医学信息学领域算法类别使用及影响力研究*
2020-11-25马彩珍邰杨芳吴胜男贺培凤
于 琦 马彩珍 邰杨芳 吴胜男 贺培凤
(山西医科大学管理学院 太原 030001)
1 引言
20世纪中期,国外生物医学研究者利用计算机处理医学数据,加速计算机科学与生物医学发展,20世纪70年代,“医学信息学”概念在国际信息处理协会会议上正式提出[1-2]。医学信息学是计算机科学技术、现代医学、图书情报学等多学科交叉的应用型新兴学科,是典型的以数据驱动且高度依赖机器学习和深度学习算法的研究领域[1]。随着网络信息技术、计算机科学飞速发展,数据驱动的医学信息学内涵不断丰富,研究领域逐渐广泛。同时文献计量方法逐步应用于医学领域定性热点趋势分析及影响力评估等[3]。算法是医学信息学重要工具[4]。学术界对算法在科研领域的调查较少,现有算法影响力评估主要根据同一任务中不同算法的完成效果进行评价[5-6]。这种基于实验效果的评价方法较直接、准确,但存在一定局限性,即实验需要特定数据集、评估者需要较高专业知识水平。本研究基于内容分析对医学信息学领域算法类别的使用情况及影响力进行分析,定量考察不同算法实际应用情况,为深化医学信息学学科认识提供参考。
2 资料与方法
2.1 资料来源
2018年美国科学情报研究所出版的网络版《期刊引用报告》(Journal Citation Reports,JCR)共收录26种医学信息学期刊。本研究基于已有期刊评价研究[7-8],综合考虑期刊影响因子和特征因子分值,对上述26种期刊进行排序,参考专家意见,选择影响因子>2.70、特征因子分值≥0.006的期刊,最终选取5种期刊进行研究,见表1。

表1 医学信息学领域5种高影响力期刊
在Web of Science数据库中,以5种期刊名称进行检索,限定检索年限为2009-2018年,文章类型选择"Article",检索结果为7 948篇。采用社会调查法中总样本容量公式(1)进行样本规模确定,其中t为置信度所对应的临界值,e为抽样误差。允许抽样误差为2%、置信度为95%计算得到总样本容量为2 401,采用分层抽样方法确定每种期刊样本量,见表2。
