基于开放评测的临床信息抽取分析*
2020-11-25赵琬清胡佳慧陈凌云
赵琬清 胡佳慧 娄 培 陈凌云 方 安
(中国医学科学院/北京协和医学院医学信息研究所 北京 100020)
1 引言
相比开放领域数据,电子病历数据具有较强隐私性。尽管国内外许多学者对电子病历信息抽取进行了深入研究,但相关研究数据难以公开。通过开展电子病历开放评测使更多研究人员参与到临床信息抽取任务中,能够促进更大范围的临床自然语言处理研究。基于英文的临床信息抽取评测以美国国家临床自然语言处理挑战(Informatics for Integrating Biology & the Bedside / National NLP Clinical Challenges,i2b2/n2c2)和只标注医疗问题的命名实体语料库(Shared Annotated Resources /Conference and Labs of the Evaluation Forum,ShARe/CLEF)健康评估实验室(eHealth Evaluation Lab)为典型代表。基于日文的临床信息抽取评测主要是日本国家科学信息系统中心信息检索系统测试集会议(NII Testbeds and Community for Information Access Research,NTCIR)会议组织的电子病历评测。我国基于中文的临床信息抽取评测主要有两项,分别是中国知识图谱与语义计算大会(China Conference on Knowledge Graph and Semantic Computing,CCKS)和中国健康信息处理大会(China Conference on Health Information Processing,CHIP)每年组织的评测,均由中文信息学会主办。本文基于国内外典型临床信息处理开放评测案例,首先介绍评测基本概况,重点分析评测语料、评测任务以及信息抽取方法,在此基础上探讨面向临床需求的信息抽取发展方向,为基于中文临床文本的进一步分析与挖掘提供参考借鉴。
2 典型案例
2.1 i2b2/n2c2
由美国国立卫生研究院(National Institutes of Health,NIH)资助成立的生物医学计算中心,自2006年起开始组织临床记录自然语言处理挑战的研讨会,至今已举办10届。鉴于i2b2在临床自然语言处理方面做出的卓越贡献,这一系列评测于2018年被命名为美国国家临床自然语言处理挑战(National NLP Clinical Challenges,n2c2)。
2.2 CLEF
主要针对欧洲语言进行的信息检索开放评测平台,于2003 年开展第1届多语言问答系统评测项目。2013年CLEF发布临床信息抽取相关评测[1],基于该评测数据集,SemEval2014[2]和SemEval2015[3]相继开展临床文本语义相似度任务。
2.3 NTCIR
