车辆碰撞事件与碰撞损伤的检测方法①
2020-11-24张鲁江
张鲁江
(滨州学院 信息工程学院,滨州 256600)
当今世界每天都有大量的交通事故发生[1],其中碰撞事故占交通事故总量的90%左右[2].当碰撞事故发生时,如果车辆能够自动发出报警,则有助于降低事故的死亡率,这种技术称为车辆紧急呼叫(Automatic Crash Notification)系统,调查表明该技术能有效的降低车祸的死亡率[3,4].因为如果急救部门能够在第一时间收到报警信息,则可以迅速出动进行抢救,从而避免因延误造成的死亡.实现车辆自动报警的前提是车辆碰撞的自动检测,这种技术对于社会上的一些行业也很有价值.例如,保险公司为车险业务推出了双免服务,但骗保导致的理赔风险增大,因此希望能够自动检验车辆事故的真伪,而出租车公司和物流公司等拥有大量车辆的企业需要实时监控车辆的运行状况.
车辆碰撞的自动检测可分为两大类:一类是碰撞的预警检测,也就是预测行驶中的车辆可能发生的碰撞[5-7],从而提前发出警告;另一类是碰撞事件的检测[8],也就是碰撞发生后的实时检测.本文的研究属于后者.目前此类研究多集中于车辆被动式安全系统的碰撞检测,文献[8]综述了该领域常用的碰撞检测算法,由于主要应用于安全气囊等被动式防护系统的碰撞触发,必须在极短的时间内完成碰撞的识别,以便给防护系统的点火启动留下足够的时间,因此只能进行简单的计算,如速度和加速度的变化率、位移和变形、信号的能量与功率等.当计算结果超过某个阈值时,则认为发生碰撞,经验公式的色彩浓厚.而且只能判断是否发生碰撞,而无法判断车辆的损伤程度.
本文提出了一种基于机器学习的车辆碰撞检测方法.该方法用于车辆的远程监控,而非车辆被动式安全系统.不但能检测碰撞是否发生,还能同时检测车辆的损伤程度.由于使用机器学习方法[9]对车辆的信号进行分析,因此具有更好的适应性.
1 技术原理与处理流程
1.1 技术原理
车辆碰撞时产生的信号明显异于正常行驶状态下信号[10].图1是车辆的加速度信号曲线图,其中脉冲部分是车辆发生碰撞时的信号,而相对平坦的部分则是正常行驶时的信号,由图中可以看出,两类信号的区别比较明显.检测碰撞事件就是从采集到的信号中识别出碰撞信号,但是碰撞类型不同,碰撞信号也会有所变化.图1(a)和图1(b)分别是不同碰撞场景下产生的信号,具有明显的差异.简单的计算难以将各类碰撞信号都识别出来,应当使用机器学习算法进行分类.
系统实时的采集速度和加速度信号.X 方向的加速度信号和Y 方向的加速度信号分别采集,X 方向是车辆行驶的方向,Y 方向是与车辆行驶方向垂直的方向.速度信号不考虑方向,只考虑大小.采集信号时,将时间划分为均匀的段,每一段是一个采样窗口,窗口尺寸根据经验值设定.每采集满一个窗口,就分析判断该窗口内的信号是正常信号还是碰撞信号.
如果是碰撞信号,则进一步判断车辆的损伤程度.直接判断整车的损伤程度比较困难,而判断车辆各部件的损伤程度则相对容易.此外,要获得关于车辆损伤的完整信息,需要知道各部件的损伤程度.车辆发生时碰撞时,冲击力会作用至各个部件,对不同的部件造成不同程度的损伤,判断部件的损伤程度本质上是将冲击信号映射至部件损伤程度的过程.机器学习中的核方法具有强大的非线性映射能力,建立在核方法基础上的支持向量机具有出色的分类能力[11].先使用支持向量机判断各部件的损伤程度,然后将各部件的损伤程度作为支持向量机的输入特征,判断整车的损伤程度.
