基于边缘PUnet网络的虚拟视图空洞修复①
2020-11-24杨小利马汉杰
杨小利,冯 杰,马汉杰,董 慧,王 健
(浙江理工大学 信息学院,杭州 310018)
虚拟视点合成有着广阔的应用前景,可应用于3D 立体游戏、虚拟现实等方面[1].基于深度图的绘制(Depth Image Based Rendering,DIBR)因其绘制速度快、网络传输负担小、虚拟视点不受限等优点,已经成为虚拟视点合成的关键技术.DIBR 技术利用参考视图及其对应的深度图来生成左右虚拟视点图像[2],但生成后的虚拟视图存在着裂缝、伪影和大面积空洞的问题,这些问题降低了虚拟视点图像的质量,尤其是大面积空洞[3].
虚拟视图中的大面积空洞修复一直是个热点,同时也是一个难点.大面积空洞通常采用图像修复技术进行修复,基于样本块的修复方法是图像修复的经典算法[4],很多图像修复算法都是在该算法的基础上做出相应的改进得来,例如文献[5,6].基于样本块的方法的核心思想是不断迭代地用相似的非空洞区域块来替换空洞区域的图像块.该方法对于无结构和纹理平缓变化的空洞区域具有较好的修复效果,但其修复后的空洞区域缺乏视觉语义概念.且图像已知区域没有空洞所需的信息,则该方法无法填充在视觉上合理的空洞.现有的部分卷积神经网络(PUnet)[7]以逐层抽象的方式提取图像的特征映射,从而使修复后的空洞区域具有语义感,但其没有定位到更精细的纹理,修复后的边缘部分存在着过度平滑,甚至轻微失真.虚拟视图中的大面积空洞通常出现在前后背景交界处,即边缘处.很明显PUnet 网络对于虚拟视点图像中的空洞修复效果并不友好.
针对传统图像修复算法修复空洞后图像存在的语义缺失问题,以及现有的PUnet 网络修复后的空洞边缘失真,本文提出了基于边缘信息的部分卷积网络(Edge-PUnet)的修复方法.本文方法总体流程如图1所示.
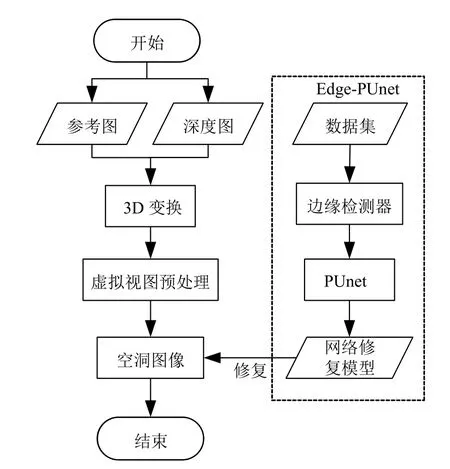
图1 本文方法流程图
1 虚拟视图生成与预处理
1.1 3D 变换
本文3D 变换使用的是从中心图像生成左右虚拟视图的并行摄像机配置,在该配置下,任何三维点投影到左右虚拟视图的垂直坐标与投影到中心图像(即参考视图)的垂直坐标是相同的[8].左右虚拟视图的横坐标可由参考视图的横坐标按视差进行移位得到.根据视差与深度的关系[9],图像中每个像素点的视差可由参考视图的深度图计算出,如式(1)所示.
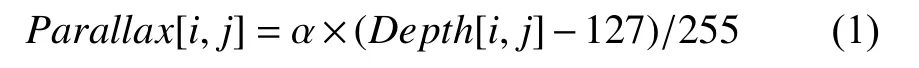
其中,Parallax[i,j],Depth[i,j]分别是参考视图中每个像素的视差值和深度值,i和j分别是图像的横纵坐标,127 为零视差平面,255 为最大视差,在本文中,α设置为15.
虚拟视图以整数位置上的像素值为有效值,因此对移位后的像素坐标进行四舍五入取整,取整的像素通常是离整数位置上最近的映射像素,左、右虚拟视图横坐标移位如式(2)和式(3)所示.

