面向复杂道路场景小尺度行人的实时检测算法
2020-11-18李昕昕
李昕昕,杨 林
1.四川大学锦城学院 计算机与软件学院,成都611731
2.西南交通大学 信息科学与技术学院,成都610031
1 引言
目标检测是计算机视觉的重要内容,是众多计算机视觉任务的基础[1]。行人检测技术作为计算机视觉中目标检测的重要分支,在行人分析、智能辅助驾驶、智能监控、服务机器人领域有着广泛的应用[2]。近年来,随着深度学习在计算机视觉领域的崛起,行人检测技术进入了一个快速发展时期,出现了许多基于深度卷积神经网络的行人检测算法,尤以在中大尺度行人目标检测上取得的效果最为突出[3]。但是在复杂道路环境下目标尺度变化大,相同近景与远景目标占据图像像素数量差别10余倍[4],导致小尺度行人目标所采集到的图像像素较少,且随着特征提取网络中网络深度的增加,检测难度越来越大。同时,由于小尺度行人图像易受周围环境和图像噪声等影响,造成漏检和误检,是目前行人检测算法研究中的一个难点。因此如何提升小尺度行人目标检测算法的正确性、快速性和鲁棒性是本文的主要研究目标。
从图1[5]可以看出,行人检测特征提取网络由浅及深多尺度特征层中:(1)随着特征提取网络逐渐加深,感受野不断增大,图像分辨率降低,使得图像空间几何特征的表征能力变弱,在小尺度行人检测上容易导致漏检。(2)浅层网络感受野较小,几何细节表征能力强,可以更加关注小尺度行人目标,但由于语义信息表征能力较弱,泛化性差,易导致误检。
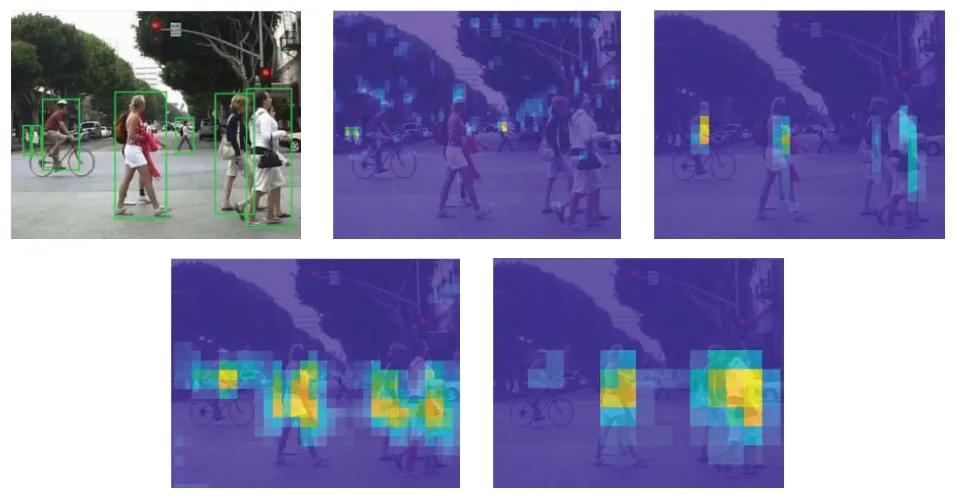
图1 多特征层可视化热力图
针对上述问题,目前多尺度目标检测的主流算法SSD(Single Shot MultiBox Detector)[6]、RFBNet(Receptive Field Block Net)[7]等,提出采用多尺度特征融合的方式,不经过上采样直接从网络不同层抽取不同尺度的特征进行独立预测,来实现不同尺度目标的检测。但是这类算法由于没有考虑浅层特征与深层特征信息的融合利用,对小尺度目标检测效果不是很好。有学者针对这一问题进行改进,提出FPN(Feature Pyramid Networks)[8],即同时利用低层特征高分辨率和高层特征的高语义信息,通过融合这些不同层的特征达到预测效果。但这类算法的检测速度较慢,不能满足实时性的要求。
因此,本文针对目前复杂道路场景中小尺度行人目标检测漏检率较高,检测实时性不佳的问题,提出了一种基于目标检测模型RFBNet的改进算法。本文主要创新包括:
(1)网络结构改进:通过反向融合的方式将多尺度特征图通道进行Shuffle后的深层特征组多级融合到浅层,将深层语义信息和浅层位置及纹理等几何信息进行有效的融合;针对原算法中浅层特征信息丢失较多的问题,引入更浅层特征层,并新增改进后的RFB 模块及Normalization 层,保证其感受野和收敛性,同时去掉部分深层特征层,以兼顾检测效果和速度。
(2)损失函数优化:针对评测和回归损失函数中评价指标不等价问题,基于交并比和中心点距离对回归损失函数进行改进。
2 特征提取网络设计与改进
本文算法的网络框架结构如图2 所示。相较于原始网络,增加了通道Shuffle(混洗)模块、多级特征融合模块、改进的RFB模块,引入了更浅层网络,删除了最深层特征层。
2.1 通道Shuffle模块
在具有多通道类型的行人检测器中,不同的通道包含不同类型的信息[9]。高层网络感受野较大,语义信息表达能力强,但是特征图的分辨率低,几何信息表征能力弱,难以检测小尺度目标。而低层网络的感受野较小,几何细节表征能力强,虽然分辨率高,但是语义信息表征能力弱。为了更加充分地利用局部细节特征和全局语义特征,需要充分利用网络上下文信息,进行深浅特征层信息间的融合。本节提出通道Shuffle模块在多尺度特征层间进行深浅层间的信息融合。