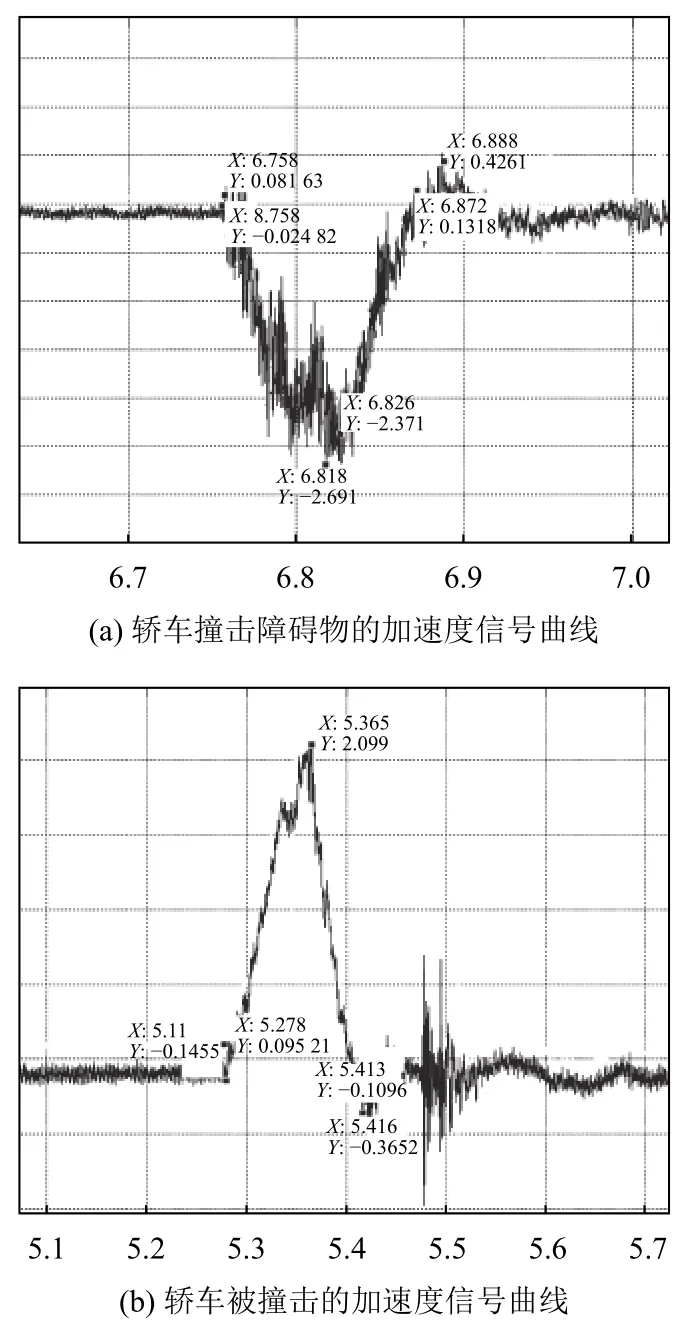
图1 轿车碰撞的横向加速度信号曲线
1.2 处理流程
如图2所示,在每辆汽车上安装一部前端设备,通过车载无线网络[12]和一个后台服务器相联.前端设备的处理流程如图3所示:实时的采集车辆的速度和加速度信号,每采集满一个窗口,就从信号中抽取特征,然后用简单的算法初步判断是否发生碰撞,将可能的碰撞信号发送给后台服务器.这相当于对所有信号先做个过滤,留下候选的碰撞信号.前端设备因为有实时性的要求,因此只能进行简单的计算,并且不对信号做滤波处理.

图2 系统架构示意图
后台服务器的处理流程如图4所示:接收前端设备发来的信号,对信号进行滤波并抽取特征,然后使用机器学习算法确认是否发生碰撞;如果发生则进一步判断各部件的损伤程度,并在此基础上判断整车的损伤程度.

图4 后台服务器的处理流程
2 检测方法
2.1 信号滤波
在碰撞的过程中,加速度的信号变化剧烈,包含了噪声成分(如图1所示),需要对加速度信号进行滤波,以便从中提取稳定的特征.在实验的基础上,确定使用切比雪夫I 型低通滤波器[13].速度信号不需要滤波,取窗口中的速度最大值作为特征.
2.2 特征抽取
从车辆的速度和加速度信号中提取两类特征,一类用于判断碰撞是否发生,另一类用于判断部件的损伤程度.X 方向的加速度信号和Y 方向的加速度信号各自提取一组相同的特征,然后合并成一个向量.在前端设备上提取特征不需要滤波,而在后台服务器上提取特征要先进行滤波.
设系统从t0时刻开始采集信号,ti时刻的采样信号为sti,i=0,1,2···,采样窗口尺寸为h,Δt=sti−sti−1为采样时间间隔.信号流 (st0,st1,st2,···)的第1 个采样窗口为w1=(st0,st1,···,sth−1),第k个采样窗口为wk=(st(k−1)h,st(k−1)h+1,···,stkh−1),k=1,2,···.
