基于Pytorch和神经网络的云数据中心故障检测①
2020-11-24来风刚李济伟王怀宇牟霄寒
来风刚,刘 军,李济伟,王怀宇,牟霄寒,刘 赛
1(国家电网有限公司信息通信分公司,北京 100761)
2(南瑞集团(国网电力科学研究院)有限公司,南京 211106)
3(南京南瑞信息通信科技有限公司,南京 210003)
信息时代的到来使得数据量急剧增长,云数据中心逐渐成为研究的热门之一[1,2].近年来,数据中心同样在智能电网中得到广泛应用,通过将数据在云端进行存储,处理,能够实现高速率、低成本储存和管理,提高运行效率[3].设备管理是云数据中心正常运行的必要环节之一,通过对设备运行参数进行采集,对设备运行状况进行诊断.设备运行故障能否被及时检测,直接关系到数据中心的安全运行.
在智能电网领域,设备故障检测方法主要针对于电网中各种元件.当故障元件的电气量发生突变时,利用一些智能诊断方法对电气量的异常信息进行分析,从而找出产生故障的元件,发现故障原因.这些诊断方法主要包括专家系统[4],贝叶斯网络[5],多信息融合技术[6]和神经网络[7]等.然而,这些故障诊断方法主要针对于电网中的电力传输部件,例如变压器,电缆,开关等.云数据中心作为新兴技术之一,其运行设备主要由网络设备构成,而电网现有的设备故障检测方案显然无法满足云数据中心的要求.
目前云数据中心故障检测方法主要从网络层次进行故障诊断,这些方法将数据中心设备划分为“基本功能单元组”,利用不同算法对发生故障单元进行检测[8,9].考虑到数据中心数据的复杂性,这些算法多数基于仿真实验进行.且在单元层次对故障进行检测后,后续仍需要故障发生位置进行进一步的确认.因此这类算法在实际应用中的可靠性有待商榷.
为解决上述问题,对云数据中心设备故障进行检测,同时对未来运行状况进行预测,保证设备正常运行.本文研究了一种基于Pytorch 以及神经网络的设备故障检测方法,在对数据进行预处理后,利用自然语言处理类方法使神经网络能够学习到对故障检测有效的特征,并使用长短期记忆网络(Long Short-Term Memory,LSTM)对故障进行检测.基于阿里集群数据的实验结果显示,本方案能够有效检测设备运行故障,并对运行状况进行预测.本文的创新点总结如下:
(1) 采用GRU (Gate Recurrent Unit) 模型作为架构基础,相比常用的LSTM 模型,运算量显著减少,训练速度得到提升.
(2) 双向GRU 叠加的设计使得每个GRU 单元在当前输入的基础上,除了能够得到过去时间点的信息,还能得到该时间点之后的数据,提高了检测的准确度.
(3) 在双向GRU 输出的基础上采用了自注意力机制,使得重要信息能够通过训练获得更高的权重,解决了信息超载问题并进一步提高检测准确率.
(4) Embedding 层和多层感知机对自注意力层的输出进行进一步处理,在降低数据维度基础上提高了分类效果.
本文后续内容组织如下,首先介绍循环神经网络的基本架构,以及优缺点,并引出在检测任务中常用的LSTM 模型.接下来对模型所采用的数据集进行概括,并提出基于GRU 改进后的模型架构.最后展示了实验结果并对提出的框架作了简要总结.
1 循环神经网络
神经网络被大多数人视为能够拟合任意函数的黑盒子,给定足够的训练数据,以及数据标签,在设定合适的损失函数后,神经网络就能够被充分训练并在输出层得到特定的y.这一拟合能力近似于常见的连续非线性函数,称为通用近似定理[10]:
令φ (x)代表非常数、有界、单调递增的连续函数,JD代表一个D维的单位超立方体,定义为[0,1]D.令C(JD) 表示JD上的连续函数集合,则对于任意函数f∈C(JD),必然存在一个整数M,以及一组实数vm,bm∈R,向量wm∈RD,m=1,···,M,使得:

其中,F(x)作为函数f的近似实现,且F(x)定义如下:
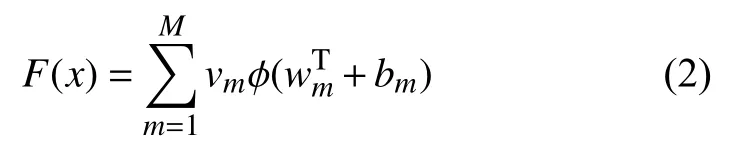
根据通用近似定理,如果神经网络具有线性输出层,以及至少一个使用“挤压”性质的激活函数的隐藏层,则该神经网络就能够以任意的精度近似任何一个定义在 RD中的有界闭集函数.这里,“挤压”性质的激活函数可以是类似Sigmoid 函数的有界函数.神经网络强大的拟合能力使其能够拟合任意复杂的非线性关系,在各种复杂的应用场景中提供了坚实的理论基础.