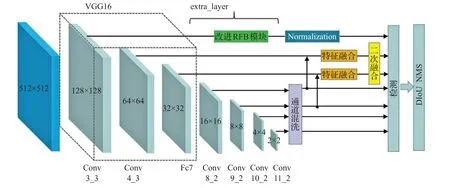
图2 本文算法网络结构图
原始RFBNet 网络中用于引出多尺度特征图的网络extra layer 中包含Conv8_2、Conv9_2、Conv10_2 和Conv11_2 特征层,在进行多尺度特征提取时取得了很好的效果[7]。经过对比实验(见表1),本文选择使用RFBNet512 网络中的Conv8_2、Conv9_2、Conv10_2 和Conv11_2 特征层用于通道Shuffle。其中Conv8_2 通道数为512,其余三层为256。通道Shuffle 模块的实现步骤是:
(1)对Conv8_2使用1×1卷积降至256通道,并保留。
(2)对Conv9_2、Conv10_2、Conv11_2 依次上采样至16×16,按照Concatenation 方式和Conv8_2 进行特征融合。
(3)对步骤(2)中的特征层通过两次reshape操作和一次转置操作进行通道Shuffle。
(4)将Shuffle 后的特征层通过分割和最大值池化的方式转换为融合前的尺度大小,分别为16×16、8×8、4×4、2×2。将步骤(1)中保留的特征层以Concatenation方式与经过通道Shuffle后的Conv8_2进行融合。
通道Shuffle模块算法流程如图3所示。
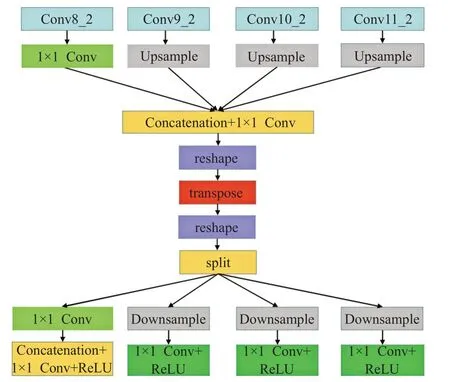
图3 通道Shuffle模块
通过上述通道Shuffle 模块,使得网络各深层语义信息进行充分的混合,提升后续多级特征融合的效果。通道Shuffle模块中不同特征层选取的性能对比实验如表1所示。其中仅选取Conv8_2、Conv9_2、Conv10_2和Conv11_2特征层用于通道Shuffle的检测效果最佳。
2.2 多级特征融合模块
经过通道Shuffle 模块后,深层特征间全局语义信息已经得以充分融合,浅层特征即使不逐级与深层特征融合也可获得较多信息。后三层Conv10_2、Conv11_2、Conv12_2经过上采样后,特征图尺度太小,属于高层语义特征,而Conv4_3 和Fc7 属于低层语义特征,如果直接进行特征融合差异过大,容易导致性能不稳定。因此本节的多级特征融合模块算法流程为:
步骤1 选取经过通道Shuffle后的Conv8_2、Conv9_2两层与浅层的Conv4_3、Fc7层进行特征融合。
步骤2 对每次跨层融合后的特征进行BN操作,保证充分的特征融合以及网络的非线性和稳定性,加快收敛速度。
步骤3 为进一步加强浅层特征融合效果,将经过融合的Fc7和Conv4_3层以Eltwise-SUM方式进行二级融合至Conv4_3层。
步骤4 按照原RFBNet的方法在Conv4_3和Conv7层分别接上RFB-S和RFB模块,加强特征提取能力。
具体操作流程如图4所示。
选取表1中表现效果最好的Shuffle模块(Shuffle3)作为后续实验基础,与增加多级特征融合模块后的算法性能进行对比,结果如表2所示。
2.3 更浅层网络及改进RFB模块
针对浅层特征信息丢失严重的问题,对VGG16 网络中base 层进行修改,引入了Conv3_3 层特征进行检测。但由于Conv3_3 为低层信息,含有语义信息较少,直接用作特征检测层时容易导致模型不收敛,并且可能出现梯度爆炸的情况。因此,后接改进的RFB 模块和Normalization层来丰富浅层特征信息,提升算法的收敛速度和鲁棒性。