判断车辆碰撞所使用的特征用V表示,V=[Vx,Vy],是X 方向加速度信号的特征,是Y 方向加速度信号的特征.具体包括:加速度绝对值的最大值加速度最大值与最小值的差值加速度的平均能量加速度曲线上各点斜率的绝对值的平均值
判断各零件损伤程度所使用的特征用U表示,是X 方向的加速度信号的特征,是Y 方向的加速度信号的特征.具体包括:速度值(u0)、加速度绝对值的最大值加速度最大值和最小值的差值加速度最大值到最小值之间的平均能量加速度最大值到最小值的连线的斜率绝对值加速度最大值到最小值的横坐标距离加速度曲线上各点斜率的绝对值的平均值加速度信号离散傅里叶变换的0 到38 频谱的各频率幅值
不失一般性,设X 方向加速度信号的当前采样窗口为wx=(st1,st2,···,sth),则X 方向的特征计算公式为:

各特征的量纲或取值范围不同,需要进行归一化处理,使用Z-score 方法,归一化后各特征的取值范围均为[-1,+1]
2.3 机器学习算法与训练数据
在前端设备初步判断车辆是否发生碰撞,对实时性要求比较高,因此使用计算简单的逻辑回归[14].将碰撞信号错分为非碰撞信号的代价要远高于把非碰撞信号错分为碰撞信号的代价,在前端设备宁愿将非碰撞信号误分为碰撞信号,而在后台服务器准确判别时排除掉,也不愿将碰撞信号误分为非碰撞信号,从而造成碰撞事件的漏报.这属于代价敏感学习问题,在使用逻辑回归分类器时,可以通过提高碰撞类别的样本权重,而降低非碰撞类别的样本权重来加以解决[15].由于希望碰撞信号的查全率尽可能高,因此还需要调低逻辑回归的分类阈值,以便尽量不遗漏碰撞信号.
在后台服务器判断接收到的信号是否为碰撞信号,不存在迫切的实时性要求,而对准确率的要求更高,因此使用支持向量机对碰撞信号进行分类.判断各部件的损伤程度同样使用支持向量机,这是个非线性分类问题,借助核方法将信号从输入空间映射到高维的特征空间,从而提高该问题的线性可分性.将各部件的损伤程度作为支持向量机的输入特征,可以判断出整车的损伤程度.不管是仿真碰撞还是实车碰撞,想获得足够多的碰撞样例来训练深度神经网络,在时间、成本以及计算力上都是很困难的,因此没有使用目前流行的深度学习[16],而选择非常适合于中小样本的支持向量机.
训练数据包括正常信号(非碰撞样例) 和碰撞信号(碰撞样例).每个碰撞样例都由专业鉴定师判定各部件的损伤程度和整车的损伤程度.汽车上的部件很多,只考虑对车辆损伤起重要作用的部件.部件的损伤程度分为4 级,分别是1、2、3、4 级.从1 级到4 级损伤程度逐级加重,1 级表示没有损伤,4 级表示损伤严重.整车的损伤级别与部件的相同,也是分为4 级.
给每个样例标上1 或0 的标签,1 表示碰撞样例,0 表示非碰撞样例,并标注各个部件的损伤级别和整车的损伤级别.然后从每个样例中都抽取用于判断碰撞是否发生的特征和用于判断部件损伤程度的特征.判断部件的损伤程度时,需要为每个部件单独训练一个分类器,训练每个分类器都要复用所有的碰撞样例,根据对某个部件造成的损伤级别,将每个样例归为4 类之一,如图5所示.
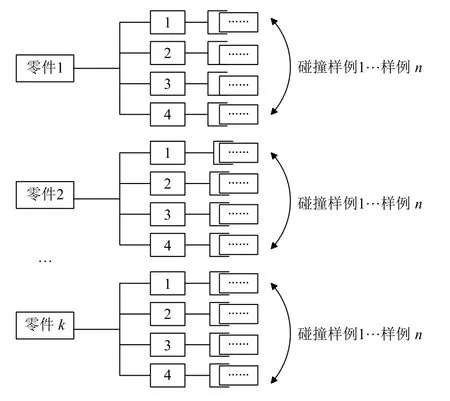
图5 判断部件损伤程度的训练样例复用示意图
将一个碰撞样例造成的各个部件的损伤级别作为支持向量机的输入特征,可以判断这个碰撞样例对整车造成损伤程度.由于部件的损伤级别是有序的离散值,因此需要先使用Z-score 方法进行归一化处理.
3 实验分析
实验数据来自实车的碰撞实验.在实验中,选择了有限方形刚性壁、防护栏、防撞桶、柱状体、路缘石这5 种典型的碰撞物构建5 种测试工况.每种工况生成160 个实验样例,其中80 个为非碰撞样例,80 个为碰撞样例.在训练时,使用k-折交叉验证调优超参数,k的值取4.