循环神经网络(Recurrent Neural Network,RNN)是深度学习的经典算法之一,其具有记忆性,能够捕捉输入信息中的时间顺序关联,因此常被用于时间序列数据分析[11].RNN 已经在自然语言处理领域,例如语言识别,语言建模和机器翻译等场景取得成功应用.然而,普通的神经网络存在一个缺陷,即只能近似输入与输出之间的关系,而前一个与后一个输入之间的关系无法处理.对于大多数序列信息,例如文本数据,金融时间数据,前后数据之间存在复杂的依赖关系,普通的神经网络难以捕捉.RNN 正是针对处理序列信息而设计的,图1展示了RNN 的基本架构.
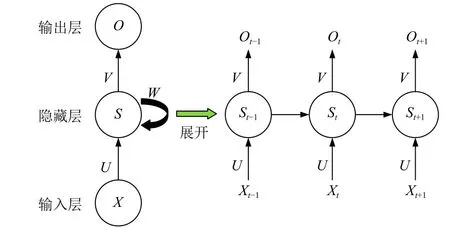
图1 循环神经网络的基本架构
如图1所示,RNN 由输入层、隐藏层和输出层组成,隐藏层展开后可以看到由多个神经元串联组成,这里则是循环神经网络和普通神经网络的根本差别.U,V,W分别表示输入层到隐藏层,隐藏层到输出层和隐藏层的参数,Xt-1,Xt,Xt+1表示不同时刻的输入.从图1中可以发现,隐藏层St在t时刻除了接受来自Xt的输入外,还从左边接受St-1时刻的输入,这就使得未来的时刻能够保留过去时刻传来的信息,因此循环神经网络能够捕捉输入数据中的时序关系.
上述过程用公式表述如下:

可以看到St的值由Xt和St-1共同决定,Ot则是最终输出.
在文献[12]中,作者使用RNN 对5432 例阿兹海默症病人的进展进行预测,时间跨度从2005 至2017年.实验结果显示循环神经网络能够很好地捕捉单个病人在多次检查中的时序变化信息,即便时间间隔并不均匀.更多地,实验结果显示循环神经网络在测试集预测病人下一次检查结果的AD 进展上达到了99%的准确率,这表明RNN 在时序信息分析上的强大能力.类似的,在云数据中心中,设备的信息、日志数据等同样以时间序列顺序被记录.这些数据在时间顺序上的变化能够精确地被循环神经网络所捕捉,并且学习到数据随时间变化的复杂非线性关系,从而实现对设备未来状态的预测.
在实际应用中,研究者发现循环神经网络难以处理信息的长时间依赖关系,一个简单的例子是在英文句子生成时,如果句子很长,在生成谓语动词时,循环神经网络无法记住主语的单复数形式并选择合适的谓语动词.为了解决这一问题,门控机制被提出,即大多数错误检测模型常用的LSTM.在LSTM 中,门控机制包括遗忘门(forget gate)、输入门(input gate)和输出门(output gate).其中,遗忘门用于控制前一时刻输入信息通过的比例,仅仅保留部分重要信息向后传递而忽略无关信息.包括细胞状态和隐藏状态两种,LSTM原理如图2所示.
图2中,Xt表示输入ht表示输出.σ 和t anh 激活函数的组合控制输入信息能否通过门控向后传递,即选择性遗忘.基于LSTM 模型强大的处理长时程信息依赖的能力,该模型已经成为错误检测研究中的常用模型[13,14].

图2 长短期记忆网络的基本架构
2 Pytorch 机器学习框架
Pytorch 是一个著名的基于Torch 的Python 机器学习库,由Facebook 的人工智能研究组在Torch 的基础上开发.Pytorch 在学术领域广泛应用,作为常用深度学习研究平台之一[15],其API 接口统一,采用了动态计算图机制和自动求导机制,能够方便地搭建定制化的神经网络并进行训练.相对于谷歌开发的TensorFlow框架,Pytorch 拥有以下几点优势:
(1) Pytorch 中的模型定义更为简单,并且提供了容易调用的包,而TensorFlow 接口定义种类繁杂.