(1)

表2 2009-2018年5种期刊样本量汇总(篇)
2.2 数据标注与处理
采用全文内容分析法对2 401篇论文算法使用情况进行深入分析。首先,根据已有研究中提出的算法句标注类目[9],建立本研究标注信息,见表3。其次,依据标注信息类目进行标注。共有705篇论文使用算法,共涉及170种算法,在此基础上根据《数据挖掘10大算法》(TheTop10AlgorithmsinDataMining)一书标准[10]及专家咨询进行算法名标准化及算法分类,在该书10大数据挖掘算法类别基础上新增回归算法、人工神经网络、文本分析、降维、模型、时频分析、检测等7种算法类别,最终得到16种算法类别(序列模式算法在本研究样本未使用,故不做分析),见表4。最后基于算法分类词典方法对标注结果进行统计。

表3 算法句标注信息

表4 算法分类词典
2.3 算法使用评价指标
2.3.1 提及次数 即算法在文章中出现的次数,将提及次数分为3个指标。(1)提及论文数。借鉴学术论文影响力评价Count One方法[11],即某种算法类别属下的某种算法无论在一篇文章中出现多少次只记为1次,对其提及次数进行累加。例如一篇文章中提及算法类别A中的算法a和算法b则该篇文章算法类别提及次数记为2。(2)提及总次数。借鉴 Ding 等提出的 Count X方法[11],考虑算法反复提及情况对算法类别影响力进行评估,即记录一篇论文中某种算法类别属下的所有算法出现次数。(3)平均提及次数,即算法类别提及总次数与提及论文数比值。
2.3.2 提及位置 即算法类别所在章节类型。学术论文各章节重要性不同[12],因此不同章节提及算法的重要性不同,导致算法类别在不同章节类型中影响力不同。结合实证型研究论文IMRDC(Introduction-Material and methods-Results-Discussion-Conclusion)结构[13]将章节划分为5种类型,见表5。因部分算法可能只出现在摘要中故将Abstract也作为一种章节类型进行研究。

表5 章节类型划分
2.3.3 共现情况 即一篇论文同时涉及两种或两种以上算法,共现次数越多算法间关系越密切。共现情况次数经计算提及论文数得到。