为满足面向咨询检索与自然语言处理研究需要,日本国家科学咨询系统中心(National Center for Science Information Systems,NACSIS)开展基于日文的信息检索测试集(NACSIS Test Collections for IR,NTCIR)计划,将数据集作为相关研究的基础语料。在临床信息抽取方面NTCIR自2013年起举办了4届相关评测任务。
2.4 CCKS
由中国中文信息学会语言与知识计算专业委员会主办。2017年至今针对中文电子病历开展连续3届评测任务。
2.5 CHIP
由中国中文信息学会医疗健康与生物信息处理专业委员会主办,会议涉及医疗、健康和生物信息处理相关领域。CHIP自2018年起已连续开展两届临床信息相关抽取评测。
3 案例分析
3.1 语料分析
开放评测语料概况,见表1。出院小结中含有大量临床实体,因此大量临床信息评测任务选取出院小结作为原始文本数据。临床信息抽取任务中的标准评测数据需要领域专家进行数据筛选与人工标注,从数据量角度,各评测任务中电子病历数据量均未超过1 500份,说明临床信息数据标注难度较大。而几个数据量较多的评测任务,其量化数据的标准为句子和短语对,有些文本来源为互联网开放数据。

表1 开放评测语料概况
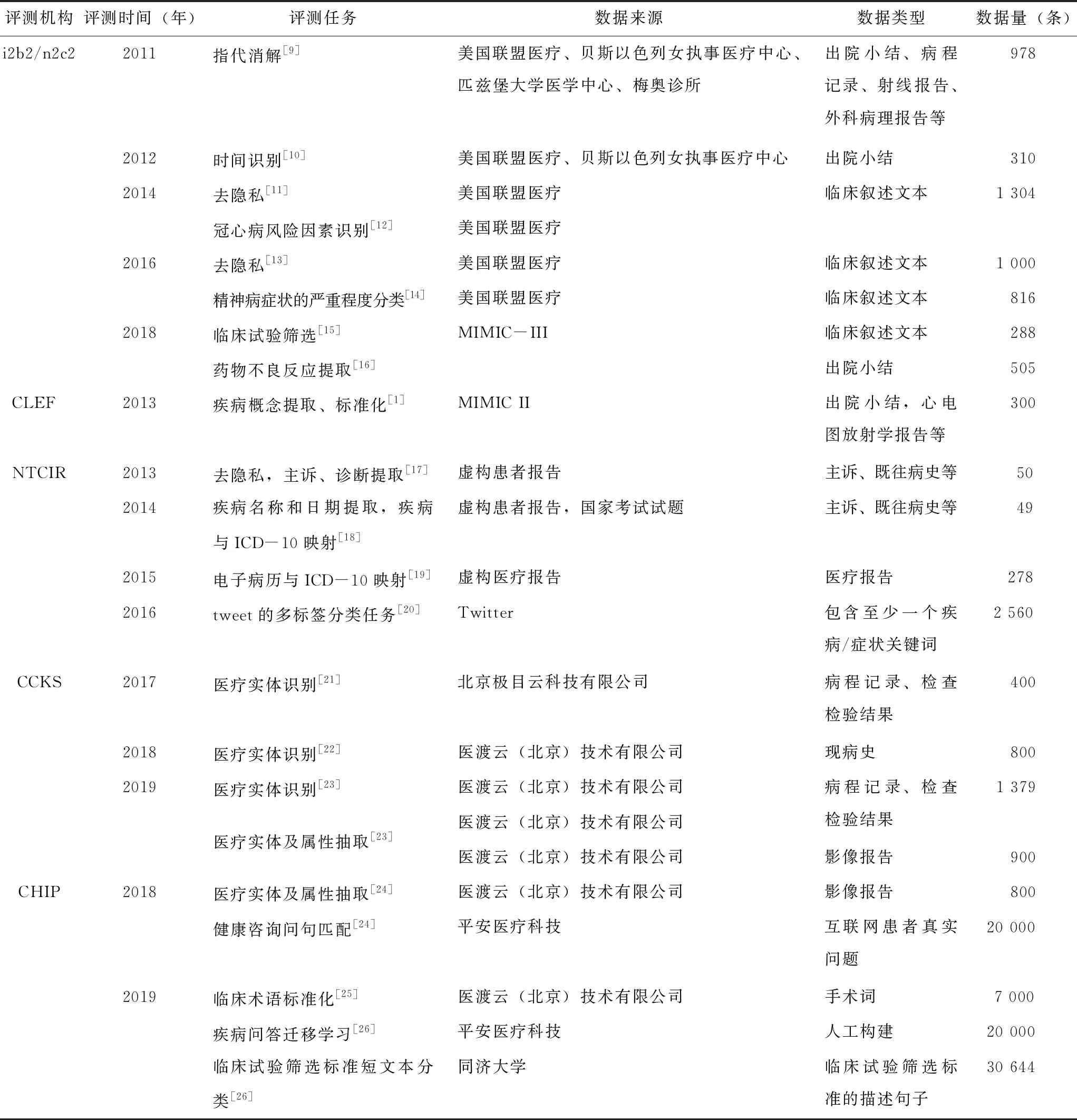
续表1
3.2 评测任务
3.2.1 临床实体识别 从国内外开放评测任务数量来看,最多的评测任务为实体识别,识别不同类别实体,主要为隐私和临床实体。临床信息特殊性在于极强的隐私性,因此去隐私识别是临床信息抽取以及后续科学研究分析的重要先决条件,已有多个评测开展去隐私识别任务。i2b2 2006发布去隐私识别任务,其中隐私信息包括患者姓名,医生姓名,医疗和护理机构名称,ID号(识别医疗记录、患者、医生或医院的数字),日期(包括所有类型日期,但不包括年份),地理位置,电话号码和年龄(90岁以上的为隐私,90岁以下的不做处理)。i2b2 2014发布糖尿病患者医疗记录去隐私识别任务,在i2b2 2006的基础上增加职业这一隐私类别。NTCIR 10(2013年)发布虚构电子病历的去隐私任务。i2b2 2016发布精神病临床记录的去隐私任务。电子病历中蕴含丰富的临床实体,临床实体识别是非结构化临床文本处理的首要、关键步骤。国外已发布许多临床实体识别相关评测任务。i2b2 2009评测任务从出院小结中提取7种与药品相关的属性信息,包括药品名称、剂量、用药方式、用药频率、用药持续时间、用药原因以及列表/叙述(药品信息出现在列表结构还是出院小结的叙述文本中)。该评测任务着眼于药品相关信息,其提取可以为药品不良反应的提取提供基础支撑。i2b2 2010评测任务分别为从病程记录和出院小结中抽取医疗概念、医疗概念的修饰分类以及医疗概念之间的关系,该届评测是i2b2 举办的医疗文本处理领域评测中最受广泛关注的一届。医疗概念抽取任务可视为一个信息抽取任务,要求参赛者从无标注的患者病历中抽取医疗问题、治疗和检查3类实体;医疗概念的修饰分类任务要求参赛者识别病历中医疗问题概念的修饰;医疗概念间的关系抽取任务主要识别医疗问题、检查和治疗3类概念之间的关系。