基于改进粒子群算法的异质车队二级IRP优化
2020-11-18杨华龙辛禹辰
杨华龙,陆 婷,辛禹辰
1.大连海事大学 交通运输工程学院,辽宁 大连116026
2.大连海事大学 物流研究院,辽宁 大连116026
1 引言
库存路径问题(Inventory Routing Problem,IRP)是VMI(Vendor Managed Inventory)模式下,供货商整合库存管理、车辆路径决策的综合性优化问题。供货商为满足位置较远地区的多零售商(客户)需求,节省配送成本,需要在靠近这些客户位置租用配送中心,以便为客户提供配送服务,这就出现了二级IRP[1]。此时,供货商需要考虑三方面成本:一是配送中心库存成本;二是客户处的库存成本;三是配送成本。由于配送和库存之间存在效益背反规律,且在不同销售区和不同时段,客户需求常常会出现随机波动等情况[2],因此随机需求下的多客户二级IRP 优化已成为VMI 模式下供货商经营决策的核心与瓶颈问题。
国内外学者针对IRP展开了许多有益的研究。Soysal等[3]在随机需求的情况下,针对易腐品,建立了多周期的IRP模型,研究将单一产品配送给多个顾客的输出型配送网络。Soysal等[4]进一步研究多个供货商服务多个客户的物流网络结构,建立横向整合策略下的易腐品IRP模型,研究考虑横向整合战略对整条供应链的影响。在此基础上,Micheli等[5]研究拥有异质车队的多对多网络配送系统,重点强调了碳排放策略,如碳限额、碳税、限额交易等对IRP决策的影响。此外,Cheng等[6]研究将单一产品配送给多个顾客的输出型配送网络,建立了同时考虑环境问题和异质车队的IRP模型,并证明了异质车队配送可以节约成本。以上研究都是针对供货商直接交付给顾客的情形,并没有考虑二级IRP的情形。
二级IRP 是IRP 的扩展问题,考虑一个具有两阶段间接交付和路线决策的两级系统。Zhao 等[7]提出了由一个供货商、一个中央仓库和一组客户组成的三级分销系统,提出了用于运输的固定分区策略(Fixed Partition Policy,FPP)和用于库存补充的二次幂(Power-of-Two,POT)库存策略。Rahim 等[8]研究同样的物流系统,提出两阶段启发式解决方案,第一阶段最大程度减少系统总库存成本,第二阶段对车辆路径进行优化。Guimarães等[9]研究了二级多配送中心库存路径问题,强调不同的库存策略对供货商产品输入和最终产品输出的影响,并运用分支定界法和自适应大规模邻域搜索算法对问题进行求解。Rohmer等[10]提出了关于易腐品的二级库存路径问题的模型,主要考虑易腐品的产品生命周期问题,提出了自适应大规模邻域搜索算法进行求解。
在上述已有研究中,研究问题从单个供货商到多个供货商、从直接交付和联合交付等方面不断深化。但是以上关于二级IRP的研究都是假定同质车队,当需求波动较大时,运用同质车队并不能与配送需求很好地匹配,此时采取异质车队配送可以节约成本[11]。因此,研究异质车队的二级IRP更加贴合现实。