(2) Pytorch 所采用的动态图计算机制相比TensorFlow的静态图更加灵活,对于研究者更加友好,
(3) 对Caffe 具有良好的支持,可以联合英伟达GPU进行高效的神经网络训练.
3 实验及结果分析
3.1 实验数据
云数据中心已经成为互联网的基础设施,在网络流量日益增长的今天起到核心作用,与此同时,云数据中心的网络设备故障的发生率也在上升,这使得服务器的性能下降,对用户终端的使用体验造成影响.本文采用循环神经网络训练公开的数据中心数据集,并对未来故障进行预测,这样运维人员可以在潜在故障发生前进行干预并解决.
实验使用数据集为阿里巴巴集团在Github 平台公布的阿里云集群数据[16],该数据集包括以下两部分数据:
(1) cluster-trace-v2017:1300 台机器12 小时的运行数据.该批数据包含在线服务的数据集合以及批次化的工作负荷记录.
(2) cluster-trace-v2018:4000 台机器长达8 天的运行数据.该批数据除了包含v2017 的数据种类外,额外包含DAG 产品的运行负荷信息[17].
本文采用了cluster-trace-v2018 数据集进行训练和测试,预测所包含的故障分为设备响应时间过长,CPU利用率过高,内存利用率过高和传输信息速率低5 种.实验所采取的流程如图3所示.
如图3所示,首先对数据进行预处理,包括去冗余与清洗,标准化两步.冗余数据指与故障预测没有关联的数据或者数据不随时间变化的数据,例如设备型号信息,不同客户账号信息等.冗余信息对预测效果没有影响并且会造成额外计算负担,因此预先对冗余进行清洗是重要一步.数据集标准化是提高预测效果的重要步骤,当不同机器间指标水平相差较大时,直接用原始指标进行分析会突出数值较高指标在预测中的作用,导致高数值指标在预测中所占权重过大,影响结果的可靠性.这里我们对机器的不同指标采用最为常用的Z-score 标准化,以时间序列x1,x2,···,xn为例,Zscore 计算方式为:

则新序列y1,y2,···,yn的均值为0,标准差为1.Z-score方法对数值区间较大,离群值较多的情况比较合适,在对不同指标进行Z-score 处理后,能够使数据落入一个较小的区间,减轻不同指标间数值差异的影响.
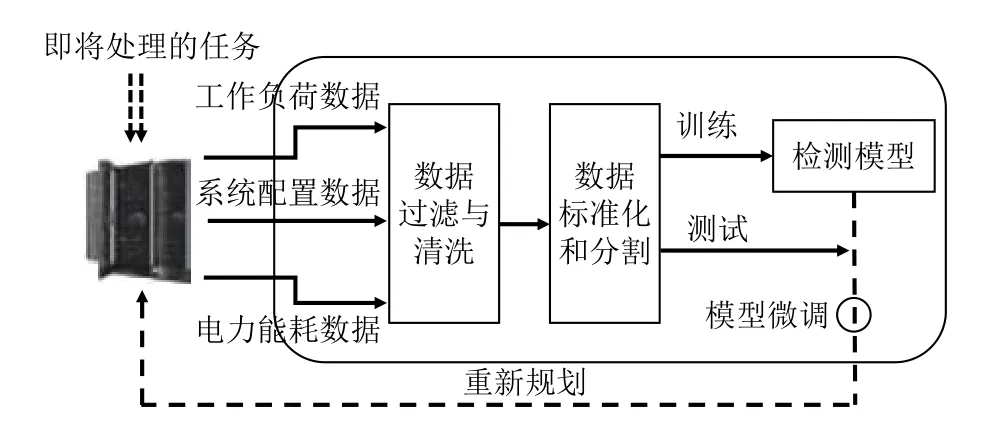
图3 实验流程图
本文以每1 分钟的数据为一个窗口,将1 分钟的阿里云硬件集群的各项指标进行平均,作为单个数据进行统计.本文使用统计检验将CPU 使用率和内存分配率等指标与平均指标严重偏离的时间点作为故障时间点(P-value<0.05).CPU 使用率在一天内使用率波动较大,在部分时间点存在高峰,经过统计后发现在高峰使用期故障发生率较高,这与真实情况相符合.针对内存使用故障,使用请求内存和真实使用内存之差作为判断故障指标(P-value<0.05).统计结果表明CPU 使用率高峰和内存使用故障高峰存在一定的关联,这正常情况相一致.在实验中仅考虑单个时间点只存在一种故障,将故障检测视为单标签分类问题.图4显示了不同故障数目的柱形图.
