基于卷积神经网络的动作识别骨架特征研究
2020-11-20仇思宇仇德成赵国营
仇思宇 仇德成 赵国营
(1.武汉数字工程研究所,湖北 武汉 430200;2.河西学院信息技术与传媒学院,甘肃 张掖 734000;3.中国人民解放军32738部队信息服务室,河南 郑州 450053)
1 绪论
动作识别在计算机视觉中有重要的作用,并具有广泛的应用,例如人机交互,视频监视,机器人技术,游戏控制等[1,2].通常,人体可以看作是具有刚性骨骼和铰接关节的关节系统,而人体的动作可以表示为骨骼的运动[3].目前,基于低成本的深度传感器与实时骨架估计算法[4,5],可以提供相对可靠的关节坐标,基于这些坐标,已经开发出有效的动作识别方法[3,6,7].
2 研究背景
姿势随时间的动态变化可以建模为时间序列问题,这对于连续的动作识别至关重要[8-10].骨骼关节坐标可用于表示人类的姿势及其关于时间的演变.基于手工提取骨架特征[3,11,12]的方法具有依赖算法设计者对骨架和人体骨骼构造的先验知识的缺点,且在不同数据集中可能会使模型表现出不同的泛化性能,而基于深度学习技术的方法则可以弥补上述缺点.当前,主要有两种使用深度学习技术来捕获骨架序列中的时空信息的方法:循环神经网络(RNN)和卷积神经网络(CNN).
2.1 卷积神经网络
卷积神经网络直接从骨架序列编码的纹理图像中提取信息. Wang P 等的文章中使用关节轨迹图(JTM)将每个时间实例的身体联合轨迹(位置、运动方向和运动幅度)编码为HSV图像[13].Hou Y等的文章提出在图像中空间信息由位置表示、动态信息由颜色表示[14].Li C等的文章采用骨架光学光谱(SOS)来编码动态时空信息[15],采用关节距离作为空间特征,并使用颜色条进行颜色编码.在图像中,每一行纹理捕获空间信息,而每一列纹理捕获时间信息.当前,用于编码的空间特征相对简单.
2.2 循环神经网络
循环神经网络又称递归神经网络,采用循环神经网络来从提取的空间骨架特征中捕获时间信息.由于信息的顺序流动,性能很大程度上取决于提取的空间骨架特征的有效性.而且,时间信息很容易过分强调,尤其是在训练数据不足时,容易导致过拟合[13].
3 特征选择
本文使用的方法如图1所示,包括五个主要组成部分,即从输入骨架序列中提取空间特征,关键特征选择,从关键特征中进行纹理彩色图像编码,卷积神经网络模块预训练以及分数融合的神经网络训练.
从关节时空位置提取出来的特征有多种,通过选择特定的关节组合提取特征并进行颜色编码,可以产生多种纹理图像.卷积神经网络会分别在每种图像上进行训练,训练后的卷积网络作为特征提取模块放置在网络的前端.由两层全连接层组成的分数融合模块作为网络的后端,以完成最终的动作识别.

图1 多特征动作识别模型整体结构
3.1 特征提取
本节研究的空间特征包括在Yang X和Tian YL的文章中介绍的绝对关节位置J 和相对关节位置Jr,以及在Zhang S等人的文章中介绍的关节-关节距离JJd 、关节-关节向量JJv 、关节-关节方向JJo 、关节-线距离JLd 和线-线角LLa[16-18],实验中使用J 、Jr、JJo、JLd 和LLa 作为姿态序列每一帧的特征.