此外,IRP 是典型的NP 难问题[12],因此二级IRP 也是NP难问题。近年来,粒子群算法以其概念简单清晰,参数较少,鲁棒性好等优点被广泛应用于VRP 及相关领域[13]。鉴于此,本文结合客户需求波动因素,创新性地开展以下研究:一是提出干线运输和配送相结合的异质车队二级IRP优化问题,构建异质车队二级IRP模型;二是设计改进的粒子群算法对模型进行求解,以期为解决VMI下的二级IRP提供决策参考。
2 问题描述与参数设置
2.1 问题描述
考虑某供货商通过一个配送中心为区域内的多个客户提供VMI服务。在这个供应链系统中,一方面,供货商为配送中心库存补货,由于供货商至配送中心距离远,供货数量大,集货过程(即干线运输)中通常采用运量大的单一类型运输工具,因此只要在销售周期内零售商的总需求给定,则干线运输总成本便不会发生变化。另一方面,供货商通过其配送中心给零售商配送产品,配送车辆完成配送作业后,便返回配送中心。供货商、配送中心与零售商组成的供应链网络库存与配送结构如图1所示。

图1 二级IRP供应链网络
由图1 可见,二级IRP 决策包含虚线圈内的干线运输决策、配送中心库存决策、各零售商库存决策,以及配送中心至零售商的配送车辆路径决策。
由于销售期内不同时段零售商的需求量随机波动,为了提高车辆的使用效率,供货商需要以配送中心和各零售商的库存与配送路径总成本最小的原则,使用异质车队进行配送。由此可见,二级IRP优化的目标是为了最小化配送中心与各零售商两级库存成本,以及配送中心向各零售商的车辆配送成本。决策内容包括:(1)产品从供货商运送给配送中心的时间和数量;(2)配送中心将产品配送给零售商的时间和数量;(3)基于不同车型,如何组成配送中心—零售商的配送车辆和路径。
为了便于问题的解决,本文做以下假设:
(1)在销售期内每个时段零售商需求量已知,但在不同时段会发生随机变化;
(2)只考虑配送中心和零售商的库存持有成本,不考虑订货成本;
(3)配送中心和零售商的初始库存为0;
(4)配送中心和零售商不允许缺货;
(5)配送中心有足够的各类型车辆可供派遣。
2.2 参数设置
(1)集合
ΔC={1,2,…,N}表示零售商的集合;
Δ={0,1,…,N}表示配送网络节点的集合,0表示配送中心;
ΔT={1,2,…,T}表示时段的集合。
(2)参数
Lij:表示从配送网络节点i 到节点j 的距离,i,j ∈Δ;
Dit:表示在t 时段零售商i 对商品的需求量;
Qk:表示k 型车辆的最大载重量,k ∈{1,2,…,K};
Hi:表示配送网络节点i 处单位商品的存储成本,i ∈Δ;
Ii:表示配送网络节点i 处的最大库存容量,i ∈Δ;
F:表示每升燃油的成本;
W :表示司机每小时的薪水;
Rk:表示k 型车辆单位租车成本;
Q:表示干线运输车辆最大载重量;
C:表示每辆干线车每次运输的总成本。
(3)决策变量