在式(2)和式(3)中,∏表示向下整,i,iL,iR分别是参考视图、左虚拟视图和右虚拟视图的像素横坐标.根据视差估计移位得到的左右虚拟视图如图2所示.

图2 DIBR 技术生成的虚拟视图
在参考视图向虚拟视图映射的过程中,用矩阵标记虚拟视图中的像素是否为映射点,从而生成左右虚拟视图掩膜,生成的左右虚拟视图掩膜如图3所示.
1.2 虚拟视图预处理
在虚拟视图绘制的过程中,生成了对后期空洞修复产生影响的裂缝和伪影,修复空洞前需对这些伪像进行去除,裂缝在虚拟视图中的宽度为一个像素大小,且出现在相同的纹理区域下[10].因此本文从水平和垂直两个方向对裂缝进行邻近像素赋值以去除裂缝,其中水平方向上按照左右虚拟视图映射方向的不同,分别从左侧和右侧进行邻近像素赋值,裂缝去除效果如图4所示.对于伪影,则对虚拟视图掩膜进行膨胀,作用于虚拟视图的空洞,从而消除空洞边界处的伪影,伪影去除效果如图5所示.

图3 左右虚拟视图掩膜

图4 裂缝去除效果

图5 伪影去除效果
去除这些伪像后,虚拟视图中仅含有空洞,如图6所示.然后利用本文提出的Edge-PUnet 网络修复虚拟视图中的大面积空洞.

图6 空洞虚拟视图
2 虚拟视图空洞修复
2.1 边缘检测器
虚拟视图中的空洞通常是由于三维场景中物体之间的遮挡关系引起的[11,12],因此空洞通常出现在前后背景交界处,即边缘处.如图6所示.边缘是图像信息最集中的地方,包含着纹理、结构等丰富的信息[13].基于此,本文在PUnet 网络中设计了边缘检测器,以使网络重点学习图像的边缘部分.
虚拟视图中的空洞通常是纵向的,因此本文的边缘检测器主要检测的是图像中的垂直边缘部分,边缘检测器检测步骤如下:
(1)对输入的图形进行灰度化操作,将彩色图转换为灰度图,其转换过程如下所示:
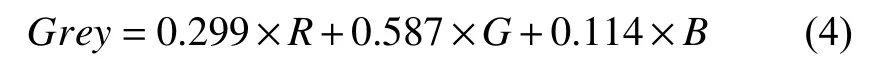
其中,R、G、B为彩色图像三通道中像素的值.
(2)利用高斯滤波器对灰度图进行卷积操作以滤除噪声,防止噪声引起的错误边缘检测.噪声滤除过程如下所示:

其中,H为高斯滤波器核,计算如下所示:
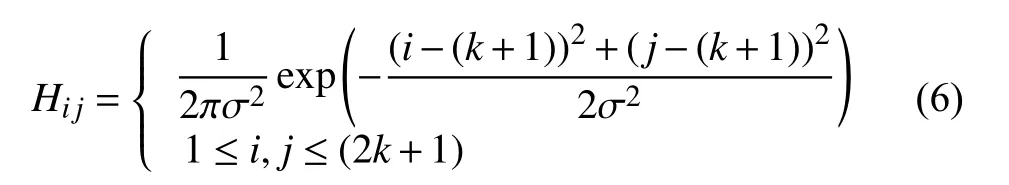
式中,i和j为像素的横纵坐标,(2k+1)为高斯滤波器核的大小,设置K为2,σ=1.5.
(3)利用Sobel 算子检测出图像中垂直方向上的边缘,其检测依据是每个像素点的方向,如下所示:


在上述公式中,Sx,Sy分别是x和y方向上的Sobel 算子,Gx,Gy分别是像素点水平和垂直方向的梯度值.
(4)利用膨胀函数对其存在断点的垂直边缘进行连接,并对处理过后垂直边缘图进行二值化,生成由0 和1 组成的二进制边缘掩膜图.
最终生成的二进制边缘掩膜如图7(b)所示.PUnet网络需要大量的数据集进行训练,若小将产生过拟合.为了扩大数据集,本文对检测出来的边缘掩膜进行随机保存,在保存的过程中,边缘宽窄和高低是随机调整的.将随机边缘掩膜与图片作用生成边缘随机缺失图像,彩色图、随机边缘掩膜传入PUnet 网络中.
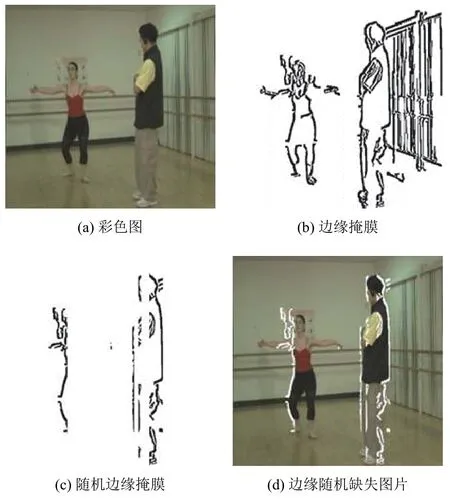
图7 边缘检测器检测边缘
2.2 PUnet 网络
PUnet 网络架构如图8所示,PUnet 网络结构主要包括编码器和解码器两个部分,编码器包含8 个部分卷积层,每次卷积后对特征图进行1/2 的下采样(即最大池化),然后对数据进行归一化处理,并对其进行非线性变换,非线性函数为ReLU.解码器包含8 个最近邻上采样层,上采样层对得到的特征进行解码,得到图像和掩膜的特征图,将得到的特征图在通道维上与编码器对应的图像和掩膜的特征图分别连接(即Skip-Connection),然后对解码器和编码器的特征图分别进行卷积并相加,跳过连接之后对数据进行归一化处理和非线性变换,非线性函数为LeakyReLU.

图8 PUnet 网络结构简图
在PUnet 网络中,编码器利用部分卷积层逐层提取图像的语义特征,即物体与其周围环境之间的关系,最大池化层用来降低特征图的维度和保留有效的纹理信息,池化层提高了特征的空间不变性,在池化的过程中编码器逐步丢失了背景信息,解码器阶段上采样逐步将编码器得到的高级语义特征图恢复到原图片的分辨率,并通过Skip-Connection 融合来自于编码器的低级特征.这使修复的图片的边缘、纹理等信息更加精细.
传统的卷积神经网络修复空洞时,需要对空洞区域进行初始化,空洞的初始值一般设置为127.5 或者图片的平均值.设置了初始值的空洞区域和非空洞区域被网络同等对待,混淆了网络,进而导致空洞修复的效果受空洞初始值的影响.PUnet 网络部分卷积层采用的是部分卷积运算,即当前卷积核窗口下的输出值仅取决于掩膜中未隐藏的输入,也就是说卷积操作时会忽略空洞区域的值,只利用非空洞区域的值进行卷积操作,从而消除了以往的卷积神经网络对空洞进行卷积操作所造成的不良影响.每次部分卷积之后更新空洞掩膜,即在当前卷积核窗口下,若卷积不能将输出设定在至少一个有效的输入值上,那么将该卷积核窗口下的掩膜值设为0,随着卷积的深入,掩膜中为0 的像素越来越少(即掩模中空洞越来越小),直到个数为0,输出结果中有效区域的面积越来越大.
2.3 损失函数
PUnet 网络的损失函数包括4 种,分别是逐像素求差损失、感知损失、风格损失和总变差损失.逐像素求差公式如式(10)和式(11)所示,该损失函数可以衡量生成图片跟真实图片之间的差异.但是并不能捕捉生成图像跟真实图片的感知和语义差别,文献[14]表明高质量的图像可以通过建立感知损失函数并使损失函数最小化来生成,生成的图像在细节和边缘上表现的更好,因此损失函数中加入文献[15]引入的感知损失,如式(12)所示.为了恢复生成图片的颜色纹理和精确的形状,同时减少边界处的伪影,加入了风格损失函数,如式(13)和式(14)所示.总变差损失函数是对空洞区域中单个像素扩张进行的平滑惩罚,如式(15)所示.