3 结果分析
3.1 使用趋势
3.1.1 年代变化 705篇提及算法类别论文数量呈整体上升趋势,其中2015年期刊刊载论文数量相对较少致使算法使用论文刊载量较少。分类算法、统计学习、人工神经网络算法使用论文数量较高且逐年递增,尤其在2015年后增幅明显,而图形挖掘、检测算法、粗糙集3种算法数量较少但呈逐年上升趋势,见图1。说明医学信息学领域对分类算法等3类算法依赖程度较强;其他算法发挥越来越重要作用。

图1 算法类别使用变化趋势
3.1.2 算法类别使用的期刊变化趋势 16个算法类别在5种期刊的使用各不相同,在《生物医学信息学杂志》和《生物医学中的计算机方法和程序》期刊论文中都有提及且提及论文数较多,在其他3种期刊使用较少,其中《医学互联网研究杂志》提及算法类别最少,仅为7类。说明生物医学中的计算机方法与程序及生物医学信息计量对算法依赖程度较高。分类算法、统计算法、人工神经网络算法在5种期刊中提及论文数较多,图形挖掘、检测算法、粗糙集算法提及论文数较少,见图2。
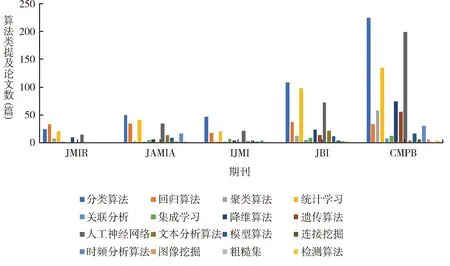
图2 算法类别期刊使用变化趋势
3.2 使用影响力
3.2.1 提及次数(表6) 算法类别提及论文数越多,则该算法类别使用越多、影响力越大;当两种算法类别提及论文数相同时,提及总次数高则影响力大;平均提及次数反映算法类别在单篇论文中的使用情况。其中分类算法提及论文数最高,约占65%,有研究者指出构建分类器系统是数据挖掘最常用工具之一[10],因此使用率较高。人工神经网络算法排名第2,第3为统计学习算法。随着人工智能发展,人工神经网络在医学信息学领域应用广泛,如在预测与估计、模式识别、生物医学等方面取得较大进展;统计学习是基于概率的算法,能更好地实现预测,从而提高科研效率[14-15]。回归、聚类、降维、遗传算法提及论文数较多,原因在于:回归算法原理简单易实现;聚类算法可从新视角把握数据资源价值;降维算法可去除数据噪声和不重要特征,提高数据处理速度;遗传算法为近年理论和应用研究热点等。粗糙集算法类别仅有1篇论文提及,排名最低。