效率为先:机器翻译译后编辑技术综述
2020-11-18孟福永唐旭日
孟福永,唐旭日
华中科技大学 外国语学院,武汉430074
1 引言
译后编辑是近年来随着机器翻译(Machine Translation,MT)研究不断发展而新兴的计算机应用研究领域。译后编辑(Post-Editing),是指根据一定的目的对机器翻译的原始产出进行加工与修改的过程,包括更改翻译(语言)错误,提高MT 译文的准确性与可读性等[1]。尽管将人与机器翻译结合起来完成翻译任务的研究可以追溯到20 世纪50 年代,但那时译后编辑工作在整个过程中微不足道,译后编辑人员甚至不需要掌握源语。直到20 世纪80 年代,译后编辑才逐渐成为翻译流程的重要组成部分。1994年Hans Krings完成了译后编辑的博士后研究报告,随后Geoffrey Koby 等把该报告译成英文,并于2001 年出版[2],这可能是译后编辑领域最早的一本专著。此后随着MT 技术与产品在翻译行业中的应用,越来越多的研究人员将目光投向了译后编辑。2010年Tatsumi分析研究了业界译后编辑人员在译后编辑过程中影响编辑数量的因素、源文特征、译后编辑行为、译后编辑工作量[3]。崔启亮在2014年引用行业数据说明,译后编辑正越来越受到翻译公司的重视[4]。在2017 年的《机器翻译市场报告》中,TUAS 认为,新的翻译模式,即“机器翻译+译后编辑”(MT+PE)模式有可能在未来5 年(即2022 年)内成为翻译行业首要的生产环境[5]。文献[6]也预测,在可见的未来,在机器翻译尚未完全具备可用性之前,“机器翻译+译后编辑”这种人机融合的翻译模式将维持较长一段时间。
与诸多计算机辅助技术一样,译后编辑技术研究的主要目的是提高翻译效率和质量,即在给定MT输出译文和译员水平的前提下,如何通过技术手段,提高译后编辑的速度和最终译文的质量。为此,自然语言处理领域的研究人员尝试将MT 领域的技术用于设计自动译后编辑系统,让机器进一步分担部分译后工作量;此外,译后编辑往往需要从多个MT 引擎给出的译文中挑选出最佳结果作为译后编辑的输入,因而涉及MT译文质量评估研究;研究者还需考察和分析译员的译后编辑过程,以找出影响译员工作效率的主要因素,为译后编辑系统环境的设计提供理论依据。
本文综合评述自动译后编辑、自动译文质量评估以及译后编辑人员工作效率这三个译后编辑研究中的主要技术问题,为进一步开展机器翻译译后编辑研究提供参考。
2 自动译后编辑
2.1 理据
自动译后编辑(Automatic Post Editing,APE)指应用机器学习等技术对MT译文进行自动编辑。事实上,大多数自动译后编辑系统使用的技术都来自MT 领域。那么,为什么还需要在MT 完成之后,增加一个自动译后编辑环节呢,这主要是基于以下考虑[7-8]:
(1)只有当完整的MT 译文给出后,才能对其进行质量评测或是文本分析,从而进行自动修改,而这些评测与分析是无法在MT引擎内部完成的。
