基于Retinex-UNet算法的低照度图像增强
2020-11-18刘佳敏尹晓杰
刘佳敏,何 宁,尹晓杰
北京联合大学 智慧城市学院,北京100101
1 引言
部分图像增强在计算机断层成像、工业产品质量检验、交通监控及卫星图像处理中有着广泛的应用。其中低照度图像是一种常见的图像种类,它的主要特点是微光、暗色区域占图像主要部分。造成图像低照度的原因有很多,例如光线不足,摄影设备性能有限以及设备配置不正确等,这类图像可见性偏低,不便于观察与分析,且会对相关应用产生负面影响,尤其是在图像的匹配、融合、分析、检测以及分割方面,给数字图像处理带来极大挑战。
当前国内外对于低照度图像增强技术的相关研究还在不断探索中,虽然取得了一定的成果,但还远未达到成熟,该领域仍具有很大的研究价值和发展空间。经研究,针对低照度图像增强的研究方法大致可分为传统方法与深度学习两类。
传统方法中,基于Retinex 理论[1-4]主要在频域中增强图像,基于直方图均衡化等算法[5-6]则集中于增强图像对比度,但黑暗区域的细节没有得到适当的增强[7]。Dong等人[8]发现,低亮度图像与反转后的图像相似。同样,Lin 等人[9]和Zhang 等人[10]利用暗通道先验[11]来增强低照度图像。尽管如此,这些方法仍缺乏理论依据。除此之外,Ying 等人[12-13]提出一种用于低照度图像增强的多重曝光融合框架,根据权重矩阵融合输入图像和合成图像来获得增强的结果。Guo 等人[14]也提出利用图像反射图进行图像增强,其增强的关键是对反射图的估计程度。但这种基于反射图的方法容易造成过度增强,这是现有照明图估计最常出现的问题。如今,过度曝光问题仍未得到有效解决。
近年来,研究者们相继提出了一些基于深度学习的方法。Lore 等人[15]提出了一种基于深度自动编码器的方法,该方法可从低照度图像中识别信号特征并自适应地增亮图像,并且不会过度放大饱和高动态范围图像中的较亮部分,但并未考虑低照度图像的性质。Chen等人[16]和Loh 等人[17]分别构建短曝光低光图像及相应长曝光图像数据集(SID,ExDARK),并搭建网络来学习图像增强,但是结果仅在构建的数据集上表现良好。受Retinex方法的启发,Wei等人[18]和Guo等人[19]分别提出Retinex-Net网络和基于卷积神经网络(Convolutional Neural Network,CNN)与离散小波变换(Discrete Wavelet Transform,DWT)的LLIE网络对图像进行端对端训练,其中文献[18]验证了图像分解在一定程度上可以增强图像亮度。Cheng等人[20]提出的深度融合网络(Deep Fusion Network,DFN)无需估计反射图,而是使用CNN 生成置信度图作为空间权重因子,以融合多种基础图像增强技术相互补充增强图像。Bhat 等人[21]提出了一种实时的低光照增强算法,并通过伽玛校正合成训练数据,该算法计算复杂度较低,实时性较高,能保留图像更多细节。
Retinex理论典型的假设是图像可分解为反射图和照明图,但此假设缺乏理论基础。在此基础上本文设计了一种数据驱动的深层网络来学习图像分解和增强,该网络旨在调整图像亮度,增强图像整体效果。
2 网络架构(RUNet)设计
Retinex 理论假设照明在空间上逐渐变化,但这种假设与实际存在一定偏差,并且MSRCR默认图像的三个通道所占比例均等,这样造成处理后的图像偏暗并带噪声,因此本文设计了一个集成图像分解与增强的神经网络架构RUNet 来解决上述问题。该网络包括两个子网络:图像分解(DeNet),图像增强(EnNet)。DeNet 网络通过卷积神经网络(CNN)学习并分解图像,并将其结果作为亮度增强网络EnNet的输入,对输入图像进行端对端训练,即可对任意大小的图像进行增强。
Retinex分解图像的方法是直接在输入图像上估计反射率和照度,但设计适合各种场景的适当约束函数并不容易。因此,尝试以数据驱动的方式解决此问题。DeNet每次都会获取成对的弱光/正常光图像,并在弱光和正常光图像的指导下学习弱光及其对应的正常光图像的分解。
在增强子网EnNet 中,为了分级地调整照明,即保证局部照明和全局照明的一致性,引入了多尺度级联,设计了一个全卷积网络(Fully Convolutional Network,FCN),并结合U-Net网络来实现图像增强。
2.1 DeNet
在DeNet 子网中,RUNet 通过DeNet 将输入图像分解为反射图R 和亮度图I 。尽管此分解可能与Retinex的图像分解相似,但本质上是不同的。在处理过程中,不需要准确获取实际图像就可以很好地调节图像亮度。本文为子网设置了两个约束:一是低光与正常光图像共享反射率;二是保证反射图平滑但保留主要结构。在此约束下,DeNet学会了以数据驱动的方式提取各种照明图像之间的共享反射率。
由图1 可知,DeNet 将低光图像Slow与正常光图像Snormal作为输入,然后分别进行分解。首先使用3×3 卷积层从输入图像中提取特征,然后使用以整流线性单元(ReLU)为激活函数的5个3×3卷积层将RGB图像映射到反射率和照明度,最后使用一个3×3卷积层从特征空间投影出R 和I 。其中所有层使用卷积核大小(3×3)与通道数(64)不变,使用Sigmoid函数目的在于将R 和I 约束在[0,1]范围内。

