基于神经网络的EAST密度极限破裂预测①
2020-11-24陈俊杰胡文慧肖建元郭笔豪肖炳甲
陈俊杰,胡文慧,肖建元,郭笔豪,肖炳甲,
1(中国科学技术大学 物理学院 工程与应用物理系,合肥 230026)
2(中国科学院 合肥物质科学研究院 等离子体物理研究所,合肥 230031)
1 引言
托卡马克磁约束聚变装置是实现热核聚变最具有前景的手段.EAST (Experimental Advanced Superconducting Tokamak) 核聚变装置是我国自主要发的全超导托卡马克[1].托卡马克装置放电时由于磁流体不稳定性、约束性能下降和储能快速损失会导致等离子体电流瞬间熄灭,即破裂(disruption)[2-4].等离子体破裂会对装置造成严重损害,限制可达到的运行参数.目前EAST主要的破裂避免和缓解系统是大量气体注入(Massive Gas Injection,MGI)、散弹弹丸注入.EAST 的MGI 系统从响应到气体到达破裂区的时间大约10 ms[5].而破裂预测是破裂避免和缓解的前提,因此对破裂进行预测尤为重要.
实验中已观察到多种破裂类型,如锁模破裂、垂直位移破裂、密度极限破裂等.等离子体密度是托卡马克装置3 大运行极限之一[3],高密度运行有利于达到聚变点火条件且是实现聚变的必要条件,如国际热核聚变实验堆(ITER) 将以0.85nGW(nGW为Greenwald密度极限[6]) 的高密度作为基本的运行模式[7],然而给定一个等离子体电流,密度存在安全运行极限值,当超过这个密度上限后.就会发生密度极限破裂(density limit disruption)[6,8-10].EAST 的运行参数都较接近下一代托卡马克,如ITER、中国聚变工程实验堆(CFTER),EAST 的密度极限破裂炮占所有的破裂炮的16.3%(972 炮),因此,EAST 密度极限破裂预测的研究对于下一代聚变装置的稳定运行具有重要意义.
通常,等离子体破裂分为3 个阶段:先兆阶段(1 ms~100 ms)、热猝灭阶段(~0.1 ms)、电流猝灭阶段(~10 ms),这3 个阶段的时间与装置尺寸有关,且有的破裂没有先兆或先兆时间极短[6,11].此外,破裂是一个非常复杂的非线性物理过程,其物理机制复杂,破裂原因、种类、先兆繁多,这些原因通常不是单一而是相互耦合在一起的,所以仅依靠先兆活动或者物理理论模型的研究远达不到预测的目的[12].
因此,在各大装置上进行了数据驱动的机器学习模型进行预测的探索,Cannas 等[13]在2004年利用MLP 对JET 装置进行破裂预测,成功预测率达85%;同样是Cannas 等[14]利用自组织映射(SOM)对JET 装置提取出破裂炮中属于非破裂阶段的样本,再利用MLP 进行训练;Ratta 等[15]在2013年利用遗传算法对诊断信号进行特征提取;文献[16,17]利用SVM 对JET进行破裂预测,成功预测率达82%;马瑞等[18]利用MLP 对HL-2A 进行破裂预测,但是使用的标签是0 或者1,不能很好地反映破裂发生的情况;Cannas 等[19]利用SOM 和MLP 对ASDEX 装置进行不区分种类的预测,成功预测率为80%;文献[20,21]利用随机森林对Alcator C-MOD、DIII-D 以及EAST 进行破裂预测的研究和对比,对EAST 的破裂炮成功预测率为91%;以上破裂预测的研究都是不区分某种破裂类型的,也就是只把放电炮分为破裂炮和非破裂炮,而不区分破裂种类.谭胜均等[22]利用双变量分析方法对EAST 垂直位移不稳定破裂进行破裂预测的研究,其中垂直位移破裂炮仅有2016年内72 炮.Sengupta 等[8]利用MLP对ADITY 装置的密度极限值进行预测,但训练集仅12 炮放电.王绅阳等[9]对J-TEXT 装置用MLP 进行密度极限值的预测,在提前5 ms 预测的前提下成功预测率为80%;胡斐然等[10]利用MLP 对J-TEXT 进行密度极限破裂的预测,受文献[13]启发,使用的输出是在破裂前的固定时间内才开始上升的Sigmoid 函数,最终在至少提前30 ms 触发预警的前提下成功预测率为90%,错误预测率为10%.但目前没有关于EAST 密度极限破裂预测的研究.