i2b2 2014的冠心病风险因素识别任务中冠心病风险因素识别包括吸烟史、家族史、高血压、高血脂等因素的危险程度。n2c2 2018发布电子病历中药物与药物不良反应的实体与关系提取的评测任务,从临床记录中提取药物不良反应对用药安全以及新药研发具有临床指导意义。n2c2 2019发布家族史信息提取评测任务[27],家族史信息在疾病尤其是遗传病的诊断和治疗中有重要作用,但这些信息通常存在于非结构化文本中,需要抽取家族史中的遗传、生活习惯信息进行辅助治疗。CLEF 2013的评测任务包括病历疾病概念的提取。NTCIR 10(2013年)的评测任务为主诉和诊断的提取,NTCIR 11(2014年)的评测任务之一为从电子病历中提取疾病名称。近年来基于中文电子病历的临床实体识别受到广泛关注,相关评测任务也相继开展。CCKS自2017年起开展临床信息的命名实体识别任务。CCKS 2017评测任务识别的临床实体包括症状和体征、检查和检验、疾病和诊断、治疗以及身体部位5类。CCKS 2018评测任务聚焦现病史识别解剖部位、症状描述、独立症状、药物和手术5类临床实体。CCKS 2019在结合前两年评测任务的基础上,识别疾病和诊断、检查、检验、手术、药物以及解剖部位6类临床实体。此外在CHIP 2018评测任务中增添对影像报告文本的识别,从影像报告文本中抽取所需的肿瘤原发部位、病灶大小和转移部位,这一任务可以看作临床实体识别与实际临床需求的更紧密结合,通过自动分析影像报告文本,更直观地提供简练的结构化分析结果。CCKS 2019在CHIP 2018医疗实体及属性抽取任务的基础上发布影像报告文本中临床医疗实体及属性抽取。此外电子病历中时间信息非常重要,i2b2 2012 评测任务抽取出院小结中的时间关系。以往实体识别任务多关注临床意义明确的医疗实体,如疾病、治疗等,而时间线作为电子病历记录中的关键信息也需要进行结构化,这一信息处理过程能为临床提供更多的参考信息。
3.2.2 分类任务 除实体识别任务外,另一类评测任务为患者分类任务。从不同维度对电子病历中的内容标记,进而对患者进行分类。i2b2 2006发布吸烟状态识别评测任务。吸烟状态识别数据由两名肺科医生共同进行标注,标注不一致的地方再由另外两名肺科医生判断。肺科医生根据病历信息和专业知识经验将患者吸烟状态分为5类:过去吸烟、当前吸烟、吸烟、不吸烟和未知。吸烟状态识别任务是一个分类任务,基于电子病历记录对不同患者进行吸烟状态分类,有助于后续进一步对不同类别患者进行临床研究。i2b2 2008 评测任务从出院小结中自动抽取肥胖信息及15种常见并发症,包括哮喘、动脉粥样硬化性心血管疾病、充血性心力衰竭、抑郁症、糖尿病、胆结石/胆囊切除术、胃食管反流病、痛风、高胆固醇血症、高血压、高甘油三酯血症、阻塞性睡眠呼吸暂停、骨关节炎、外周血管病和静脉功能不全。该评测任务与i2b2 2006的吸烟状态识别任务类似,最终患者被分类为肥胖、不肥胖、可能肥胖与未提及4种类别。