wt:表示t 时段供货商给配送中心运送产品的重量;
ut:表示t 时段供货商给配送中心运送产品车辆数;
zit:表示t 时段末,节点i 处商品的库存数量;
2.3 模型构建
由于本文采用异质车队进行配送,车型不同会影响车辆载重、车辆速度等各方面差异,为准确计算不同车型在配送过程中的燃油消耗成本,参见文献[5],引入公式如下:
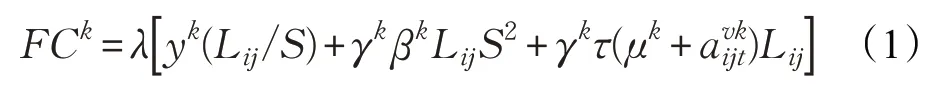
式(1)中,FCk表示第k 种车型从节点i 行驶到节点j过程中的燃油消耗量,λ 为燃油热值系数,φk为第k 种车型的发动机系数,S 为车辆行驶速度,γk为第k 种车型的车辆传动效率系数,βk为第k 种车型的空气阻力系数,τ 为车辆的阻力系数,μk为第k 种车型的整备质量。
于是,可建立考虑异质车队的库存路径优化模型如下:
目标函数:


约束条件:
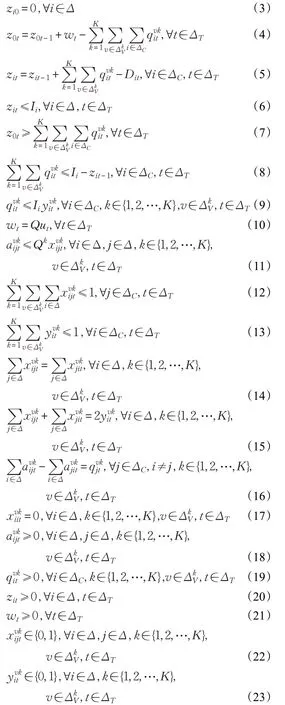
目标函数式(2)表示总成本最小化,第一项为配送中心和零售商的库存成本,第二项为干线运输成本,第三项为配送中心至零售商的配送司机薪水,第四项为配送中心至零售商的租车成本,第五项为配送中心至零售商的车辆燃油消耗成本;式(3)表示配送中心和零售商的初始库存为0;式(4)和式(5)表示配送中心和零售商当前时段末库存数量与上一阶段末库存数量及需求的关系约束;式(6)表示配送中心和零售商的最大库存水平约束;式(7)表示本时段配送中心的库存数量与本时段配送给零售商的产品数量的关系约束;式(8)表示零售商最大库存水平的补货策略约束;式(9)表示如果没有车型为k 的第v 辆车访问零售商i,则车型为k 的第v 辆车向零售商i 交付的产品数量为0;式(10)和式(11)表示配送给配送中心和零售商的装载量约束;式(12)表示配送中心至零售商每个时段每个零售商最多被访问一次;式(13)表示配送中心至零售商的配送任务只能由一辆车来执行;式(14)表示车辆平衡等式;式(15)表示连接两个决策变量之间的关系;式(16)表示产品平衡等式以及消除所有子回路;式(17)表示车辆不会从配送中心直接回到配送中心;式(18)~(21)表示决策变量非负;式(22)和式(23)表示0-1变量。
3 算法设计
本文构建的上述模型是混合整数规划模型,对于小规模算例,可以通过整数线性规划求解器来解决,而对于较大规模的实例,需要设计启发式算法求解。为此,结合模型的特征,本文设计改进的粒子群算法对模型进行求解。
设在一个D 维的搜索空间中,由n 个粒子组成种群X=(X1,X2,…,Xn),每个粒子在D 维搜索空间中的位置代表问题的一个解,第i 个粒子的位置为Xi=(xi1,xi2,…,xiD),速度为Vi=(Vi1,Vi2,…,ViD),个体极值为Pi=(Pi1,Pi2,…,PiD) ,种群的群体极值为Pg=(Pg1,Pg2,…,PgD),粒子在m+1 代的搜索空间中更新自身的速度和位置可如下确定[14]:
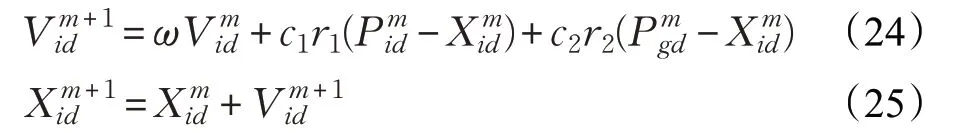
式中,ω 为惯性权重;d ∈(1,2,…,D);i ∈(1,2,…,n);m为粒子群算法当前迭代次数;c1和c2为加速度因子,是非负的常数;r1和r2是分布在[0,1]之间的随机数。
惯性权重的设置影响着算法收敛速度和结果,较大的惯性权重能增强算法的全局搜索能力,而较小的惯性权重则增强算法的局部搜索能力。为避免算法较早陷入局部极值,本文采用线性递减的惯性权重,其取值如下:
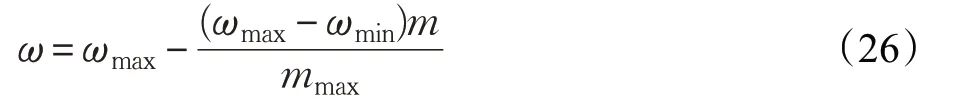
式中,ω 为惯性权重,ωmax是惯性权重最大值,ωmin是惯性权重最小值,m 是粒子群算法当前迭代次数,mmax是粒子群算法的最大迭代次数。
此外,粒子群算法存在容易早熟和迭代后期收敛较慢的缺陷[15],因此针对粒子群算法的收敛速度、收敛精度和早熟问题,本文基于帐篷映射[16]对粒子群算法进行混沌局部搜索改进,运用帐篷映射模型对种群进行初始化,使粒子均匀地分布在空间内,增大粒子群的多样性,以增加局部搜索能力。帐篷映射模型表达式为:

式中,p 为混沌局部搜索的当前迭代次数,p ∈(1,2,…,n);为第j 维变量上的混沌变量。
因此,改进的粒子群算法步骤如下:
步骤1 设置参数。根据问题规模,设置种群大小、粒子群算法的最大迭代次数、混沌搜索的最大迭代次数、学习因子等相关参数。
步骤2 种群初始化。随机产生粒子位置和速度,再利用混沌局部搜索进一步初始化粒子群的速度和位置,进行以下混沌局部搜索:

式中,xmax,j和xmin,j分别为第j 维变量的搜索上下界。

(3)判断当前混沌局部搜索迭代次数p 是否达到混沌局部搜索的最大搜索次数,如果未达到,则返回(2);否则,将混沌搜索的新结果作为新的粒子。
步骤3 根据目标函数式(2)计算步骤2产生的粒子适应度值。
步骤4 根据步骤3 计算的粒子适应度值寻找个体极值和群体极值。
步骤5 更新粒子。根据式(24)和式(25)进行粒子的速度和位置更新,并根据更新后的粒子按照目标函数式(2)重新计算粒子的适应度值。
步骤6 根据更新后新种群中的粒子适应度值更新个体极值和群体极值。
步骤7 终止条件判断。判断粒子群算法的迭代次数m 是否达到粒子群算法的最大迭代次数mmax,如果未达到,返回步骤4;否则,终止算法,输出最优值。
4 算例分析
4.1 算例数据
设有一家供货商,在6 周的决策期内,供货商通过其配送中心D 为位于8 个不同销售区域的零售商C1~C8 提供VMI 服务,供货商和零售商位置数据取自文献[8]。每个零售商每周的随机需求量数据和配送车辆的燃油消耗相关系数数据取自文献[5]。供货商至配送中心的集货过程统一采用30 500 kg 车型进行运输,其每车每次的干线运输成本为3 000元,配送中心给各零售商配送产品的过程有三种车型,载重量分别为4 000 kg(车型1)、12 500 kg(车型2)和17 236 kg(车型3),车辆的行驶速度均为80 km/h。假设配送中心以及零售商的最大库存水平分别为100 000 kg和10 000 kg,配送中心库存持有成本为0.03 元/(kg·周),零售商库存持有成本由均匀分布U[0.01,0.05] 元/(kg·周)随机生成。