算法类别提及论文数与总提及次数排名结果基本一致,而平均提及次数排名发生变化。这表明提及论文数、提及总次数和平均提及次数间不成正比。平均提及次数在2~17间浮动,遗传、模型和文本分析算法分别从提及论文数结果中的第7、9、10位升至平均提及次数结果前3位,原因在于其作为新兴算法在医学信息学领域使用较少,在使用时需较多篇幅描述解释原理而反复提及。在提及论文数中位列第1的分类算法跌至第9位,可能由于该算法类别原理较简单而解释较少。其他算法类别的3种排序结果差距较小。
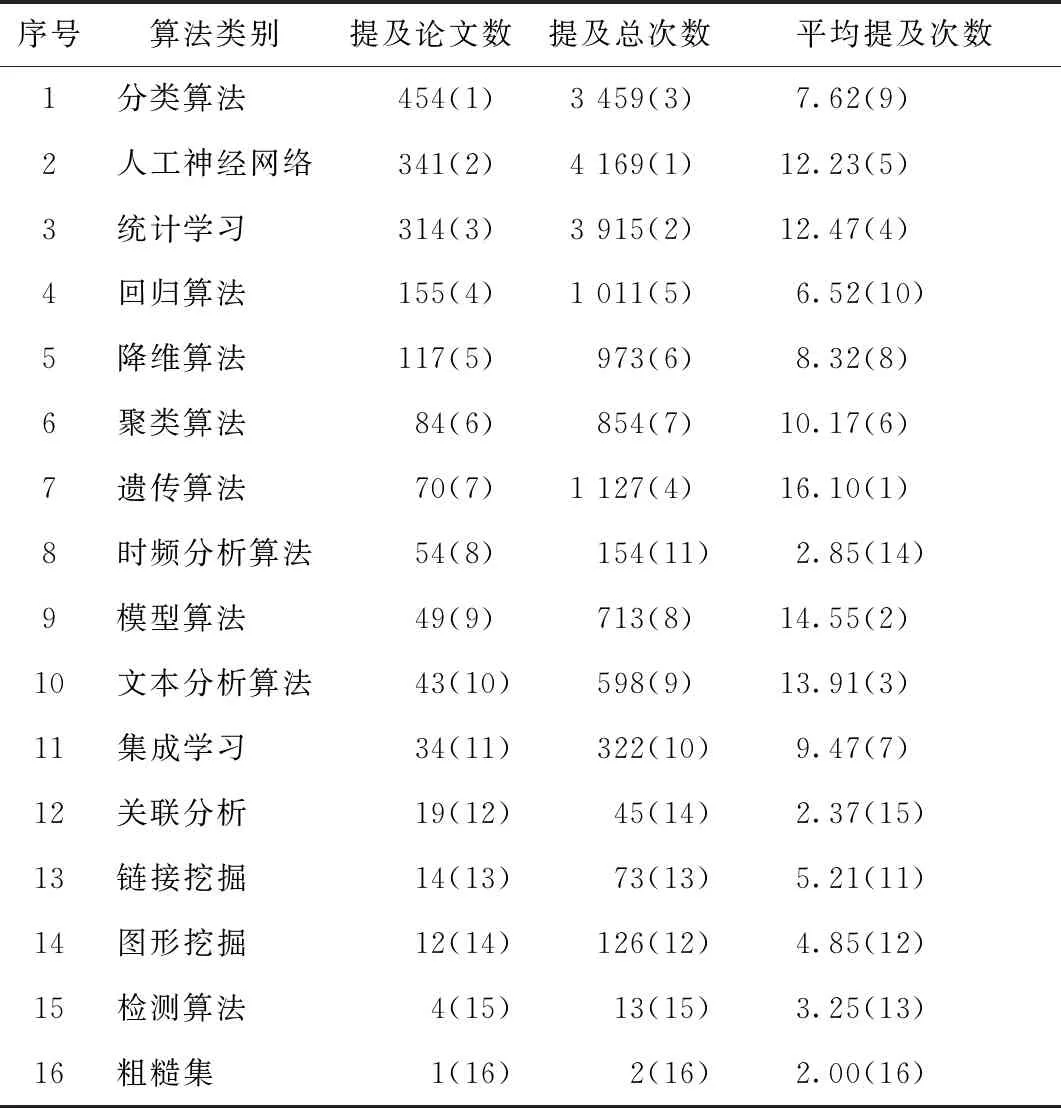
表6 提及论文数、提及总次数、平均提及次数结果
3.2.2 提及位置(图3)
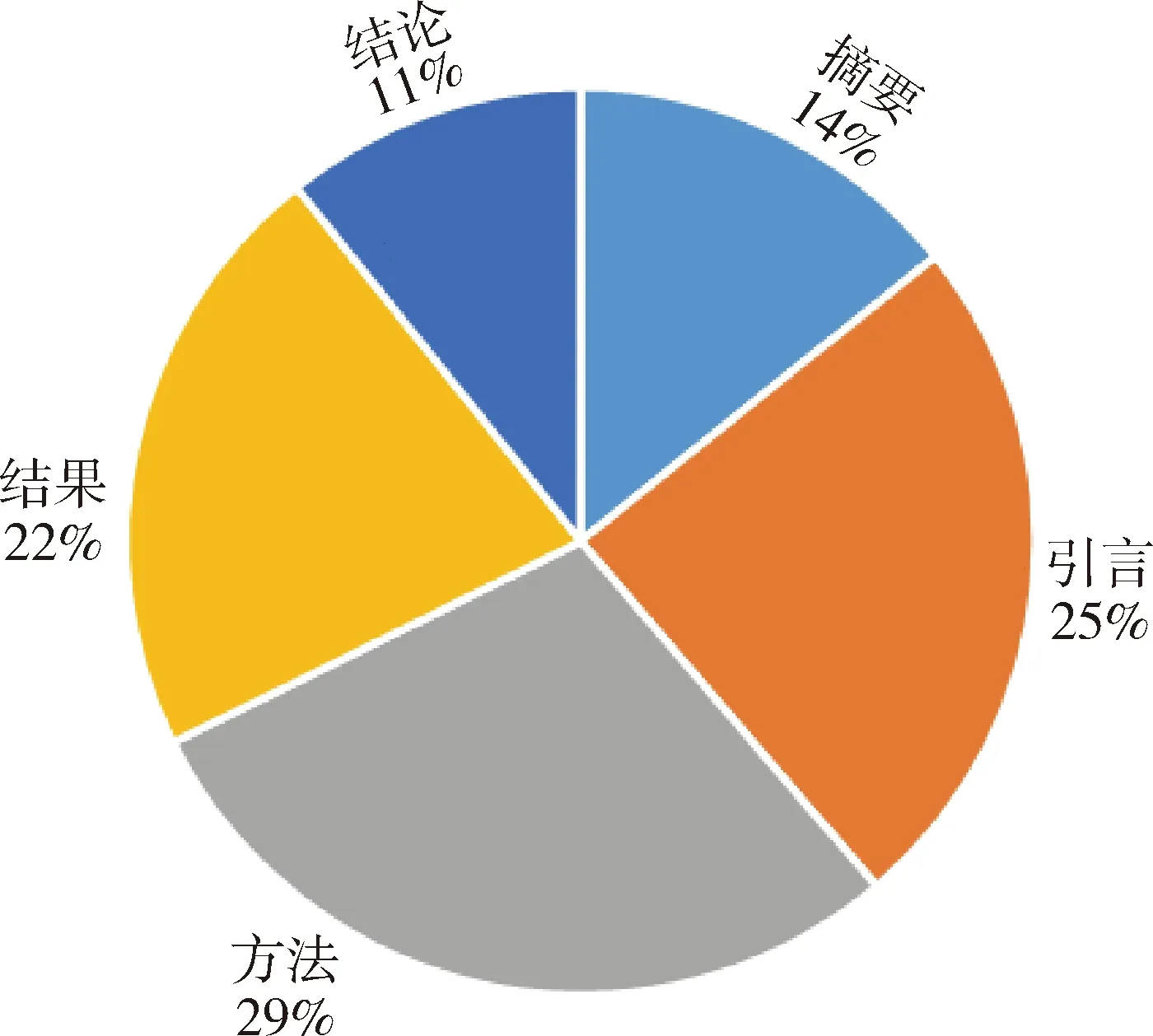
图3 算法类别各章节分布情况
算法类别在不同章节类型中的提及论文数不同,其中提及论文数最多的是“方法 ”部分,“结论” 部分最少。“摘要”部分是对全文的简要概括,部分期刊要求其包含“目的”、“方法”、“结果”、“结论”4部分,导致此章节类型中算法提及论文数较低; “引言”部分需对文章所用算法做简单背景介绍,因此会有一定频次的算法提及; “方法”部分是全文描述方法核心部分,算法在该章节类型提及论文数显著增加;“结果”部分对实验所得结果进行分析,不需要对算法相关内容进行详细阐述,因此算法提及论文数相对下降; “结论”部分对全文大致流程和结果做简要总结但不会大量描述,此章节类型算法提及论文数较少。综上,在不同章节类型提及算法其作用不同、影响力不同。本文重点针对“方法”和“结果”章节,分析不同位置各算法类别共现情况,见表7。算法类别提及次数在“方法”与“结果”部分一般高于其他章节类型,其次是“引言”部分,在“摘要”和“结论”部分提及较少。说明医学信息学研究领域算法主要作为具体实验方法使用。根据“方法”和“结果”章节类型统计结果,排前3位的为分类、统计、人工神经网络算法,其提及论文数远高于其他算法;回归、聚类、降维、遗传算法提及论文数较高;检测和粗糙集算法提及较少。与前文研究结果一致。