(2)MT是从源语到目标语的映射,相同的输入会导致相同的输出。因此,一旦映射有误,MT系统就会重复输出有问题的译文。当MT是“黑箱”式引擎时1对MT引擎内部的工作原理一无所知,只能将源语文本输入后获得译文。尽管将具体的MT引擎相关信息纳入考量可能会提升APE系统的表现,但同时也会使APE系统与某个MT引擎“绑死”,不再适用于其他MT引擎。因此2.2节介绍的技术均假设MT系统是“黑箱”式的。,只能对MT输出的译文进行重复修改。这种重复劳动会让译员觉得很枯燥,适合由机器完成。
(3)APE 系统能够为译员提供更高质量的MT 译文,降低其工作量。
(4)通用MT引擎给出的译文在用词和风格上不一定适应具体任务需求,机器能够代替人工完成这种调整。
2.2 自动译后编辑技术
APE本质上与MT相同,都是文本间的映射。因此研究者们设计APE系统时使用的技术也随着MT技术的发展,经历了基于规则、基于短语、神经网络这三个阶段。
基于规则的系统采用针对具体语言现象的规则,因此能够较好地纠正相应的MT 错误。但实际的翻译场景复杂多变,光靠事先制定的规则很难覆盖所有的MT错误。而且每一种语言都需要独特的规则,要求的人工和时间成本太高。因此近年来APE 系统大多采用数据驱动的方法自动学习纠错规则。其基本思想是将MT译文作为源语文本,将在MT译文的基础上经人工编辑获得的文本作为目的文本,应用统计学习或是神经网络的方法训练模型。这种思想可以形式化地表述为:给定源语句子s 和相应的MT 译文t ,APE 系统尝试在所有可能的译后编辑译文集合C(e)中找到一个最优的译后编辑译文e,如下所示:

Simard 等人于2007 年率先提出这一思路,用当时流行于MT 领域的基于短语的方法来训练APE 系统[9]。但他们只利用了MT译文和人工编辑译文,未考虑源语文本的信息。Béchara等人在2011年采用对齐技术将源语文本和MT 译文中的字/词一一配对,共同作为APE系统的输入[10]。文献[7]对这两种方法进行了对比,发现后者即包括源语信息的方法性能稍优。
近年来,随着深度学习技术在自然语言处理中的广泛应用,许多研究者将其应用于译文自动后编辑,如使用双向递归神经网络编码器-解码器模型来训练自动译后编辑系统[11],以Transformer结构作为自动译后编辑系统的原型[12]等。最新一届的机器翻译研讨会(WMT19)APE 子任务中,绝大多数模型使用的都是Transformer结构,利用源语、MT译文、译后编辑译文、译员编辑行为等多种信息训练自动译后编辑系统[13],本届会议表现最好的Unbabel 系统则对预训练模型BERT(Bidirectional Encoder Representations from Transformers)稍加改造,使之适用于APE任务。
不管是早期基于短语的方法,还是近年流行的神经网络,自动译后编辑系统的训练都是在受控环境下进行的,也就是说训练数据的来源、内容都是统一的。这种数据的有限性使其只能反映部分MT 错误。但在真实场景中自动译后编辑系统可能要接受来自于不同MT引擎,不同文本类型的输入,受控训练学习到的纠错规则不一定适用所有场景,有时反而会降低MT译文的质量。为了更好地适应现实场景,研究者们尝试将在线学习与自动译后编辑结合起来,实现译员与自动译后编辑系统的互动。流程如图1所示[13-14]。