相比吸烟状态识别任务,肥胖与相关并发症的识别具有更强的临床意义,评测方法对后续相关并发症与肥胖研究有指导意义。i2b2 2016发布精神病学评估记录中患者精神病症状严重程度分类任务。现代社会对精神疾病的定义越发清晰,从精神病学评估记录中确定患者精神病症状严重程度能够对患者后续治疗给予有力干预。n2c2 2018临床试验筛选任务从临床记录中确定患者是否符合临床试验筛选标准。该评测新增了临床试验筛选标准,临床试验是指通过受试者进行药物的系统科学研究,一般通过人工比较受试者病历记录和临床试验筛选标准完成,这种方式费时费力且效率低下,通过自然语言处理和机器学习方法对临床记录进行自动解析并比对临床试验筛选标准,自动进行临床试验筛选。CHIP 2019试验筛选标准短文本分类任务与n2c2 2018临床试验筛选任务十分相似,通过自然语言与机器学习方法自动从临床记录中提取符合临床试验的受试者,具有广阔的实际应用前景和较高的临床研究价值。NTCIR 13(2016年)的任务为tweet多标签分类任务,将每条tweet标记为8种疾病/症状阴性或阳性的两种标签状态,共发布中、日、英3种语言的语料数据,这一任务的原始数据已经不属于临床信息领域,但是其目标疾病/症状为流感、腹泻/胃痛、花粉过敏、咳嗽/喉咙痛、头痛、发烧、流鼻涕和感冒,具有一定的临床研究价值。
3.2.3 临床术语标准化 医学统计中不可或缺的一项任务。由于各种临床实体有多种不同的表述形式,标准化工作能为临床实体找到标准化的表述形式。这本质上也是一种语义相似度匹配任务,与临床文本的相似度计算类似。i2b2 2011 评测任务是指代消解,关注实体之间等价关系,抽取出院小结、病程记录和临床报告等病历文本中相同指代实体。n2c2 2019第1个与第3个评测任务分别为临床文本语义相似度计算[28]和临床术语标准化[29]。以往的评测任务多针对临床记录的临床实体进行识别,而电子病历记录的广泛应用也带来一系列问题,由于可复制粘贴、模板的使用造成电子病历冗余和错误问题增多。临床文本语义相似度计算任务旨在通过计算临床文本之间的语义相似度,检测和消除冗余信息,排查错误,优化临床决策。在非结构化临床记录中有效使用和交换临床相关概念信息需要命名实体识别和命名实体规范化两个互补过程。命名实体识别从临床记录中抽取临床相关概念。命名实体规范化涉及将命名实体与标准化医学术语中的概念联系起来,将临床上各种不同说法的概念找到对应的标准术语概念,便于电子病历进行后续统计分析以及科学研究。TCIR 11(2014年)的任务是从电子病历中提取疾病名称与日期并将疾病名称映射到ICD-10编码中,旨在通过自动方法完成疾病名称与标准化词/编码的映射;NTCIR 12(2015年)任务在NTCIR 11(2014年)的基础上更改为完成患者电子病历记录到ICD-10编码的映射。CHIP 2018的问句相似度匹配任务针对中文互联网上真实患者疾病问答数据进行问句意图匹配。CHIP 2019继续开展疾病问答迁移学习评测任务,与前一年度的问句相似度匹配任务类似,为疾病问答数据增添新的语料,后续可以进行病种间的迁移学习,这两次评测任务的数据主体来源于互联网,为互联网智能分诊、智能客服等应用提供基础。CHIP 2019发布临床手术术语标准化评测任务,具体内容为临床手术术语的标准化,为中文手术术语标准化研究提供珍贵语料。