图1 RUNet网络架构
损失函数L 由重建损失Lrecon、不变反射率损失Lir和平滑度损失Lis三项组成,其中λir、λis分别表示反射率一致性和照明平滑度的系数:

基于Rlow和Rhigh都可以使用对应照明图重建图像的假设,重建损失Lrecon可表示为:
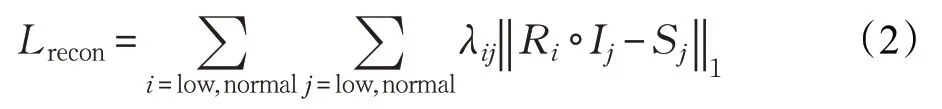
引入共享反射率损失Lir来限制反射率的一致性:

2.2 EnNet
EnNet将反射图R 和亮度图I 作为输入,并将其连接后进入网络层,其中卷积层卷积核大小为3,池化层卷积核大小为2。为结合U-Net 思想,本文利用最近邻插值法增大图像,并进行上采样,保证与相结合特征图大小一致,将其对应加和,之后进行特征融合,得到细节保存更完整的特征图,最后使用随机梯度下降对网络进行端到端微调,得到增强后的图像。
全变分(Total Variation)最小化,就是最小化图像梯度,通常在进行图像恢复任务之前用作平滑度处理。在图像处理中最直接和最有效的应用莫过于图像去噪和复原,但是在图像像素均匀或亮度急剧变化的区域,直接使用TV作为损失函数会失败。为使损失了解图像结构,本文使用反射率图的梯度对原始TV 函数进行加权,得出Lis公式为:

其中,∇包括水平方向∇h和垂直方向∇v的梯度,λg表示平衡结构感知强度的系数。在权重exp(-λg∇Ri)的情况下,Lis放宽了对反射率梯度较陡的平滑度的约束,即放宽了在图像结构所在的位置以及照明应不连续的位置平滑度的约束。
3 实验
3.1 数据集
本文采用公开的SID 数据集[16],包含5 094 个原始的短曝光图像序列,每个图像序列都有对应的长曝光参考图像。选取每个图像序列中曝光时间最短的图像作为低照度图像,同时选取该图像对应的长曝光图像作为参考图像。SID 数据集中的图像分别由富士和索尼相机拍摄,由于相机设置不同,将原图格式由RAW格式转换成JPG 格式,由此得出图像对324 对,每个图像对大小一致,分辨率为600×400,共648张图片。
为增强网络泛化能力,本文增加了合成图像数据集LOL[18]。该数据集包含1 485个图像对,每个图像对大小一致,包含600×400 和384×384 两种分辨率,共2 970 张图片。
本文将这两个数据集合并成一个泛化能力更强的数据集,用于网络训练和测试。该数据集有低、正常光图像对1 809对,共3 618张图片。数据集如图2所示。
3.2 训练
本文对1 759对图像进行训练,并对50幅图像进行了测试。
训练过程中无需提供反射率,只需将反射率一致性和照明图平滑度作为损失函数嵌入网络中即可。因此,本文的网络分解是从配对的低、正常光图像中自动学习获取的,并且自然而然地适合于描述不同光照条件下图像之间的光变化。
训练时,批处理大小设置为16,图像块大小设置为48×48。 Lir、Lis和λg分别设置为0.001、0.1 和10。当i ≠j 时,λij设置为0.001,当i=j 时,λij设置为1,网络整体迭代100次。
尽管分解是使用成对的数据进行训练的,但它可以在测试阶段对任意大小单图像进行测试。
3.3 图像分解与亮度增强
为了突出Retinex-UNet算法的优越性,本文将低光图像的分解及增强效果与正常光图像进行了对比,每张图像由原图反射图与亮度图的对应效果图组成。由图3可见,本文方法增强效果无限趋近于正常光图像。
3.4 测试
为了评估本文方法的性能,将其与几种最先进的方法进行了比较,包括Guo 等人[14]提出的LIME 算法,Dong 等人[8]提出的反转去雾算法,Ying 等人[12]提出的BIMEF 算法,以及Wei 等人[18]提出的Retinex-Net 算法,效果如图4所示。本文方法不仅能满足人的视觉需求,而且验证了此网络对图像增强的普适性。