图1 中,MT 系统将源语文本自动翻译成目标语译文,自动译后编辑系统接受源语文本和相应译文作为输入,输出其预测的经过编辑的译文,交给译后编辑人员进行最后的编辑。当译员编辑完一段文本后,译员的编辑操作会与相应的原文和MT 译文一起被添加进译后编辑行为数据库。数据库更新后,自动译后编辑系统也需要基于更新后的数据库进行训练与更新,更新后的自动译后编辑系统接着处理下一段MT 译文。具体的流程描述如下:
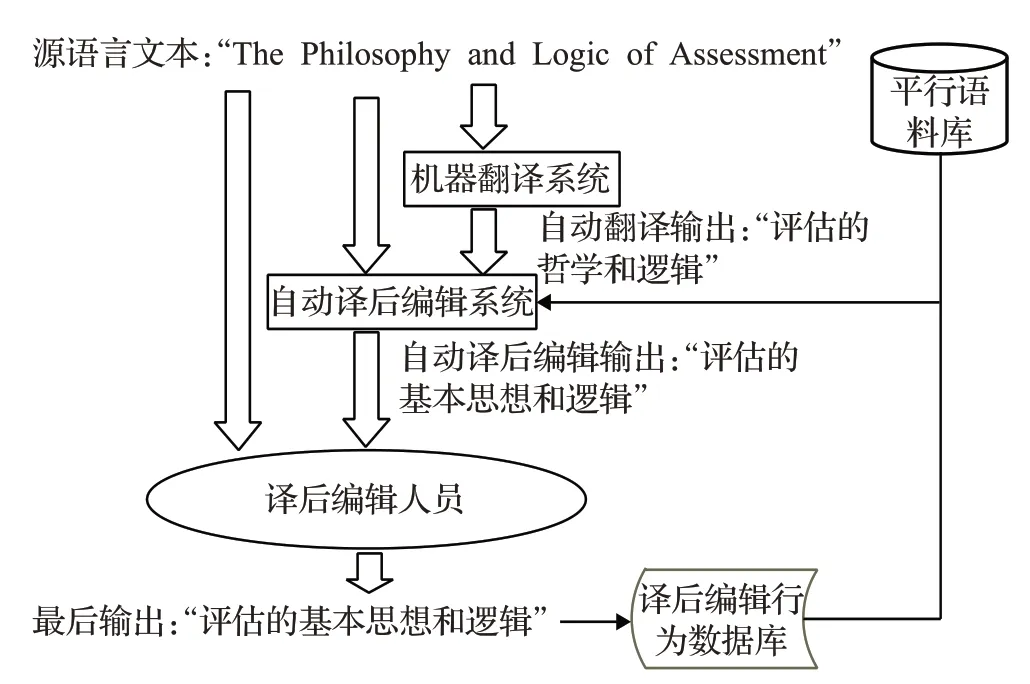
图1 在线学习与自动译后编辑结合的模式
(1)自动译后编辑系统收到一个由源语文本srctest,MT译文mttest组成的二元组(srctest,mttest);
(2)检索由三元组(src,mt,hpe)组成的知识库KB,其中hpe 指的是译员在编辑(src,mt)时的操作,并计算各三元组中的(src,mt)与(srctest,mttest)的相似度,将相似度大于事先设定的阈值的三元组提取出来,记作(srctop,mttop,hpetop);
(3)用(srctop,mttop,hpetop)训练并更新自动译后编辑系统M ,获得更新后的M*;
(4)用M*处理(srctest,mttest),给出其预测的编辑行为ape;
(5)译员收到ape 后对其进行(或不加)修改,记作hpe;
(6)用(srctest,mttest,hpe)再对M*做一次训练,更新为M**,并将这个三元组添加进KB。
在线学习和译后编辑相结合的模式主要涉及两个关键技术:其一是第2 步二元组的相似度计算。文献[14]使用TF-IDF(Term Frequency-Inverse Document Frequency)值,但随着词嵌入技术的发展,完全可以用预训练好的词向量来表示二元组的文本,计算其cosine值来表示彼此的相似度,文献[15]采取的就是这样的方法。其二是自动译后编辑系统所采用的具体模型。文献[14]与文献[16]使用的是基于短语的方法,文献[15]则使用神经网络的方法。在线学习的模式要求译员进行一次编辑操作后,系统能够很快地利用其进行训练并做出反馈,因此文献[8]认为在这一点上基于短语的方法要比神经网络模型更有优势。此外,在线学习模式中能够获取到的用于训练的数据量往往很少,这也是神经网络模型不具备优势的另一个原因。
3 自动MT质量评估
现代翻译流程往往是从多个MT 引擎的输出中挑选一个送往下游流程。那么如何挑选MT译文呢,人工判断固然准确,但速度太慢,与自动译后编辑追求效率的目的相悖。而已有的一些MT质量评价指标,如BLEU(Bilingual Evaluation Understudy)[17]和TER(Translation Error Rate)等需要参考人工译文,也不适用于这里的场景。因此研究者们提出了一系列不需要参考人工译文,由机器自动对MT译文的质量进行评估的方法,这些研究被称为翻译质量评估(Translation Quality Estimation)。
最早的翻译质量评估系统只能对MT 译文做出二元分类:好或是差。后来逐渐发展成能够将MT译文分为多种类别或是对其打分。而具体操作的对象也从字词层面扩展到了句子层面,这也是将其应用在MT+APE模式时最常用的层面[18]。而文件层面的MT质量评估往往是对句子层面评估结果的一个平均[19]。
