基于数据驱动的水泥熟料烧成系统能耗优化
2020-11-18丁孝华
丁孝华,黄 堃,杨 文
(国电南瑞科技股份有限公司,江苏 南京 211106)
0 引 言
目前,我国水泥总产量已接近峰值,位居全球首位,但在能源消耗方面还具有较大潜力[1],存量调整、结构优化、产能利用率提高等趋势明显。随着分散控制系统(distributed control system,DCS)在水泥企业的广泛应用[2],实现了对水泥生产过程的实时控制及数据采集、处理和存储。因此通过研究建立水泥烧成系统的能耗模型,并对其关键参数进行优化,对减少电能消耗,提高水泥生产过程的节能和效率具有重要意义。
水泥熟料烧成系统涉及众多环节与设备,是一个多工序相互耦合的系统,具有结构复杂、非线性、强耦合性、变量众多等特点,国内外研究人员对其能耗模型的建立和优化进行了大量研究。文献[3]通过物理原理得到熟料冷却剂参数和能耗之间的模型,但若扩大到整个烧成系统,其复杂性和耦合性会使物理建模可行性不高。文献[4]采用改进的多元非线性数学模型建立了水泥电耗预测模型,但面对变量更多的情况时,计算量大且过程繁琐,不够灵活。文献[5]运用了e-p分析法建立能耗模型,但仅能了解水泥生产过程能耗的分布,确定影响水泥综合能耗的关键工序,并不能为参数优化提供帮助。文献[6]采用多元自适应样条(Mars)建模,但其对比神经网络方法来说,模型不够精准。
综上,现有的建模方法可分为基于机理和基于数据2类,前者具有很强的模型解释能力,但在模型假设条件过多时建模过程复杂;基于数据的方法中,线性回归和自适应等传统建模方法在面对复杂系统建模时没有人工神经网络的方法精准度高,但神经网络方法存在黑盒特性,无法利用神经网络得到一个目标函数表达式,从而造成优化难题。由于遗传算法是采用自然选择和遗传规律的并行全局搜索算法,直接以目标函数值作为搜索信息来度量个体的优良程度,因此不需要一个具体表达式。遗传算法和神经网络的结合算法,克服了神经网络无法得到目标函数表达式的缺点,有效解决了复杂系统的能耗优化问题。此算法目前已应用于很多领域的优化,如激光涂层优化[7]、火电厂燃耗优化[8]、球面精密磨削优化[9]等,但在水泥烧成系统能耗参数优化方面的应用很少。