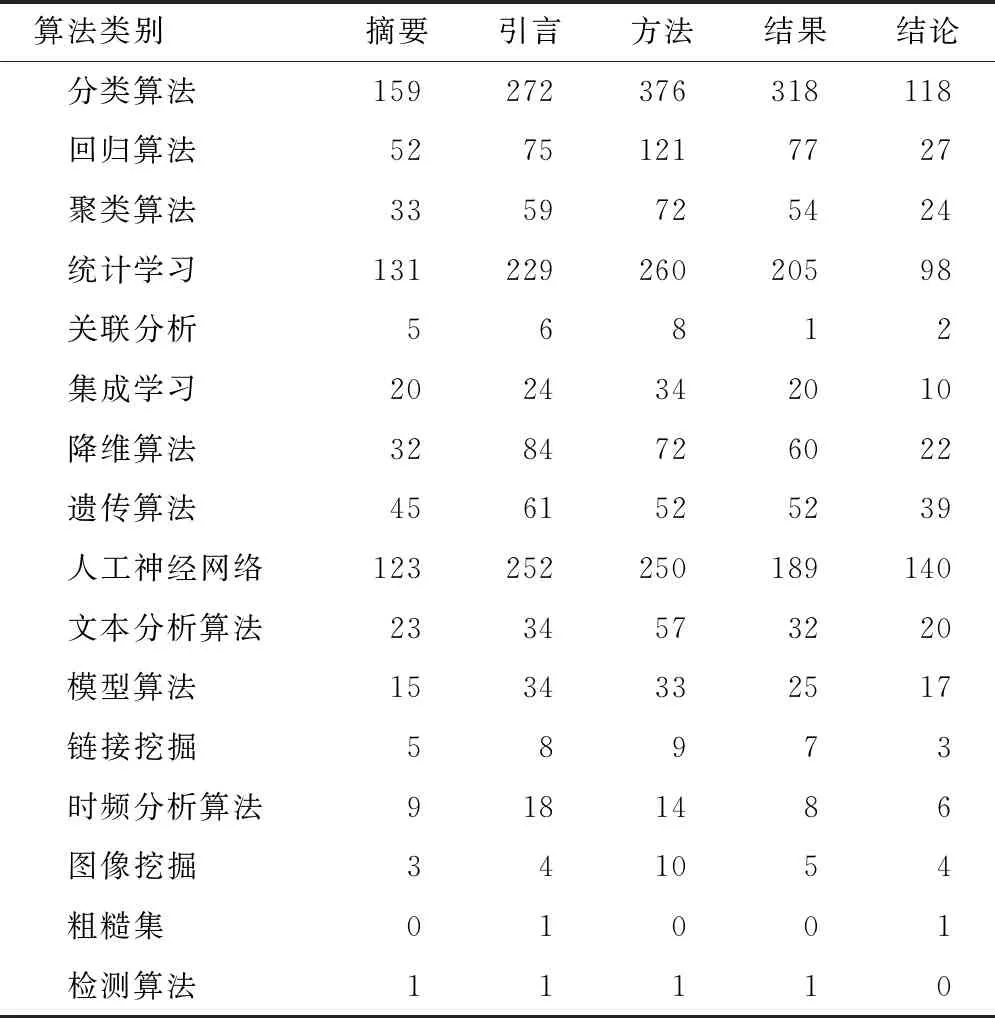
表7 各个算法类别在各章节类型中分布情况
3.2.3 基于共现情况的算法类别影响力分析 利用VOSviewer软件依据提及论文数分析170种算法共现情况,见图4,其中节点越大表示算法被提及次数越多,即重要性越大、影响力越大;连线表示两种算法在同一篇文中被共同提及次数,次数越多连线越粗。在收集到的705篇文章中提及两种或两种以上算法的512篇,约占73%。统计学习算法类别中支持向量机(Support Vector Machine,SVM)算法节点最大且与其他71种算法均有连线,说明SVM算法是医学信息学领域常用算法。研究发现SVM算法主要受统计学理论支持,是一种非线性机器学习算法,能够对数据进行高精度处理[14],是最稳定、最精确的算法之一[10]。分类算法类别中的Naive Bayes节点与其他60种算法均有连线,其中与人工神经网络算法中的近似最近邻(Approximate Nearest Neighbors,ANN)算法、回归算法中的逻辑回归(Logistic Regression,LR)算法、分类算法中的决策树(Decision Tree,DT)和随机森林(Random Forest,RF)算法共现次数较高,超过40次。这可能由于其原理简单,易应用于大量数据集。K-近邻算法(K-Nearest Neighbor,KNN)排名第3,可能由于其精度高且适用数据范围为数值型和标符型,处理数据较方便。同时分类算法中的RF、DT、C4.5算法及人工神经网络算法类别中的ANN、卷积神经网络(Convolutional Neural Networks,CNN)等算法也具有较高共现次数。这可能由于RF算法能有效运行于大数据集,评估各特征在分类问题上的重要性,在预测疾病风险和患者诊断方面应用前景广阔;ANN是一种类似于生物神经网络的非线性算法,可模拟人脑某些智能行为,为近年研究热点[16]。LR算法、降维算法类别中的主成分分析(Principal Component Analysis,PCA)算法、遗传算法等节点较大,聚类算法类别各算法节点较小且连线强度较低。说明分类、统计、人工神经网络算法共现使用较为频繁,而聚类算法多为单独使用。