字词层面的MT质量评估需要为MT译文中的每个词,包括词与词之间的位置,以及原文本中的每个词指定好或是差的标签。其中词与词之间的位置如果被标记为差,说明此位置需要添加内容。原文本中的词如果被标记为差,说明该词被错译或是漏译。图2给出从英语译成德语的一个例子[20],英语原文在上,德语MT译文在下,中间是对MT译文进行人工编辑后的版本。句子层面的MT 质量评估需要预测整句MT 译文的质量,通常要求系统预测人工编辑需要的时间,或是需要的编辑操作次数HTER(Human Translation Error Rate)[20]。值得注意的是,在句子层面上,虽然最终的MT 质量评估系统不需要参考译文,但其训练过程还是用到了需要参考译文的评价指标等数据。文件层面的MT 质量评估需要对整个文件的质量做出评分,并且标注出MT译文中出错的字词和段落。训练数据包括人工标注出的错误以及根据这些错误计算出的质量评分,但并不要求最终的系统在这两个指标之间保持一致,即系统预测的质量评分可以与根据系统标注出的错误计算得到的质量评分不一致。
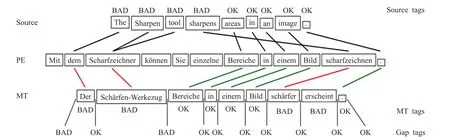
图2 WMT 2018字词层面MT质量评估训练用例
在神经网络技术被应用到这个领域之前,翻译质量评估系统大多由两个模块组成[21]:特征选择模块和机器学习模块。前者从原文和译文中提取特征,交给后者完成对MT 译文的评分。特征主要有三类:复杂度、流畅度、忠实度。复杂度类特征包括原文本的字符数量以及原文本在语言模型上的概率等。流畅度类特征包括译文的字符数量以及译文在语言模型上的概率。忠实度类特征衡量原文本的结构和语义有多少在译文中得到了体现,通常比较原文与译文的字词数量、实体数量等。机器学习模块使用的技术包括支持向量机[21]、条件随机场[22]等。
近年来,神经网络的方法被应用于MT 质量评估。与自动译后编辑领域的发展类似,研究者们使用不同的神经网络结构对文本进行编码解码,从双向递归神经网络编码器-解码器[23]到Transformer[24]。最新一届的WMT 2019 MT质量评估子任务上,使用语境相关的预训练词向量如BERT 及XLM(Cross-lingual Language Models)等进行迁移学习成为了新的趋势[25],比如在本届会议大多数子任务上取得最好结果的Unbabel系统就使用了BERT以及XLM。
除了从众多机翻引擎给出的译文中挑出质量最高的一个版本交给译员,以节省其精力以外,自动MT 质量评估还有很多其他的应用。提高机翻译文的质量最有效的方法之一就是在训练时提供大量的双语文本,但通过人工翻译的方式获取这类数据成本太高,研究者们另辟蹊径,尝试选择“最有用”的数据来训练模型,这种方法通常被称作主动学习。而挑选数据的标准就是一个句子或是一段文本对应的MT质量,如果一个句子已经被翻译得很好了,那么用它来训练机翻模型可以想见不会有多大提升,但倘若一个句子被翻译得很差,很可能这个句子中含有值得机翻模型学习的表达。Logacheva和Specia[26]就基于这一假设,将被自动评估为较低质量的机翻译文所对应的人工译文添加进训练数据。