本文针对水泥炉窑熟料烧成系统,通过改进BP神经网络和遗传算法的结合,并利用平均值法对关键参数进行敏感度分析,根据DCS获取的能耗数据进行建模优化,探讨了水泥熟料烧成系统能耗建模与优化的新途径。
1 水泥生产的工艺流程与参数选取
中国目前水泥生产过程需要向能耗低、产量高、污染少发展[10],而水泥烧成系统内部工序复杂,可分为三大工序:生料的制备、熟料的烧成和水泥的制备,即“两磨一烧”。具体流程[11]为:石灰石经破碎机破碎,按比例和砂岩、粉煤灰、钢渣等原料调配后,送至生料磨粉磨、烘干。在生料均化处均化后,进入窑尾预热器充分预热后,在分解炉中吸收煤粉燃烧释放出的热量而分解,进入回转炉。经回转窑高温煅烧以后形成熟料,从回转窑出来的燃烧化合物称为水泥熟料。此时的熟料温度很高,需要进入篦冷机系统进行冷却输送,通过篦冷机输送设备进入熟料库,熟料或直接出售,或经过水泥制备后,出厂销售,具体流程如图1所示。
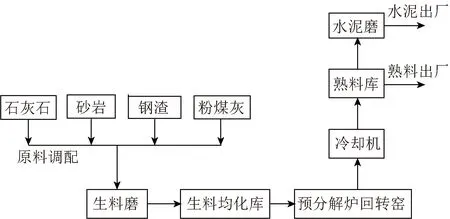
图1 水泥烧成系统流程Fig.1 Flow chart of cement firing system
由图1可知,烧成系统可能依赖参数[12]包括:喂煤量、CO体积百分数、生料流量、冷却剂鼓风管道压力、入冷却机空气温度、熟料流量、预热器出口压力、预热器废水温度、冷却机出口熟料量、冷却机出口熟料温度、冷却剂烟筒压力、冷却剂烟筒废气温度、分解炉中段表面温度、回转炉中段表面温度和环境温度。
2 水泥生产过程的神经网络建模
水泥烧成系统和能耗的关系复杂,各参数相互影响且与能耗呈非线性关系,很难运用简单的模型描述。因此,本文利用BP神经网络进行能耗建模,然后通过遗传算法对BP神经网络的初始权值和阈值进行优化[13],得到改良后的BP神经网络。
通过水泥企业DCS系统的数据库获得吨熟料能耗和能耗关键参数数据,对不同能耗参数分别进行归一化的处理,即
(1)
式中,yi为归一化后的数据值;xi为原始数据值;xmin为数据序列的最小值;xmax为数据序列的最大值。
通过遗传算法对BP神经网络的初始值和阈值寻优[14],将获得的能耗和影响能耗的参数通过改良BP神经网络建立能耗模型,流程如图2所示。具体过程包括:
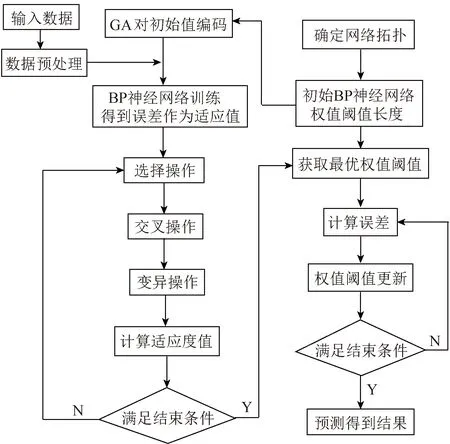