表1 Shuffle模块中不同特征层选取对算法性能的影响

表2 增加特征融合模块后的算法性能对比
改进的RFB 模块是在原算法RFB-S 模块的基础上增大感受野,更加关注感受野中心。改进后的RFB模块如图5所示。
改进后的RFB模块算法实现步骤是:
步骤1 通过7 个分支的卷积将通道数变为原来的1/7,接着通过3组分别为3×1和1×3的卷积在提升网络深度的同时减少计算量。
步骤2 通过4组膨胀系数分别为1、3、5、7的膨胀卷积来增大感受野,并将经过这4组膨胀卷积后的特征图通过Concatenation的方式融合至初始通道数,后接1×1卷积保证充分融合。
步骤3 通过ShortCut 的方式给非线性的卷积层增加直连来提高信息的传播效率,与前面经过融合后的特征进行Eltwise-SUM操作。
步骤4 使用ReLU函数作为激活函数进行训练。
Normalization层即L2-normalization操作,数学表达式为:

可以通过该操作将尺度数据归一化到一定的范围,保持多尺度间的相对关系。但如果仅仅将特征的模长缩放到刚好等于1的长度,会使得学习到的特征值变得很小,网络难以训练,于是引入scale_filter 参数将特征值放大20倍,以增强算法的鲁棒性,加快网络收敛速度。
增加浅层特征层Conv3_3,删除深层特征层Conv12_3,并引入改进后的RFB 模块的算法性能结果如表3 所示。实验结果显示,通过引入浅层Conv3_3 层,增加改进的RFB 模块及Normalization 层,可以在保证网络收敛的前提下有效降低网络对小尺度行人目标的漏检率,提升检测效果;由于Conv12_2特征层尺度太小,分辨率太低,对图像中原本就占比较小的行人目标检测较为困难,去掉该特征层后对算法的漏检率无影响,且计算速度更快。
3 损失函数优化
第2章对现有RFB网络进行了改进,提出了LS-RFB网络,但由于评测中评价指标与回归损失函数评价指标不等价,容易造成不易收敛等问题。因此本章引入基于交并比和中心点距离的DIoU Loss 和DIoU NMS 对回归损失函数和非极大抑制算法进行改进。
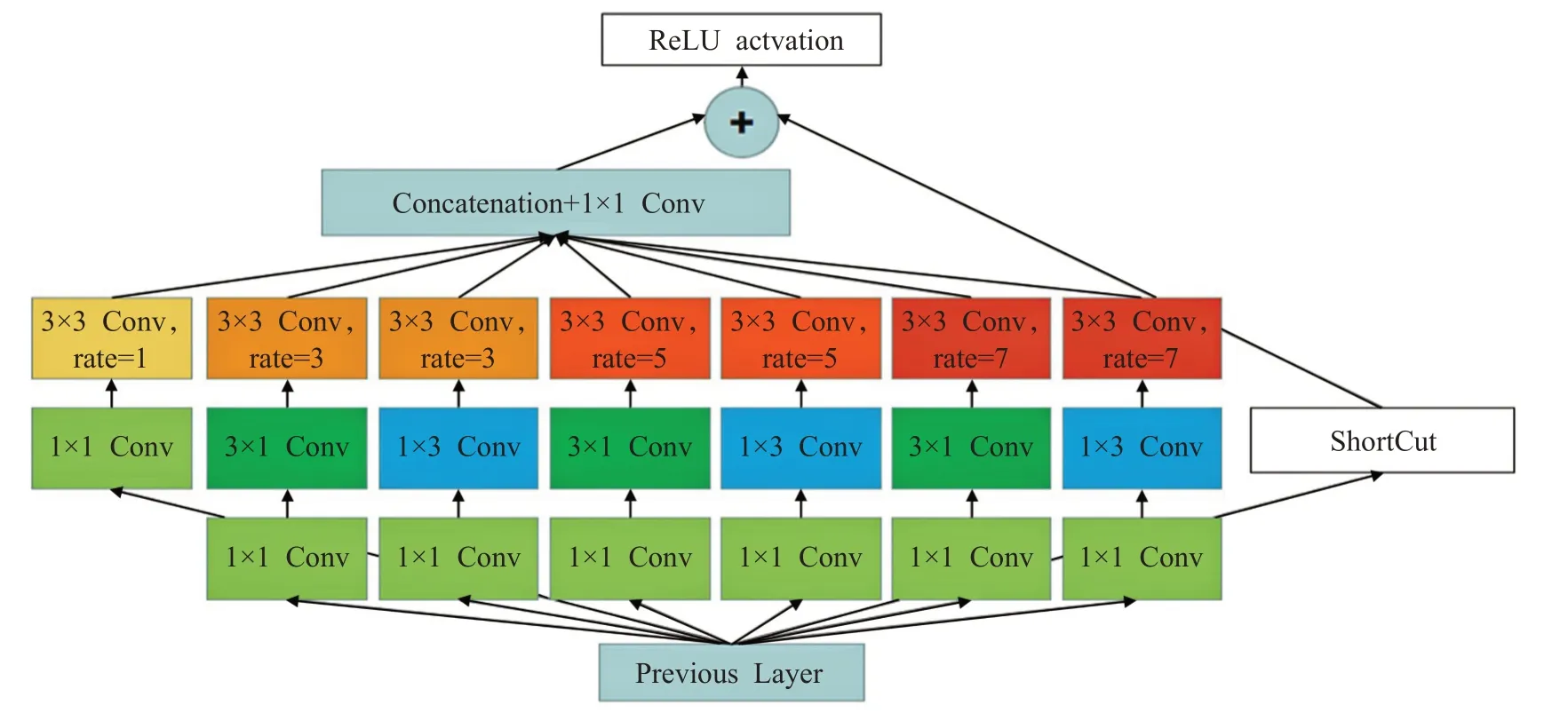
图5 改进后的RFB模块

表3 改进后的算法性能影响

表4 损失函数改进对算法性能的影响
3.1 DIoU损失函数
原网络中回归损失函数采用SmoothL1函数:

虽然SmoothL1函数相较于传统回归损失函数有较大改善,但是在行人检测任务中,还是有一定的局限性:
(1)SmoothL1应用于行人检测任务时,是分别对Bounding Box的4个点的损失进行计算之后求和,得到最终的回归损失。其假设前提是4个点相互独立,对于在实际应用中,有关联性的点其收敛效果并不好。
(2)行人检测的实际评价指标IoU 和用SmoothL1来判断的方法不等价。实际情况中会出现多个检测框与真实框具有相同大小的SmoothL1损失,但是IoU 间差异较大的问题,导致收敛方向错误。
基于上述对SmoothL1函数的分析,本文引入最新工作成果DIoU Loss[10]对原算法的SmoothL1函数进行替换。DIoU Loss是基于现有成果GIoU Loss[11]改进得到的最新算法。
DIoU Loss表达式如下:

最后一项定义为预测框和真实框之间的惩罚项,其中b 和bgt分别表示预测框和真实框的中心点,ρ 表示欧式距离,c 表示预测框真实框的最小外接矩形的对角线距离。
DIoU 在具有尺度不变性的基础上,通过惩罚项直接优化了两个框间的直接距离,特别是在水平和垂直方向以及预测框被目标框包围时,相对于原始回归损失函数能够对算法进行更好更快的收敛。
3.2 DIoU NMS
在原始的非极大值抑制(Non-Maximum Suppression,NMS)中,使用IoU指标抑制多余的检测框,但由于只考虑了重叠区域交并比,在多个预测框有包含关系的情况下,常会导致错误的抑制,因此本文使用DIoU 作为NMS的标准,不仅考虑了重叠区域交并比,还考虑了中心点的距离。
设m 为预测框中置信度最高的一个,DIoU NMS可以表示为:
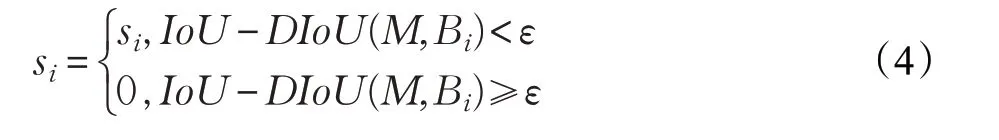
其中,si为分类置信度,ε 为NMS的阈值,Bi为同时考虑到IoU以及两预测框中心点的距离。通过DIoU NMS可以更好地判断多预测框间关系,减少错误的抑制。
3.3 改进后的损失函数实验结果分析
为了验证引入DIoU Loss 和DIoU NMS 后对网络性能的影响,本节进行了对比实验,实验结果见表4。可见,引入改进后的损失函数使算法性能相较于第2章的算法在小尺度行人漏检率上提升了2.4 个百分点,在平均漏检率上提升了1.1个百分点。
4 实验结果与分析
4.1 数据集
Caltech[12]行人数据集采集自常规街景道路中车载摄像头拍摄的大约10小时的分辨率为640×480,帧率为30帧的视频。视频中行人遮挡较多、姿态多样、尺度较小、分辨率低,非常适合用作复杂道路场景下小尺度行人检测数据集。Caltech行人数据集共包含35万个行人标注框和2 300 个不同的行人,分为11 个子集,其中set00~set05 为训练集,set06~set10 为测试集。尺度为Near scale(高度大于80 像素)的有56 000 个行人标注框,尺度为Medium scale(高度在30 至80 像素间)的有241 500个行人标注框,尺度为Far scale(高度小于等于30 像素)的有52 500 个行人标注框。Caltech 行人数据集图片及标记示例如图6所示。

图6 Caltech行人数据集及标记示例
去掉数据集中无行人图片后再对图片进行隔帧抽取,得到训练集22 364张,测试集3 247张。
4.2 实验环境
本文算法实验环境如表5所示。