基于以上,本文首次对EAST 密度极限破裂进行离线预测算法的研究,离线算法是实时在线预测的前提.除MLP,LSTM[23-26]也被用于预测器的构建,LSTM专用于时间序列数据的处理,被广泛的应用于自然语言处理领域,而EAST 每次放电的数据是长时脉冲,属于典型的时序数据.
文章组织如下:第1 节介绍密度极限破裂预测的意义以及目前的研究现状;第2 节简要的介绍密度极限破裂、数据库的建立;第3 节阐述诊断信号的选择和数据预处理;第4 节介绍模型的大致原理,数据集的划分、模型输出以及评价指标;第5 节介绍相关结果;第6 节总结.
2 EAST 密度极限破裂及数据库的建立
2.1 EAST 密度极限破裂
根据劳森判据,为了达到聚变点火条件,等离子体温度、密度以及能量约束时间的乘积需要达到一定值[3,6],然而给定一个等离子体电流,密度存在最大的安全运行值,当超过这个密度上限后.就会发生密度极限破裂.
密度极限破裂的物理机制尚不明确[6],经过长期的实验研究与数据统计,目前有多种计算密度极限的定标关系,最广泛认同的是Greenwald 定标律[6]:

其中,nGW是Greenwald 密度极限,IP为等离子体电流,a为等离子体半径.但这些定标率是经验定理,所以,仅仅依靠这些定标律无法做出有效的预测.
Zheng 等[7]对EAST 密度极限运行做了详尽研究.EAST 通过持续的较强甚至正常充气就可能实现高密度极限放电.EAST 的密度极限与Greenwald 定标率吻合.这为密度极限破裂数据库的筛选提供了重要的指导意义.
图1是典型的密度极限破裂炮,1.7 s 后电流进入平顶段,而电子密度持续增加,在7.2 s 时开始出现不稳定性先兆,密度达到0.8nGW,直到7.954 s 时发生密度极限破裂.破裂时刻td的数值被定义为:等离子体电流一阶导数最大值出现的时刻[9,13].
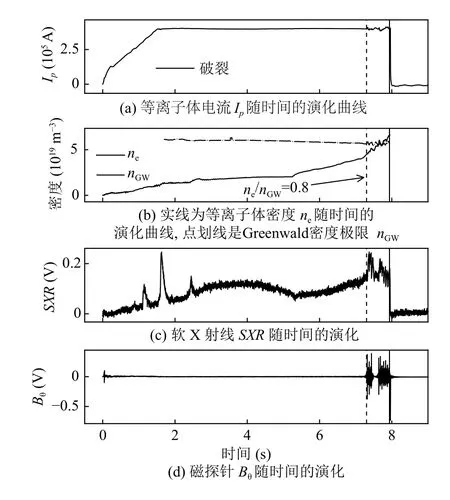
图1 典型密度极限破裂炮(#67039)
2.2 数据库的建立
本文根据Greenwald 定标率建立EAST 密度极限破裂数据库,分为3 步:
(1) 首先区分出破裂炮和非破裂炮.这主要依赖于诊断信号It,It为等离子体控制系统(PCS)[27]中的预设电流值,对于非破裂炮,It有爬升、平顶段、下降阶段,而对于破裂炮,It只有爬升和平顶段;
(2) 其次是从破裂炮中区分出密度极限破裂炮.筛选标准是根据实际密度和Greenwald 密度极限的比值ne/nGW是否大于0.8;
(3) 最后剔除缺失了对预测任务重要的诊断信号的放电炮.