图2 改良BP神经网络算法流程Fig.2 Improved BP neural network algorithm flow chart
Step1:根据处理的能耗关键参数作为输入训练BP神经网络,确定神经网络拓扑。
Step2:根据Step1的神经网络拓扑确定遗传算法个体长度,进行种群初始化。
Step3:确定适应度函数[15],首先通过个体i获取此时神经网络的初始权值和阈值,经过网络训练后,得到网络输出的预测值。预测值与实际值的差值之和,乘以系数K即为适应值H,即
(2)
式中,n为网络输出节点数;oi为第i个节点的预测输出;yi为 BP神经网络第i个节点的期望输出;
Step4:选择轮盘赌法作为遗传算法的选择策略,个体i的选择概率pi为
fi=a/Fi,
(3)
(4)
式中,Fi为个体i的适应度值,fi为对适应度值进行求倒数;N为种群个体数目;a为系数 。
Step5:采用实数交叉法进行交叉操作,第k个染色体αk和第l个染色体αl在j位的交叉操作,具体方法为
αkj=αki(1-b)+αlib,
(5)
αlj=αlj(1-b)+αkjb,
(6)
式中,b为[0,1] 的随机数。
Step6:选取第i个个体的第j个基因αij,并对其进行相应的变异操作,具体的变异操作方式为
(7)
式中,αmax和αmin分别为基因αij的上界和下界;r为[0,1] 间的随机数;f(g)=r2(1-g/Gmax),r2为一个随机数,g为当前迭代次数,Gmax为最大进化次数。
Step7:通过以上流程得到的最优个体作为改良BP网络初始权值和阈值赋值,得到改良的BP神经网络后,用其重新建立能耗模型。
3 关键参数的敏感度分析和基于遗传算法的工业参数优化
改良BP神经网络进行能耗建模后,对关键的能耗参数进行敏感度分析,筛选出对能耗影响较大的参数,本文选用平均影响值法[16]选择参数。其具体实现步骤为:设神经网络的训练数据有n个变量,总计m组数据,即样本集P={P1,P2,...,Pn},输出为一个变量Y=[y1,y2,...,ym]。
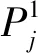
Step3:对m个输出差值IVj求和并取平均,得到第j个输入变量的平均影响值MIVj,其绝对值大小表示该参数的能耗敏感度。
