及改进后的IHRNet在Adience数据集上进行训练及测试. ResNet50为50层的残差网络, 优化器为均方根传播(RMSProp)优化算法, 初始学习率为0.045, 每迭代2次后以0.94的指数速率衰减. HRNet初始学习率设为0.1, 并在迭代30,60,90次时减少10倍, 使用随机梯度下降(SGD)优化算法, 权重衰减为0.000 1, Nesterov动量为0.9. MobileNetV3初始学习率设为0.1, 每迭代3次后学习率衰减为0.01, 使用均方根传播(RMSProp)优化算法, 动量为0.9, 权重衰减为10-5, 卷积层后使用批量归一化层. 经试验, ResNet50的迭代次数、 批量大小设为60,32, 其他3个网络迭代次数和批量大小设为150,16时, 可取得最高准确率, 测试结果列于表3. 由表3可见, 改进后的网络在年龄及性别识别上的准确率分别高达82%,95%, 比同类算法分别平均提升9%和3%.

表3 同类方法在Adience数据集上性别、 年龄的识别准确率
在模型的参数量方面, 未改进的HRNet参数量为19.97 M, 改进后的网络采用轻量级网络结构, 参数量为12.81 M, 参数量减少36%.
对于改进网络性能提升的原因, 本文从网络内部机理给出以下分析: 区别于其他网络仅由高分辨率卷积的表示或从网络输出的低分辨率表示中恢复高分辨率表示, 改进后的网络通过聚合所有并行卷积增强高分辨率表示, 各尺度特征重复进行信息交换, 聚合多种不同感受野上的特征获得性能增益; 可分离卷积有效减少了参数量, SE模块调整权重作为特征选择后的每个特征通道的重要性, 根据该重要程度提升有用的特征, 并抑制对当前任务影响较小的特征, 使靠近输入的层也可获得全局的感受野, 从而提高了人脸特征识别的准确率.
综上所述, 本文提出了一种基于改进高分辨率网络(IHRNet)的新方法. IHRNet融合具有线性瓶颈、 倒置残差结构的可分离卷积, 减少了网络参数; 通过挤压和激发的轻量级注意模块调整通道权重, 使靠近输入的层也可获得全局感受野; 同时网络能使高、 低两种分辨率模式并行, 保证了多尺度特征的融合, 从而使人脸特征识别准确率明显提升. 此外, 网络通过预训练, 进一步降低了过拟合风险. 实验结果表明, 本文方法不仅具有较高的识别准确率, 而且优于同类对比方法, 验证了本文改进措施有效、 可行.
