基于OpenCL 的Salsa20 算法实现与优化*
2020-11-20
(中国电子科技集团公司第三十研究所,四川 成都 610041)
0 引言
当前环境中,随着通信技术的快速发展,网络带来快捷性的同时,也伴随着出现了诸多信息安全隐患,使得人们对隐私和信息保护越来越重视。在传输层采用基于流加密算法的Salsa20 可以有效阻止信息泄露[1],防止通信关系被暴露,成为保障用户信息隐秘传输的有力手段。
在物联网的世界,日常设备之间信息相互交换十分频繁,使其非常容易受到安全攻击。而基于Salsa20 的流密码算法采用轮函数迭代的设计结构,利用AES 中的行移位和列混合思想,具有较少的参数、较小的内存占用空间和较少的执行周期,在资源受限的设备上性能良好,可以设计用于物联网中资源受限的设备,能够实施其当前无法提供的安全服务,以保护用户的数据隐私并保护系统免受攻击。
Salsa20 算法作为入选eSTREAM 计划的序列密码加密算法,对其进行研究具有重大意义。Salsa20旨在提供非常快速的软件加密性能,即使与AES 相比也不会影响安全性[2-3]。
OpenCL 全称Open Computing Language,是一个面向异构平台并行编程框架标准,被广泛应用于密码分析系统。OpenCL 的优势是使程序员能够控制所有功能系统中的各个可用处理单元[4]。OpenCL用于编写跨异构平台执行的程序的框架。其中,该异构平台由中央处理单元、图形处理单元、数字信号处理器、现场可编程门阵列和其他组件组成处理器或硬件加速器[5]。通过将流密码算法Salsa20 在OpenCL 中实现,可以获得加速,并且可以有效提高算法执行速度。
本篇文章结构如下:第1 节介绍了Salsa 算法和基于OpenCL 的高性能计算平台;第2 节分析密码算法原理;第3 节测试和评估方法;第4 节展望未来的工作。
1 Salsa20 算法和OpenCL 介绍
1.1 Salsa20 算法简介
流密码因为安全性高和加密速度快等优点,非常适合在网络加密数据传输和受限资源场合应用。Salsa20 密码长度可灵活变化,且具有运算速度快等优点,被Shadowsocks 推荐使用。它基于addrotate-XOR(ARX)操作-32 位加法,按位加法和旋转操作的伪随机函数构建。核心功能将256 位密钥、64 位随机数和64 位计数器映射到密钥流的512 位块。密钥分为128 bit 和256 bit 两种类型。Salsa20 算法首先对密钥进行扩展。如图1 所示,扩展所用的quarterround 函数用数学公式表示为:


图1 Salsa20 中QuarterRound 函数
Salsa20 算法的初始状态是由16 个字节构成的一个×4 矩阵,其中包括8 个密钥k0,k1,k2,…,k7、4个常数σ0、σ1、σ2、σ3、2 个初始IV 值n0、n1、2 个时间标号c0、c1。假设用X表示初始状态,则X为:

将初始状态X经过10 轮变换后的输出与X进行模223加,得到密钥流后,对明文分组进行异或操作便可得到密文数据,操作流程如图2 所示。

图2 Salsa20 加密原理
1.2 OpenCL
OpenCL 所支持的平台可由多核CPU、GPU 或其他类型的处理器组成。OpenCL 主要由两部分组成,一是用于编写内核程序(在OpenCL 设备上运行的代码)的语言,二是定义并控制平台的API。图3 中的设备可以被看成是CPU/GPU,而设备中的计算单元可以被看成是CPU/GPU 的核。计算单元的所有处理节点作为SIMD 单元或SPMD 单元(每个处理节点维护自己的程序计数器)执行单个指令流[6]。抽象的平台模型更与当前的GPU 的架构接近。
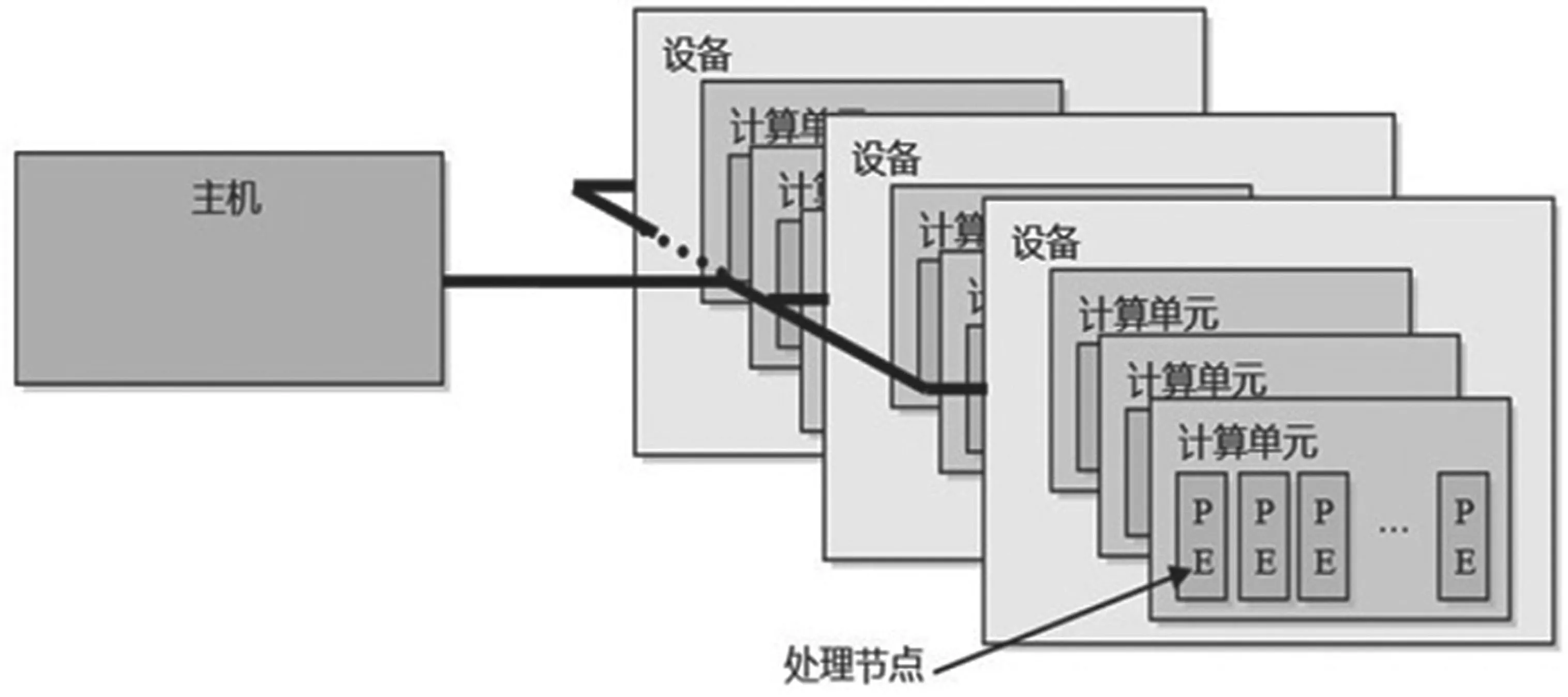
图3 OpenCL 模型
OpenCL 程序由主机程序(Host Program)和内核程序(Kernel)组成。主机程序为Kernel 定义了上下文并管理Kernel 代码的执行,Kernel 则在支持OpenCL 的计算设备(Compute Device)如GPU 上执行具体的计算任务。平台可被认为是不同厂商提供的API 的实现。一个平台选定后,一般只能运行该平台所支持的设备。一般而言,A 公司的平台选定后不能与B 公司的平台进行通信。
OpenCL 的本地内存是片上内存,使得它非常快。访问共享内存通常需要4~6 个周期。但是,共享内存非常小,通常为16 kB,因此必须用于存储经常用于计算和更新的数据。共享内存可以由工作组的所有工作项访问,因此可以用于同一工作组的工作项之间的通信。此功能非常适合在需要在工作项之间共享数据情况。
另一个有用的内存空间是常量缓存(只读内存),通常为64 kB,位于芯片上。当工作组中有多个线程尝试读取相同的常量缓存地址空间时,它只占用一个事务,否则会对不同地址的读取进行序列化。该内存空间用于通过缓存常用数据来加快读取的速度。类似的缓存也可以使用纹理缓存,以加快图像读取速度对象。
专用内存(寄存器)是最快的内存,由SM 私密地分配到工作组的工作项。每个多处理器的内存总量受到限制,介于8 192 和16 384 个32 位寄存器(32~64 kB)之间,并划分为多个线程。如果工作组需要更多的寄存器,则会出现性能问题,称为“寄存器压力”。寄存器是存储需要频繁使用的少量数据的最佳解决方案。
2 破解算法
2.1 基于OpenCL 的密码算法实现
根据Salsa20 加密算法原理,设计基于OpenCL的密码实现,具体密码算法流程如图4 所示。

图4 算法实现流程
将Salsa20 代码分为两部分:第一部分是创建块密钥流的加密过程;第二部分是密钥流与原始数据的实际混合(通过使用XOR)。加密算法将原始消息切分成相等的块,通过按位操作应用于函数来确定大小并进行计算。
在设计Salsa20 算法内核时,还需要注意每个工作项注意如下参数。
(1)字节偏移量,表示包含到现在共处理了多少字节的信息。
(2)块大小,表示根据每个工作项负责多少字节消息而创建适当大小的密钥流。
(3)传输到GPU 的总字节数,如果块大小未完全划分总工作量,则最后一个工作项将需要产生一个较小的密钥流。
(4)块号,当工作项要计算块号时,必须首先计算它在所有工作组的所有工作项中的位置,然后考虑块大小,并通过添加块偏移量来计算块编号。
(5)随机数,字节偏移量和块大小在全局内存中传递,并由所有工作项使用。工作组的所有工作项都可以从同一内存地址读取随机数。基于先前对其他加密算法的研究,发现该算法的最佳块大小相对较小,为1 024 Byte,选择通过寄存器而不是共享内存来处理数据,以获得更好的性能。经过实验,以16 Byte(128 位)的块的形式写入全局存储器性能最佳。
2.2 密码算法内存优化
OpenCL 体系结构中有几个不同的内存空间。不同存储空间的位置描述如图5 所示。GPU 体系结构的主要最大内存是片外全局内存,高端GPU 通常介于128 MB 到几GB 之间。访问全局内存需要400~600 个周期,使得在访问全局内存时必须谨慎。所有工作组的所有工作项可以访问全局内存。全局内存区域按顺序保留用作常量的只读存储器,称为常量存储器。