通过选择关键关节和关键线的方式可以减少组合数量来进行特征选择.关键关节和关键线的选择遵循以下原则:所选特征应包含尽可能多的信息,并且对于视点和动作是不变的.基于运动主要位于骨架末端且通常是局部特征才具有识别力的观点[17],我们采用Zhang S等人的方法从主要动作执行者中选择39条线,得到612维JLd 特征和741维LLa 特征.
Li C等作者的文章中,彩色纹理图像被用来编码空间特征以捕获动作的时间信息[15].具体而言,图像中的每一列代表一帧中的空间特征,而每一行代表特定特征的序列.给定具有T 帧的骨架序列,为每帧提取S 维特征,形成的S×T 的特征矩阵编码为H×W 大小的彩色纹理图像以作为网络的输入.
3.2 网络结构设定
卷积模块由多个卷积层和池化层顺序组合而成.为防止过拟合,正则化和dropout等方法被应用在神经网络中.
3.3 多特征模块的分数融合
本文采用如图2所示的网络结构作为卷积模块.给定一个测试骨架序列,将生成M 种类型的纹理图像,并使用训练后的模型识别每种类型的纹理图像.然后,通过乘法将卷积模块的输出(分数)融合为最终分数,这已得到了验证[19,20].融合过程如下:
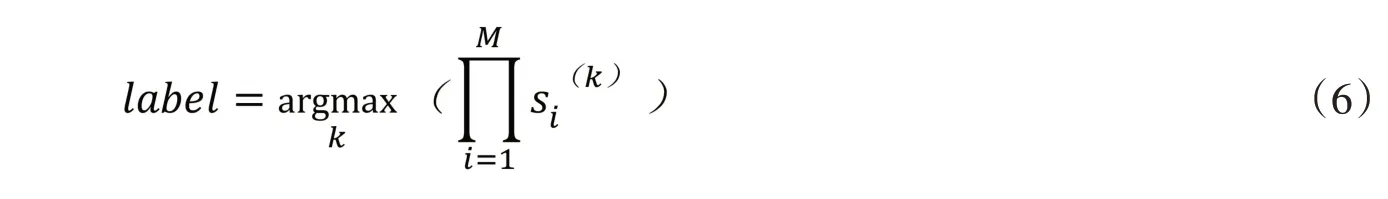
其中s 是卷积模块输出的分数向量,k 则代表动作标签的序号,而arg max(·)是用于找到最大元素的对应序号的函数.
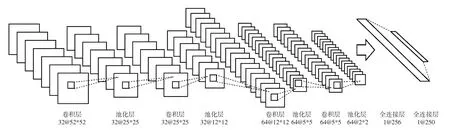
图2 预处理模块网络结构
4 实验与评估
该模型在MSR Action3D 数据集上进行了评估.该数据集包含用于动作识别的深度点云和关节位置信息.它具有20 个不同动作类别的560 个有效样本,这些样本是由20 位动作执行者执行(每组执行3次).此数据集具有挑战性,且数据量较小,因此不额外划分验证集,直接采用测试集作为验证集.实验采用跨目标的方法评估模型的准确性:即将50%的动作执行者的样本划分为测试集,剩余50%的动作执行者的样本划分为测试集.

表1 模型训练参数
4.1 数据集与测试方法
实验环境是Google公司为深度学习研究者免费提供的Colaboratory服务器.该服务器配备了Tesla T4 GPU,16GB显存,16GB的内存.实验模型在此环境下平均每批数据仅需计算353毫秒.训练中使用的模型训练参数见表1.

图3 同一样本不同特征的图像编码结果

表2 特征提取方法的精确度

表3 不同模型精确度对比
4.2 模型测试结果
由图3所展示的不同动作的样本生成的纹理图像中可以得出,实验所选特征是具有辨别力的.
表2列出了各个特征提取方法进行试验后的结果,以及分数融合的结果.评估的五个特征,对每个特征都使用不同的关节、线的选择方法进行了评估.从表2中可以看出,基于单个结果和融合结果的比较,JJv 特征是最好的关节-关节特征.而JLd 是五种特征中最好的特征,这与Zhang S等人的结果相吻合.实验结果表明,对于此任务,某些关节存在噪音.其他不同模型精确度对比结果在表3中,与基于手工特征的方法和基于深度学习的某些方法相比,本文所提出的方法精确度为81.31%,获得了较好的结果.