根据以上3 步,设计自动筛选程序,最终筛选出EAST 聚变装置2014年到2019年、炮号分布在45 000~88 299 之间的972 炮平顶段破裂的密度极限破裂炮.
3 特征选择及数据预处理
3.1 特征选择
EAST 装置有上百种诊断信号,选出最能表征破裂的诊断信号对于破裂预测任务至关重要,一方面:过多的信号会造成过大的计算量,另一方面:过少的诊断信号不能很好地表征破裂.本文选取了电子密度(ne)、等离子体电流(IP)、磁扰动(Bθ)、环电压(Vloop)、软X 射线(S XR)、极向比压(βP)、q95安 全因子(q95)、内感(li)、边缘辐射(Pedge)、中心辐射(Pcore)、垂直位移(DV)、快控线圈电流(IC)、韧致辐射(Pbrem) 这13 种诊断信号作为神经网络的输入,这些信号在相关的研究中也被采用.选取这些信号考虑了考虑物理机制、兼顾信号的实时可测性、等离子的全局测量参数.4.3 节将对这些信号的有效性做出敏感度分析.
3.2 数据预处理
由于这13 种诊断信号的原始采样率不一致,因此本文对原始信号进行插值重采样,且重采样时间间隔为1 ms (破裂3 个阶段的时间尺度).
此外,不同诊断系统的诊断信号的数量级相差很大,这巨大差异会导致神经网络权值的差异不是反映模型输入的相对重要性而是反映数量级的差异,且会降低神经网络的训练速度,因此还需对各信号做归一化:

其中,Mj、mj分别为所有训练炮中第j种诊断信号的最大最小值[14,19].为了更具有实时性,需要用此最值对验证集,测试集归一化[19].
4 MLP 和LSTM 模型简介与预测原理
4.1 模型简介
人工神经网络(ANN)源自生物学上神经系统,其最重要的功能是实现复杂的、多维度的非线性映射.采用不同的数学模型就会得到不同的神经网络方法.其中最为经典的是MLP[8-10,13],一般由输入层、隐藏层、输出层组成,它的输入是一个个样本点,且认为每个样本点是独立的.
循环神经网络(RNN)是用来处理序列数据的神经网络,它克服了传统MLP 对序列数据处理的低效,RNN相当于多个MLP 横向连接,相邻MLP 之间的隐藏层之间全连接,使得信息不仅可以向下一层传递信号,而且可以向相邻MLP 传递信号[23,24].作为一种特殊的循环神经网络,LSTM 通过输入门、输出门、遗忘门不仅克服了RNN 梯度消失和爆炸的问题,而且还可以保持网络的长期记忆状态,其误差反向传播由通过时间的反向传播算法(BTPP)来解决.LSTM 有多种形式,考虑到计算量以及输入输出在时间上的相关性,本文采用many-to-many 形式,其具体结构如图2所示.
LeakRelu 激活函数[26]相比于其他激活函数具有收敛速度快、解决梯度消失问题、缓解过拟合等优点因而近年来受到广泛的关注,本文的隐藏层采用LeakRelu激活函数,输出层采用Sigmoid 函数,优化算法为Nadam[26].
本文中LSTM 的时间步选为100,LSTM 和MLP的输入层和输出层神经元个数分别为13、1,而隐藏层层数和每层神经元个数通过经过网格搜索[26]的方法试验了30 个模型,发现网络结构(13:200:200:1) 的结构相对较好,为了便于比较,因此MLP 和LSTM 都采用这一结构.