图2 数据集图像对

图3 低/正常光图像分解、亮度增强效果对比

图4 低光图像增强效果图比较与细节展示
4 评估
4.1 时间复杂度
一个算法的优劣主要从算法的执行时间(计算量)和所需要占用的存储空间(访存量)两方面衡量,但时间复杂度的计算并不是计算程序具体运行的时间,而是算法执行语句的次数。
如果算法的执行时间不随着问题规模n 的增加而增长,即使算法中有上千条语句,其执行时间也不过是一个较大的常数。此类算法的时间复杂度是O(1)。当有若干个循环语句时,算法的时间复杂度是由嵌套层数最多的循环语句中最内层语句的频度f(n)决定的。除此之外,循环不仅与n 有关,还与执行循环所满足的判断条件有关。
而对于深度学习神经网络模型而言,时间复杂度决定了模型的训练/预测时间。如果复杂度过高,则会导致模型训练和预测耗费大量时间,既无法快速地验证想法和改善模型,也无法做到快速地预测。本文参考了文献[22]中模型指标——计算量。计算量指的是输入单个样本,模型进行一次完整的前向传播所发生的浮点运算个数,也即模型的时间复杂度,单位是Flops,其计算公式如下:

其中,D 为神经网络所具有的卷积层数,即网络的深度;l 表示神经网络第l 个卷积层;Cl为本卷积层具有的卷积核个数,也即输出通道数;Cl-1为输入通道数,即上一层的输出通道数;M 为每层卷积输出特征图的大小,由输入矩阵大小X、卷积核大小K、Padding、Stride 这4个参数所决定,表示如下:
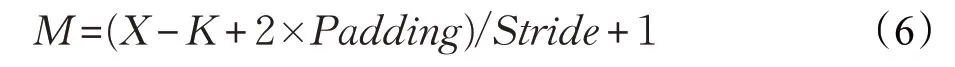
4.2 空间复杂度
空间复杂度是对一个算法在运行过程中临时占用存储空间大小的量度。在深度学习中,空间复杂度决定了模型的参数数量。模型的参数越多,训练模型所需的数据量就越大,而现实生活中的数据集通常不会太大,这会导致模型的训练容易过拟合。
空间复杂度(访存量)包含两部分,即总参数量和各层输出特征图大小,分别表示为式(7)中第一个和第二个求加公式,其参数表示与式(6)一致。其中总参数量是指模型所有带参数的层的权重参数总量,即模型体积。特征图是指模型在实时运行过程中每层所计算出的输出特征图大小。