3.2 网络结构与实验结果
本文使用的检测模型设计架构如图5所示.
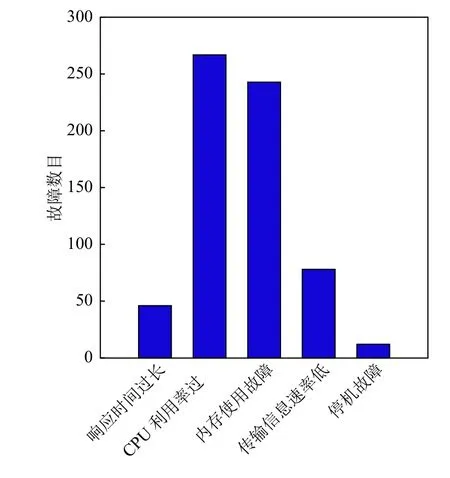
图4 故障数目统计
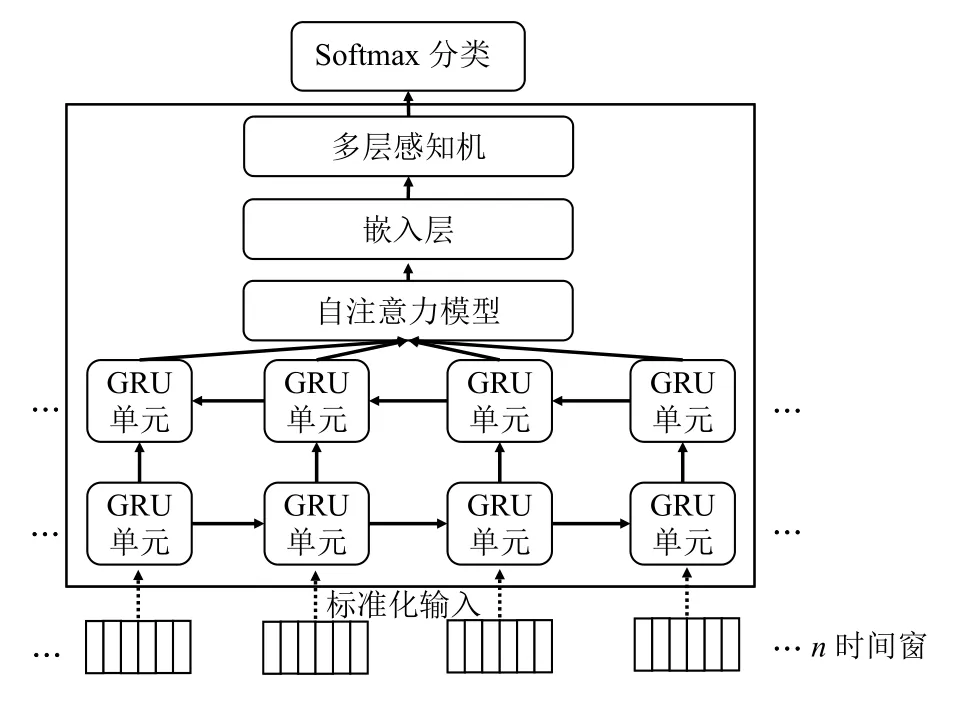
图5 神经网络架构
图5中,输入层包含200 个神经元,因此数据被分割为200 个时间窗输入.本文使用双向门控循环神经网络处理数据输入.双向门控循环神经网络(BiGRU)可以看做的LSTM 一种拓展,将LSTM 中的LSTM 模块替换为GRU 并使用双层GRU 模块反向叠加.GRU将LSTM 中隐藏状态和细胞状态合并成一种状态,因此显著缩短了训练时间.更明确地说,GRU 读取词嵌入向量ti以 及隐藏层状态向量hi−1后,经过门控计算产生输出向量Ci和 隐藏层状态向量hi,具体计算方法参考下列公式:

其中,z∈ℜd,r∈ℜd分别表示接受d维向量的输入门与重置门,{Wz,Wr,W,Vz,vr,V} 表示权重矩阵,{bz,br,b}为偏置向量,⊙表示矩阵点乘.在双向GRU 后是 selfattention 层、embedding 层和多层感知机(Multi-Layer Perception,MLP).输出层为5 个神经元组成的Softmax层,计算输入时间段在5 类故障上的概率.