图2中的重复单元的数学原理如下:
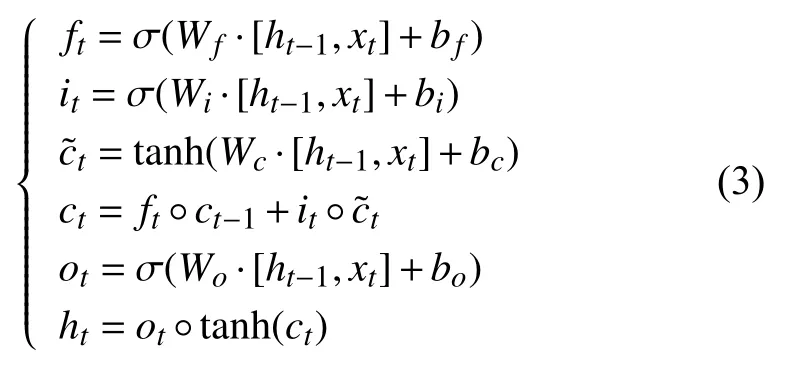
其中,ft、it、ot分别为遗忘门、输入门、输出门,xt为时间步t时刻的输入,σ、tanh 分别为Sigmoid、tanh激活函数,W为权重矩阵,◦代表向量间按元素点乘,为当前输入的当前状态,ct为当前时刻的输入状态,ht为在第t步的输出.
4.2 模型输出与评价指标
本文训练集包括密度极限破裂炮和非破裂炮,在每个时刻,神经网络的输入为一个具有13 个特征的样本.数据集的划分如表1所示.

表1 数据集的划分
模型训练时,对于每炮密度极限破裂炮,本文选取时间窗口[tflat,td]内的样本点作为输入,其中tflat为平顶段开始时刻,td为破裂时刻;对于非破裂炮,采样点所在的时间窗口为[tflat,tfe],tfe为平顶段结束时刻.至于模型训练时的输出,文献[8,9]以每炮的密度极限最大值为输出,但这种方法存在缺陷[10].文献[18]以0 或1为输出,但这样不能反映破裂的概率大小,本文中:
(1) 对于密度极限破裂炮,文献[10,13]中使用的输出是在破裂前的固定时刻才开始上升的Sigmoid,本文使用的Sigmoid 开始上升时刻并不是在破裂前的固定时间而是取决于实际密度达到0.5 倍Greenwald 密度极限的时刻,如图3所示.
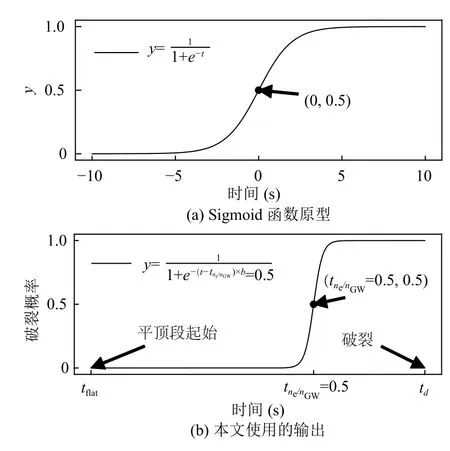
图3 训练神经网络时密度极限破裂炮的输出

其中,tne/nGW=0.5为 实际密度ne达到0.5 倍的Greenwald密度极限的时刻,b为缩放因子(无量纲),最终定为25.
(2) 对于非破裂炮,训练时的输出恒为0,即认为破裂的概率为0.
预测器的最终目的是能对即将发生破裂的放电炮在破裂前发出预警,本质上是一个时序样本的分类问题,但神经网络在实际使用时对于每炮放电的输出都是一个取值范围为0 到1 之间的时间序列,因此在使用模型时需要选取一个阈值(th,0 ≤th≤1).一旦模型的输出第一次等于或者超过这个阈值(可能为0 到1 之间的任何值),就会触发破裂预警,此时刻记为tpred.为了对模型进行客观评价,根据相关研究[9,10,13,14,28],定义如下概念、数量、指标:
对于每炮放电脉冲,预测结果可以分为以下:
(1)若为密度极限破裂炮(正例):
① 成功预测(successful alarm):预测器至少在破裂发生前 Δtalarmms 触发预警,即tpred∈[tflat,td−Δtalarm],该炮在机器学习中称为“真正例(True Positive)”,其中Δtalarm为预警时间临界值;
② 遗漏预测(missed alarm):在破裂前Δtalarmms 内触发预警,即tpred∈[tflat−Δtalarm,td],此时破裂缓解系统没有足够的时间避免或者缓解破裂.或模型在破裂前始终没有触发预警.该炮在机器学习中称为“假反例(false negative)”.