翻译质量评估还可以与自动译后编辑结合起来,提高机器翻译的质量。Chatterjee等人[27]对此进行了总结:
(1)句子层面上,对MT 质量的评估作为是否需要交由APE系统处理的标准,当一个句子的MT质量低过阈值时,由APE系统对其进行修改。
(2)词层面上,对词的质量评估结果(即好或是差)决定了APE系统是保留还是替换该词。
(3)整体而言,对一段文本的质量评估可用作在原始机翻译文与经APE 系统修改后的版本间进行选择的标准。
4 人工译后编辑
Daems等人[28]认为,研究人工译后编辑过程的终极目标是实现在译员进行编辑之前,就能够预测编辑所需投入的时间与精力(Post-Editing Effort)。在此基础上译员就能够在译后编辑和直接翻译之间做出选择。为实现这一目标,首先需要弄清译员在编辑过程中做出了哪些努力以及如何测量它们,然后通过源语及MT译文中的信息对其进行预测。
4.1 工作量与指标
Krings 在2001 年将译员在译后编辑过程中的工作量按三个维度进行区分:时间(Temporal)维度、技术(Technical)维度、认知(Cognitive)维度[2]。本文分别将其译为工作时间、技术操作、认知负荷。工作时间最容易理解,指译员完成译后编辑工作所花的时间,测量起来也很方便。技术操作统计的是译员在译后编辑过程中做出的具体操作,如删除、插入、重新组织等。早期测量技术操作是计算HTER(Human-Targeted Edit Rate)2本节内的HTER指的是人工编辑比率,而上一节中的HTER指的是人工译文错误率,两处虽然缩写相同,但意义不同。值,但Koponen等人[29]认为译员在实际编辑过程中很可能做出无用操作,如修改之后又撤销,只计算最优路线的HTER无法反映这些操作。文献[28]也表达了类似的观点,认为HTER 测量的是应有的操作数量,而不是实际的操作数量。后来的研究大多通过软件记录译员编辑过程中的击键行为及鼠标操作[28,30]来测量译员在技术操作上的工作量。
工作时间和技术操作可以被直接测量,而认知负荷则只能通过间接手段来测量。对译后编辑工作量的研究也主要围绕认知负荷展开。
认知负荷指的是译后编辑过程中译员完成推理与做出决策所承受的精神压力。通俗地讲,就是发现错误并改正错误所耗费的脑力。文献[2]提出认知负荷与技术操作作为一个整体会影响工作时间,因此有研究尝试通过测量工作时间与技术操作来反映认知负荷。文献[28]测量了译员更正不同难度的MT错误的工作时间,发现难度越高工作时间越长。由于难度与认知负荷是关联的,因此他们认为工作时间可以作为测量认知负荷的指标。他们还指出技术操作并不能很好地反映认知负荷,因为较难的错误可能只需要较少的操作数量来修改。