式中,Iout表示网络预测图像,Igt表示真实图像,NIgt表示真实图像中的像素个数,‖·‖1表示求L1距离,M是当前卷积核窗口在二进制随机边缘掩膜上的像素值,Lh为当前卷积核窗口下掩膜区域的损失,Lv为非掩膜区域下的损失.

式中,Icomp是网络输出图像Iout中非空洞像素直接设置为真实像素得到的.是给定输入图像的第P层的激活映射,为的元素个数.
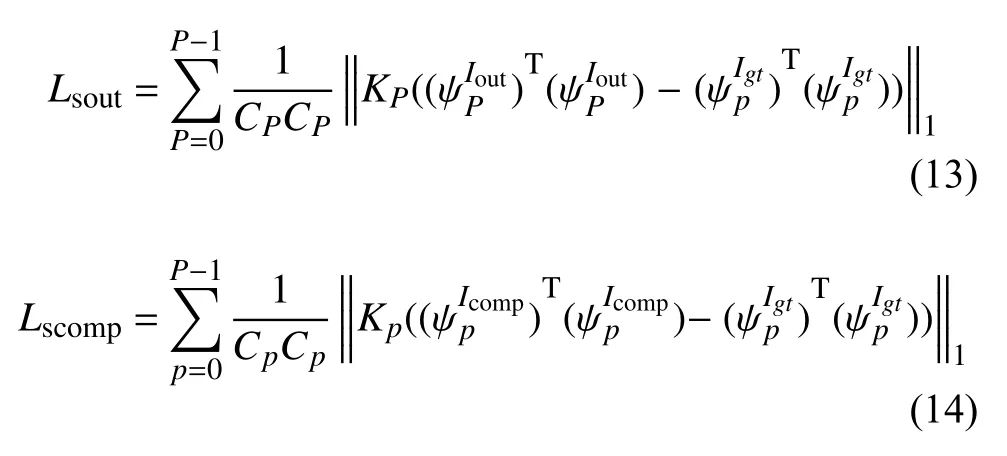
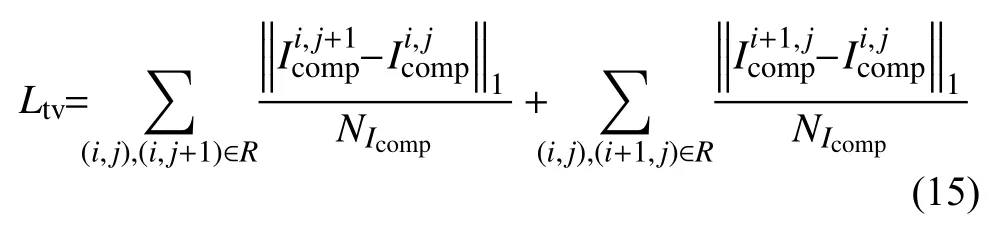
其中,R是空洞区域单个像素的扩张区域,NIcomp为Icomp网络输出图像的像素个数.
总损失是上述损失的组合,各个损失函数的权重由测试图像所得,如式(16)所示.
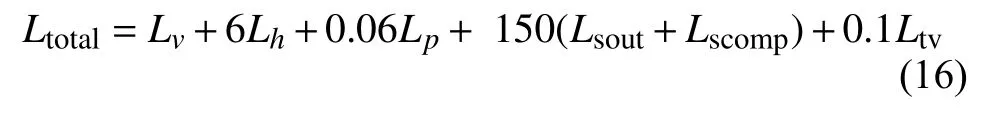
2.4 网络训练
本文实验的数据集为微软数据集的Ballet 和Breakdancers 视频序列,其中训练集、验证集和测试集图片数分别为1000、400 和200 张,分辨率为1024×768.在训练的过程中对该数据集进行旋转、平移变换、尺度变换等数据增强扩充处理.同时对输入的图片进行归一化处理,并缩放到512×512,以减少网络训练所需内存.
本文的实验是在Linux 平台下的TensorFlow 框架下进行,并以Keras 为框架的前端.训练首先加载由ImageNet 训练而来的VGG16 模型来初始化权重,并采用Adam 优化算法对数据集进行批归一化处理,采用batch_size=4 将图片输入网络,在数据集上以0.0003的学习率迭代训练60 000 个周期,每个周期迭代训练250 次.
3 实验分析
本文的虚拟视点图像是以Ballet 和Breakdancers视频序列中cam3 视点下的参考图和深度图进行DIBR变换得到的.采用主观评价和客观评价的方式对空洞修复的效果进行评价.其中客观评价的指标为峰值信噪比(PSNR)和结构相似度(SSIM).PSNR 是基于像素间的误差,单位是dB.SSIM 分别从亮度、对比度、结构3 方面度量参考视图和虚拟视图的相似性,其取值范围为[0,1].PSNR 和SSIM 值越大,表示图像失真越小.
基于样本块的修复方法[6]、PUnet 方法[7]和本文方法修复空洞的效果如图9和图10所示.从图中可以看出,当空洞处在纹理平缓变化和结构单一的位置,基于样本块的修复方法、PUnet 方法和本文方法对空洞都有着良好的修复效果,修复后的空洞能保持与周围背景的一致性.在纹理剧烈变化位置处的大空洞处,例如图9和图10中前景与背景的交接处,即边缘处,可以看到基于样本快方法修复后的图像边缘存在着严重的失真现象.