3.1 在前端设备检测碰撞信号
在前端设备把碰撞信号误分为非碰撞信号的代价要高于把非碰撞信号误分为碰撞信号的代价,因此要尽量做到不遗漏碰撞信号.这属于代价敏感学习问题,可以通过调整类别权重来解决,在使用逻辑回归分类时,将碰撞类别的权重设为0.6,而非碰撞类别的权重设为0.4.同时,为了提高碰撞信号的查全率,将分类阈值降低为0.4.将每种工况的实验样例按照3:1 的比例分裂为训练样例和测试样例,将所有的训练样例合在一起组成训练集,而各个工况的测试样例单独组成测试集,以便观察各个工况的测试结果.
测试结果如表1所示,提供碰撞类别的查全率和查准率两个性能指标.从表中可以看出,碰撞类别的查全率在4 个工况上达到100%,查准率也都超过了90%.由于碰撞信号和非碰撞信号的区别明显,因此即使逻辑回归这种简单的分类器也能以较高的准确率进行区分.
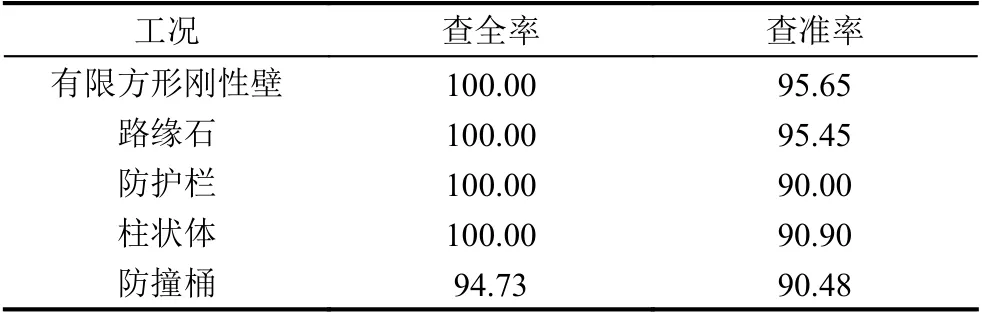
表1 在前端设备检测碰撞信号的测试结果(%)
3.2 在后台服务器对接收到的信号进行确认
当前端设备检测出可能的碰撞信号后,将信号发送给后台服务器,使用准确率更高的支持向量机判断该信号是否是碰撞信号.后台服务器使用的训练数据和前端设备的训练数据相同,而将前端设备在测试过程中发送给后台服务器的信号作为测试数据.实验结果如表2所示,多数工况达到了100%的准确率.由于实验数据有限,这并不意味着分类器具有100%的泛化性能,有待使用更多的实验数据进行测试.

表2 在后台服务器确认碰撞信号的测试结果(%)
3.3 在后台服务器判断车辆各部件的损伤程度
当后台服务器确认发生碰撞后,接下来判断各部件的损伤程度.将各个工况的碰撞样例合在一起,按照3:1 的比例分裂为训练集和测试集,然后按照2.3 节所述的方式(见图5)为各个部件组织训练集,为每个部件训练一个支持向量机分类器.总共有100 个测试样例,其中每个测试样例都要分别用每个部件的分类器测试一下.测试结果如表3所示,大多数部件的准确率较高,少数部件的准确率低于80%.从测试结果来看,对于部件损伤程度的判断还有待改进提高.
3.4 在后台服务器判断整车的损伤程度
当判断出车辆各部件的损伤程度后,接下来使用支持向量机判断整车的损伤程度.训练集与3.3 节的相同,而测试数据则由3.3 节的100 个测试样例的输出结果构成,也就是将每个碰撞样例造成的各部件的损伤级别作为输入特征.测试结果如表4所示,分类准确率不高.由于将3.3 节的测试结果作为输入特征,因此3.3 节的分类错误会影响本阶段的分类准确率.但测试结果表明该方法是有效的,远高于随机猜测的准确率.

表3 在后台服务器判断各部件损伤程度的测试结果(%)

表4 后台服务器判断整车损伤程度的测试结果(%)
4 结束语
提出了一种基于机器学习技术的碰撞检测方法,用于车辆的远程监控,可以实时的检测车辆的碰撞事件.以往的碰撞检测算法多用于车辆被动安全系统的触发,难以用于车辆的在线监控,且只能检测碰撞是否发生.本文提出的方法除了能检测碰撞是否发生,还能检测车辆的损伤程度,从而提供更全面的信息.从实验结果来看,该方法对于碰撞事件的检测达到了较高的准确率,对于碰撞损伤的检测也是有效的.