本文在CPU 为Intel®CoreTMi7-7700 3.60 GHz,内存为8 GB的电脑上利用Matlab 2016a软件进行数值算例分析,得到供货商使用异质车队时(方案1)的二级IRP配送车辆行驶路径、平均装载率和总行驶距离的计算结果如表1所示。同时,根据每个时段零售商只能配送一次的限制以及结合零售商各时段的需求量数据情况,可知供货商不能使用车型1组成的同质车队进行配送。为此,为了进行异质车队与同质车队配送效果的对比,本文分别计算供货商使用车型2(方案2)和车型3(方案3)组成的同质车队进行配送的结果,亦见表1所示。
由表1中配送车辆行驶路径可以看出,使用异质车队时,会根据配送量合理安排配送车辆,减少车辆的租用成本。根据其行驶距离的计算结果显示,方案1车辆总行驶距离小于方案2车辆总行驶距离,但略高于方案3 车辆总行驶距离。当考虑其平均装载率时,方案1 车辆平均装载率明显高于另两种方案,从而可以有效减少车辆空间的浪费。究其原因,是由于采用本文提出的方案1,配送中心可以根据顾客的需求选择合适的配送车辆进行产品的配送。三种方案下各时段末的客户库存数量计算结果如表2所示。
由表2可以看出,在方案1中,配送中心与零售商的总库存累计为84 900 kg,其中配送中心的库存量累计为70 200 kg,各零售商总库存量累计为14 700 kg;在方案2中,配送中心与零售商的总库存累计为84 900 kg,其中配送中心的库存量累计为61 900 kg,各零售商总库存量累计为23 000 kg;在方案3 中,配送中心与零售商的总库存累计为84 900 kg,其中配送中心的库存量累计为65 200 kg,各零售商总库存量累计为19 700 kg。说明在三种方案中,配送中心与零售商的库存总量一样,但在方案1中,库存主要集中在配送中心处。究其原因是在方案1中车型相对多样,配送中心会根据客户需求合理安排车型,避免不必要的配送,从而减少配送成本,使零售商处库存降低,因此配送中心处的库存较高。
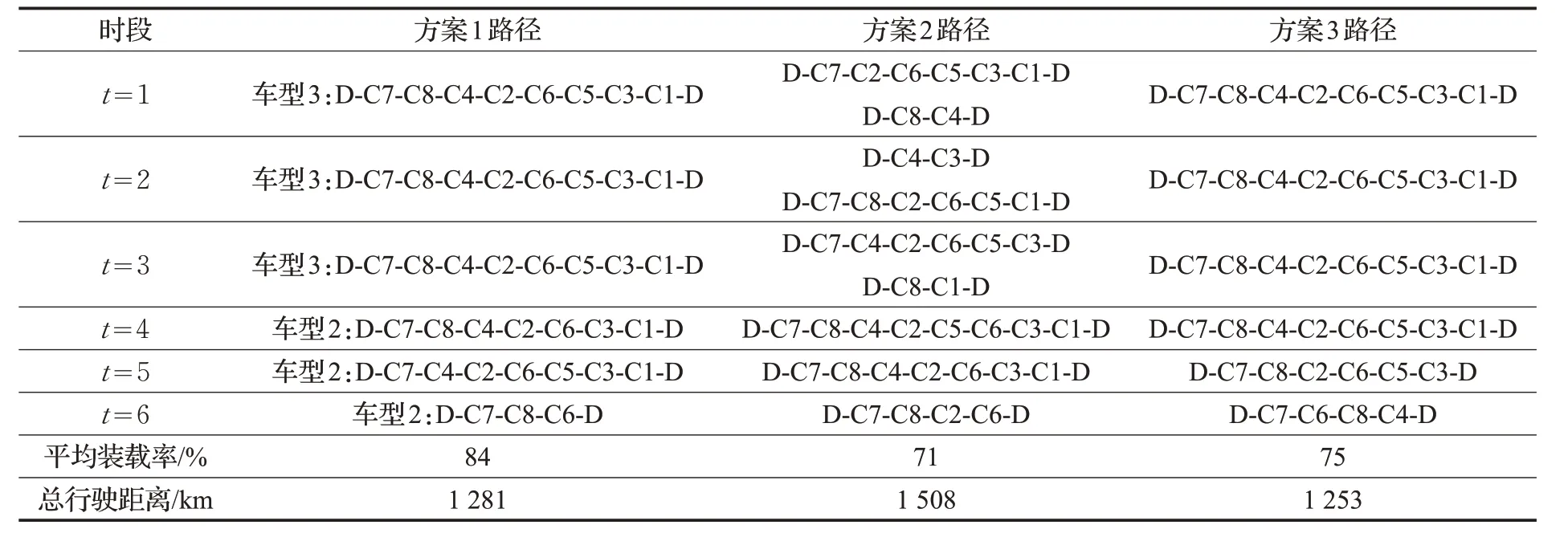
表1 三种方案车辆行驶路径和总距离

表2 使用异质车队与同质车队各时段末的客户库存数量 kg
计算三种方案配送中心库存成本、零售商库存成本、租车成本、燃油成本和总成本等指标,得到结果如表3所示。

表3 三种方案的各项成本 元
从表3的总成本数据可以看出,在方案1中,使用异质车队来完成配送比同质车队更节约成本,尽管在库存持有成本(配送中心与零售商库存持有成本之和)、干线运输成本及司机成本方面,三种方案的结果相差不大,但在租车成本和燃油消耗成本方面,方案1都有明显的降低。这是因为零售商的需求波动变化会导致每一期产品配送量会有差异,使用异质车队进行配送,能够合理地配置车辆,使车辆租用成本和燃油消耗成本普遍减少,从而使总成本减少。此外,从环保的角度来说,也会降低车辆行驶中的排放污染。