Step4:对MIVj的绝对值降序排列,前k个MIV绝对值的累计贡献率满足
(8)
根据实际数据分析,本文选取η0=70%,既可保证数据的敏感度,也留下足够组的特征值。通过平均值法,最终筛选满足敏感度的k个能耗代表全部输入变量重新构建神经网络建模,然后利用遗传算法以能耗为目标,对能耗关键参数进行寻优。
遗传算法优化[16-17]过程如下:
1)将改良BP网络的输入关键参数通过实数编码的编码方式进行编码操作,得到一个实数编码,作为种群的个体。
2)由于遗传算法不需要具体表达式,直接将神经网络预测值作为适应值。
3)选择选择轮盘赌法作为选择操作。
4)采用实数交叉法进行交叉操作。
5)进行相应的变异操作。
6)最终通过以上流程寻找模型的全局最优值,并将对应的输入值作为优化解,即算法推荐的水泥生产特征变量推荐值。
遗传算法可直接以目标函数值作为一个搜索信息[18],仅使用适应度函数值来度量个体的优良程度,不涉及目标函数值求导求微分过程。实际上很多目标函数很难求导,甚至不存在导数,使遗传算法可结合具有黑盒特性的神经网络进行优化。因此将人工神经网络和遗传算法[18]相结合,可实现复杂的水泥烧成系统的能耗参数优化问题,优化能耗的同时可以得到其对应的关键参数,流程如图3所示。
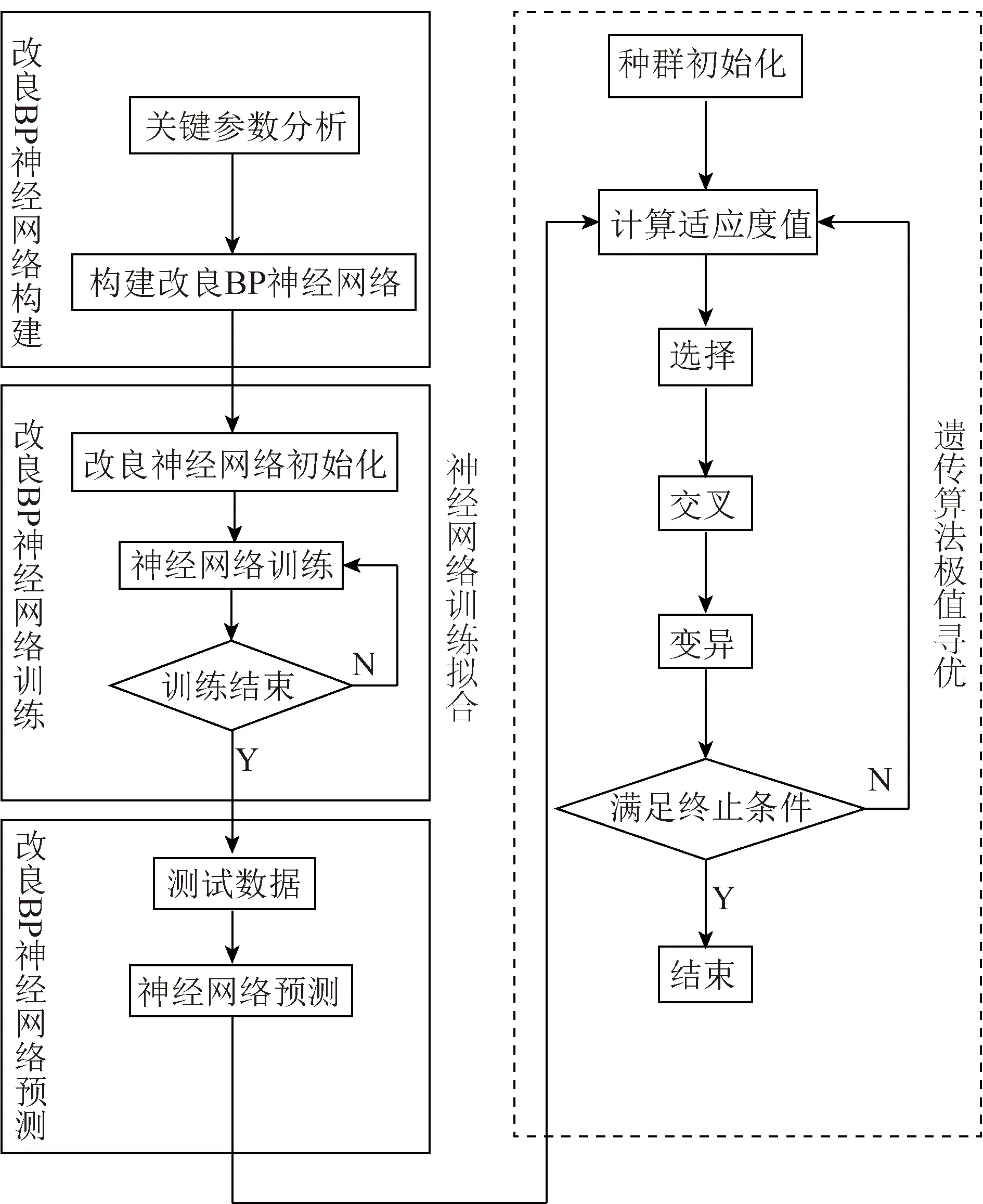
图3 改良BP神经网络-遗传算法流程Fig.3 Improved BP neural network-genetic algorithm flow chart
4 算法验证
本文取白山水泥熟料烧成系统实测的样本数据进行能耗优化和参数推荐,为了验证本文提出的混合算法效果,根据白山水泥熟料烧成系统,结合以往文献对影响能耗参数的分析,选取16组参数数据进行建模,分别为:生料喂煤量、冷却剂鼓风管道压力、入冷却机空气温度、熟料流量、预热器出口压力、分解炉喂煤量、窑头喂煤量、高温风机转速、EP风机转速、预热器出口压力、分解炉中段表面温度、冷却机出口熟料温度、冷却剂烟筒压力、分解炉中段表面温度、回转炉中段表面温度和环境温度。通过敏感度分析,筛选8组关键参数重新对改良的BP神经网络进行训练,分别为生料喂料量、分解炉喂煤量、窑头喂煤量、高温风机转速、EP风机转速、预热器出口压力、分解炉中段表面温度和环境温度。下载75组DCS能耗数据后,其中60组数据用作训练改良BP神经网络的训练数据,其余数据作为测试集,用于测试BP神经网络和遗传算法结合算法的优化效果。改良BP神经网络的预测值与测试值对比和误差百分比分别如图4、5所示。