表5 实验环境参数
预训练模型采用VGG16 网络上的模型vgg16_reducedfc 作为预训练模型,输入图片大小为512×512,数据集格式为VOC 格式,模型匹配正样本时设置阈值为0.5,Batch Size设置为8,动量大小设置为0.9,非极大抑制值设置为0.45。训练Epoch 最大值设置为80。学习率初始化采用适应性学习率的方法,从0.000 001 开始,到Epoch 为8 时,逐步增长至0.001,并且在50/60/70个Epoch 时逐步降低学习率,衰减系数为0.1,前60 个Epoch每隔20个Epoch保存一次,最后20个Epoch每隔5 个Epoch 保存一次,选取最后20 个Epoch 中最好结果作为算法最终结果。使用随机梯度下降法进行网络参数优化,权值衰减为0.000 5。
4.3 实验结果及分析
为验证本文提出算法的有效性,首先相对于原算法RFBNet 进行比较,得到的测试结果如图7 所示。相较于RFBNet 算法,本文算法在Caltech 行人数据集上,总体行人和小尺度行人的漏检率分别降低了4.7%与9.0%,大大提升了原算法针对小尺度行人的检测效果。
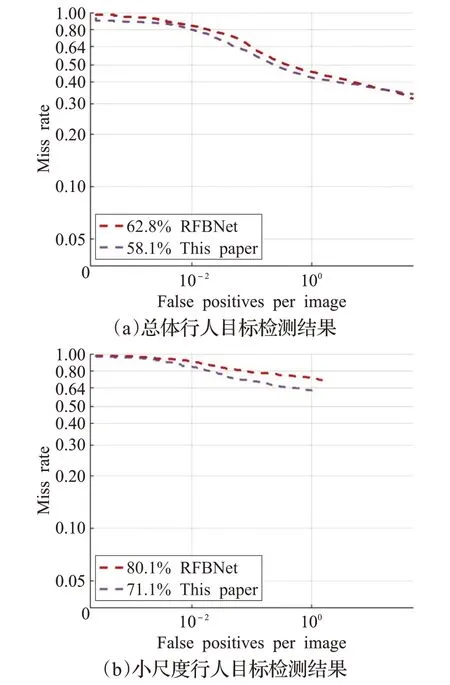
图7 RFBNet与本文算法在Caltech上评价曲线图
其次,将本文算法与现有知名行人检测算法进行漏检率及检测速度比较,如图8 及表6 所示。其中VJ[13]、HOG[14]、ChnFtrs[15]为 传 统 行 人 检 测 算 法,F-DNN[16]、MS-CNN[17]、FasterRCNN+ATT[18]、SSD、RFBNet 为基于卷积神经网络的行人检测算法。