图5 OpenCL 中内存分布
Salsa20 算法内核参数需要确定最佳的块大小。所谓“块大小”,是指分配给每个工作项的数据量。大的块不会导致私有内存问题,因为密钥流是在固定大小(64 Byte)的块中生成,然后写入全局内存,且使用同一私有内存生成下一个密钥流块。但是,由于生成的密钥流的数据量大,块大会导致全局内存问题,所以需要尝试不同的块大小,并找到此方法的最佳选择。最佳块大小还取决于硬件,因此在获取GPU 设备有关工作组中最大工作项数的信息后,必须在运行时确定它。因此,对于不同的GPU,该值可能会有所不同,但变化不大。假设GPU 设备支持共X个并行线程,并且将块大小确定为Y(这是可以并行执行的数据大小)。为了隐藏延迟,需要在GPU 上传递此大小的多个Z。XYZ即它们的乘积必须小于支持的GPU 内存总量,否则编译器将出现错误。
由于寄存器资源被占用直到内核完成才释放变量,可见导致了资源浪费。因此,本文进行了重复使用寄存器优化操作,以减少浪费。寄存器重用分配了两个完全不同的地方,在不影响正确性的情况下对一个变量表示含义。它损害了程序的可读性,但节省了寄存器使用,并带来了性能的提升。
根据程序性能对不同数量的工作组进行自动化评估,是寻找工作组最优数量的有效手段。工作组数量越多,该程序执行速度会越快,因为内核启动耗时同步会随着工作组编号的增加而增加。但同时每个内核的执行时间将变长,且需要中间结果等待更长的时间,所以这个数字不应该太大。
3 实验结果与分析
本文对上述算法进行测试,测试平台和实验结果如表1 和表2 所示。
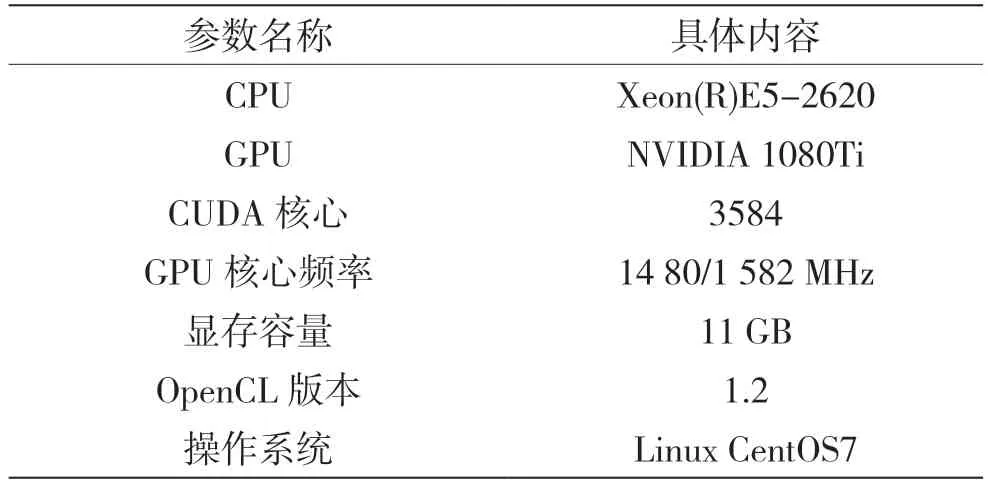
表1 实验环境

表2 GPU 吞吐率对比
实验中,将算法加密的字符串大小限制为1 MB。结果表明,基于GPU 平台的OpenCL 算法实现速度达到11.5 Gb/s,相较于优化前提高了2 倍多。
对不同大小的算法加密字符串在GPU 平台上进行测试,结果如图6 所示。从图6 可以看出,字符串越大,算法的吞吐率越高。

图6 不同大小字符串在GPU 平台速度优化前后速度
4 结语
随着数据保护需求的快速提升,利用高性能异构系统并行计算进行算法实现已成为当今研究热点。为研究这一问题,利用OpenCL 的异构多核的体系架构和Salsa20 轻量化算法,提出了一种基于OpenCL 的Salsa20 加密算法实现方法。实验表明,根据不同内存访问速度和容量差异性优化方法,明显提升了算法吞吐率性能,表明了算法优化的可行性。下一步工将在异构系统协同方面开展进一步优化。