除了通过工作时间、技术操作来反映认知负荷,研究者们还提出了其他方法和指标来测量认知负荷。早期的研究使用有声思维(Think-Aloud Protocols,TAP)、选择分析网络(Choice-Network Analysis)、译员评分等方法。有声思维指让译员说出其编辑工作中的决策[2],缺点是难以形式化、再利用。选择分析网络[31]关注译员们对MT译文做出的修改方法的数量,同一个词的不同修改方法的数量越多,译员对该词的认知负荷就越高。这种方法的缺点是并非所有译员都能想到所有修改方法,也就是说一个词的不同修改方法数量较少也可能是因为有些修改方法译员未想到。近年来则更多使用可计算的指标,涉及停顿、生产单元、凝视等。其中生产单元的定义依赖于停顿,而凝视则是随着眼追踪技术的发展被提出的一种指标。可计算指标的使用在一定程度上提高了认知负荷测量的科学性,避免了主观性导致的误差。以下分别介绍了停顿、生产单元和凝视三个指标的计算方式。
4.1.1 停顿
当译员的两次操作之间相隔的时长超过一定阈值时,这段时间被认作是一次停顿。阈值数值过大会导致漏掉对短时长停顿的统计,过小会导致将完整的编辑操作割裂。Lacruz等人将该阈值设置为300 ms[32],而文献[28]则设置为1 000 ms。
2006年O’Brien在研究文本的机器可译性(Machine Translatability)时尝试将停顿率(Pause Ratio)与选择网络分析结合起来,作为测量认知负荷的指标,但并没有找到有力的证据来证明这种关系[31]。文献[31]认为这是因为停顿率未考虑每次暂停的平均长度,对认知负荷不够敏感,并介绍了平均停顿率(Average Pause Ratio):

文献[28]对实验数据的分析显示,MT 错误的增加会导致停顿率与平均停顿率减小。由此说明停顿率与平均停顿率在一定程度上反映了认知负荷。
此外,Lacruz等人[32]还提出了与停顿相关的另一种指标——停顿对词比率(Pause to Word Ratio),其计算方式是:

并认为停顿对词比率相对于停顿率和平均停顿率而言,更能精确反映认知负荷。
4.1.2 生产单元
译员在两次停顿之间进行的编辑操作被认为是一个生产单元(Production Unit)[28]。文献[28]通过计算译员在一段源语文本s 上的平均生产单元数来测量认知负荷:

文献[30]从直觉上认为生产单元次数的增加反映的是认知负荷的提高,但文献[28]对此持保留态度,因为像拼写这种简单的错误可能需要相当多的生产单元来更正,但对认知的要求并不高。他们的实验也证明了认知负荷越高,平均生产单元数就越低。
4.1.3 凝视
根据Just和Carpenter于1980年提出的眼-大脑假说(Eye-Mind Hypothesis)[33],人的眼睛在看什么,大脑就在处理什么内容。由此,研究人员假设凝视一段文本的时长反映了该文本对译员认知负荷的要求。Doherty和O’Brien[34]将凝视定义为至少需要注视一段文本100 ms。Jakobsen 和Jensen[35]证明,当译后编辑任务的复杂度上升,即由阅读变为翻译时,平均凝视时长增加,凝视次数增多。Doherty 和O’Brien[34]发现差的MT 译文比好的MT译文需要更多的凝视次数,但两者所需的平均凝视时长并无显著差异。译员在一段文本s 上的平均凝视时长的计算方法如下:

综上所述,停顿、生成单元以及凝视作为可计算指标,均能在一定程度上反映译后编辑过程的认知负荷。然而译后编辑本身是一个复杂的心理活动过程,涉及多种认知方式以及认知方式的转换,仅依赖于一种指标难以测量认知负荷。但目前还缺乏综合性的认知负荷测量研究。
4.2 MT错误分类
MT领域的研究者对MT错误进行分类是为了改进MT 系统,而译后编辑领域的研究者研究MT 错误的分类是因为不同类型的错误对译后编辑工作量的影响不一样[2]。为了弄清楚哪些错误会要求最多的工作量,就需要对MT错误进行分类。
Vilar 等人[36]为了更好地评价MT 译文,将英汉MT错误分为漏词、词序、词语使用不当、未知词、标点符号五类,这五类下面又有更细致的分类,如图3所示。
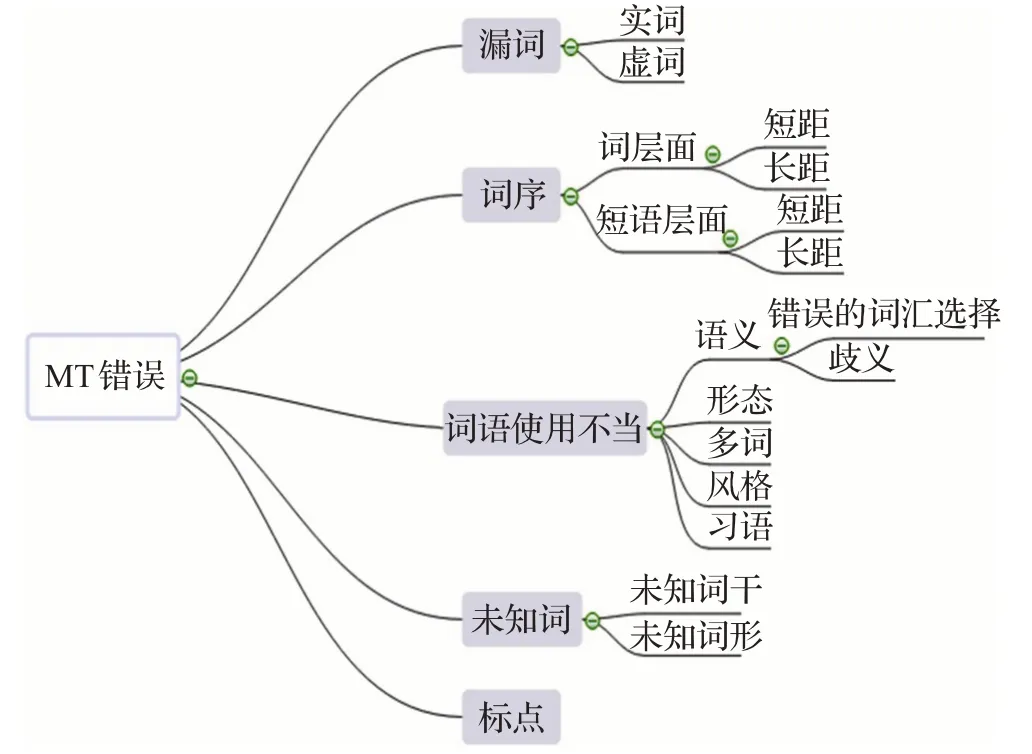
图3 Vilar等人(2006)对MT错误的分类
图3 中的分类被很多译后编辑研究领域的研究者参考并修改为适应自己研究目的的版本,其中最有影响的一个版本是Temnikova 在2010 年[37]提出的。他按照译员在译后编辑时做出的具体操作对图3 中的分类加以修改,并按译者修改错误的难度对错误类型排序,排序结果如表1所示。表1中从1到10难度依次变高,1属于形态类错误,2、3 属于词汇类错误,7~10 属于句法类错误。

表1 Temnikova(2010)对MT错误的分类及排序
在国内,崔启亮和李闻[38]基于自身从事译后编辑工作的经验,以科技文本的英汉翻译为例,将MT 错误分为11 类。具体包括术语翻译错误、形式错误、格式错误、短语顺序错误、欠译和过译、多译和漏译、冗余、词性判断错误、从句翻译错误、短语顺序错误、受英汉句子结构的束缚等。
以上分类方法大多是根据语言学概念做出的分类,显得具体而繁多,即使有些研究将某些类别合并,也没能脱离这个框架。接下来介绍的分类方法在此基础上从更抽象的角度,即按译员从事译后编辑工作时参考的信息来源对MT错误进行了分类。
文献[32]从译员修改机器译文的依据这一角度对MT错误做出分类,不需要参考原文本就能修改的被称作机械类(Mechanical)错误,需要参考原文才能修改的被称作迁移类(Transfer)错误。在这一层次的分类下又分为五类:错译、省略或添加、句法、词语形态、标点。需要注意的是这五类错误需视语境分为机械类或迁移类,比如大多数省略或添加类错误属于迁移类,但当文本与食物有关且译文包含短语fish chips 时,译员不需要参考原文就能将其修改为fish and chips。文献[32]认为前三类,即错译、省略或添加、句法类错误比后两类对译员要求的认知负荷更高。
Daems、Macken和Vandepitte[39]按照翻译标准(Norms)将MT错误分为两类:第一类是只需要观察原文本就能发现的错误,称作不通顺(Acceptability)类错误,包括语法和句法、用词不当、拼写、语域风格、连贯;第二类是需要对比原文和译文才能发现的错误,称作不忠实(Adequacy)类错误,包括歧义、术语不一致等。Tezcan[40]提出了相似的分类方法,但使用了不同的术语Fluency 和Accuracy来描述。
很多研究者[37,40]都指出,由于语言、文本类型、翻译目的等因素的影响,某些MT错误换个情景就可能不再被视作错误或是被分到不同的类别去,因此对MT错误的分类并无绝对的标准。