图9 不同方法对Ballet 虚拟视图修复效果对比

图10 不同方法对Breakdancers 虚拟视图修复效果对比
放大其修复后的图片,如图11和图12所示,可以看到基于样本块方法修复后的图片边缘存着典型的块效应,且前景一部分像素过渡到了背景区域.这是由于填充的部分是空洞周围与之相似的纹理块造成的,而PUnet 方法和本文方法修复后的边缘比较平滑,其前景像素能够自然的过渡到背景区域,在高度结构化区域处的空洞,对比PUnet 方法修复的效果,本文修复后的空洞在边缘细节方面表现的更好.例如,在图11男听众的头部区域,PUnet 方法修复后的眼睛与手连接区域存在着轻微模糊现象,以及衣领部分被过渡平滑到背景区域,而本文修复后的该处区域结构和边缘更为清晰,有着更好的视觉效果.

图12 不同方法对Breakdancers 虚拟视图修复效果局部放大对比
为做出较为正确的客观评价,本文分别在Ballet和Breakdancers 视频序列中cam3 摄像机视点下选取了30 张图片作为参考视图,并利用3D 变换技术生成虚拟视点图像,修复空洞后计算每张图片的PSNR 和SSIM 值,最后取其平均值.不同方法修复效果的PSNR和SSIM 值如表1和表2所示.从表中可看出,本文的方法修复后的图像PSNR 和SSIM 值明显比基于样本块方法和PUnet 方法的高,说明本文方法修复后的图像有着较小的失真,且与真实图像更接近.同时达到一样的空洞修复效果,相比于PUnet 方法利用不规则掩膜作用于数据集进行网络训练.本文利用边缘掩膜作用于数据集进行训练的时间要短.

表1 不同方法修复的PSNR 比较

表2 不同方法修复的SSIM 比较
4 结论与展望
针对传统图像修复算法修复的缺点,以及现有的PUnet 方法修复后的空洞图像边缘模糊甚至失真现象,本文提出了一种基于边缘信息的部分卷积神经网络方法,在修复虚拟视图空洞前,本文对虚拟视图进行预处理,以消除虚拟视图中裂缝和伪影对后期空洞修复的影响.然后利用提出的Edge-PUnet 网络修复空洞,相比于传统的图像修复方法,本文修复后的空洞区域具有良好的结构和语义信息,相比现有的部分卷积神经网络,本文修复后的空洞边缘更加精细.不足的是在修复虚拟视图过程中没有考虑到视频的连续性,这是下一步努力的方向.