可以看出:首先,基于深度学习的行人检测算法在总体漏检率上大幅领先传统算法。但在小尺度行人检测中,受制于多种原因,漏检率普遍较高,与传统检测算法相比,差距不大。其次,在总体漏检率上,本文算法排名第三,相较于排名第一的F-DNN 算法由于没有在除Caltech 外的ETH[19]、TudBrussels Data[20]等多个数据集上进行训练,导致总体漏检率高于F-DNN7.5%。但是在小尺度行人检测结果中,本算法的漏检率低于F-DNN6.4%。最后,从检测速度来看,本文算法对单张图片的平均检测时间为36 ms,相对于F-DNN算法检测速度快近5倍,在保证精度的前提下,相较于其他算法具有最快的检测速度,完全满足复杂道路环境下实时检测的要求。能获得如此优异的实验指标是因为:首先本文采用了基于直接分类回归的检测算法,相较于FasterRCNN+ATT等基于候选区域的Two-Stage方法,检测速度提升明显;其次本文通过反向融合的方式将多尺度特征图通道间Shuffle后的深层特征组多级融合到浅层,经过前面通道Shuffle模块后,深层特征间全局语义信息已经较为充分地混合,浅层特征不用逐级与深层特征混合也可以获得较多的信息,保证了检测速度。由此证明本文针对小尺度行人检测的改进算法是切实有效的。
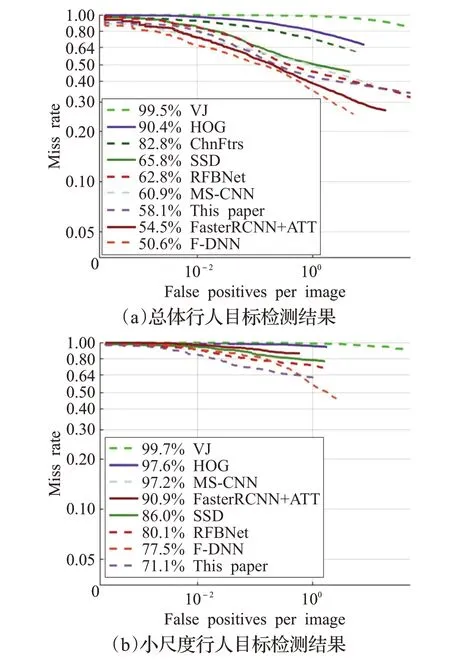
图8 各算法在Caltech上评价曲线图
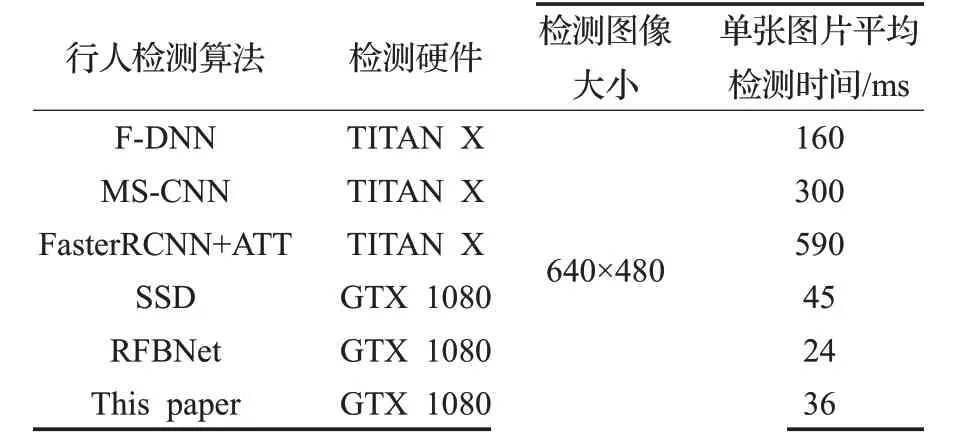
表6 各算法速度比较