4.3 MT错误对不同指标的影响
影响度量工作量的指标的因素有很多,比如说译员差异[27],文本类型、主题的差异,翻译目的的差异,MT系统的差异等,但大多数研究都是围绕MT错误这项因素展开的。文献[37]在对MT 错误进行分类时给出了各MT 错误的难度排序(见表1),此后的很多研究都参考了这种排序,也提出了一些修改建议,但对于具体任务中哪些语言现象的错误更难仍没有一定之规。最近的研究多是汇报MT错误与各指标的联系,因此这里主要从宏观和微观两个角度介绍MT 错误对能够反映认知负荷的各指标,即涉及时间、停顿、生产单元、凝视的指标的影响。
4.3.1 宏观
文献[32]认为转移类MT错误比机械类的对认知负荷的要求更高。但文献[37]分析认为,不忠实类MT 错误与译后编辑工作量各指标的联系不够紧密,不通顺类MT 错误能够很好地预测各指标。尽管使用的术语不同,但在各自的定义中,转移类MT错误和不忠实类MT错误可归宿为同一种类型,而机械类MT错误与不通顺类MT 错误相近。上述两个研究在相似的分类上得出了相反的结论。文献[37]对此的解释是,虽然其对MT错误的分类与文献[32]的分类非常相似,但终究不同。文献[37]的分类依据是译员发现错误所用到的信息,而文献[32]的分类依据是译员发现并修改错误所用到的信息,这种差异可能是导致不同结论的原因。
4.3.2 微观
在微观方面,文献[32]发现作为平均停顿率的一种替代,停顿对词比率与错译(Mistranslations)、结构性错误、插入和删除之间联系紧密;文献[29]将编辑操作与错误类型对应起来,发现词层面上的错误更花时间;依据文献[37],MT 错误(尤其是不通顺类)的增多会导致词均工作时长的增加,连贯与结构错误对其影响最大;对于生产单元,文献[37]发现MT 错误(尤其是不通顺类)的增多会导致生产单元数量的增加;对于凝视,文献[37]发现对认知负载要求更高的错误类型,如连贯及错译对平均凝视时长、次数以及词均工作时间的预测更好;错译会导致平均凝视时长显著增加,而连贯会导致平均凝视次数显著增加,这是因为修改连贯性问题需要译者重复回看。
综上所述,不同类型的MT错误与认知负荷之间的关联还缺乏系统性的研究。这一方面是因为MT 错误分类的系统性缺乏,另一方面是认知负荷指标研究的系统性缺乏。
5 结束语
在机器翻译译文输出的基础上进行译后编辑,其初衷是提高译员的工作效率。本文综述了机器翻译译后编辑所涉及的技术问题,主要讨论了自动译后编辑、自动MT 质量评估以及译后编辑人员工作量三方面。其中自动译后编辑与自动MT质量评估均应用MT领域的技术,试图通过自动完成部分编辑及筛选工作来降低译员的工作量,从而提高效率。对人工译后编辑工作量的研究则考察分析不同MT错误类型对工作量的影响,为译后编辑系统环境的设计提供理论依据。总体看来,译后编辑的技术研究是以提高译员工作效率,提高翻译过程工作效率为主要目标。然而,译后编辑作为一个新的研究领域,虽然其主要技术来源是MT 领域,但其主要特征是机器与人协作完成编辑任务。这方面的研究还处于萌芽状态,有待进一步系统研究。