(2)若为非破裂炮(反例):
错误预测(false alarm):如果模型在任意时刻触发预警,则此非破裂炮被判定为密度极限破裂炮,因此为错误预警.也称为“假正例(False Positive)”.
将密度极限破裂炮总数记为Ndisr,非破裂炮总数记为Nnondisr,成功预测炮的总数记为Nsucc,遗漏预测炮的总数记为Nmiss,Ndisr=Nsucc+Nmiss;错误预测炮的总数为Nfalse.模型性能指标为:
(1) 成功预测率(Rsucc):被成功预测的密度极限破裂炮总数占密度极限破裂炮总数的比例,Rsucc=Nsucc/Ndisr;
(2) 遗漏预测率(Rmiss):被遗漏预测的密度极限破裂炮总数占密度极限破裂炮总数的比例,Rmiss=Nmiss/Ndisr;
(3) 错误预测率(Rfalse):被错误预测的非破裂炮总数占非破裂炮总数的比例,Rfalse=Nfalse/Nnondisr.
(4) 平均预警时间(Talarm):被成功预测的密度极限破裂炮的预警提前时间(td−tpred)的平均值.
本文采用ROC(Receiver Operation Characteristic)曲线面积,即AUC(Area Under ROC Curve)值作为阈值的选择标准,AUC值越大说明模型的分类性能越好[23,26].ROC曲线的横轴为假正例率FPR=FP/(FP+TN),纵轴为真正例率TPR=TP/(TP+FN),其中TP、FP、FN、TN定义如表2所示.可知,FPR=Rfalse,而TRP=Rsucc,每个Δtalarm都对应一个最佳阈值th∗:
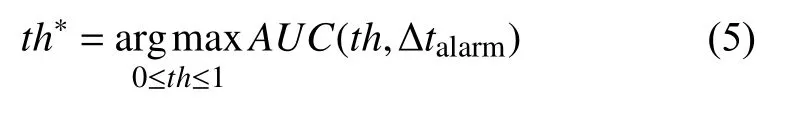

表2 混淆矩阵
4.3 诊断信号敏感度的分析
本文采取“留一法”对诊断信号的敏感度进行分析,具体如下:每次移除一种诊断信号,将剩余的12 种诊断信号作为特征输入模型并在相同的训练集上进行训练,接着在相同的测试集上进行测试.同时,计算模型实际输出和理论输出间的均方误差,误差越大,说明破裂预测对此诊断越敏感越,即此诊断信号越重要.最终的计算结果如图4,可以看出,等离子体电流(IP)和密度(ne)是最重要的诊断信号,环电压(Vloop)是反映等离子体运行的基本参量,软X 射线(SXR)反映电子温度,而中心辐射(Pcore)、边缘辐射(Pedge)、韧致辐射(Pbrem)都是重要的辐射信号.

图4 留一法对诊断信号的敏感度分析结果
5 实验与结果分析
5.1 收敛性及运算实时性
图5是模型训练过程中模型损失的变化,LSTM和MLP 在训练集上的损失均是逐渐减小然后趋于稳定,在验证集上损失整体也是呈现逐渐减小直至在一定范围内波动,且LSTM 的损失波动较小.
至于实时性,在测试过程中,LSTM 和MLP 预测每个输入样本所需时间分别为0.000 654 ms、0.010 815 ms,均小于样本之间的间隔时间(1 ms),且测试过程中使用的是Python 程序,实际部署时会将模型转换为C 语言,运算速度更快,更易满足实时预测需求.