图9 小尺度行人检测结果对比

图10 密集场景检测结果对比

图11 遮挡场景检测结果对比

图12 模糊场景行人检测结果对比
在复杂道路场景中,小尺度行人由于离摄像头距离较远,常会存在尺度较小、密集出现、遮挡严重、图像模糊的情况,为验证本文算法改进效果,选取Caltech行人数据集中不同场景,针对上述情况进行效果验证。如图9~图12 所示,左列为原RFBNet 算法检测结果,右列为本文算法检测结果。图9中,针对远处人行道上小尺度行人表现出更好的检测性能,同时也检出了第二张图右边部分遮挡的行人。图10 中,由于图中主要是尺寸较小且分布密集的行人,原算法检测不全,而改进算法全部检出。图11 中,改进算法针对被汽车及广告牌部分遮挡的小尺度行人表现出更好的适应性。图12 中,由于图像质量问题造成的行人边缘模糊,改进算法也能更好地检测。由此可见,本文改进算法不仅针对小尺度行人性能提升较大,且对遮挡、密集、模糊等场景具有更好的鲁棒性。
5 结束语
本文提出的面向复杂道路场景小尺度行人的实时检测算法主要进行了以下几点改进和创新:(1)选取目标检测模型(RFBNet)中的深层特征通道进行Shuffle,利用反向融合的方式将深层语义信息和浅层位置及纹理等几何信息进行有效融合;(2)根据小尺度行人数据集的特点,在兼顾检测效果和速度的前提下,引入VGG16 中的Conv3_3,并新增改进后的RFB 模块,增强其感受野的同时保证收敛性;(3)针对评测和回归损失函数中评价指标不等价问题,基于交并比和中心点距离对回归损失函数进行改进。与原算法相比,本文算法能在保证实时性检测的基础上,显著降低小尺度行人检测漏检率,并对遮挡、密集、模糊等场景具有更好的鲁棒性。
虽然本文提出的算法针对小尺度行人检测问题的准确率有一定提升,但是与实际应用仍然有一定距离,未来准备针对骨干网络进行优化,选取或者设计更轻量且特征提取能力更强的骨干网络;同时准备通过引入热力图数据集等多维度图像数据集增加图像辅助信息,提高模型的泛化能力。