为了定性地测量结果,本文方法与其他方法进行了对比,见图4。Dong等人[8]的方法使物体轮廓变黑,图像整体颜色很重。LIME[14]和BIMEF[12]色彩保持较好,轮廓清晰,但是物体被遮挡部分亮度没有得到有效增强。Retinex-Net(ReNet)[18]很好地解决了这一问题,但是该方法导致图像噪声过多,图像整体较模糊。本文方法在保存图像细节基础上,很好地避免了噪声扩大的问题,这得益于平滑损失函数的设计和去噪的操作。但在增强低照度图像区域的同时也增强了其他区域的图像,这与Relight网络输入有关,在实验过程中,将亮度图与反射图矩阵进行连接后作为亮度增强网络的输入,进而对图像的亮度进行了整体增强。
为了定量地测量结果,本文使用均方误差(MSE)、峰值信噪比(PSNR)和结构相似性指数(SSIM)[23]对图像质量进行评估。较低的MSE也通常意味着较高质量的图像,较高的SSIM 和PSNR 表示增强的图像更接近于真实情况,并利用测试时间(Test Time,以s 为单位)来表示不同算法平均测试一幅图像消耗的时间。如表1所示,本文方法同文献[18]算法一样,相较传统方法耗时更多,空间占比更大,这与算法的复杂度有关。
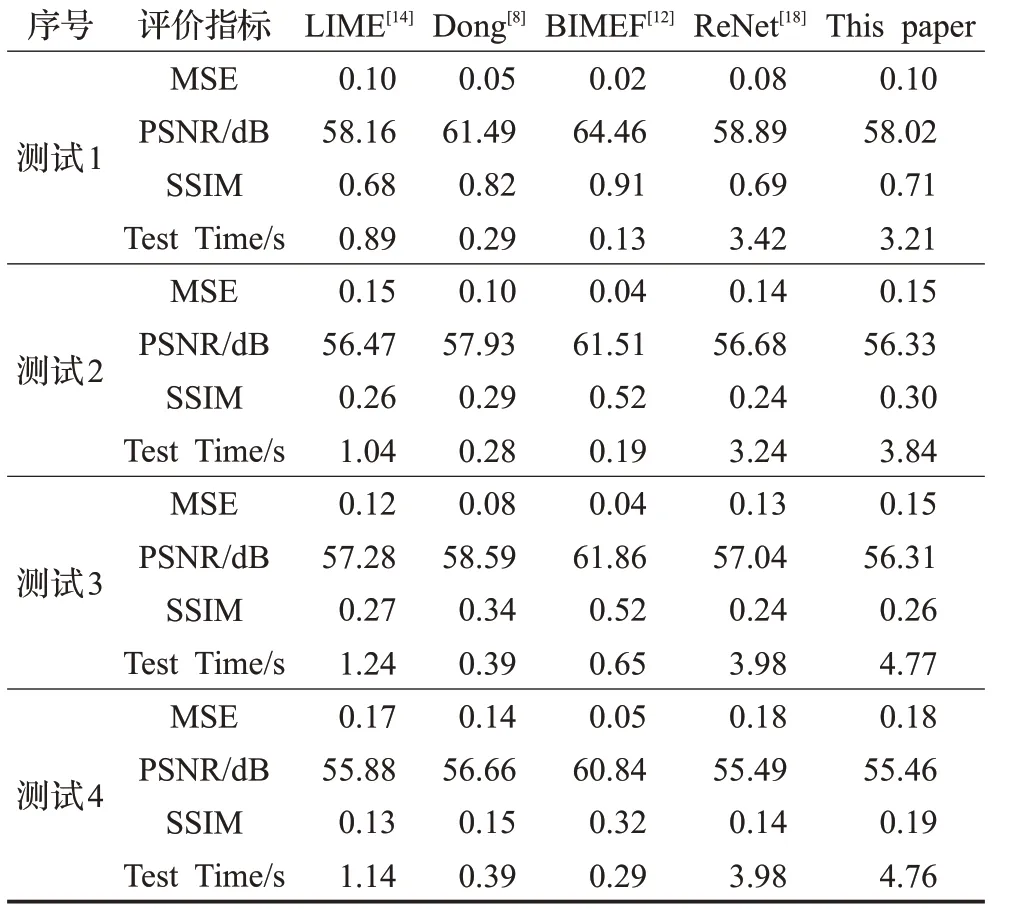
表1 测试图像对应MSE、PSNR、SSIM、Test Time对比
为进一步对比方法性能,对神经网络层数(Network Layers)、程序运行时间(Run Time,以s为单位)、时间复杂度(Time,以阶/计算量表示)、空间复杂度(Space,以Mb为单位)对传统方法与神经网络方法进行比较与分析。其中Run Time 分别指程序运行时间和网络训练时间,传统方法时间复杂度用阶表示,而深度学习方法用模型进行一次完整前向传播的网络计算量表示。空间复杂度Space用程序运行时所占用内存大小表示。如表2所示。

表2 算法复杂度对比
从表2中可以看出,更复杂的深度学习方法对算法质量、设备性能要求更高。
综上所述,本文方法增强图像效果优于Retinex-Net深度学习方法,与其他传统方法相比,图像主观效果均有所提升。从客观数据分析,本文方法虽在图像质量上有所提高,但还有进步空间。
5 结束语
受Retinex-Net实验启发,本文验证了利用神经网络分解图像能更精确地调整图像亮度,并提出了一种由连续的子网络组成的新型网络RUNet。该网络是在预测阶段没有任何人工参与的端对端神经网络,但在处理现实中的低照度图像时会添加噪声。本文分别从定性与定量的角度将RUNet与现有的最新方法进行了比较,实验表明,本文方法在其他方法基础上有所进步,不仅在合成图像中表现出色,而且在现实世界图像集中表现也很出色。
未来的研究方向是:(1)用泊松噪声和量化伪像进行训练以模拟更现实的情况;(2)增强去模糊能力以增加图像细节的清晰度;(3)将应用场景扩展到雾天和多尘等其他背景中;(4)对网络进行改进,避免在增强低照度部分时增强其他区域。