为了验证本文改进粒子群算法的有效性,将本文改进粒子群算法(算法1)与传统粒子群算法(算法2)、Cplex最佳可行解算法(算法3)和Cplex精确解算法(算法4)进行比较,结果如表4所示。

表4 算法结果对比
由表4可见,本文提出的改进粒子群算法比传统粒子群算法和Cplex最佳可行解算法的求解效果更好,其不仅与精确解相差不大(与Cplex精确解算法的误差率为0.62%),而且其求解时间优势明显。
图2和图3为本文算法与传统粒子群算法运行结果。

图2 改进粒子群算法迭代变化

图3 粒子群算法迭代变化
从图2 和图3 的算法迭代变化对比可以看出,改进粒子群算法能有效地引导算法跳出局部最优,故算法改进效果明显。
4.2 灵敏度分析
为了分析当产品需求变化波动不同时,考虑异质车型对二级库存路径问题的影响,本文在保持产品的需求总量为72 000 kg 不变的情况下,令产品的需求标准差分别为200 kg至1 600 kg,共8种情况,对算例进行敏感性分析。本文针对每种情况,运用不同的车型运行10次,根据10 次的平均值,得到使用异质车队和同质车队时二级IRP库存路径总成本对比结果,如图4所示。
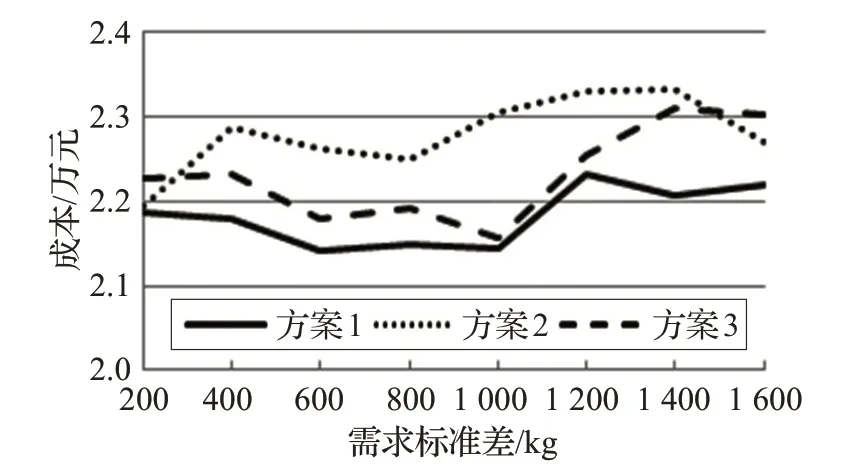
图4 不同需求波动下总成本对比
由图4可以看出,无论产品的需求波动程度怎样变化,使用异质车队时二级IRP库存路径总成本都要低于使用同质车队时的总成本。这是由于产品需求波动变化程度会直接影响产品送货量的大小,间接影响产品的库存水平,由此对成本产生影响。当使用异质车队配送时,即从三种车型中选取合适的车型来满足配送需求,不仅可使车辆运送的路线减少,降低车辆的燃油消耗成本以及驾驶成本,提高车辆的装载率,还可以降低配送中心和零售商的库存成本,从而降低二级IRP库存路径总成本。
5 结束语
VMI 模式下的二级IRP 无论在理论上还是实际应用中都具有非常重要的研究价值。针对这一问题,本文考虑了客户需求频繁波动的实际情况,建立了异质车队的二级IRP 优化模型,并设计了改进粒子群求解算法,算例分析验证了模型和算法的适用性和有效性。研究表明:(1)使用异质车队,不仅可以提高配送车辆的装载率,还能够减少零售商的库存水平;(2)本文提出的异质车队二级IRP 模型,可以有效地降低二级IRP 库存配送系统总成本;(3)不论零售商的需求如何波动,相比于同质车队,异质车队都会降低供货商二级IRP库存路径总成本。研究结论可为供货商VMI决策提供有益的参考。
本文在研究二级IRP 时,假设产品种类是单一的。然而,在实际配送中,产品种类也存在多样化的情形。因此,考虑多种产品的异质车队二级IRP优化将是下一步的研究方向。