3.3 信息抽取方法
开放评测为临床信息抽取研究领域提供珍贵的语料数据,评测任务开展过程中参赛者选取的信息抽取方法为未来研究提供启示。传统方法多为字典、规则、隐马尔科夫模型(Hidden Markov Model,HMM)、条件随机场模型(Conditional Random Field,CRF)和支持向量机(Support Vector Machine, SVM)等,其中CRF模型在信息抽取领域取得较为显著的成果。随着神经网络与深度学习的发展,越来越多的信息抽取任务采用深度学习方法,并结合传统的规则与机器学习方法,如LSTM-CRF模型、BiLSTM-CRF模型等。中文相关临床信息抽取评测较英文评测开展时间晚,相对来说方法更新颖,多采用融合方法,选取混合传统规则与字典方法、机器学习、深度学习的模型。BERT(Bidirectional Encoder Representations from Transformers)模型[30]由Google AI团队于2018年11月提出,基于该模型已在自然语言处理相关任务中表现出较好性能,2019年CCKS和CHIP两项信息抽取评测任务中几乎所有评测队伍都融合该模型并取得显著效果。
3.4 临床应用
开放评测中的实体识别、分类、标准化等任务是信息抽取的基础性工作。在非结构化临床记录中命名实体识别任务是从临床记录中抽取临床相关概念的第1步,而这些临床概念由于书写错误、不同的表述形式,难以有效地使用和交换。因此需要通过临床术语标准化任务将命名实体与标准化医学术语中的概念联系起来,为临床上各种不同说法的概念找到对应的标准术语概念,便于电子病历进行后续统计分析以及进一步科学研究。临床术语标准化任务原理还可进一步用于病历书写质检,提高电子病历质量,更好地为患者服务。这些临床信息抽取任务可看作是临床记录打标签的过程,而临床试验自动筛选正是基于患者不同特征建模,进而筛选出符合临床试验的受试者。临床文本相似度匹配任务可作为临床信息检索、患者健康问答的基础,能够快速、准确找到相似的临床信息以及相关健康问答,为临床科研以及健康科普提供有力支撑。
4 结语
随着医学信息化与智能化不断发展,电子病历作为蕴含丰富医疗资源的宝库越来越受到重视。i2b2是临床信息抽取评测领域中开展最早且持续发布不同临床信息评测任务的机构,其历年的评测任务主要从不同类型实体识别任务转为临床信息分类、临床术语标准化以及临床试验自动筛选,更进一步面向临床信息处理的实际需求。中文临床信息抽取相关评测虽然起步较晚,但受到的关注度较高。针对临床术语的标准化研究工作,目前的评测任务只针对部分手术术语进行标准化,基于疾病、治疗等临床实体的标准化以及基于临床文本语义相似度计算的中文临床信息抽取相关研究还有待进一步开展。