为了让神经网络能够学习到对预测故障有效的特征,本文采用了自然语言处理中的embedding 技术.类似于常用的预训练词向量,在输入层后加入embedding层,其中包含100 个神经元,对输入特征起到降维作用[17].此外,在embedding 层前加入了注意力层,并使用了经典的自注意力模型.自注意力机制引入了查询向量q(query vector),通过打分函数计查询向量和输入向量直接的相关性,同时引入了一个注意力变量t∈[1,N]代表选择的索引位置.具体计算方式如下:

其中,ai是注意力分布,s(xi,q) 是注意力打分函数.自注意力打分函数采用基于缩放点积函数,缩放点积的定义如下:

其中,d表示输入向量的维度.缩放点积模型是基于点积模型的一种改进,区别在于缩放点积模型除以向量维度d的平方根.当d很大时,点积模型的值会出现较大的方差,因此导致Softmax 的梯度变小,缩放点积模型的提出解决了这一问题.可以看出,自注意力层通过查询向量实现对输入数据的权重分配,这一查询向量可以通过反向传播进行学习和优化,从而能够对重要的特征分配更大的权重.在阿里云数据中心数据集中,不同类型的数据对故障分类的重要性存在差别.例如,线程分配数目和消息队列排队数目对CPU 响应时间过长和CPU 利用率过高这两类故障类型起到直接的影响,缓存区数据量和堆栈区使用率则对内存使用故障和传输速率低起到决定性作用,而在输入数据中无法体现此类差别.因此,在双向GRU 层充分学习输入数据的时序信息后,引入自注意力层能够对映射后特征进行权重分配,使得不同位置的特征对每类故障学习不同的权重,从而提升最终的检测效果.在模型实现中,我们采用了以自注意力模型为基础的Multi-head Attention.Multi-head Attention 在自注意力基础上进行了进一步拓展,能够同时学习到GRU 输出序列的位置编码信息和特征的权重信息.该注意力机制在著名的自然语言处理模型Transformer 和Bert 中被广泛采用.
实验平台的具体配置如下:
操作系统:Windows 10.
GPU:NVIDIA RTX2080Ti,11 GB 显存.
RAM:64 GB.
深度学习框架:Pytorch 1.3 稳定版.
开发工具:Visual Studio Code.
编程语言:Python 3.6.
Adam 是一种基于随机梯度下降(Stochastic Gradient Descent,SGD)的一阶优化算法,与SGD 不同在于SGD在训练过程中学习率不会改变,而Adam 通过计算梯度的一阶和二阶矩估计动态改变学习率,是一种自适应学习率优化算法,同时结合了AdaGrad 和RMSProp两种算法的优点[18].
本文将数据集分割为训练集与测试集,其中验证集数目占20%,训练集数目占80%.使用Adam 优化算法训练神经网络,实验结果显示Adam 算法效果卓越,如图6所示,在使用Adam 算法后,训练集和测试集上的loss 均能够降低到0.05 左右.