图5 实验过程中LSTM 和MLP 的损失变化
5.2 结果与性能分析
为了全面衡量模型的性能,本文将Δtalarm以20 ms为间隔依次取[20 ms,200 ms]中的10 个值,分别评估LSTM 和MLP 的性能,结果如图6所示,可以看出,在不同 Δtalarm下LSTM 的成功预测率都高于MLP,而错误预测率都低于MLP,因此,LSTM 对密度极限破裂测预测性能明显优于MLP.
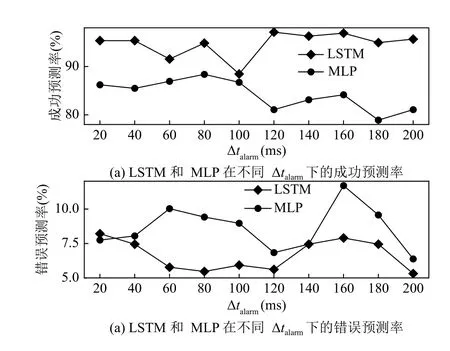
图6 成功和错误预测率比较
接下来令Δtalarm=20 ms来分析成功预测率、错误预测率随阈值的变化,以LSTM 为例,如图7(a)所示,灰色区域的阈值为 0.67 ≤th≤0.78,此区间的成功预测率Rsucc≥0.9 且 错误预测率Rfalse≤0.1,从图7(b)(c) 可以看出,当阈值为0.73 时,AUC值达到最大0.948,平均预警时间为2.142 s.同理,对于MLP,当Δtalarm=20 ms时,MLP 的最佳阈值为0.73,此时AUC值为0.899.
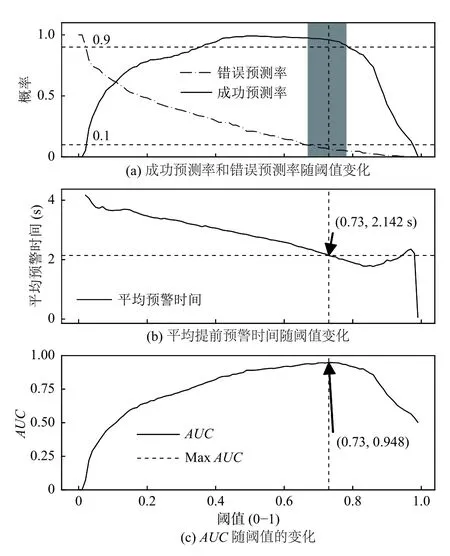
图7 Δtalarm=20 ms 时,LSTM 各项评价指标随阈值的变化
MLP 和LSTM 总体预测结果如表3所示.从中可以看出,LSTM 和MLP 在所有数据上对密度极限破裂炮的正确预测率分别为95.37%和86.21%,对于非破裂炮的错误预测率分别为8.21%和7.75%.