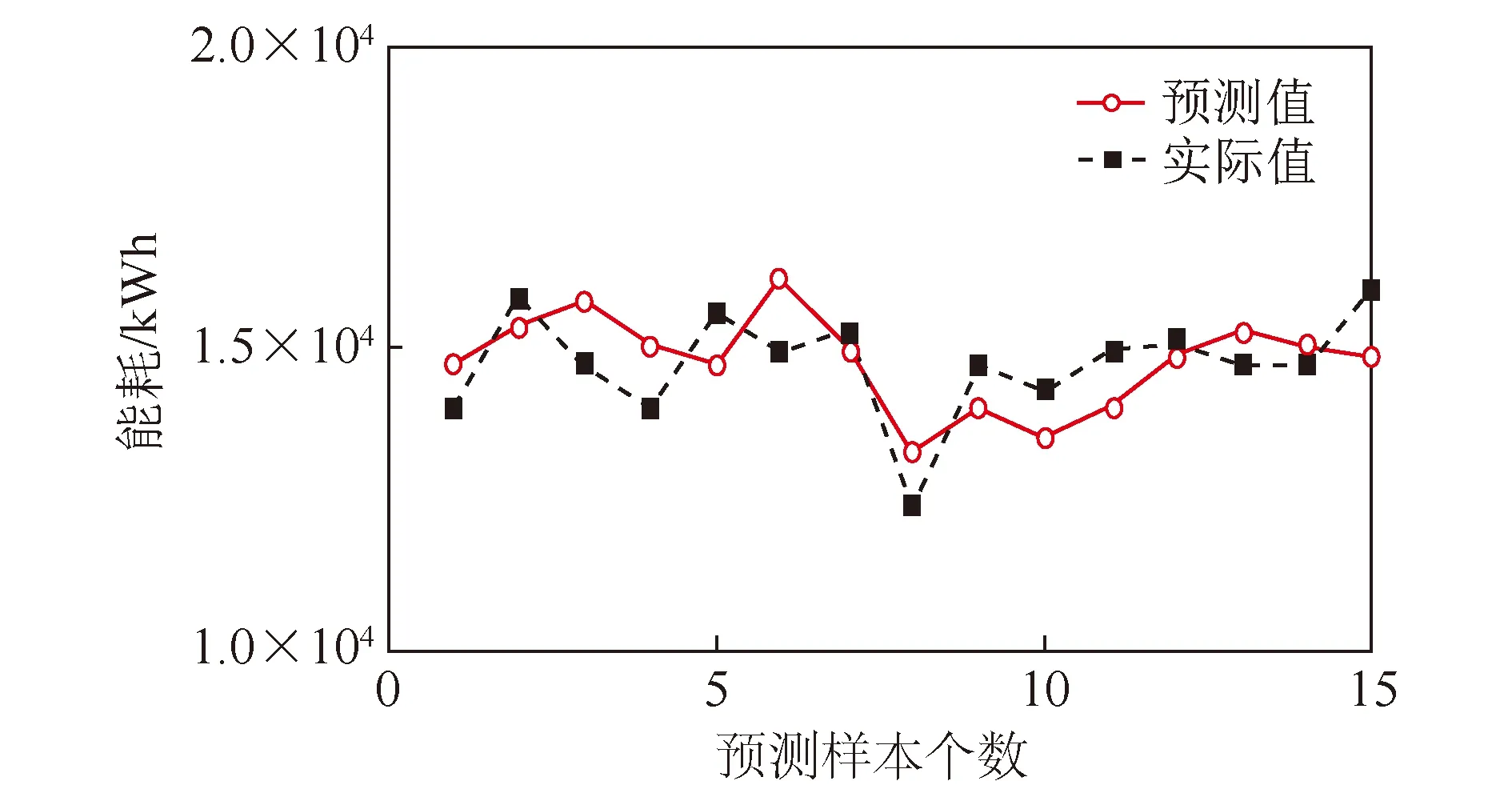
图4 改良BP神经网络预测输出Fig.4 Improved BP neural network prediction output

图5 改良BP神经网络预测误差百分比Fig.5 Prediction error percentage of the improved BP neural network
从图4、5可以看出,改良BP神经网络的能耗模型预测结果较为准确,模型精度较好,误差均可控制在±0.1%以内。
通过训练得到改良BP神经网络拓扑,再利用遗传算法寻找能耗的最小值。将遗传算法的交叉概率设置为0.4,变异概率为0.3,迭代次数为100次,种群规模为20。
遗传算法得到的生料喂料量、分解炉喂煤量、窑头喂煤量、高温风机转速、EP风机转速、预热器出口压力、分解炉中段表面温度和环境温度的最优值分别为223.319 2 t、7.567 2 t、9.992 5 t、1 242.2 r/min、1 230.2 r/min、6.022 0 kPa、860.732 3 ℃、19.206 3 ℃,最优能耗为13 661 kWh,对比一直处于15 000 kWh左右的实际能耗,优化效果达7%左右,同时得到的关键参数可对操作人员提供指导,说明该方法有效。
5 结 论
1)改良BP神经网络模型预测值与测验值误差较小,相对误差不超过0.1%,可有效预测水泥烧成系统的能耗,且在改良BP神经网络模型建立能耗与参数的关系,利用遗传算法对能耗的关键参数进行优化。
2)优化前水泥能耗处于15 000 kWh左右,通过仿真优化,得到的最优能耗为13 661 kWh,优化能耗减少7%。
3)优化后的能耗对应的关键参数为[223.319 2,7.5672,9.992 5,42.291 4,30.233 3,6.022 0,860.732 3,19.206 3],表明该算法可获得特征变量推荐值,优化水泥生产能耗。