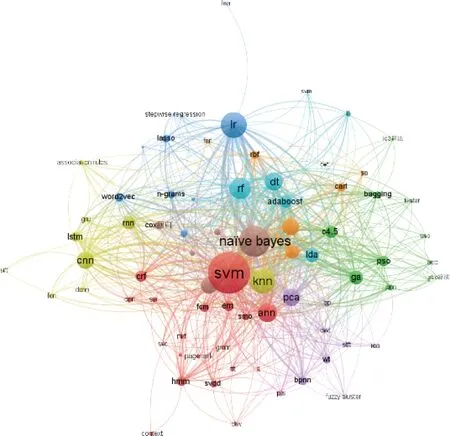
图4 算法共现情况网络图谱
4 讨论
4.1 算法类别使用总体趋势
除2015年外,期刊中使用算法类别的论文比例呈逐年上升趋势;各期刊对算法类别依赖程度不同。医学信息学领域算法使用类文章不足30%,与软件使用类文章占比接近[16]。说明该领域研究对算法和软件依赖性较低,但呈逐年上升趋势;不同期刊对算法类别依赖程度不同,16种算法类别在《生物医学中的计算机方法和程序》期刊均有涉及。
4.2 算法类别使用影响力
分类、统计、人工神经网络等算法类别提及次数较多、提及位置较集中、共现次数较多,具有较高影响力。首先,算法类别提及论文数和提及总次数指标对算法类别影响力评估几乎没有差别。可以假定算法类别影响力范围越广、提及论文数越多,相应提及总次数越高。就提及次数来看,提及论文数和提及总次数可反映算法类别影响力广度。而平均提及次数相较前两项指标对算法类别影响力评估有一定变化,排在前3位的算法类别均排名下跌但仍居前列。可以认为算法类别对论文影响力程度越深平均提及次数越高。其次,提及位置影响力反映算法类别在论文不同位置的集中程度,提及位置影响力越高算法类别在“方法”和“结果”部分的占比越大。最后,共现情况影响力越高,算法影响范围越大,集中程度越高。综上,分类、统计、人工神经网络算法影响力广度和深度均高于其他算法;回归、聚类、降维、遗传算法影响力广度和深度次之;检测和粗糙集算法类别影响力广度和深度最低。此外,模型和文本分析算法影响力广度不足,但有较强深度,说明其在少数论文中反复使用,在“方法” 和“结果”位置的集中程度、共现情况影响力均排在中后位置。
5 结语
基于内容分析的量化评估可相对全面地统计算法类别在特定领域使用情况,有助于了解算法类别价值并根据科研任务类型选择算法类别及决策算法。未来可考虑获取多种期刊全部论文进行研究;在现有研究基础上可基于年代、使用国家等更多方面进行影响力评估;可区分算法提及和算法使用概念,研究算法类别在文中不同使用身份的影响力差异。