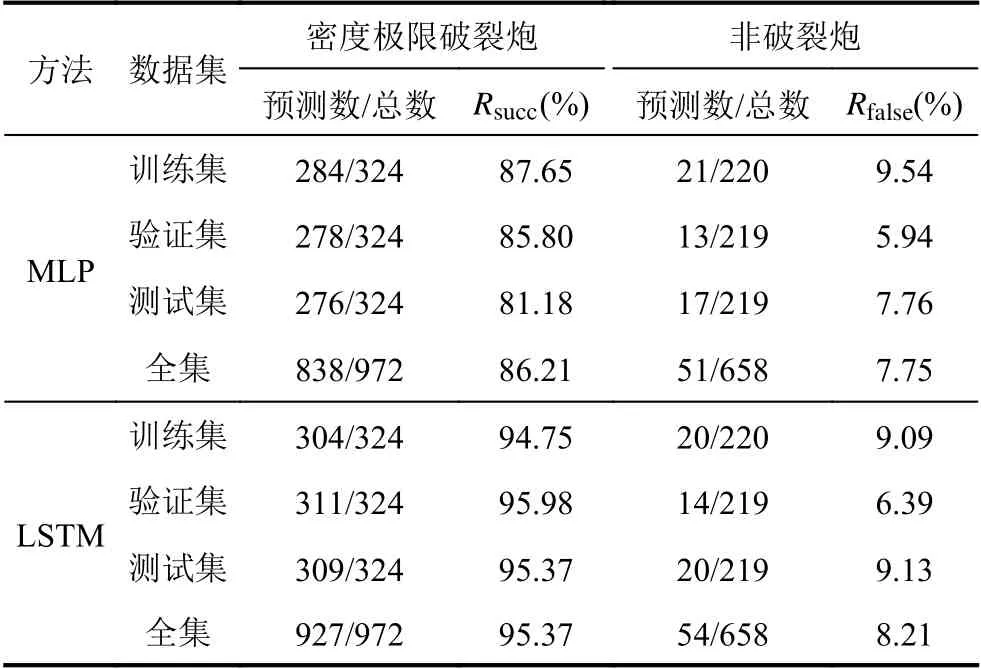
表3 Δtalarm=20 ms时,LSTM 和MLP 的预测结果
图8展示的是#66972 炮密度极限破裂炮的预测结果.可以看出,该炮在td=3.948 s 发生破裂,MLP 的输出在3.931 s 时超过阈值,提前17 ms 触发预警,导致破裂缓解系统没有足够的时间采取措施,因此为“遗漏预测”;LSTM 在3.588 s 触发预警,提前360 ms 触发预警,被LSTM 成功预测.
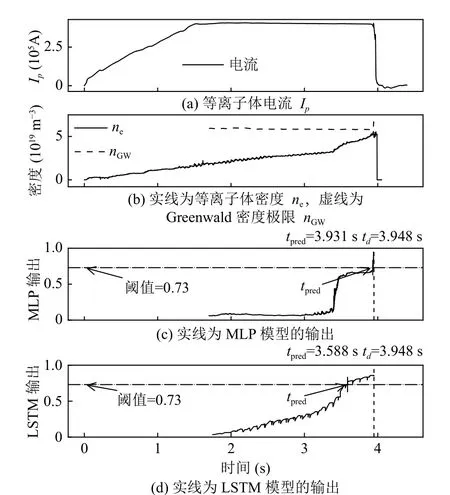
图8 #66972 炮密度极限破裂炮的预测结果
图9展示的是#69104 炮密度极限破裂炮的预测结果.可以看出,该炮在td=6.84 s 发生破裂,MLP 的输出始终没有超过阈值,导致没有触发破裂缓解系统,因此为“遗漏预测”;LSTM 在6.38 s 触发预警,提前460 ms触发预警,被LSTM 成功预测.
图10展示的是被LSTM 和MLP 成功预测的密度极限破裂炮的提前预警时间(tpred−td)分布图,可以看出LSTM 的提前预警时间柱较MLP 的明显紧密,经过计算,LSTM 和MLP 平均提前预警时间分别为2.21 s和2.47 s,等离子体控制系统有足够的时间采取措施缓解破裂带来的危害.
6 总结
高密度运行对于未来的装置具有重要意义,本文首次针对EAST 采用神经网络进行密度极限破裂预测研究.首先建立了EAST 密度极限破裂数据库,其次将MLP 和LSTM 分别建立离线模型,模型输出为更具实际意义的考虑了实际密度和Greenwald 密度极限相对大小的Sigmoid 函数,最后离线测试结果表明,对于密度极限破裂炮,在至少提前20 ms 触发预警的前提下,LSTM 和MLP 对密度极限破裂炮的成功预测率分别为95.37%和86.21%,对于非破裂炮的错误预测率分别为8.21%和7.75%.本研究说明利用神经网络建立密度极限破裂离线预测算法的可行性,下一步研究计划是在EAST 托卡马克上实现破裂预警的实时在线计算.