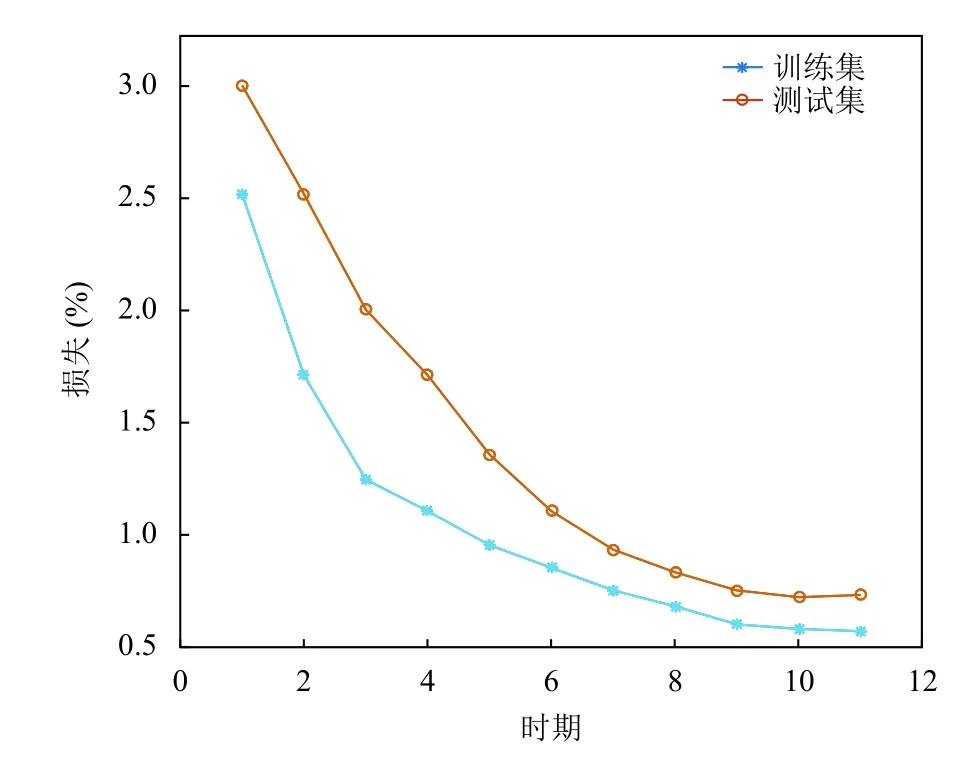
图6 模型损失函数变化
图7展示了神经网络对于故障检测的准确率,在实验中,设置batch 大小为200,通过11 个epoch 后算法已经接近收敛并在测试集上获得了超过98%的准确率.
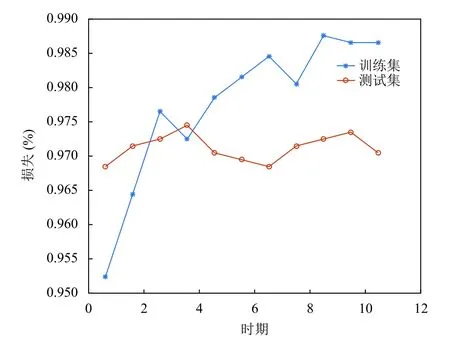
图7 模型准确率
作为对比,本文使用SVM,KNN 和普通LSTM 模型对故障进行检测,检测结果如表1所示.
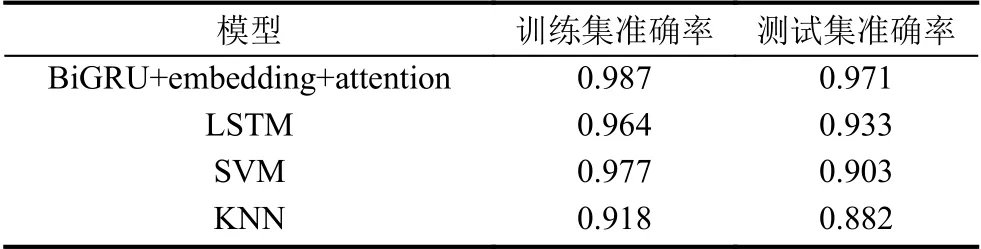
表1 不同模型准确率对比
综合来说,深度学习模型相比传统机器学习模型拥有更高的诊断准确率.SVM 作为经典的分类模型,其在训练集上表现出良好的效果,但是测试集上准确率显著下降,存在明显的过拟合现象.KNN 分类器因为没有显式的训练过程,在训练集和测试集上的诊断效果均较为一般,LSTM 在训练集和测试集上表现较为稳定,表明深度学习模型能够学习到数据中的时序变化信息.相比普通LSTM,加入了embedding 层和自注意力机制后BiGRU 模型准确度相比基线模型LSTM有2%的准确度的提升.实验结果显示深度学习模型能够在云数据中心进行部署,相比传统机器学习模型拥有更高的故障诊断准确率.除此之外,随着数据的积累,深度学习模型的准确率能够进一步提高.
4 结论与展望
为了解决当前云数据中心缺乏故障检测方法,且当前方法均基于仿真数据实验的问题,本文提出了一种基于Pytorch 和双向GRU 网络的云数据中心故障检测方法.GRU 模型的使用相比传统的LSTM 提高了训练速度,并且双向机制的结合进一步提高了模型的检测准确度.在对数据进行预处理后,利用embedding 技术使神经网络能够提取关于故障检测的相关特征,并使用特征进行进一步加工和处理,最后利用Adam 优化算法训练神经网络.基于阿里云集群数据的实验结果显示,相比于其他模型,本文提出的模型准确率有着明显改善,有助于智能电网云数据中心故障检测的准确率,可靠性的全面提升.