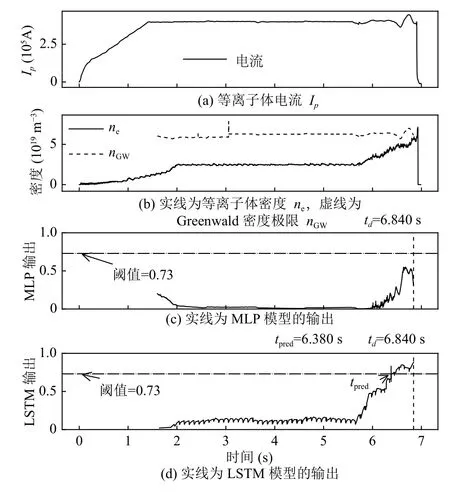
图9 #69104 炮密度极限破裂炮的预测结果
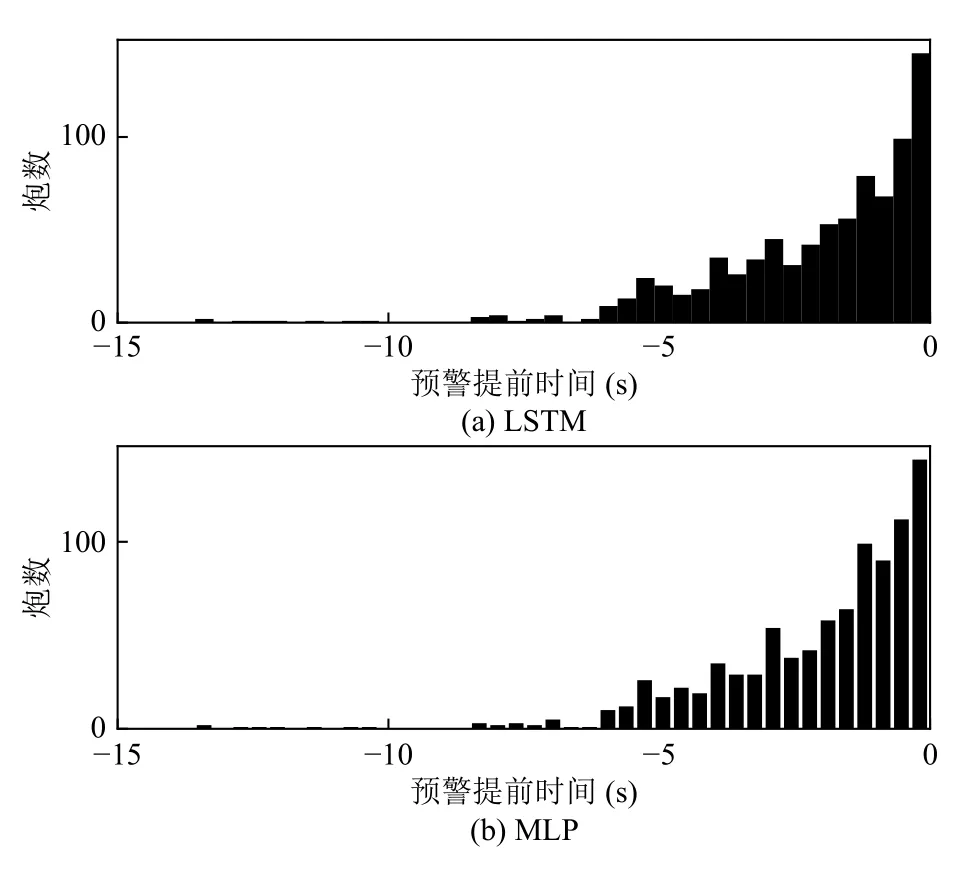
图10 被LSTM 和MLP 正确预测的密度极限破裂炮的预警提前时间(t pred−td)的分布柱状图.
